 夜雨聆风
夜雨聆风事情的起点很简单:我想找一个技术参数。

那个参数在某份 PDF 里,那份 PDF 在某次项目交付的附件里。但我不记得 PDF 叫什么名字,也不记得它存在哪个盘。最后在搜索引擎里用关键词翻了 20 分钟,在第三个搜索结果里找到了那份 PDF 的标题,然后才在自己的硬盘上搜到了它。
搜索引擎比我自己的文件系统更清楚我的文件在哪。这事让我很不舒服。
试过手工整理,两周就崩了

我的工作文档大概有 8000 多个。散在本地硬盘、同步盘、U 盘、公司 Wiki、邮件附件里。同一个文件经常有 5 个版本——最终版.docx 旁边躺着 最终版(2).docx 和 最终版-真正最终.docx,三个文件的 MD5 还不一样,打开一看改了一个标点。
花过一个周末手工整理。建了目录结构,分了类,清了一堆重复文件。那两天特别有成就感。然后过了两周——新文件进来了,老文件被改了,目录又乱了。那感觉就像刚大扫除完的房子,还没住热乎就被人进来翻了个底朝天。
后来就放弃了。维护成本太高,整理完的那一瞬间是清爽的,然后熵就开始增加。
自己摸出来的五轮查重法
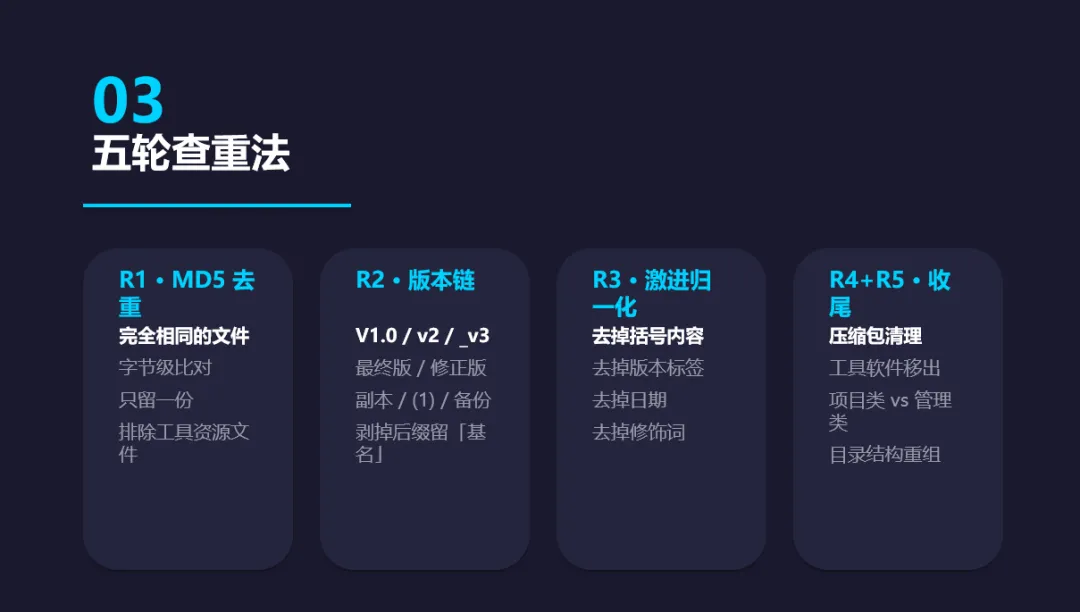
后来实在受不了了,决定认真搞一次。这回我不搞手工了——我写脚本。
第一轮最简单:扫 MD5。完全相同的文件只留一份。一下就清掉不少。
第二轮复杂一点:按文件名找版本链。V1.0、v2、_v3、最终版、修正版、定稿版、副本、(1)——这些后缀我都见过。写正则把版本号、日期、修饰词全剥掉,剩一个"基名",同基名的文件只保留最新的那个。
第三轮更激进:文件名归一化。有的文件叫 (最新)某某系统方案【改后2】,括号里套方括号,把括号内容和版本标签全去掉之后发现跟另一个文件是同一份东西。这一轮又清掉一堆。
第四轮扫压缩包。同目录下已经有解压出来的文件夹了,压缩包就别占地方了。还有一些 Axure安装包.rar、某某工具.iso 之类的——这些东西不是工作文档,移走。
第五轮把剩下的文件归成两类:项目类(某个项目的完整交付件)和管理类(跨项目的重复性产物,比如周报、考核表、竞品分析)。具体的子分类按实际情况来。
五轮搞完,8000 多个文件活下来不到一半。剩下的全是被版本迭代和各种副本吃掉的空间。

这套查重方法是我自己一边清一边总结出来的。搞完之后我把整个经验讲给了 Reasonix(我用的 AI 助手),让它帮我总结成了一套标准的查重 Skill。反过来想挺有意思——不是 AI 教我怎么整理,是我把整理方法教给了 AI,让它以后能帮别人做同样的事。
后面的事:Karpathy 的思路
文件是干净了,但如果只是干净地堆在那儿,要查一个技术细节还是得翻半天。我需要的是知识库,不是文件柜。

大概在这个时候读到了 Andrej Karpathy 写的 LLM WIKI。他的想法很直接:
LLM 负责编写和维护知识库,人类负责阅读和提问。
我之前是"人整理好了存着,需要的时候自己翻"。他的思路是反过来——AI 来读、理解、融合、写文章,人只管提问。
方向我认同。但把这个方向走通,中间还是踩了几个坑。
PDF 转成文字,离知识还差十万八千里
市面上有个工具叫 markitdown,微软出的,PDF、DOCX、PPTX、XLSX 各种格式都能转 Markdown。很好用。但转出来的东西就是一大坨文字——没有结构,没有重点,50 页的技术方案变成 50 页的纯文本。
一开始我也犯了这个错,以为"转了就是提了"。后来发现这种 dump 堆在知识库里跟没堆一样,查询的时候根本翻不到有用的东西。
后来定了规矩:markitdown 只负责格式转换,输出是中间产物。真正的理解和重组在后面。
AI 写文章也会摸鱼
把 MD 丢给 LLM,让它读、理解、写融合文章。它经常干一件事:给你一个文件清单,标题写成"项目概述"。
比如一个目录里有 5 个 PDF 和 3 个 DOCX,它返回:
"本项目包含以下文档:技术方案.pdf、接口规格.docx、测试报告.pdf..."
看着像文章,实际零信息。问它"这个系统用的什么架构"——说不出来。因为它根本没读文件内容,只读了文件名。
我加了一个硬性标准:每篇文章必须能通过"镜像地球测试"——一个没见过原始材料的 AI 能不能仅凭这篇文章理解这个系统的背景、架构、模块设计和关键参数?通不过就打回去重写。
这个标准的好处是双向的:LLM 自己最清楚 AI 需要什么格式的信息,所以拿这个当写作标准,它写出来的东西比随便总结要好得多。
知识库不过期才是真本事
一开始以为建知识库是一次性工程,跑完就完了。
过了一段时间发现不对。新文件不停进来,旧文件有了新理解,不同文章之间还慢慢出现了互相矛盾的说法。大概三个月不碰,知识库就开始不可信了。
加了两件事。Query——让 AI 理解你的问题之后去翻知识库,不是简单关键词匹配。Lint——自动检查有没有断链、索引漏了新文章、两篇文章对同一件事说法矛盾。自动能修的修,修不了的列出来。
输出格式也不是小事
十几篇文章的时候,一个文件夹够了。50 篇以上就需要分组、排序、筛选。再往上,需要一张图来看文章之间的引用关系。
所以最后一步是按 Obsidian 标准格式化:frontmatter 元数据、wikilinks 内部链接、callouts 高亮关键信息、Base 数据库视图做多维度浏览、Canvas 知识图谱看全局结构。不是非得用 Obsidian,但这几种组织能力是知识库上规模之后绕不开的。
跑出来的结果
在自己的项目群上跑完了完整流程:21 个项目,8000 多份原始文件,将近 300 篇结构化文章。核心系统的产品规格覆盖比较完整,项目文章深不深直接取决于原始材料厚不厚——有两三个薄 PDF 的项目,AI 确实编不出花来。
整套东西开源在 GitHub:
github.com/CS-Faith/llm-wiki-pipeline
9 个 Skill 文件,覆盖查重、转换、融合、Obsidian 输出、持续维护五个阶段。MIT。
最早那套查重方法也在里面,就是 knowledge-cleanup。我自己摸出来的,让 AI 帮我总结成型的。后面的融合、Obsidian 化、维护也是边用边补。如果你也有"文件能搜到但找不到"的困境,可以试一下。
