 夜雨聆风
夜雨聆风面对10万行无文档的"屎山",与其推倒重来,不如用SDD给它装上"规范引擎"。
前面三篇文章,我们从Vibe Coding的困境出发,逐步建立了SDD(规范驱动开发)的完整认知:先理解了"为什么AI编程越用越累"的根源,然后梳理了SDD工程化的工具和技能框架,最后通过OpenSpec完整走了一遍从零到一交付项目的流程。
现在,我们面对一个更现实的场景——你不是在绿地上新建项目,而是要在一片"屎山"上做增量改造。如果你的项目没有文档、没有测试、架构已经腐化,SDD还能发挥作用吗?
答案是:能,而且比新项目更需要。
如果你对前面的概念还不熟悉,建议先查看文末合集目录中的前三篇文章,再来看这篇实战攻略。
一、场景设定:当SDD遇上"祖传代码"
1.1 一个真实的棕地困境
你接手了一个运行了3年的电商订单处理系统。代码库膨胀到10万+行,技术栈是Node.js + Express + MongoDB。系统支撑着日均5万单的业务量,但代码质量堪忧——没有单元测试、没有设计文档、没有架构图。
产品经理丢来一个新需求:"订单模块增加Excel导出功能,支持按时间范围导出订单列表,包含用户名、手机号、订单金额、下单时间。"
你打开项目目录,看到的是这样的景象:
src/
├── controllers/
│ ├── order.js # 3200行,包含订单CRUD、支付、退款、物流、导出...
│ ├── user.js # 1800行
│ └── product.js # 2500行
├── services/
│ ├── orderService.js # 1500行,业务逻辑与数据库操作混在一起
│ └── ...
├── models/
│ └── Order.js # 400行,但字段定义散落在多处
└── utils/
└── helpers.js # 600行工具函数,谁也不敢删
更令人头疼的是,这个系统没有任何规范文档。业务规则散落在代码注释、Slack聊天记录和离职同事的口头传承里。你不知道:
订单状态有哪些?流转规则是什么? 折扣计算的逻辑在哪里? 为什么这个字段叫 orderStatus,那个叫status?
传统方式下,你需要花费数周甚至数月来理解这个系统,才能安全地添加一个新功能。
这就是典型的 "棕地项目"(Brownfield Project)——有大量历史遗留代码、文档缺失、架构腐化的存量系统。
1.2 棕地项目的四大"熵增"陷阱
对于任何存续超过三年的商业系统,代码库往往会演变成一座"数字迷宫":
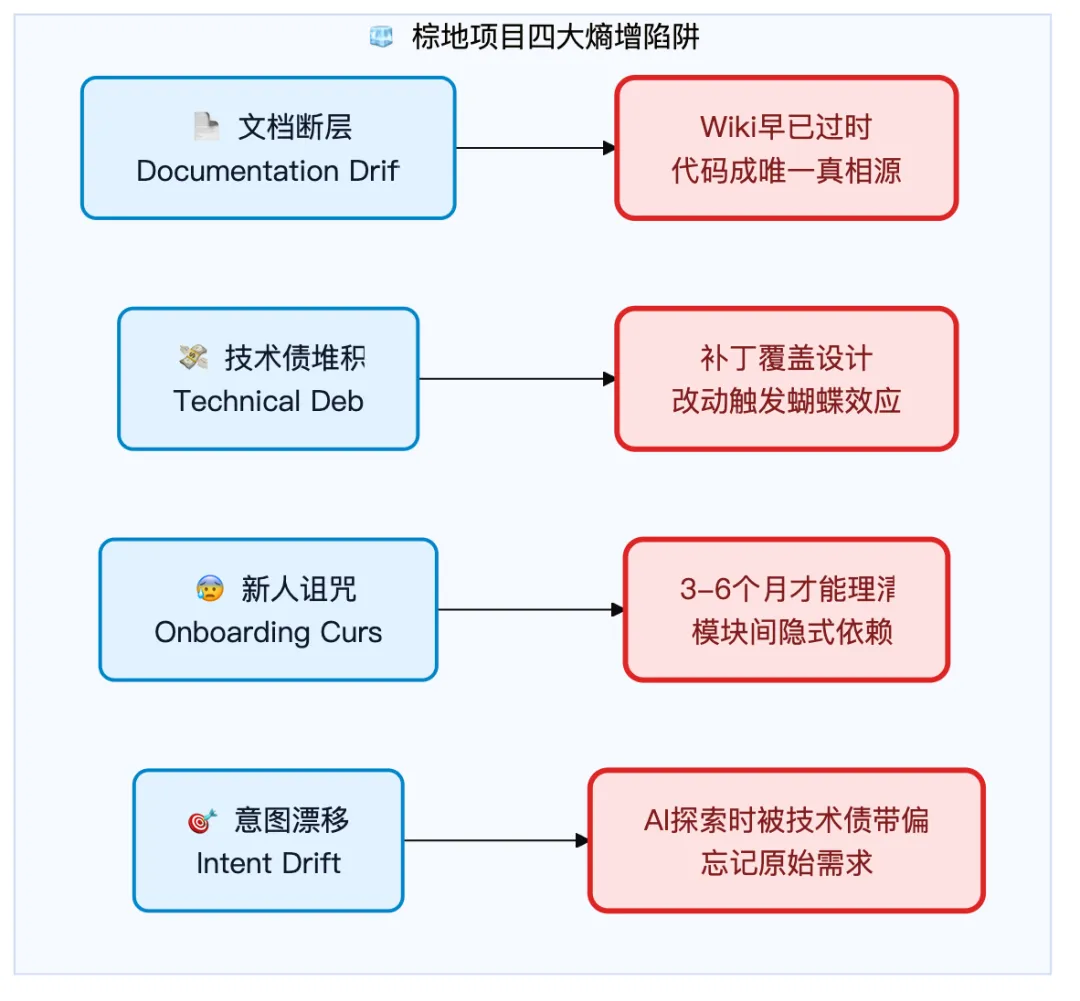
文档断层:Wiki早已过时,代码成为唯一的真相源,但由于缺乏注释和上下文,无人敢轻易解读。
技术债堆积:由于业务压力,补丁代码覆盖了设计模式,维护成本指数级上升,每一次修改都可能引发蝴蝶效应。
新人诅咒:新入职的工程师往往需要3-6个月才能理清模块间的隐式依赖。
意图漂移:在复杂的遗留代码库中使用AI代理时,你从一个清晰的需求单开始,但随着AI探索代码库,它可能会迷失在技术债务中,产生幻觉模式,或在长会话中丢失原始需求。
1.3 为什么SDD是棕地项目的解药?
老项目改造完全可以使用SDD,且比新项目更需要SDD——因为老项目知识都散落在代码、口头传说和过期文档里,年久失修,非常需要更体系化的项目文档和迭代机制。
SDD在棕地项目中的核心价值在于:
- 逆向工程
:从现有代码中提取规范,让"隐性知识"显式化 - 增量改造
:不必一次性重构整个系统,而是改哪写哪,不改不动 - 知识沉淀
:每次变更都产出规范文档,逐步建立完整的项目知识库
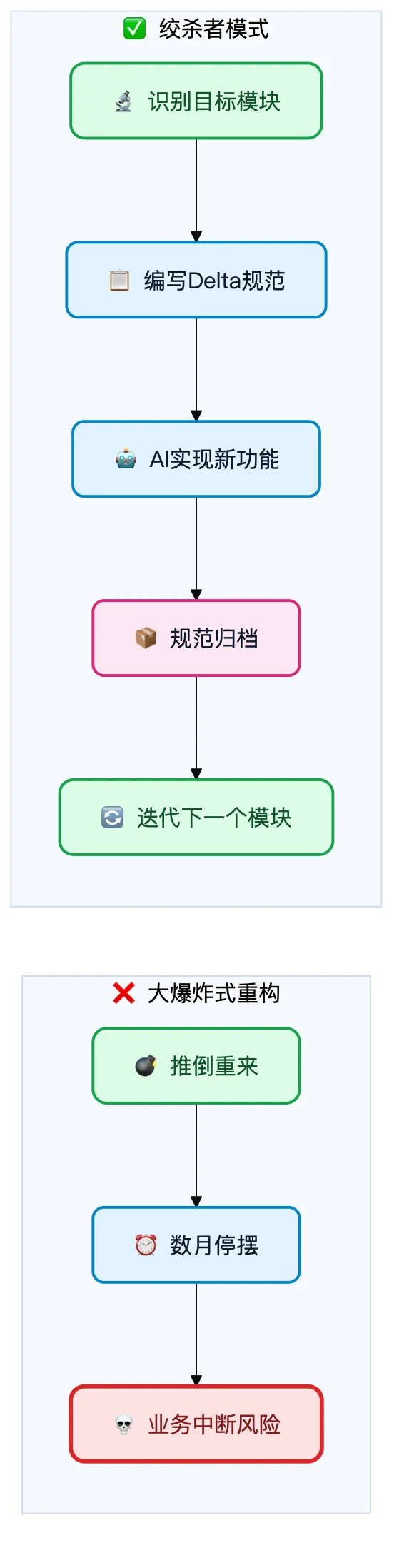
传统重构方式通常是 "大爆炸"式的(Big Bang Refactoring),风险极高,极易导致业务中断。而SDD提供了一种 "显微镜式"的增量改造方案——它不要求你推倒重来,而是要求你为每一个新的变更编写规范。
二、逆向工程:从代码沼泽到清晰规范
面对一个无文档的老项目,首要任务是建立规范基线。传统方式需要人工阅读数万行代码,而借助AI,我们可以大幅加速这个过程。
2.1 AI辅助代码分析:使用 /opsx:explore
OpenSpec的 /opsx:explore 命令是一个探索模式,专门用于开发前的思路梳理和需求调研。它的核心特点是 "只读不写"——可以阅读文件、搜索代码、调研代码库,但绝不编写任何应用程序代码或实现功能。
在AI助手的聊天面板中输入:
/opsx:explore 请分析当前项目的整体架构:
1. 目录结构与模块划分
2. 核心数据模型(Order、User等)
3. 主要API端点及其功能
4. 外部依赖与服务
5. 编码规范与模式(如果有)
6. 订单相关的业务规则(状态流转、折扣计算等)
AI会以只读方式扫描代码库,输出一份结构化的分析报告。
保存探索结果:AI输出分析报告后,直接告诉它将内容保存到文件:
请将上面的分析结果保存到 openspec/explorations/architecture-analysis.md
AI会直接调用写文件能力,将内容保存到指定路径。不需要手动复制粘贴。
# 项目架构分析报告
## 1. 目录结构
- controllers/:路由控制器(order.js 3200行,包含CRUD+支付+退款+导出)
- services/:业务逻辑层(与DAO层耦合严重)
- models/:Mongoose模型定义
- utils/:工具函数(存在大量重复代码)
## 2. 核心数据模型
### Order模型(models/Order.js)
- id: String (主键)
- orderNo: String (唯一订单号)
- userId: ObjectId (关联User)
- items: Array (商品列表)
- totalAmount: Number (订单总额)
- discountAmount: Number (折扣金额)
- finalAmount: Number (实付金额)
- status: String (枚举: pending, paid, shipped, completed, cancelled)
- createdAt: Date
- updatedAt: Date
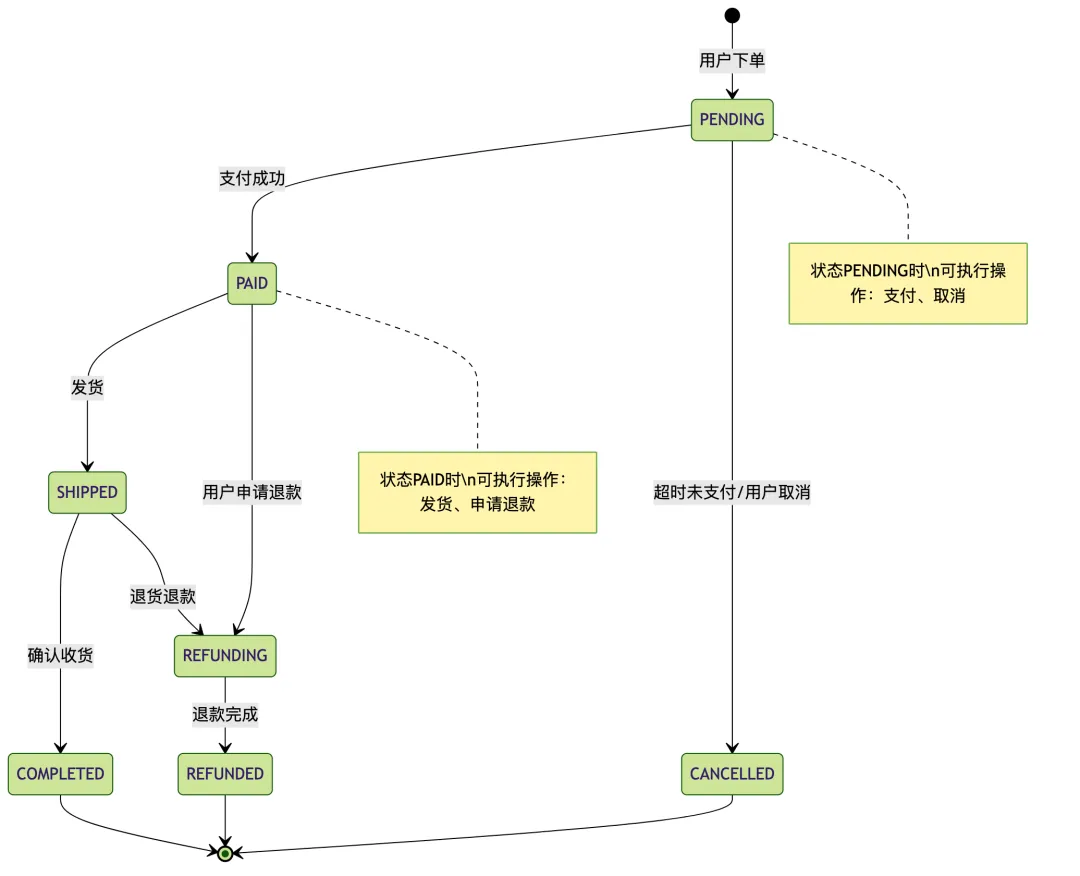
## 3. 订单状态流转(从代码中逆向推导)
pending → paid → shipped → completed
pending → cancelled
paid → refunding → refunded
## 4. 折扣计算逻辑(散落在多处)
- 新用户首单折扣:在 orderService.create() 中
- 满减活动:在 orderService.calculateDiscount() 中
- 优惠券:在 orderService.applyCoupon() 中
- 会员折扣:在 userService.getUserDiscount() 中
## 5. 发现问题
⚠️ 订单导出功能未实现(本次需求目标)
⚠️ 折扣逻辑分散在4个不同文件中,维护困难
⚠️ 无单元测试覆盖
⚠️ 状态流转无统一校验
2.2 生成"宪法(Constitution)"文档
/opsx:explore 输出的分析报告是宪法文档的原始素材,但格式较为松散。开发者需要人工整理这份报告,将其提炼为结构化的 Constitution 文档(即 project.md)——定义项目的"生存边界",包括技术栈、架构模式、编码规范、数据模型约束等。
操作方式:可以直接让AI基于分析报告生成宪法文档初稿:
请基于 architecture-analysis.md 的内容,帮我生成一份结构化的 Constitution 文档(project.md),
包含:项目概述、技术栈、架构模式、编码规范、数据模型约束、API规范、状态枚举定义。
AI会生成初稿,你再结合团队经验进行人工补充和确认。
# Constitution:电商订单系统架构宪法
## 一、项目概述
- 项目名称:E-Commerce Order System
- 技术栈:Node.js 18 + Express 4 + MongoDB 6 + Mongoose 7
- 架构模式:分层架构(Controller → Service → Model)
## 二、现有架构约束
### 2.1 分层规范
- Controller层:只负责请求解析和响应格式化,**禁止**包含业务逻辑
- Service层:包含所有业务逻辑,**禁止**直接操作HTTP对象
- Model层:定义数据模型,**禁止**包含业务逻辑
> ⚠️ **现状偏差**:当前order.js控制器包含大量业务逻辑(3200行),需在后续迭代中逐步拆分
### 2.2 数据模型规范
- 所有模型必须包含:id、createdAt、updatedAt
- 软删除:使用deletedAt字段(非物理删除)
- 状态字段:使用String枚举,统一命名规范
### 2.3 API规范
- RESTful风格:GET(查询)、POST(创建)、PUT(更新)、DELETE(删除)
- 响应格式:{ code, message, data }
- 错误码规范:4xx(客户端错误)、5xx(服务端错误)
### 2.4 订单状态枚举
PENDING → 待支付
PAID → 已支付
SHIPPED → 已发货
COMPLETED → 已完成
CANCELLED → 已取消
REFUNDING → 退款中
REFUNDED → 已退款
### 2.5 折扣计算规则(从代码中提取)
| 条件 | 折扣类型 | 优先级 |
|------|---------|--------|
| 新用户首单 | 固定折扣15% | 高 |
| 会员等级(VIP) | 额外5% | 中 |
| 满减活动(满500减50) | 固定减免 | 中 |
| 优惠券 | 自定义 | 低 |
**规则**:多个折扣可叠加,但最终折扣金额不能超过订单总额的50%
💡 为什么需要人工整理? AI的分析可能遗漏某些隐式规则(如"VIP会员折扣不与新用户首单折扣叠加"这类业务潜规则),需要开发者结合团队经验进行补充和确认。
保存宪法文档:确认无误后,让AI将内容保存到 openspec/project.md。
2.3 隐性知识显式化:用 /opsx:explore 定向提取
除了全面的架构分析,你还可以用 /opsx:explore定向提取特定领域的知识。
提取状态流转规则:
/opsx:explore 请从代码中提取订单状态流转的所有规则:
1. 找出所有订单状态的定义和枚举值
2. 追踪状态变更的所有触发点(支付、发货、退款等)
3. 绘制完整的状态流转图
AI会追踪代码中的状态变更逻辑,输出状态流转图:
保存提取结果:同样,直接让AI将输出保存到文件:
请将上面的状态流转图和规则保存到 openspec/explorations/state-machine.md
提取折扣计算逻辑:
/opsx:explore 请分析订单折扣计算逻辑:
1. 找出所有涉及折扣计算的代码位置
2. 提取每种折扣的触发条件和计算公式
3. 整理为决策表格式
AI会输出结构化的决策表:
请将上面的折扣规则保存到 openspec/explorations/discount-rules.md
💡 人工确认环节:AI提取的结果需要人工验证——状态流转是否完整?有无遗漏的分支?折扣规则是否准确?是否存在AI无法理解的业务"潜规则"?
三、规范编写(棕地版)
3.1 棕地规范的特殊要求
与绿地项目不同,棕地项目的规范编写有三个特殊要求:
- 确认现有基础结构
:新功能必须与现有架构兼容 - 明确集成点
:规范必须说明新功能如何与现有系统对接 - 兼容性考量
:不能破坏现有功能,需明确回滚方案
3.2 完整流程:从探索到提案
在棕地项目中创建新功能规范,需要遵循 "先探索,后提案" 的完整流程:

第一步:执行 /opsx:explore 探索新功能的集成方案
在创建正式提案之前,先用 /opsx:explore 探索新功能如何融入现有系统:
/opsx:explore 我需要在订单模块增加Excel导出功能。
请分析:
1. 现有订单查询服务的接口和用法
2. 现有文件存储服务的接口
3. 推荐的技术方案(Excel生成库、异步任务方案)
4. 可能的风险点和兼容性问题
AI会基于已有代码库分析,输出一份技术探索报告。同样,让AI保存到文件:
请将上面的探索报告保存到 openspec/explorations/order-export-exploration.md
报告包含:
现有订单查询服务( orderService.find())的接口定义和用法现有文件存储服务( fileService.uploadAndGetUrl())的接口技术选型建议(如:ExcelJS vs xlsx库的对比) 风险点识别(如:大文件导出可能导致内存溢出)
第二步:人工确认探索结果
审阅AI的探索报告,确认:
技术方案是否合理? 集成的关键决策点是否已确定? 是否有遗漏的风险点?
第三步:执行 /opsx:propose 生成规范制品
确认探索结果后,执行 /opsx:propose 命令:
/opsx:propose add-order-export
OpenSpec会自动生成四个制品文件:
openspec/changes/add-order-export/
├── proposal.md # 变更动机与目标
├── design.md # 技术设计方案(含集成方案、风险识别)
├── tasks.md # 实施任务清单
└── specs/
└── order-export/
└── spec.md # Delta规范(## ADDED / ## MODIFIED / ## REMOVED)
proposal.md —— 变更动机
# Proposal: 订单Excel导出功能
## Why
当前订单管理后台缺乏数据导出能力,运营团队需要手动复制数据到Excel,
耗时且易出错。
## What Changes
- 新增订单Excel导出功能
- 支持按时间范围、状态筛选
- 异步导出,完成后消息通知
## Impact
- 新增模块:ExportService、ExportController、ExportTask模型
- 复用:orderService.find()、fileService.uploadAndGetUrl()
- 无破坏性变更
spec.md —— Delta规范(棕地版核心)
棕地项目的规范使用 Delta格式——## ADDED 声明新增、## MODIFIED 声明修改、## REMOVED 声明删除:
# Order Export Specification
## ADDED Requirements
### Requirement: 订单Excel导出
系统SHALL支持运营人员按条件导出订单数据为Excel文件。
#### Scenario: 按时间范围导出
- **WHEN** 运营人员提交导出请求(startDate=2026-01-01, endDate=2026-06-30)
- **THEN** 系统异步生成Excel文件
- **AND** 文件包含订单号、用户名、手机号、商品清单、订单总额、折扣金额、实付金额、状态、下单时间
- **AND** 导出完成后通过消息通知用户
#### Scenario: 大文件导出(超过1万条)
- **WHEN** 导出订单数量超过10,000条
- **THEN** 系统采用流式写入,避免内存溢出
- **AND** 导出任务状态显示进度
## MODIFIED Requirements
(本次无修改)
## REMOVED Requirements
(本次无删除)
design.md —— 技术设计方案
/opsx:propose 会自动继承你在 /opsx:explore 阶段确认的所有信息:
# Design: 订单Excel导出功能
## Context
现有电商订单系统(Node.js + Express + MongoDB),需在订单模块增加导出能力。
## Goals / Non-Goals
- Goals: 支持按条件导出Excel、异步导出、大文件支持
- Non-Goals: 不支持实时导出、不支持自定义列
## Decisions
- Excel库:ExcelJS(支持流式写入)
- 异步方案:Bull队列(复用现有Redis)
- 导出限制:单次最多10万条
## Integration Points
| 集成点 | 现有组件 | 交互方式 |
|--------|---------|---------|
| 数据查询 | Order Service | 复用 orderService.find() |
| 文件存储 | File Service | 复用 fileService.uploadAndGetUrl() |
| 认证鉴权 | Auth Middleware | 复用JWT验证 |
## Risks / Trade-offs
| 风险 | 缓解措施 |
|------|---------|
| 大文件内存溢出 | 流式写入 + 分页查询 |
| 导出阻塞主线程 | 异步队列 |
| 并发导出过多 | 限制并发数(最多5个) |
💡 关键优势:你不需要一次性写清楚整个系统。改
order-export就写order-export的delta,改payment就写payment的delta。规范库是逐渐长出来的。
第四步:人工审阅制品
生成完成后,人工审阅这四个文件:
需求是否完整、准确? 设计决策是否合理? 边界情况是否覆盖? 集成点是否全部识别?
在这个阶段修改成本最低——改几行markdown比改代码快得多。
四、计划制定(棕地版)
/opsx:propose 自动生成的 tasks.md 就是实施任务清单,AI将严格按照它逐条执行:
# Tasks: 订单Excel导出功能
## Phase 1: 数据模型
- [ ] 1.1 创建ExportTask模型(记录导出任务状态)
- [ ] 1.2 执行数据库迁移
## Phase 2: 核心服务
- [ ] 2.1 实现ExportService.exportOrders()
- [ ] 2.2 实现Excel生成器(流式写入)
- [ ] 2.3 集成Bull队列(异步任务)
## Phase 3: 控制器与路由
- [ ] 3.1 实现ExportController
- [ ] 3.2 注册导出路由(POST /api/orders/export)
## Phase 4: 测试与验收
- [ ] 4.1 单元测试
- [ ] 4.2 集成测试(端到端验证)
新功能如何融入现有系统?架构图清晰地展示了集成点:
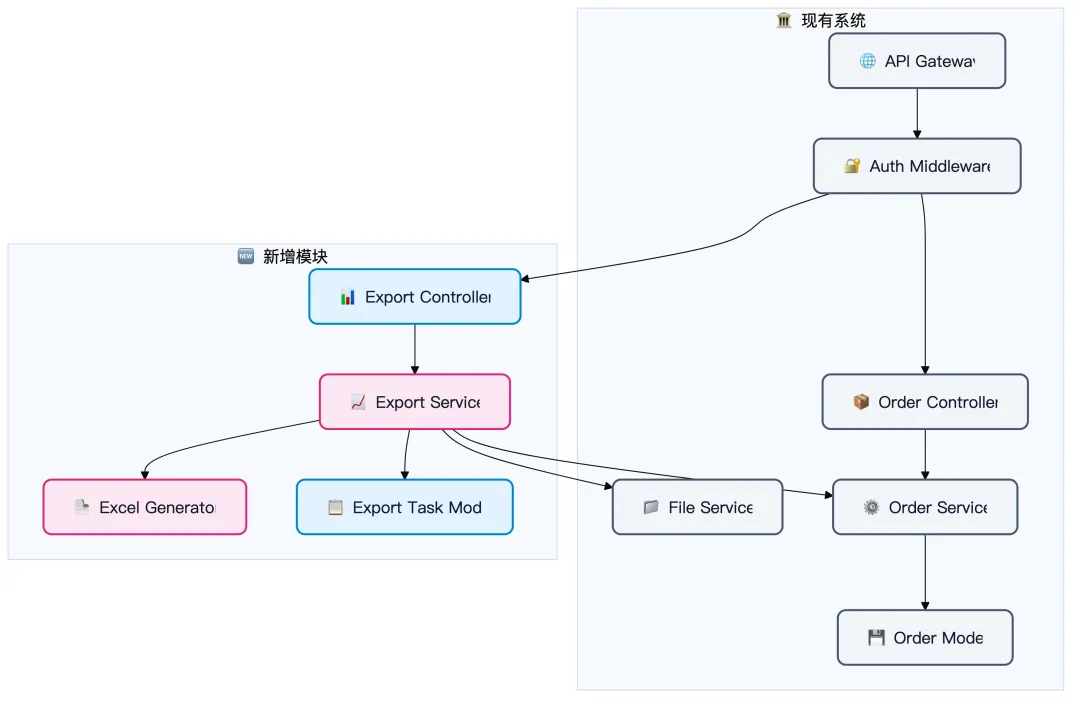
集成点说明:
orderService.find() | |||
fileService.uploadAndGetUrl() | |||
风险识别与兼容性考量:
五、渐进式引入策略
5.1 从单功能开始试点
棕地项目引入SDD,最忌讳一开始就铺开。正确的做法是选择一个小而独立的功能作为试点。
本次"订单Excel导出"功能就是一个理想的试点:
✅ 功能边界清晰(独立的导出模块) ✅ 不修改现有核心逻辑 ✅ 业务价值明确(运营团队迫切需要) ✅ 风险可控(可随时回滚)
5.2 分阶段扩大覆盖

阶段一(第1-2周):试点验证
选择一个独立功能(如订单导出) 完整走通SDD流程: /opsx:explore→ 人工确认 →/opsx:propose→/opsx:apply→/opsx:archive复盘总结经验教训
阶段二(第3-4周):扩展至相关模块
将SDD推广到支付、退款等相邻模块 团队开始熟悉SDD工作流
阶段三(第5-8周):覆盖核心流程
对核心订单流程进行SDD改造 建立完整的规范库
阶段四(第9周起):制度化
将SDD纳入CI/CD流程 所有新功能默认采用SDD 团队培训与知识沉淀
5.3 团队习惯培养
引入SDD不仅是技术变革,更是文化变革。以下是几条关键建议:
- 规范先行,而非"文档后补"
:改变"先写代码再补文档"的习惯 - 规范即代码
:规范与代码一起版本控制、一起Code Review - 渐进式改进
:不追求一次性完美规范,允许规范随代码演进 - AI是协作者
:开发者定义"做什么",AI负责"怎么做"
六、棕地SDD的完整命令流程总结
/opsx:explore | openspec/explorations/architecture-analysis.md | ||
openspec/project.md | |||
/opsx:explore | openspec/explorations/state-machine.mddiscount-rules.md | ||
/opsx:explore | openspec/explorations/order-export-exploration.md | ||
/opsx:propose | proposal.mdspec.md / design.md / tasks.md | ||
/opsx:apply | |||
/opsx:archive |
七、常见坑点与应对
| 逆向工程不充分 | /opsx:explore 全面扫描 | ||
| 跳过explore直接propose | 必须先 explore 再 propose | ||
| 探索结果未保存 | 每次explore后立即保存到文件 | ||
| 规范过于理想化 | |||
| 集成点遗漏 | design.md 中列出所有集成点 | ||
| 规范与代码脱节 | |||
| 一次性改太多 |
八、本章小结
本章我们完整走通了棕地项目引入SDD的全流程:
棕地挑战:文档断层、技术债堆积、新人诅咒、意图漂移——存量系统需要SDD比新项目更迫切。
逆向工程:使用
/opsx:explore让AI全面扫描代码库,生成架构分析报告,直接让AI将报告保存到文件;基于分析结果人工整理宪法文档(project.md),记录现有架构模式、编码规范和约束条件。隐性知识显式化:使用
/opsx:explore定向提取状态流转图、折扣计算决策表、API清单——每次提取后保存到独立的探索报告文件,让"只存在于老员工脑子里"的知识变成机器可读的规范。棕地规范编写:采用 先 explore 后 propose 的完整流程——先用
/opsx:explore探索集成方案并保存报告,人工确认后,再用/opsx:propose生成 Delta 规范(## ADDED/## MODIFIED/## REMOVED)。改哪写哪,不改不动。集成方案设计:
/opsx:propose自动生成的design.md明确新功能与现有系统的集成点,识别风险并制定缓解措施。渐进式引入:遵循 "绞杀者模式"——从单功能试点开始,分阶段扩大覆盖,最终制度化。
核心心法:
棕地SDD =
/opsx:explore(逆向提取现状→保存文件) + 人工确认 +/opsx:propose(Delta增量规范) + 绞杀者模式(渐进替换)
老项目改造不需要推倒重来。改哪写哪,不改不动——规范库随每次改动渐进生长。几个月后,你会发现项目不仅有了一整套活文档,更重要的是,AI能在规范的约束下安全地修改代码,而不会破坏你花了三年才建成的业务逻辑。
下一章,我们将进入 SDD工具组合实战——看看轻量组合、标准组合和企业级组合分别适合什么场景,以及如何根据你的团队规模选择最合适的搭配。
📌 系列预告
- 第5章
:个人开发者的SDD最佳拍档:OpenSpec + 你手边的任何AI(SDD轻量组合) - 第6章
:谁写规范?谁控流程?谁写代码?——SDD标准组合"三驾马车"的分工艺术 - 第7章
:从"完成项目"到"沉淀能力":企业级SDD组合的复利之道
如果你觉得这篇文章有帮助,别忘了点个关注。文末有合集目录,可以回顾本系列的前四篇文章,也欢迎持续关注后续更新!
