 夜雨聆风
夜雨聆风MATLAB 2024a
1、算法描述
摘要
随着工业物联网、机器类通信、智能传感网络和远程控制系统的发展,通信业务逐渐呈现出数据载荷较短、发送时间随机、业务突发性明显以及端到端时延要求严格等特点。传统信道编码技术通常通过增加码长和译码迭代次数获得较好的纠错性能,但在短包通信条件下,过长的码块会增加传输开销,复杂的译码过程也会占用较多计算资源,难以同时满足可靠性和低时延要求。
Turbo乘积码由两个短线性分组码按照行列级联方式构造,具有编码结构规则、译码过程清晰、行列处理可并行以及参数配置灵活等特点。已有公开研究表明,Turbo乘积码可以面向短包和突发包通信系统进行设计,并可应用于低时延机器类通信场景。因此,围绕短包通信条件下Turbo乘积码的译码复杂度和处理时延展开研究,具有一定的理论意义和工程应用价值。
本文构建了一种基于扩展汉明码的短包Turbo乘积码通信系统。分量码的码长为16 bit,信息位数量为11 bit,最小汉明距离为4。每帧输入121 bit信息,经过行编码和列编码后形成256 bit二维Turbo乘积码码块。接收端分别采用硬判决迭代译码、固定Chase-Pyndiah软判决译码和低时延自适应改进译码。
改进译码算法在传统Chase-Pyndiah译码基础上,引入整体码字校验早停、自适应最低可靠位数量、强可靠分量码跳过、外信息阻尼、外信息限幅以及最终硬判一致性清理机制。系统分别在加性高斯白噪声信道和带局部突发干扰的信道条件下进行仿真,并从误码率、误帧率、平均迭代次数、提前终止比例、平均候选模式数量和硬译码调用次数等方面进行综合评价。
仿真结果表明,低时延自适应译码算法能够根据接收软信息的可靠程度动态调整候选搜索范围,减少已经满足校验条件或可靠度较高的分量码所产生的重复计算。在高斯白噪声信道3 dB条件下,相对于固定Chase-Pyndiah译码,改进算法的平均迭代次数减少约8.30%,平均候选模式数量减少约40.25%。在突发干扰信道3 dB条件下,平均迭代次数减少约9.69%,平均候选模式数量减少约41.25%。研究结果说明,改进算法能够在保持基本纠错能力的同时降低平均译码计算量,适合用于短包低时延通信系统的算法研究和接收机设计。
关键词: Turbo乘积码;短包通信;低时延译码;Chase-Pyndiah算法;扩展汉明码;突发干扰
1 引言
传统移动宽带通信主要面向视频、图像和大容量文件等连续数据业务,数据包通常较长,系统可以通过较大的码块和较多的译码迭代获得较好的纠错效果。机器类通信、工业控制和无线传感网络则具有不同的业务特征。设备通常只需要上传少量状态信息、测量结果、控制指令或告警数据,单次数据载荷较短,发送行为具有随机性和突发性。
在短包通信中,传输时延不仅由无线信号传播时间决定,还受到编码、译码、同步、缓存和处理过程的影响。若译码算法采用固定的大规模候选搜索和较多迭代次数,即使最终误码率较低,也可能产生较大的计算时延。因此,短包信道编码算法需要在纠错性能、计算复杂度、平均处理时延和最大处理时延之间进行综合权衡。
Turbo乘积码是一类由短线性分组码构造的二维编码方案。编码器首先对信息矩阵的每一行进行分量码编码,再对行编码结果的每一列进行编码。最终码字中的每一行和每一列均满足相应分量码的校验要求。接收端可以交替执行行译码和列译码,并在两个方向之间传递可靠度信息。
Turbo乘积码的主要优势在于结构规则。每一行和每一列均可调用相同的分量码译码模块,适合采用并行、流水线或重复使用的硬件架构。与部分长码长编码方案相比,Turbo乘积码可以直接使用较短的分量码构造中短长度码块,便于适配不同的数据包尺寸。
传统Chase-Pyndiah译码能够利用接收信号的软可靠信息,通常具有比硬判决译码更好的纠错效果。该算法会选择若干个可靠度最低的比特,生成多个测试误差模式,并对每个测试模式调用分量码硬译码器。随着最低可靠位数量增加,候选数量会迅速增长。若所有分量码在所有迭代阶段均采用相同的候选数量,会产生较多无效计算。
已有研究从综合症判断、提前终止、候选搜索控制和软信息更新等方面对Turbo乘积码译码进行了改进。2022年的相关公开论文摘要明确提到,Turbo乘积码可以面向短包和突发包场景设计,并可服务于低时延机器类通信。这为本文课题提供了直接的研究背景。
本文以短包和低时延为主要目标,建立基于扩展汉明分量码的Turbo乘积码仿真系统。在保持码结构不变的情况下,对译码过程中的候选生成、可靠度判断、迭代终止和外信息更新方式进行改进,并通过多项复杂度指标分析改进算法的实际效果。
2 短包Turbo乘积码系统设计
2.1 扩展汉明分量码
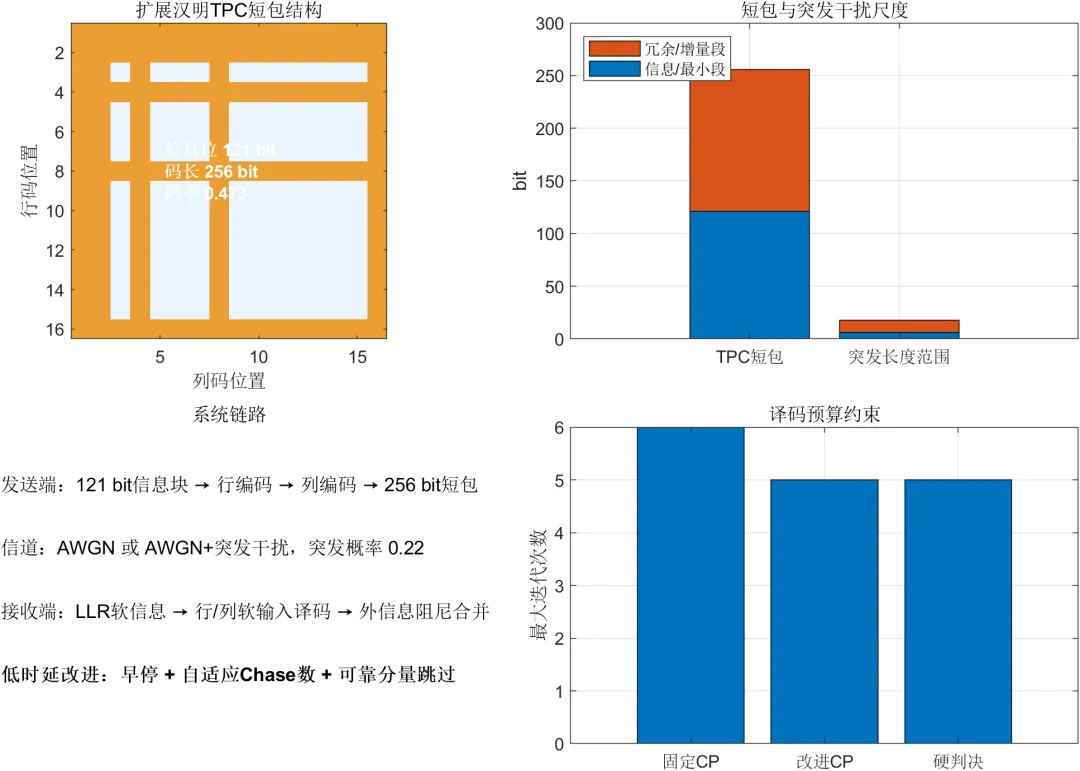
系统采用扩展汉明码作为Turbo乘积码的分量码。该分量码的码长为16 bit,其中包含11 bit有效信息和5 bit校验信息。校验信息由4 bit汉明校验位和1 bit扩展总奇偶校验位组成。
编码过程中,11 bit信息被写入规定的信息位置。随后根据各信息位之间的校验关系计算4个汉明校验位,并根据前15 bit的奇偶性生成第16 bit扩展校验位。
与普通汉明码相比,扩展汉明码增加了总奇偶校验位,可以纠正单个随机错误,并能够识别部分双比特错误状态。其码长较短、编码过程简单、硬译码复杂度较低,适合用于短包Turbo乘积码的分量码设计。
2.2 二维Turbo乘积码编码
每帧原始信息由121 bit组成,并按照11行、11列排列成二维信息矩阵。
编码时,首先对信息矩阵中的每一行执行扩展汉明编码。每行11 bit信息经过编码后扩展为16 bit,因此行编码完成后得到一个包含11行、16列的中间矩阵。
随后对中间矩阵的每一列继续执行扩展汉明编码。每列原有11 bit数据被扩展为16 bit,最终得到16行、16列的二维Turbo乘积码码字。
每个完整码字共包含256 bit,其中有效信息为121 bit,其余部分为行校验和列校验信息。系统总体码率约为0.473。该码率能够在短包长度和纠错能力之间取得一定平衡。
二维Turbo乘积码具有双重约束。最终码块中的每一行均为合法扩展汉明码字,每一列也同样满足扩展汉明码要求。接收端可以利用行方向和列方向的冗余信息反复修正错误。
2.3 调制与信道模型
编码完成后,系统采用二进制相移键控方式进行调制。编码比特0映射为正极性发送符号,编码比特1映射为负极性发送符号。
第一类仿真信道为加性高斯白噪声信道。该信道主要用于评价不同译码算法在随机独立噪声条件下的基础误码性能。噪声强度根据实际码率和设定的比特信噪比进行调整。
第二类信道为带随机局部突发干扰的高斯信道。每个短包具有一定概率受到一次局部强干扰。突发干扰长度在6个至18个连续符号之间随机变化,干扰幅度约为基础高斯噪声标准差的2.6倍。
该突发模型并不表示某一种特定无线信道标准,而是用于模拟瞬态电磁干扰、局部脉冲噪声、短时间深衰落以及连续符号错误等情况。相比纯高斯噪声,局部突发干扰更容易在同一行或同一列中形成多个错误,对分量码译码提出更高要求。
3 基准译码算法
3.1 硬判决行列迭代译码
硬判决译码首先根据接收软信息的正负符号,将每个接收位置判定为比特0或比特1。判决结果按照16行、16列重新排列为二维码字矩阵。
每轮译码首先处理所有行。行译码器依次计算每一行的汉明综合症和总奇偶校验状态。当检测到可纠正的单比特错误时,对相应位置进行翻转。行处理完成后,再采用相同方法处理所有列。
完成一次行译码和列译码后,系统检查二维码块中的全部行和全部列是否均满足扩展汉明码校验要求。若全部通过,则立即停止当前帧译码;若仍存在不合法行或不合法列,则进入下一轮迭代。
硬判决译码结构简单,对存储和计算资源要求较低。但该方法在首次判决后不再保留信道可靠度信息。可靠度较低的位置和可靠度较高的位置被同等处理,因此在低信噪比和突发错误条件下容易出现误纠正或错误传播。
3.2 固定Chase-Pyndiah译码
固定Chase-Pyndiah算法在分量码译码过程中保留接收信号的软可靠信息。
对于每一个长度为16 bit的行码字或列码字,译码器首先按照可靠度从低到高进行排序,并选择4个可靠度最低的位置。随后生成翻转数量不超过2个位置的测试误差模式。
在当前设置下,每个分量码需要测试11种候选模式。其中包括不翻转任何位置、分别翻转1个低可靠位置以及同时翻转2个低可靠位置。
每个测试模式生成后,均需要调用一次扩展汉明硬译码器。只有满足分量码校验条件的结果才能进入候选集合。译码器根据候选码字与接收软信息之间的距离选择最优候选,并利用最优候选和竞争候选之间的距离差生成软输出可靠度。
行译码产生的外信息被传递给列译码器,列译码产生的外信息又返回给下一轮行译码器。通过多轮软信息交换,译码结果逐渐趋于稳定。
固定Chase-Pyndiah译码在所有信噪比、所有迭代阶段以及所有分量码中均采用4个最低可靠位和相同的候选搜索范围。该设置具有较好的统一性,但没有考虑不同分量码的可靠程度差异。当某一行或某一列已经具有较高可靠度时,继续执行完整候选搜索会增加不必要的计算量。
4 低时延自适应译码算法
4.1 整体码字校验早停
改进算法在每次完成行译码和列译码后,立即检查整个二维码块。
检查内容不仅包括汉明综合症和总奇偶校验状态,还包括重新提取信息位并执行编码一致性验证。只有当全部16行和全部16列均为合法码字时,才认为当前短包已经完成译码。
若整体校验通过,则停止后续迭代。该机制能够避免已经正确译码的短包继续消耗剩余迭代预算。信噪比较高时,多数短包可在较少轮次内完成译码,因此整体早停能够有效降低平均迭代次数。
4.2 自适应最低可靠位数量
固定译码算法始终选取4个最低可靠位。改进算法根据当前分量码中的软信息状态,在2个、3个和4个最低可靠位之间动态切换。
译码器首先统计可靠度低于设定门限的比特比例,并同时检查该分量码中的最小可靠度。
当全部位置的可靠度较高,并且低可靠比特比例很小时,只选取2个最低可靠位。此时每个分量码只需要生成4种测试模式。
当分量码中存在一定数量的不可靠位置,但整体可靠程度仍处于中等水平时,选取3个最低可靠位,对应生成7种测试模式。
只有当低可靠位置较多时,才恢复为4个最低可靠位和11种测试模式。
该方法根据接收质量动态分配计算资源。可靠度较高的分量码使用较小的候选集合,可靠度较低的分量码使用较大的候选集合,从而减少统一采用最大搜索规模所造成的计算浪费。
4.3 强可靠分量码跳过
每个分量码进入Chase候选搜索之前,首先执行一次快速硬译码和合法性检查。
若硬译码结果已经满足扩展汉明码校验要求,并且该分量码中所有位置的可靠度均高于强可靠门限,则直接接受当前硬译码结果,不再生成任何测试误差模式。
该机制主要作用于信噪比较高或迭代后期的分量码。在这些情况下,大量行码字和列码字已经处于合法且稳定的状态。继续执行完整候选搜索通常不会改变最终判决,却会产生额外的硬译码调用和候选距离计算。
强可靠分量码跳过能够明显降低平均候选数量,同时避免已经稳定的分量码反复交换外信息。
4.4 外信息阻尼和限幅
行译码器和列译码器之间需要反复交换外信息。若外信息幅度过大,错误判决可能在行列迭代过程中被不断强化,形成错误正反馈。
改进算法对上一半轮译码产生的外信息乘以0.72的阻尼系数,再与原始信道信息进行合并。阻尼处理降低了历史外信息对当前判决的控制程度,使译码器始终保留对原始接收信息的参考。
不同迭代轮次采用不同的外信息权重。前几轮的权重相对较小,避免尚未稳定的候选结果过早主导后验判决。随着迭代继续,外信息权重逐渐增大。
所有外信息还被限制在正负6之间。当计算结果超过限制范围时,直接截断到边界值。限幅处理能够防止少数异常候选产生过大的软输出。
若分量码译码后的软信息与原始信道判决方向相同,但可靠度反而下降,则不向下一半轮传递对应外信息。该处理可以避免译码器削弱原本较可靠的接收判决。
4.5 最终硬判一致性清理
当软判决迭代达到最大次数后,若二维码块仍未通过整体校验,则执行有限次数的硬判一致性清理。
清理过程先对全部行执行扩展汉明硬译码,再对全部列执行硬译码。若一次清理后二维矩阵不再发生变化,则提前结束清理过程。若全部行列校验通过,也立即停止。
最终硬判清理主要用于修正软译码结束后剩余的少量不一致位置。该步骤的执行次数受到严格限制,不会无限增加译码时延。
5 仿真参数与评价方法
5.1 仿真参数设置
系统的比特信噪比范围从0 dB增加到6 dB,相邻仿真点之间的间隔为0.75 dB。
每个信噪比点最多仿真800帧,最少仿真180帧。当累计误码数量达到900 bit后,可以提前结束当前信噪比点的仿真,以控制低信噪比区域的运行时间。
硬判决行列迭代译码的最大迭代次数设置为5次。固定Chase-Pyndiah译码的最大迭代次数设置为6次,最低可靠位数量固定为4个,单个测试模式最多翻转2个位置。
低时延自适应译码的最大软迭代次数设置为5次,最低可靠位数量根据分量码可靠程度在2个至4个之间变化。
参数扫描仿真主要用于比较不同最大迭代次数和可靠度门限。为了控制扫描时间,每组参数最多仿真260帧,最少仿真90帧。
5.2 性能评价指标
误码率用于表示错误信息比特数量占全部传输信息比特数量的比例。误码率越低,说明译码后恢复的信息越准确。
误帧率用于表示发生至少1 bit信息错误的短包数量占全部发送短包数量的比例。对于控制指令和状态上报等短包业务,即使单帧只出现1 bit错误,也可能导致整帧数据失效,因此误帧率具有重要意义。
平均迭代次数表示每个短包实际经历的完整行列译码轮数。该指标能够直接反映早停机制的作用。
提前终止率表示在达到最大迭代次数之前完成译码的短包比例。提前终止率越高,说明大部分数据包不需要耗尽全部译码预算。
平均候选模式数量表示每个短包实际生成和测试的Chase误差模式总数。该指标能够反映自适应最低可靠位数量和强可靠分量码跳过机制带来的复杂度变化。
平均硬译码调用次数表示每个短包调用扩展汉明硬译码器的次数。由于每个候选模式通常都需要进行一次硬译码,因此该指标也能够反映算法的主要计算负担。
上述复杂度指标只能用于评价算法之间的相对计算量,不能直接等同于实际硬件平台上的微秒级时延。实际处理时延还受到处理器主频、并行数量、存储结构、流水线设计和数据接口等因素影响。
6 仿真结果分析
6.1 高斯白噪声信道结果
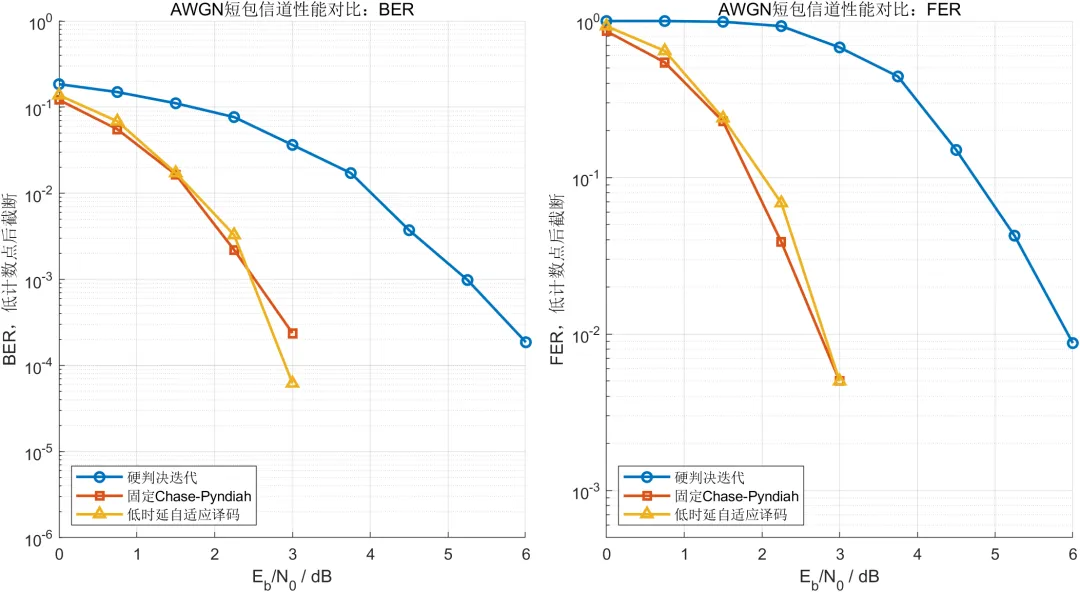
在低信噪比区域,三种译码算法均受到较强噪声影响。随着信噪比提高,软判决译码的误码率和误帧率下降速度明显快于硬判决译码。
在3 dB条件下,硬判决行列迭代译码的误码率约为百分之三点六四,误帧率约为百分之六十七点八。该结果说明,硬判决算法在失去软可靠信息后,难以有效处理多个随机错误。
固定Chase-Pyndiah译码在相同条件下的误码率下降至约二点三八乘以十的负四次方,误帧率下降至百分之零点五。软信息和候选搜索明显提高了分量码的纠错能力。
低时延自适应译码在3 dB处的误码率约为六点二乘以十的负五次方,误帧率同样约为百分之零点五。在当前有限仿真帧数下,不能仅根据该结果认定改进算法具有确定的编码增益,但可以说明自适应减少候选搜索后未产生明显的误帧率恶化。
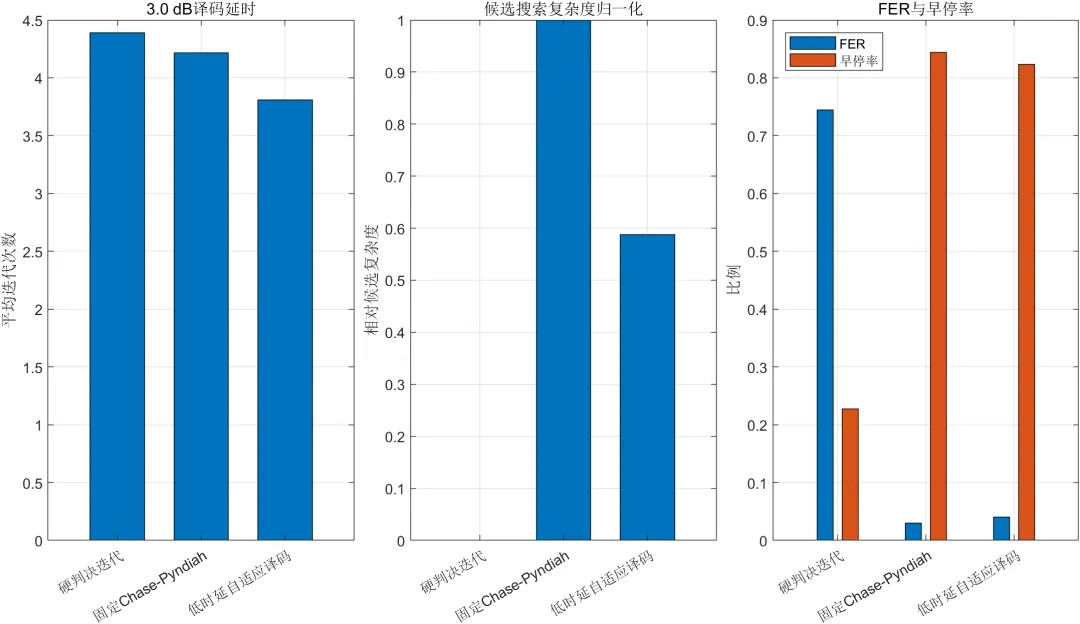
固定Chase-Pyndiah译码在3 dB处的平均迭代次数约为3.84次,平均候选模式数量约为1353个。改进算法的平均迭代次数约为3.52次,平均候选模式数量约为808个。
与固定算法相比,改进算法的平均迭代次数减少约8.30%,平均候选模式数量减少约40.25%。这说明自适应候选控制对降低计算量具有明显作用。
在6 dB条件下,改进算法的分量码跳过率约为百分之六十八点六。固定算法的平均候选模式数量仍接近903个,而改进算法下降至约449个。信噪比较高时,大量可靠分量码能够跳过完整Chase搜索,复杂度降低更加明显。
6.2 突发干扰信道结果
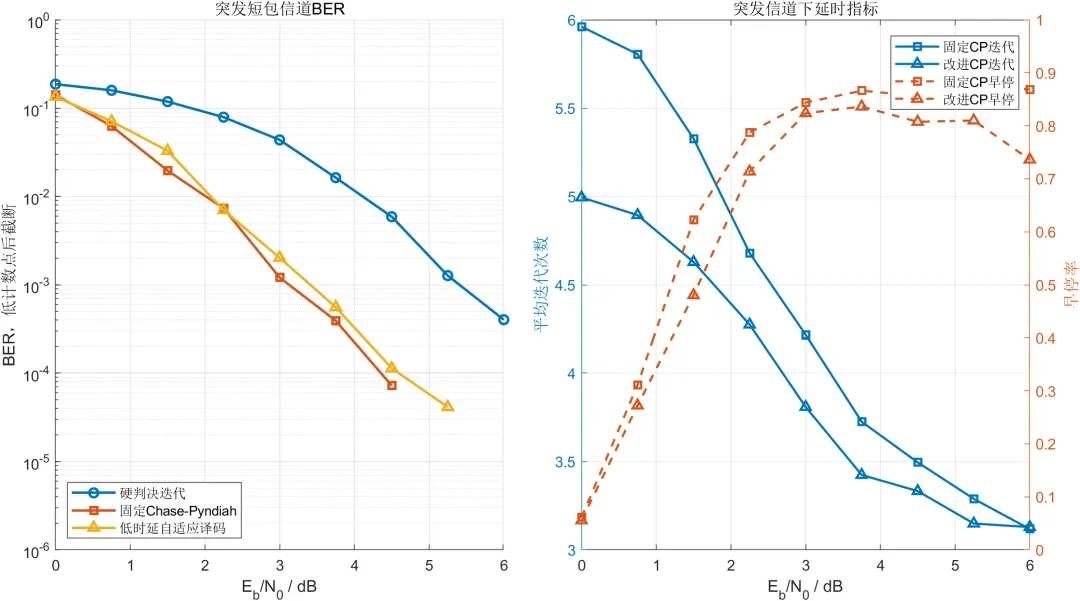
局部突发干扰会在连续多个符号位置产生较强噪声,容易使同一行或同一列中出现多个错误。与纯高斯信道相比,三种算法在突发信道中的误码率和误帧率均有所上升。
在3 dB条件下,硬判决译码的误码率约为百分之四点三七,误帧率约为百分之七十四点四。硬判决分量码难以纠正连续多比特错误,因此整体性能较差。
固定Chase-Pyndiah译码的误码率约为百分之零点一二一,误帧率约为百分之三。低时延自适应译码的误码率约为百分之零点二零三,误帧率约为百分之四。
改进算法在该条件下存在一定的可靠性损失。主要原因在于部分分量码采用了较小的候选搜索范围,同时最大软迭代次数比固定算法少1次。突发干扰造成多个低可靠位置同时出现时,较小的候选集合可能无法覆盖正确误差模式。
复杂度方面,固定算法的平均迭代次数约为4.22次,平均候选模式数量约为1485个。改进算法的平均迭代次数约为3.81次,平均候选模式数量约为872个。
改进算法的平均迭代次数减少约9.69%,平均候选模式数量减少约41.25%。这一结果表明,改进算法的主要优势是降低平均译码计算量,而不是在所有信道条件下都获得最低误码率。
在6 dB突发信道条件下,固定算法和改进算法的误帧率均约为百分之零点一二五。固定算法的平均候选数量约为1097个,改进算法下降至约517个,减少约52.87%。此时改进算法的分量码跳过率约为百分之八十二,说明高可靠分量码跳过机制发挥了主要作用。
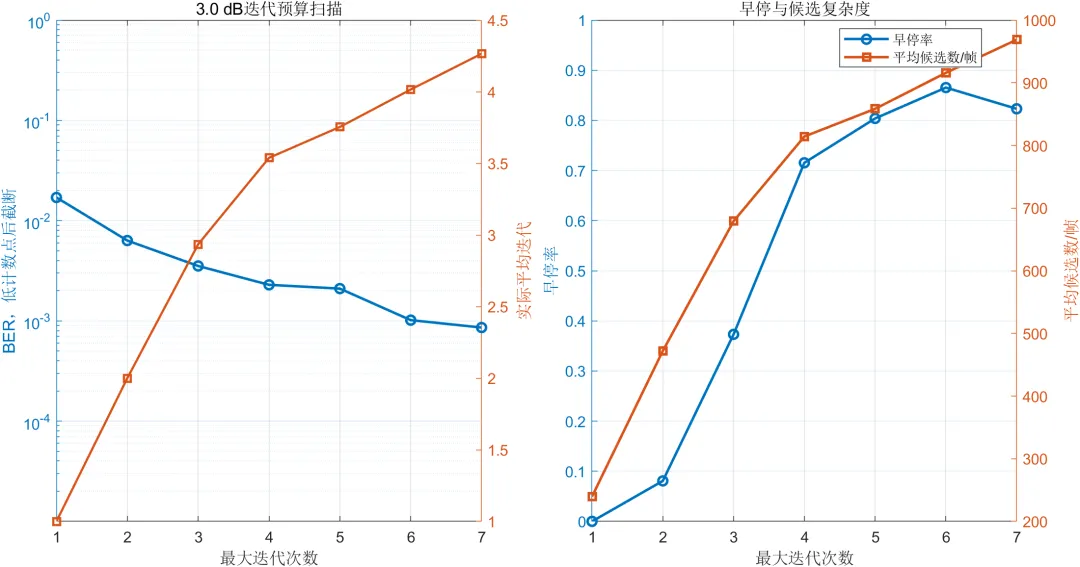
6.3 最大迭代次数影响
当最大迭代次数从1次增加到5次时,改进算法的误码率和误帧率明显下降。增加迭代次数能够使行方向和列方向之间交换更多软信息,从而修正更多错误位置。
当最大迭代次数继续增加到6次和7次时,误码率仍可能获得一定改善,但平均候选模式数量和硬译码调用次数持续增加。部分仿真结果显示,6次和7次迭代对应的误帧率差异已经较小。
这说明译码迭代次数并不是越大越好。对于短包低时延通信,应根据目标误帧率和允许的处理时延选择合适的最大迭代次数。
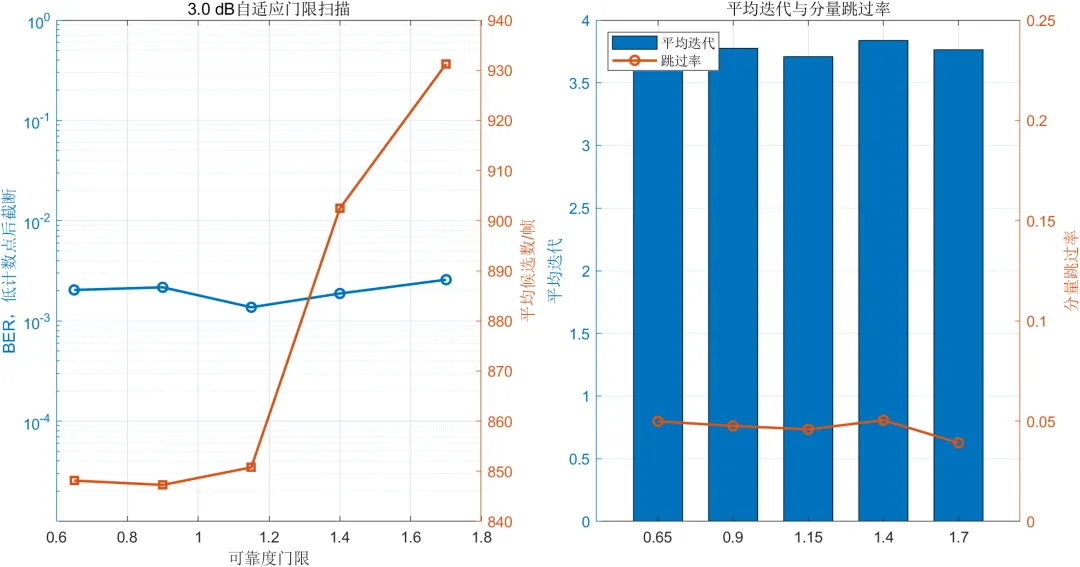
6.4 可靠度门限影响
可靠度门限决定译码器如何判断低可靠位置和强可靠分量码。门限过低时,部分存在潜在错误的分量码可能过早采用较小候选集合或直接跳过搜索。门限过高时,大量原本可靠的分量码会被判定为低可靠状态,导致候选数量增加。
在3 dB突发干扰条件下,门限设置为1.15附近时取得了较低的仿真误码率,平均候选模式数量约为851个。当门限继续提高时,候选数量有所增加,但误码率没有保持单调下降。
由于门限扫描中每个参数点的仿真帧数有限,单次扫描结果只能用于观察变化趋势,不能直接认定某一门限为所有信道条件下的最优参数。实际设计时应结合目标误码率、最大计算量和具体硬件平台进行进一步验证。
7 系统特点
7.1 适用于短包通信研究
系统每帧输入121 bit有效信息,编码后形成256 bit码块。整体码长较短,适合模拟传感器上报、设备控制、状态反馈和突发告警等短包业务。
7.2 具有二维行列约束
Turbo乘积码同时利用行方向和列方向的扩展汉明码约束。错误位置可以在行译码和列译码之间反复修正,具有清晰的二维迭代结构。
7.3 支持多种译码算法对比
系统同时实现硬判决迭代译码、固定Chase-Pyndiah译码和低时延自适应译码。三种算法采用相同的编码结构、发送数据和信道条件,便于进行公平比较。
7.4 采用多层次低时延控制
改进算法同时设置最大迭代次数、整体码字早停、自适应候选数量和强可靠分量码跳过。最大迭代次数限制最坏处理量,其他机制用于降低平均处理量。
7.5 具有软硬译码协同结构
系统利用Chase-Pyndiah算法处理软可靠信息,同时利用扩展汉明硬译码器生成合法候选和完成最终一致性清理。软译码和硬译码各自承担不同功能。
7.6 能够统计译码复杂度
除误码率和误帧率外,系统还统计平均迭代次数、提前终止率、平均候选模式数量、硬译码调用次数和分量码跳过率。算法可靠性和计算量可以同时进行分析。
7.7 同时考虑随机噪声和突发干扰
系统设置了高斯白噪声和局部突发干扰两种信道工况。高斯信道用于观察基础瀑布性能,突发信道用于评价算法面对连续错误段时的适应能力。
7.8 参数配置集中
信噪比范围、仿真帧数、突发干扰概率、突发长度、可靠度门限、阻尼系数、外信息限幅和最大迭代次数均采用集中配置方式,便于修改参数和重复实验。
8 结论
本文针对短包低时延通信系统中的可靠性和译码复杂度问题,构建了基于扩展汉明分量码的Turbo乘积码通信模型,并设计了一种低时延自适应Chase-Pyndiah译码算法。
改进算法没有改变原有Turbo乘积码的编码结构,而是对译码过程中的候选数量、可靠度判断、迭代终止和外信息更新方式进行了优化。整体码字校验早停能够减少已经收敛码块的无效迭代;自适应最低可靠位数量能够根据分量码可靠程度调整候选搜索范围;强可靠分量码跳过能够避免合法且稳定的分量码重复执行Chase搜索;外信息阻尼和限幅能够减弱错误信息在行列之间的过度传播;最终硬判清理能够处理少量残余不一致位置。
仿真结果表明,在高斯白噪声信道3 dB条件下,改进算法相对于固定Chase-Pyndiah译码减少约8.30%的平均迭代次数和约40.25%的平均候选模式数量。在突发干扰信道3 dB条件下,平均迭代次数和平均候选模式数量分别减少约9.69%和41.25%。
改进算法在部分突发干扰条件下会产生一定误码率和误帧率损失,说明低时延译码设计必须在可靠性和计算复杂度之间进行取舍。对于可靠性要求较高的应用,可以适当提高候选搜索范围或增加最大迭代次数;对于计算资源有限和响应时间要求严格的终端,可以采用更积极的跳过和早停参数。
总体而言,本文建立的短包Turbo乘积码仿真系统能够较完整地反映不同译码算法在可靠性和复杂度方面的差异,可用于后续开展定点量化、并行译码结构、现场可编程门阵列实现和实际处理时延测试等研究。
参考文献
[1] YANG T, XI Z, SUN Q T. An improved Chase–Pyndiah algorithm in the iterative decoding of turbo product codes[J]. The Journal of Engineering, 2022, 2022(9): 878-882.
[2] YOON S, AHN B, HEO J. An advanced low-complexity decoding algorithm for turbo product codes based on the syndrome[J]. EURASIP Journal on Wireless Communications and Networking, 2020, 2020: 126.
[3] DONG J, LI Y, LIU R, et al. Efficient decoder for turbo product codes based on quadratic residue codes[J]. Electronics, 2022, 11(21): 3598.
[4] BLOMQVIST F. On hard-decision decoding of product codes[J]. Applicable Algebra in Engineering, Communication and Computing, 2023, 34(3): 393-410.
[5] GAMAGE H, RANASINGHE V, RAJATHEVA N, et al. Low latency decoder for short blocklength polar codes[C]//2020 European Conference on Networks and Communications. Dubrovnik: IEEE, 2020: 305-310.
[6] HUANG L, ZHAO X, CHEN W, et al. Low-latency short-packet transmission over a large spatial scale[J]. Entropy, 2021, 23(7): 916.
[7] FENG C, WANG H M, POOR H V. Reliable and secure short-packet communications[J]. IEEE Transactions on Wireless Communications, 2022, 21(3): 1913-1926.
[8] HAN D, PARK J, LEE Y, et al. Block orthogonal sparse superposition codes for ultra-reliable low-latency communications[J]. IEEE Transactions on Communications, 2023, 71(12): 6884-6897.
[9] MAHMOOD N H, ATZENI I, JORSWIECK E A, et al. Ultra-reliable low-latency communications: Foundations, enablers, system design, and evolution towards 6G[J]. Foundations and Trends in Communications and Information Theory, 2023, 20(5-6): 512-747.
[10] BIOGLIO V, CONDO C, LAND I. Design of polar codes in 5G New Radio[J]. IEEE Communications Surveys & Tutorials, 2021, 23(1): 29-40.
2、仿真结果演示
3、关键代码展示
略
当下时代学习怎么用AI是每个人已经之路,给大家推荐几本书:学习AI相关使用技巧!!! 抓住时代红利!!!
4、MATLAB 源码获取
途径一:点击文章中蓝色字体阅读原文
途径二:复制以下网址到浏览器中打开麦完单品
https://www.maiwan8.com/#/dynamicDetail/0/0c2d94a198f0bbc9a666605236c45f46/index?yqm=5FCPU
途径三:复制网址打开麦完店铺搜索该篇文章标题即可
https://www.maiwan8.com/#/packageA/userDynamicCenter/userDynamicCenter?user_id=1261511
途径四:如果以上方式均失效请通过QQ,邮箱或者微信公众号联系我
(点击上方↑↑↑↑↑蓝色字体跳转)
