夜雨聆风
夜雨聆风业务场景
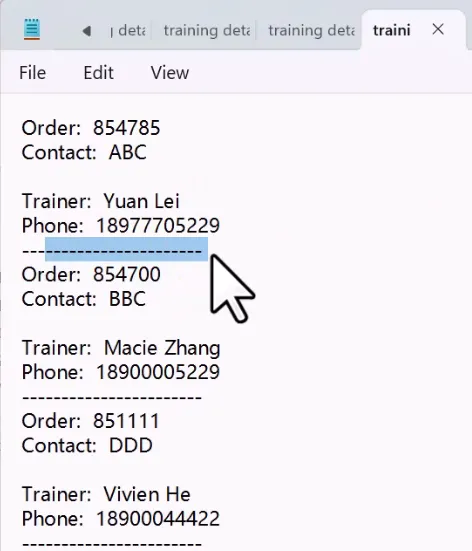
日常接收的单据、订单PDF没有标准结构化表格,仅文字固定排版分布,包含订单号、联系人、人员、电话等关键信息;无法直接使用提取表格功能,人工复制摘抄效率低。可通过PAD提取全文文本,搭配文本拆分、截取动作提取关键字段,导出文本文件,后续还能结合Excel/Power Query做精细化数据整理。

一、两种无表格PDF数据提取方案
- Extract Text提取全文法(本节课重点)
适用:PDF页面文字位置、关键字(order number、trainer等)固定,排版有统一规律,文档复杂度较低;提取全文后拆分截取字段,可配合Power Query二次清洗数据。 - OCR识别方案
适用:扫描件图片类PDF;通过识别固定标识文字定位,再偏移抓取对应数值。
二、Extract Text完整实操流程
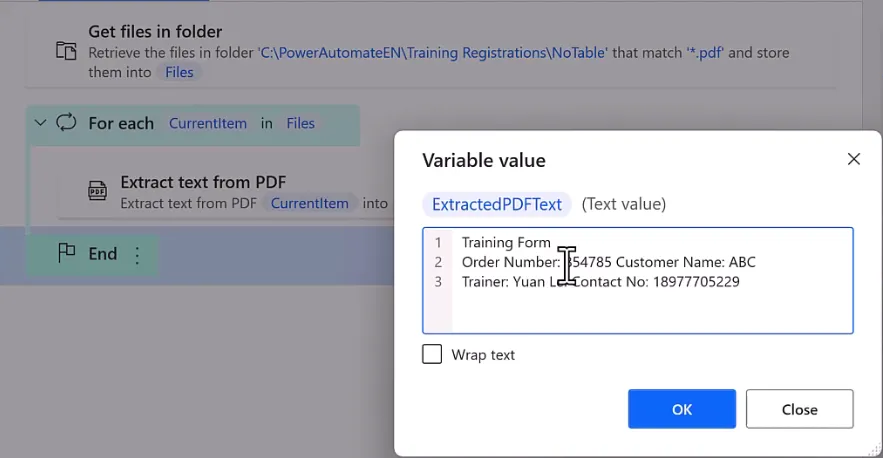
循环遍历目标PDF文件,使用 Extract text from PDF提取PDF全部文字内容;文本拆分处理:
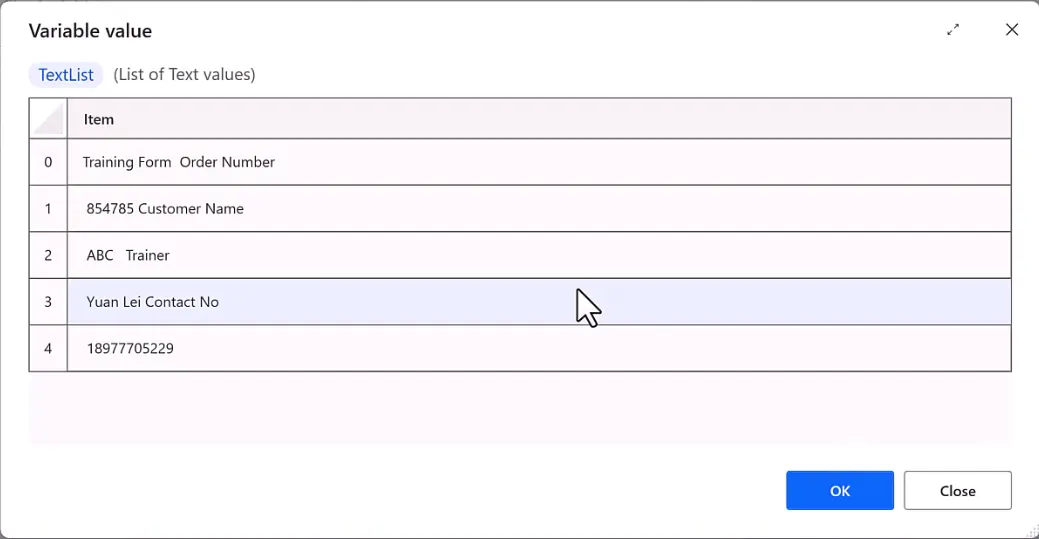
Split Text:按冒号、空格等分隔符把文本拆分为列表List; 文本截取动作(Crop Text):提取指定标识前/后的内容,精准抓取订单号、手机号等目标数据; 通过列表下标 [1][2][3][4]分别取出多条关键字段;
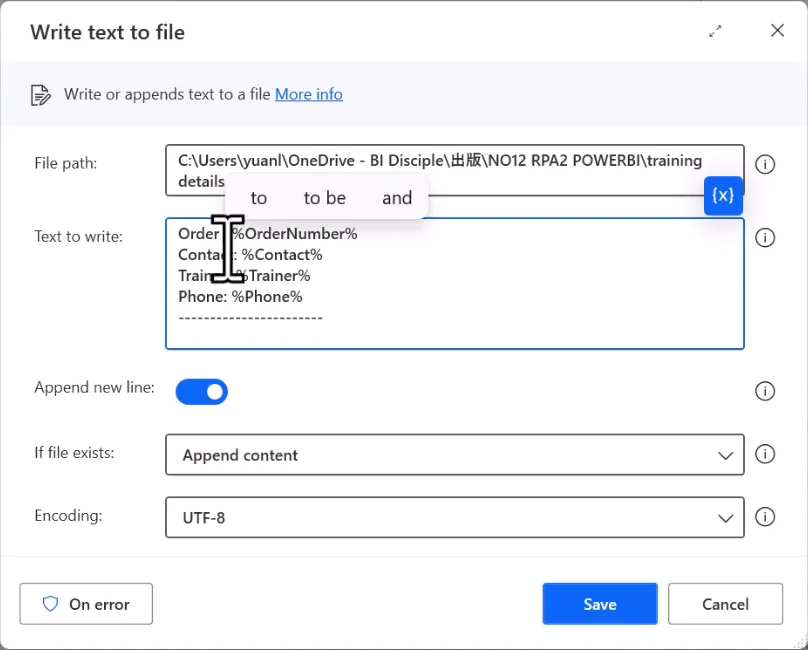
文本输出:使用 Write text to file将提取的多组字段拼接写入TXT文档;
支持追加写入(append)/覆盖(overwrite); 编码选择UTF-8,避免中文乱码。
三、PAD文本处理工具局限
Split Text仅能简单按符号拆分,无法像Excel/Power Query灵活分层清洗; 文本含连续空格、换行、特殊隐藏符号时,直接拆分容易错位,需要多次调整截取规则; 不能直接分列写入表格,提取结果一般先输出TXT,再导入PQ做二次整理。
四、实操关键技巧
空格拆分语法: %' '%,用百分号包裹单引号空格识别分隔符;利用固定关键字(customer、trainer、contact)作为截取边界,分离标签与对应数值; 多份PDF循环执行,数据自动追加至同一个文本文件统一汇总; 文本中多余换行、空格属于小瑕疵,可在Power Query批量清理。