 夜雨聆风
夜雨聆风很多 Java 团队接入大模型时,第一版很容易写成这样:业务服务里直接注入 ChatClient,调用模型,拿到结果返回。Demo 没问题,一上线就会遇到另一类问题:某个模型变慢、流式响应中断、Token 成本突然上涨、用户投诉“偶尔没返回”,但日志里只看到一段 prompt 和一个异常。
这时再补“AI 网关”,就不要把它理解成普通反向代理。它真正要解决的不是“统一转发请求”,而是把模型调用变成可治理的后端能力:谁能用、用哪个模型、多久必须返回、失败后怎么降级、一次请求花了多少 Token、链路里到底卡在哪里。
Spring AI 2.0.0 文档里已经把 ChatClient、Advisor、Tool Calling、Vector Store、Observability 等能力纳入 Spring 工程体系。它适合做模型调用层的抽象,但企业项目还需要在它外面补一层“调用治理”。
第一版 AI 网关只抓三件事
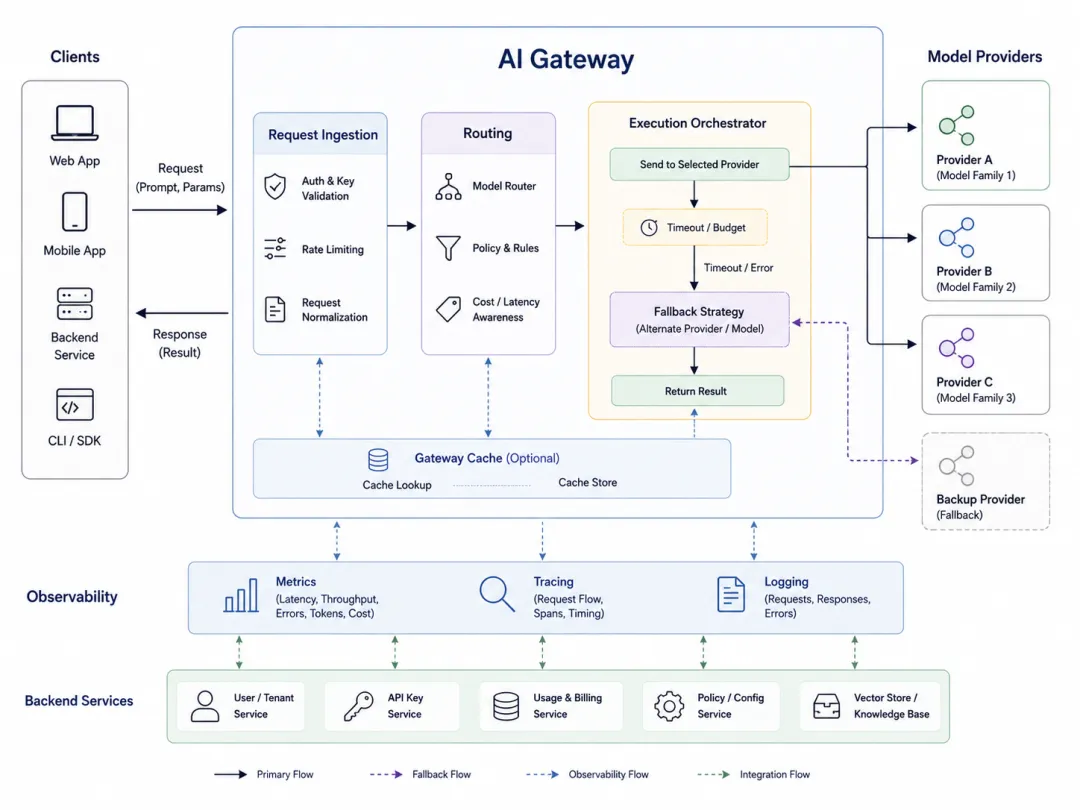
不要一开始就做复杂 Agent 平台。对多数 Java 后端团队来说,第一版 AI 网关先抓三件事就够了。
这里的关键观点是:AI 网关不是把所有模型 SDK 包起来,而是把“不稳定、昂贵、难复现”的模型调用变成可度量、可降级、可审计的工程组件。
调用链里不要丢掉业务语义
普通 HTTP 网关关心 path、status、latency。AI 网关还要关心业务语义。
例如同样是一次聊天请求,客服问答、代码解释、合同摘要、RAG 问答的容错策略完全不同。客服问答可以降级到更便宜的模型;合同摘要可能宁愿失败也不能使用不合规模型;RAG 问答则要区分是检索失败还是模型生成失败。
所以请求进入 AI 网关时,不要只传 message,至少要带上:
public record AiRequest(String scene,String userId,String conversationId,String message) {}
scene 是路由、限流、成本统计和审计的核心字段。没有它,后面所有治理都会变成“按接口猜业务”。
用 Spring AI 做模型调用层,用网关做治理层
Spring AI 的 ChatClient 提供了类似 WebClient、RestClient 的流式 API,也支持 call() 和 stream()。官方文档还说明,ChatClient 支持默认系统提示词、运行时覆盖 options、advisors、tools 等配置。
网关层可以不直接暴露 ChatClient 给业务,而是封装成统一的 invoker:
public interface ModelInvoker {String name();String call(String prompt);}
一个基于 Spring AI 的实现可以保持很薄:
@Componentpublic class SpringAiModelInvoker implements ModelInvoker {private final ChatClient chatClient;public SpringAiModelInvoker(ChatClient.Builder builder) {this.chatClient = builder.defaultSystem("You are a concise assistant for enterprise Java applications.").build();}@Overridepublic String name() {return "primary-chat";}@Overridepublic String call(String prompt) {return chatClient.prompt().user(prompt).call().content();}}
真实项目中,如果你同时接多个模型,通常会为不同 ChatModel 构造不同 ChatClient,再注册成多个 ModelInvoker。具体 Bean 名、starter 和配置会随 Spring AI 版本及模型供应商变化,实际项目中应以官方文档为准。
超时和降级要放在模型边界,而不是 Controller 里
模型调用的失败类型很复杂:HTTP 429、模型超时、响应为空、内容安全拦截、流式中断、工具调用失败。Controller 只应该知道“这次请求失败了”,不应该负责判断“换哪个模型”。
可以把候选模型和熔断逻辑放在网关服务里:
@Servicepublic class AiGatewayService {private final Map<String, ModelInvoker> invokers;private final CircuitBreakerRegistry circuitBreakers;private final MeterRegistry meterRegistry;public AiGatewayService(List<ModelInvoker> invokers,CircuitBreakerRegistry circuitBreakers,MeterRegistry meterRegistry) {this.invokers = invokers.stream().collect(Collectors.toMap(ModelInvoker::name, Function.identity()));this.circuitBreakers = circuitBreakers;this.meterRegistry = meterRegistry;}public String chat(AiRequest request) {for (String model : route(request.scene())) {try {return callWithGuard(model, request);} catch (RuntimeException ex) {// 记录失败后尝试下一个候选模型}}throw new IllegalStateException("No available model for scene: " + request.scene());}private String callWithGuard(String model, AiRequest request) {var breaker = circuitBreakers.circuitBreaker("llm-" + model);var invoker = invokers.get(model);Supplier<String> supplier = CircuitBreaker.decorateSupplier(breaker,() -> CompletableFuture.supplyAsync(() -> invoker.call(request.message())).orTimeout(8, TimeUnit.SECONDS).join());return meterRegistry.timer("ai.gateway.latency","scene", request.scene(),"model", model).record(supplier);}private List<String> route(String scene) {return switch (scene) {case "customer-support" -> List.of("primary-chat", "cheap-chat");case "contract-summary" -> List.of("primary-chat");default -> List.of("cheap-chat", "primary-chat");};}}
这段代码只展示关键结构。生产环境还要补线程池隔离、异常分类、流式响应超时、请求体脱敏、模型返回校验、审计日志等能力。
Resilience4j 的熔断器本身支持 CLOSED、OPEN、HALF_OPEN 等状态,并能基于失败率、慢调用比例切换状态。对模型调用来说,“慢调用”非常重要,因为模型不一定直接失败,它可能只是慢到拖垮接口线程。
可观测性别只打 prompt 日志
很多团队排查 AI 问题时,第一反应是把 prompt 和 completion 全部打到日志里。这在开发环境有用,但生产环境风险很高:用户输入、业务数据、检索上下文、工具调用参数都可能包含敏感信息。
Spring AI 的 Observability 文档里明确提到,ChatClient、Advisor、ChatModel、EmbeddingModel、VectorStore 等核心组件都有指标和 tracing 支持;同时 prompt、completion、tool call 参数默认不会导出,因为可能很大且包含敏感信息。
更合理的做法是默认记录结构化元数据:
traceIdscenemodelstream=true/falselatencyinputTokensoutputTokensfallbackUsederrorTypeconversationId(hash)
当确实需要排查内容问题时,再对单个用户、单个 trace、短时间窗口打开采样日志,并且对身份证号、手机号、邮箱、订单号等字段做脱敏。
AI 网关的可观测性不是为了“看起来有监控”,而是为了回答三个问题:
是哪个模型在变慢?
是哪个业务场景成本异常?
是 prompt、检索、工具调用还是模型本身导致失败?
答不上这三个问题,监控面板再漂亮也没有工程价值。
流式响应要单独设计
很多 AI 应用会用流式输出改善体验,但流式接口和普通 REST 接口不是一回事。
Spring AI 文档也提醒,ChatClient 同时涉及 imperative 和 reactive 两种编程模型,流式响应需要 Reactive stack,例如 spring-boot-starter-webflux。这意味着你在网关层要单独处理几个问题:
首 token 延迟,而不只是总耗时;
客户端断开连接后,是否取消上游模型请求;
中途失败时,前端展示部分内容还是错误提示;
流式链路的 trace 是否能串起来;
降级模型是否也支持流式。
不要把非流式调用简单改成 stream() 就上线。流式响应的用户体验更好,但治理复杂度也更高。第一版可以先只对低风险场景开放流式,比如知识库问答、代码解释;对需要完整一致结果的场景,比如合同摘要、财务分析,仍然优先使用非流式。
第一版落地建议
如果你现在要在 Java 项目里做 AI 网关,不建议先买一个很复杂的平台,也不建议把所有模型能力都抽象成同一套参数。可以从一个 Spring Boot 服务开始:
对业务只暴露 /ai/chat、/ai/stream、/ai/evaluate 这类少量接口;
用 scene 驱动模型路由、限流和成本统计;
每个模型单独配置超时、熔断、并发上限;
默认不记录 prompt 原文,只记录可观测字段;
把 fallback 当成业务策略,而不是技术补丁;
对高风险场景保留人工审核或确定性规则。
AI 工程化的难点不在“能不能调通模型”,而在模型不稳定、成本不可控、结果不完全确定时,后端系统还能不能像一个正常生产系统那样运行。Java 后端开发者真正擅长的,正是把这些不确定性关进清晰的边界里。
