





















文档内容
专题 18 统计与成对数据的统计分析
(思维构建+知识盘点+重点突破+方法技巧+易混易错)
知识点1 随机抽样
1、抽样调查
(1)总体:统计中所考察对象的某一数值指标的全体构成的集合称为总体.
(2)个体:构成总体的每一个元素叫做个体.
(3)样本:从总体中抽取若干个个体进行考察,这若干个个体所构成的集合叫做总体的一个样本,样本
中个体的数目叫做样本容量.
2、简单随机抽样
(1)定义:一般地,设一个总体含有 个个体,从中逐个不放回地抽取 个个体作为样本( ),如
果每次抽取时总体内的各个个体被抽到的机会都相等,就把这种抽样方法叫做简单随机抽样.这样抽取的
样本,叫做简单随机样本.
(2)两种常用的简单随机抽样方法
①抽签法:一般地,抽签法就是把总体中的 个个体编号,把号码写在号签上,将号签放在一个容器
中,搅拌均匀后,每次从中抽取一个号签,连续抽取 次,就得到一个容量为 的样本.适用于总体个数
较少的情况。
②随机数法:即利用随机数表、随机数骰子或计算机产生的随机数进行抽样.这里仅介绍随机数表法.
随机数表由数字 , , ,…, 组成,并且每个数字在表中各个位置出现的机会都是一样的.适用于总
体个数较多的情况,但是当总体容量很大时,需要的样本容量也很大时,利用随机数法抽取样本仍不方便.(3)简单随机抽样的特征(只有四个特点都满足的抽样才是简单随机抽样)
①有限性:简单随机抽样要求被抽取的样本的总体个数是有限的,便于通过样本对总体进行分析.
②逐一性:简单随机抽样是从总体中逐个地进行抽取,便于实践中操作.
③不放回性:简单随机抽样是一种不放回抽样,便于进行有关的分析和计算.
④等可能性:简单单随机抽样中各个个体被抽到的机会都相等,从而保证了抽样方法的公平.
3、分层抽样
(1)定义:一般地,在抽样时,将总体分成互不交叉的层,然后按照一定的比例,从各层独立地抽取一
定数量的个体,将各层取出的个体合在一起作为样本,这种抽样方法叫做分层抽样.
分层抽样适用于已知总体是由差异明显的几部分组成的.
(2)分层抽样问题类型及解题思路
①求某层应抽个体数量:按该层所占总体的比例计算.
②已知某层个体数量,求总体容量或反之求解:根据分层抽样就是按比例抽样,列比例式进行计算.
③分层抽样的计算应根据抽样比构造方程求解,其中“抽样比==”
【注意】分层抽样时,每层抽取的个体可以不一样多,但必须满足抽取 ( )个个体
(其中 是层数, 是抽取的样本容量, 是第 层中个体的个数, 是总体容量).
知识点2 用样本估计总体
1、频率分布直方图
(1)频率、频数、样本容量的计算方法
①×组距=频率.
②=频率,=样本容量,样本容量×频率=频数.
③频率分布直方图中各个小方形的面积总和等于 .
(2)频率分布直方图中数字特征的计算
①最高的小长方形底边中点的横坐标即是众数.
②中位数左边和右边的小长方形的面积和是相等的.设中位数为 ,利用 左(右)侧矩形面积之和
等于 ,即可求出 .
③平均数是频率分布直方图的“重心”,等于频率分布直方图中每个小长方形的面积乘以小长方形
底边中点的横坐标之和,即有 ,其中 为每个小长方形底边的中点, 为每个小
长方形的面积.
2、百分位数
(1)定义:一组数据的第 百分位数是这样一个值,它使得这组数据中至少有 的数据小于或等于这个
值,且至少有 的数据大于或等于这个值.
(2)计算一组 个数据的的第 百分位数的步骤
①按从小到大排列原始数据.
②计算 .③若 不是整数而大于 的比邻整数 ,则第 百分位数为第 项数据;若 是整数,则第 百分位数
为第 项与第 项数据的平均数.
(3)四分位数:我们之前学过的中位数,相当于是第 百分位数.在实际应用中,除了中位数外,常用
的分位数还有第 百分位数,第 百分位数.这三个分位数把一组由小到大排列后的数据分成四等份,
因此称为四分位数.
3、样本的数字特征
(1)众数、中位数、平均数
①众数:一组数据中出现次数最多的数叫众数,众数反应一组数据的多数水平.
②中位数:将一组数据按大小顺序依次排列,把处在最中间位置的一个数据(或最中间两个数据的平
均数)叫做这组数据的中位数,中位数反应一组数据的中间水平.
③平均数: 个样本数据 的平均数为 ,反应一组数据的平均水平,公式
变形: .
(2)标准差和方差
①标准差:标准差是样本数据到平均数的一种平均距离,一般用 表示.假设样本数据是 ,
表示这组数据的平均数,则标准差 .
②方差:方差就是标准差的平方,即 .显然,在刻画样本数
据的分散程度上,方差与标准差是一样的.在解决实际问题时,多采用标准差.
【注意】标准差、方差描述了一组数据围绕平均数波动程度的大小.标准差、方差越大,则数据的离散程
度越大;标准差、方差越小,数据的离散程度越小.反之亦可由离散程度的大小推算标准差、方差的大小.
③平均数、方差的性质:如果数据 的平均数为 ,方差为 ,那么
一组新数据 的平均数为 ,方差是 .
一新数据 的平均数为 ,方差是 .
一组新数据 的平均数为 ,方差是 .
知识点3 成对数据的统计分析
1、两个变量的线性相关
(1)正相关:在散点图中,点散布在从左下角到右上角的区域,对于两个变量的这种相关关系,我们将
它称为正相关.
(2)负相关:在散点图中,点散布在从左上角到右下角的区域,两个变量的这种相关关系称为负相关.
(3)线性相关关系、回归直线:如果散点图中点的分布从整体上看大致在一条直线附近,就称这两个变
量之间具有线性相关关系,这条直线叫做回归直线.
2、回归分析与回归方程(1)回归分析的定义:对具有相关关系的两个变量进行统计分析的一种常用方法.
(2)最小二乘法:使得样本数据的点到回归直线的距离的平方和最小的方法叫做最小二乘法.
(3)回归方程:对于一组具有线性相关关系的数据(x ,y ),(x ,y ),…,(x ,y ),其回归方程
1 1 2 2 n n
的求法为
其中, , ,( , )称为样本点的中心.
(3)相关系数
若相应于变量 的取值 ,变量 的观测值为 ,
则变量 与 的相关系数 ,
通常用 来衡量 与 之间的线性关系的强弱, 的范围为 .
①当 时,表示两个变量正相关;当 时,表示两个变量负相关.
② 越接近 ,表示两个变量的线性相关性越强; 越接近 ,表示两个变量间几乎不存在线性相关
关系.当 时,所有数据点都在一条直线上.
③通常当 时,认为两个变量具有很强的线性相关关系.
3、残差分析
对于预报变量 ,通过观测得到的数据称为观测值 ,通过回归方程得到的 称为预测值,观测值减去预
测值等于残差, 称为相应于点 的残差,即有 .
残差是随机误差的估计结果,通过对残差的分析可以判断模型刻画数据的效果以及判断原始数据中是否存
在可疑数据等,这方面工作称为残差分析.
(1)残差图:通过残差分析,残差点 比较均匀地落在水平的带状区域中,说明选用的模型比较合
适,其中这样的带状区域的宽度越窄,说明模型拟合精确度越高;反之,不合适.
(2)通过残差平方和 分析,如果残差平方和越小,则说明选用的模型的拟合效果越好;反
之,不合适.(3)相关指数:用相关指数来刻画回归的效果,其计算公式是: .
越接近于 ,说明残差的平方和越小,也表示回归的效果越好.
4、独立性检验
(1)分类变量:变量的不同“值”表示个体所属的不同类别,像这类变量称为分类变量.
(2)列联表:
①定义:列出的两个分类变量的频数表称为列联表.
②2×2列联表:假设有两个分类变量X和Y,它们的可能取值分别为{x ,x}和{y ,y},其样本频数
1 2 1 2
列联表(称为2×2列联表)为2×2列联表
总计
总计
(3)独立性检验:计算随机变量 利用 的取值推断分类变量X和Y是否独
立的方法称为χ2独立性检验.
0.10 0.05 0.010 0.005 0.001
2.706 3.841 6.635 7.879 10.828
重难点1 频率分布直方图的计算
1、由频率分布直方图进行相关计算需掌握的2个关系式
(1)×组距=频率.
(2)=频率,此关系式的变形为=样本容量,样本容量×频率=频数.
2、利用频率分布直方图估计样本的数字特征的方法
(1)中位数:在频率分布直方图中,中位数左边和右边的直方图的面积相等,由此可以估计中位数的值.
(2)平均数:平均数的估计值等于每个小矩形的面积乘以矩形底边中点横坐标之和.
(3)众数:最高的矩形的中点的横坐标.
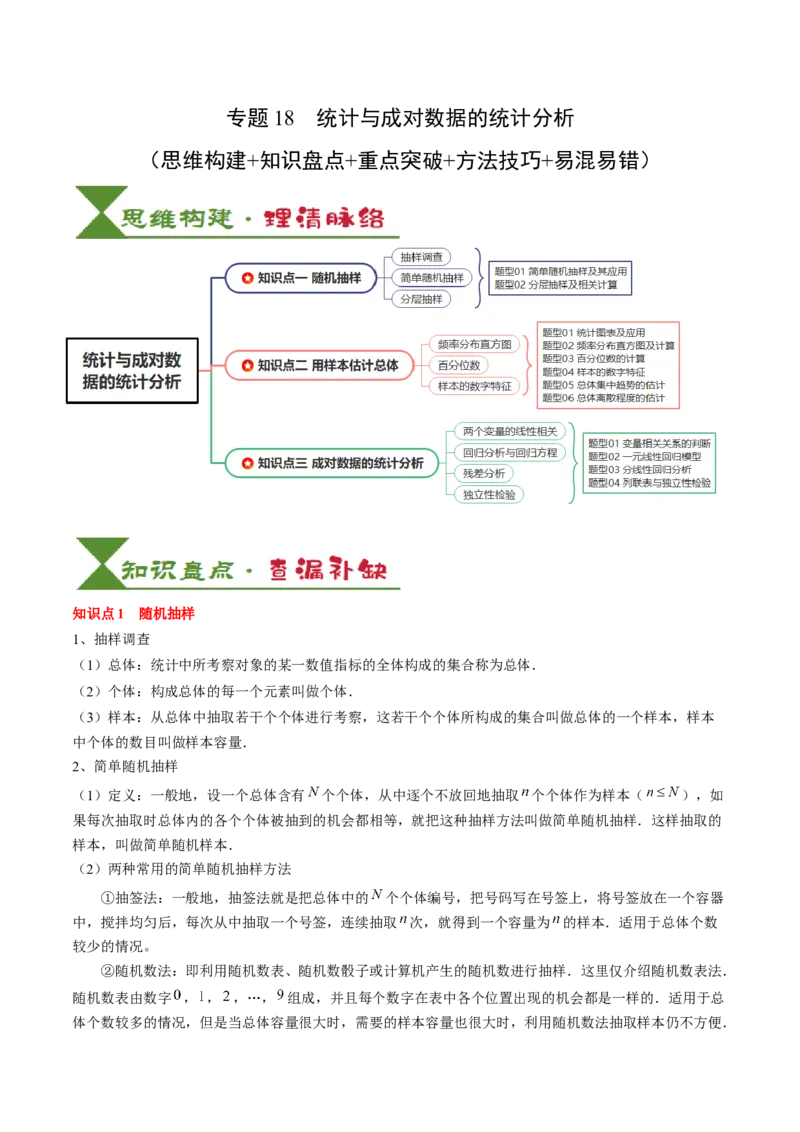
【典例1】(24-25高三上·江西上饶·月考)(多选)某高中举行的纪念红军长征出发90周年的知识答题比
赛,对参赛的2000名考生的成绩进行统计,可得到如图所示的频率分布直方图,若同一组中数据用该组区间中间值作为代表值,则下列说法中正确的是( )
A.参赛成绩的众数约为75分
B.用分层抽样从该校学生中抽取容量为200的样本,则应在 内的成绩抽取30人
C.参赛成绩的第75百分位数约为82.5分
D.参赛成绩的平均分约为72.8分
【答案】AC
【解析】对于A:由频率分布直方图可得众数为 ,故A正确;
对于B:由频率分布直方图可得 内应抽取 人,故B错误;
对于C:分数在 )内的频率为 ,
在 )内的频率为 ,
因此第75百分位数位于[80,90)内,第75百分位数为 ,故C正确;
对于D:平均数为 ,
故D错误.故选:AC.
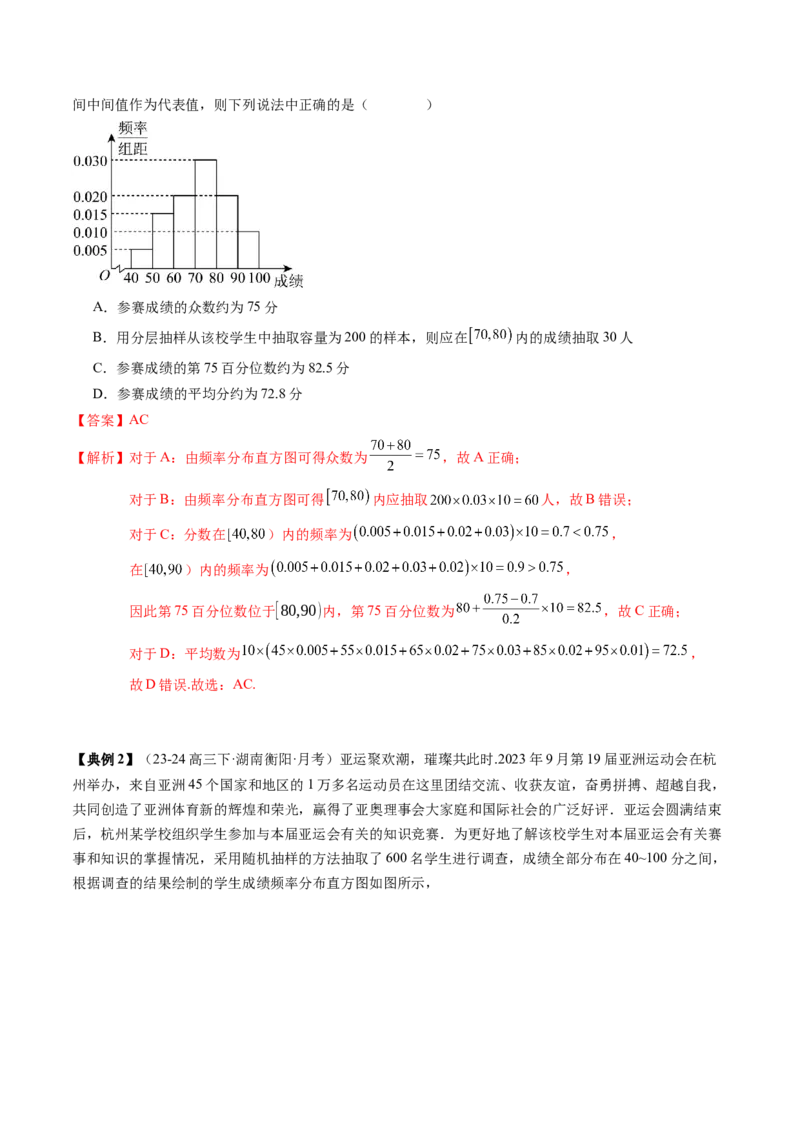
【典例2】(23-24高三下·湖南衡阳·月考)亚运聚欢潮,璀璨共此时.2023年9月第19届亚洲运动会在杭
州举办,来自亚洲45个国家和地区的1万多名运动员在这里团结交流、收获友谊,奋勇拼搏、超越自我,
共同创造了亚洲体育新的辉煌和荣光,赢得了亚奥理事会大家庭和国际社会的广泛好评.亚运会圆满结束
后,杭州某学校组织学生参加与本届亚运会有关的知识竞赛.为更好地了解该校学生对本届亚运会有关赛
事和知识的掌握情况,采用随机抽样的方法抽取了600名学生进行调查,成绩全部分布在40~100分之间,
根据调查的结果绘制的学生成绩频率分布直方图如图所示,(1)求频率分布直方图中 的值;
(2)估计这600名学生成绩的中位数;
(3)根据频率分布直方图,按分层抽样的方法从成绩在 的学生中选取5人,再从这5人中任
意选取2人,求这2人中至少有1人成绩不低于90分的概率.
【答案】(1) ;(2)80;(3)
【解析】(1)由频率分布直方图,得 ,解得 ;
(2)由频率分布直方图,得 ,
,
则估计这600名学生成绩的中位数为80;
(3)由题意得,成绩在 的频率为 ,
成绩在 的频率为 ,频率之比为 ,
所以按分层抽样的方法从中选取5人,成绩在 的学生有2人,分别记为 ,
成绩在 的学生有3人,分别记为 ,
从这5人中任意选取2人,有 ,共10种选法,
其中至少有1人成绩不低于90分的选法有 , ,共9种,
所以这2人中至少有1人成绩不低于90分的概率 .
重难点02 非线性回归分析的求法
(1)根据原始数据作出散点图;
(2)根据散点图选择恰当的拟合函数;
(3)作恰当变换,将其转化成线性函数,求线性回归方程;
(4)在(3)的基础上通过相应变换,即可得非线性回归方程.
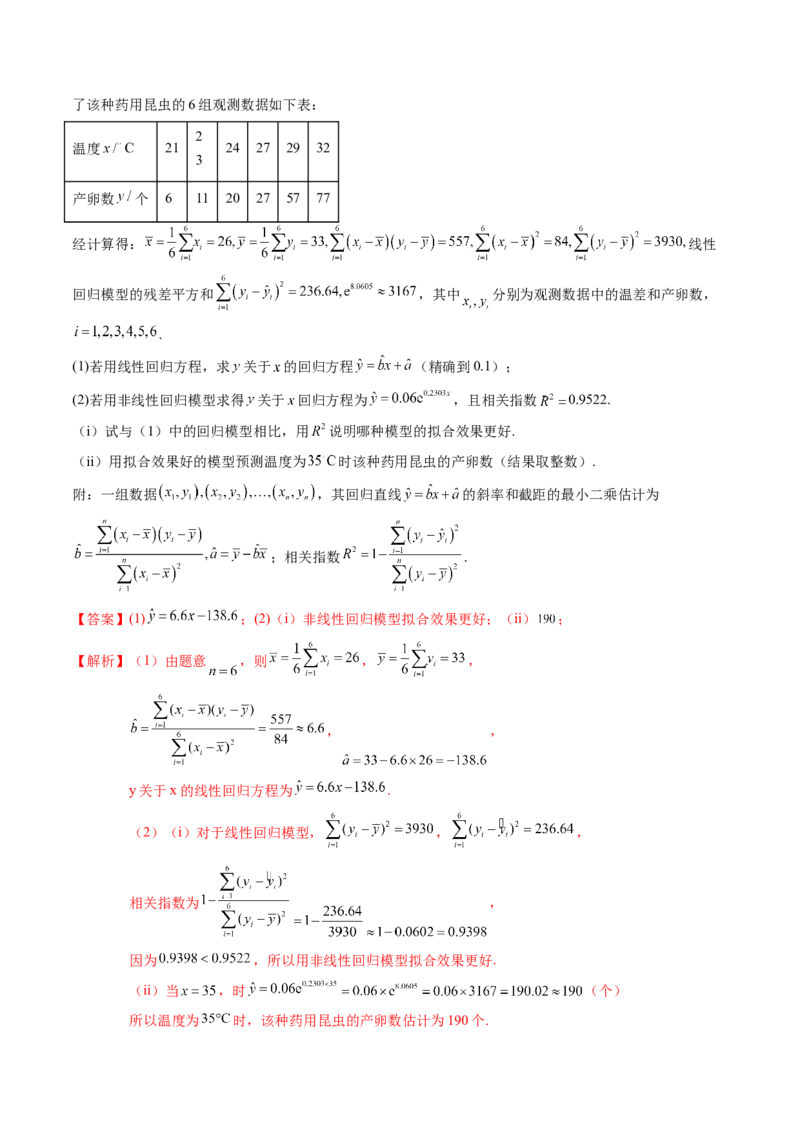
【典例1】(24-25高三上·福建泉州·月考)一只药用昆虫的产卵数 与一定范围内的温度 有关,现收集了该种药用昆虫的6组观测数据如下表:
2
温度 21 24 27 29 32
3
产卵数 个 6 11 20 27 57 77
经计算得: 线性
回归模型的残差平方和 ,其中 分别为观测数据中的温差和产卵数,
.
(1)若用线性回归方程,求 关于 的回归方程 (精确到0.1);
(2)若用非线性回归模型求得 关于 回归方程为 ,且相关指数 0.9522.
(i)试与(1)中的回归模型相比,用 说明哪种模型的拟合效果更好.
(ii)用拟合效果好的模型预测温度为 时该种药用昆虫的产卵数(结果取整数).
附:一组数据 ,其回归直线 的斜率和截距的最小二乘估计为
;相关指数 .
【答案】(1) ;(2)(i)非线性回归模型拟合效果更好;(ii) ;
【解析】(1)由题意 ,则 , ,
, ,
y关于x的线性回归方程为 .
(2)(i)对于线性回归模型, , ,
相关指数为 ,
因为 ,所以用非线性回归模型拟合效果更好.
(ii)当 ,时 (个)
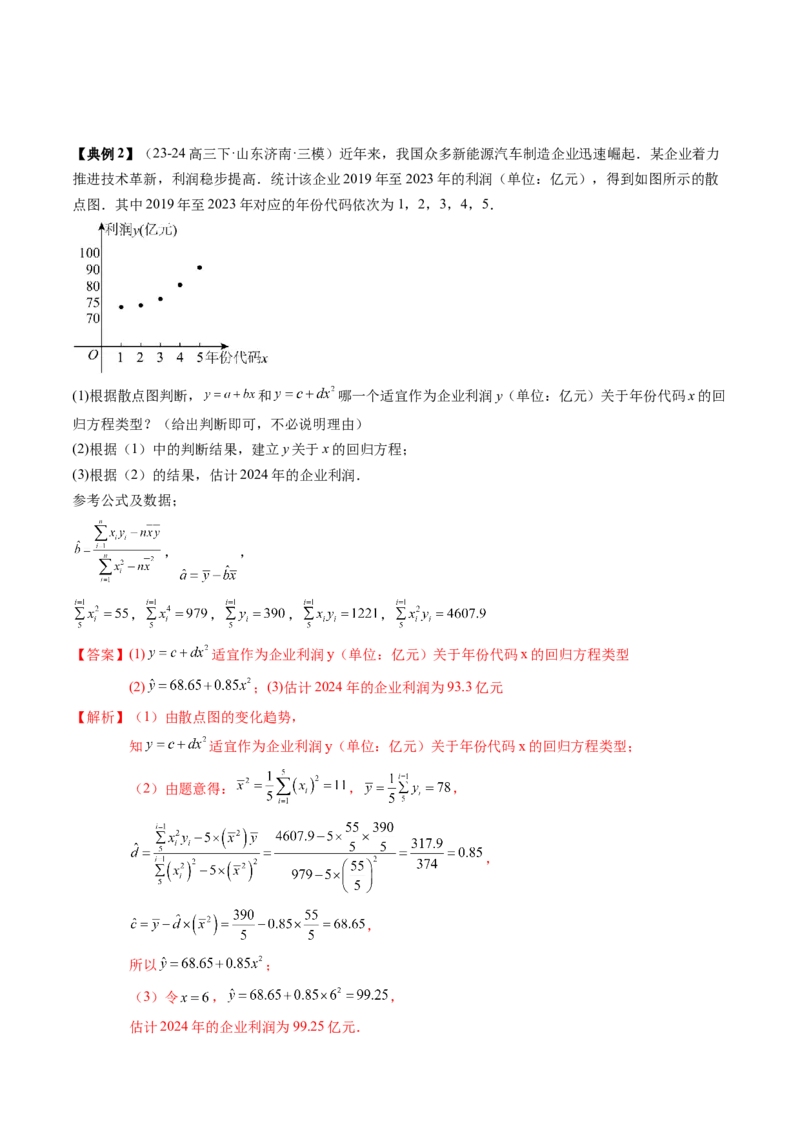
所以温度为 时,该种药用昆虫的产卵数估计为190个.【典例2】(23-24高三下·山东济南·三模)近年来,我国众多新能源汽车制造企业迅速崛起.某企业着力
推进技术革新,利润稳步提高.统计该企业2019年至2023年的利润(单位:亿元),得到如图所示的散
点图.其中2019年至2023年对应的年份代码依次为1,2,3,4,5.
(1)根据散点图判断, 和 哪一个适宜作为企业利润y(单位:亿元)关于年份代码x的回
归方程类型?(给出判断即可,不必说明理由)
(2)根据(1)中的判断结果,建立y关于x的回归方程;
(3)根据(2)的结果,估计2024年的企业利润.
参考公式及数据;
, ,
, , , ,
【答案】(1) 适宜作为企业利润y(单位:亿元)关于年份代码x的回归方程类型
(2) ;(3)估计2024年的企业利润为93.3亿元
【解析】(1)由散点图的变化趋势,
知 适宜作为企业利润y(单位:亿元)关于年份代码x的回归方程类型;
(2)由题意得: , ,
,
,
所以 ;
(3)令 , ,
估计2024年的企业利润为99.25亿元.一、应用随机数表法的两个关键点
1、确定以表中的哪个数(哪行哪列)为起点,以哪个方向为读数的方向;
2、读数时注意结合编号特点进行读取.若编号为两位数字,则两位两位地读取;若编号为三位数字,则
三位三位地读取,有超过总体号码或出现重复号码的数字舍去,这样继续下去,直到获取整个样本.
【典例1】(23-24高三下·陕西西安·一模)某高校对中文系新生进行体测,利用随机数表对650名学生进
行抽样,先将650名学生进行编号,001,002,…,649,650.从中抽取50个样本,下图提供随机数表的
第4行到第6行,若从表中第5行第6列开始向右读取数据,则得到的第6个样本编号是( )
32 21 18 34 29 78 64 54 07 32 52 42 06 44 38 12 23 43 56 77 35 78 90 56 42
84 42 12 53 31 34 57 86 07 36 25 30 07 32 86 23 45 78 89 07 23 68 96 08 04
32 56 78 08 43 67 89 53 55 77 34 89 94 83 75 22 53 55 78 32 45 77 89 23 45
A.623 B.328 C.072 D.457
【答案】A
【解析】从第5行第6列开始向右读取数据,
第一个数为253,第二个数是313,
第三个数是457,下一个数是860,不符合要求,
下一个数是736,不符合要求,下一个是253,重复,
第四个是007,第五个是328,第六个数是623,,故A正确.故选:A.
【典例2】(23-24高三下·云南·二模)本次月考分答题卡的任务由高三16班完成,现从全班55位学生中
利用下面的随机数表抽取10位同学参加,将这55位学生按 进行编号,假设从随机数表第1行
第2个数字开始由左向右依次选取两个数字,重复的跳过,读到行末则从下一行行首继续,则选出来的第
6个号码所对应的学生编号为( )
062
4313 2432 5327 0941 2512 6317 6323 2616 8045 6011
7
141
9577 7424 6762 4281 1457 2042 5332 3732 2707 3607
0
512
5179 3014 2310 2118 2191 3726 3890 0140 0523 2617
4
A.51 B.25 C.32 D.12
【答案】A【解析】依题意,前6个编号依次为:31,32,43,25,12,51,
所以选出来的第6个号码所对应的学生编号为51.故选:A
二、解决分层抽样的常用公式
先确定抽样比,然后把各层个体数乘以抽样比,即得各层要抽取的个体数.
(1)抽样比==;
(2)层1的容量∶层2的容量∶层3的容量=样本中层1的容量∶样本中层2的容量∶样本中层3的容量.
【典例1】(23-24高三下·河南·三模)国内某优秀新能源电池制造企业在锂电池单位能量密度技术上取得
了重大突破,该制造企业内的某车间有两条生产线,分别生产高能量密度锂电池和低能量密度锂电池,总
产量为400个锂电池.质检人员采用分层随机抽样的方法随机抽取了一个容量为80的样本进行质量检测,
已知样本中高能量密度锂电池有35个,则估计低能量密度锂电池的总产量为( ).
A.325个 B.300个 C.225个 D.175个
【答案】C
【解析】根据分层随机抽样可知低能量密度锂电池的产量为 (个).故选:C
【典例2】(23-24高三下·江西南昌·模拟预测)已知 三种不同型号的产品数量之比依次为 ,
现用分层抽样的方法抽取容量为 的样本,若样本中 型号产品有 件,则 为( )
A.60 B.70 C.80 D.90
【答案】B
【解析】因为 三种不同型号的产品数量之比依次为 ,
且用分层抽样的方法抽取一个容量为 的样本,
所以 型号产品被抽的抽样比为: ,
因为 型号产品有 件,所以 ,解得 .故选:B.
三、百分位数的计算
计算一组 个数据的的第 百分位数的步骤
①按从小到大排列原始数据.
②计算 .
③若 不是整数而大于 的比邻整数 ,则第 百分位数为第 项数据;若 是整数,则第 百分位数为第
项与第 项数据的平均数.
【典例1】(24-25高三上·江苏南通·月考)已知一组数据 , , , , 的下四分位数是 ,则 的可能取值为( )
A. B. C. D.
【答案】D
【解析】一共有 个数据, ,
故数据的下四分位数为从数据从小排到大的每2个数据,所以 .故选:D.
【典例2】(24-25高三上·广东·月考)样本数据 的极差和第75百分位数分别为
.
【答案】18,83.5
【解析】将这组数据从小到大排列为:72,74,77,79,80,82,85,90,共8个,
极差为 ,
因为 ,所以这组数据的第75百分位数为 .
故答案为: .
四、用样本的数字特征估计总体的数字特征
利用样本的数字特征解决优化决策问题的依据
(1)平均数反映了数据取值的平均水平;标准差、方差描述了一组数据围绕平均数波动的大小.标准差、
方差越大,数据的离散程度越大,越不稳定;标准差、方差越小,数据的离散程度越小,越稳定.
(2)用样本估计总体就是利用样本的数字特征来描述总体的数字特征.
【典例1】(24-25高三上·江苏·开学摸底)如图,已知某频率分布直方图形成“右拖尾”形态,则下列结
论正确的是( )
A.众数 平均数 中位数 B.众数 中位数 平均数
C.众数 平均数 中位数 D.中位数 平均数 众数
【答案】B
【解析】由频率直方图可得,单峰不对称且“右拖尾”,最高峰偏左,众数最小,
平均数易受极端值的影响,与中位数相比,平均数总是在“拖尾”那边,
故平均数大于中位数,所以众数 中位数 平均数.故选:B
【典例2】(23-24高三下·湖北·模拟预测)(多选)某公司为保证产品生产质量,连续10天监测某种新产品生产线的次品件数,得到关于每天出现的次品的件数的一组样本数据:3,4,3,1,5,3,2,5,1,
3,则关于这组数据的结论正确的是( )
A.极差是4 B.众数小于平均数
C.方差是1.8 D.数据的80%分位数为4
【答案】AC
【解析】数据从小到大排列为1,1,2,3,3,3,3,4,5,5.
对于A,该组数据的极差为 ,故A正确;
对于B,众数为3,平均数为 ,两者相等,故B错误;
对于C,方差为 ,故C正确;
对于D, ,
这组数据的 分位数为第8个数和第9个数的平均数4.5,故D错误.故选:AC.
五、判断相关关系的2种方法
1、散点图法:如果所有的样本点都落在某一函数的曲线附近,变量之间就有相关关系.如果所有的样本
点都落在某一直线附近,变量之间就有线性相关关系;
2、相关系数法:利用相关系数判定,当|r|越趋近于1时,相关性越强
【典例1】(24-25高三上·天津·月考)已知5个成对数据 的散点图如下,若去掉点 ,则下列
说法正确的是( )
A.变量x与变量y呈正相关 B.变量x与变量y的相关性变强
C.残差平方和变大 D.样本相关系数r变大
【答案】B
【解析】由散点图可知,去掉点 后, 与 的线性相关加强,且为负相关,
所以B正确,A错误;
由于 与 的线性相关加强,所以残差平方和变小,所以C错误,
由于 与 的线性相关加强,且为负相关,所以相关系数的绝对值变大,
而相关系数为负的,所以样本相关系数r变小,所以D错误.故选:B.【典例2】(23-24高三上·湖南·月考)某校数学兴趣小组在某座山测得海拔高度 (单位:千米)与气压
(单位:千帕)的六组数据 绘制成如下散点图,分析研究发现 点相关数据不符合实
际,删除 点后重新进行回归分析,则下列说法正确的是( )
A.删除点 后,样本数据的两变量 正相关
B.删除点 后,相关系数 的绝对值更接近于1
C.删除点 后,新样本的残差平方和变大
D.删除点 后,解释变量 与响应变量 相关性变弱
【答案】B
【解析】由题意,
从散点图中可知,删除点 后,样本数据的两变量 负相关,所以 错误;
由于 点较其他点偏离程度大,故去掉 点后,回归效果更好,
从而相关系数 的绝对值更接近于 ,所以B正确;
同理决定系数 越接近于 ,所以新样本的残差平方和变小,所以 错误;
从而解释变量 与响应变量 相关性增强,所以D错误.故选:B.
六、线性回归分析问题的类型及解题方法
1、求回归直线方程
①计算出,,,y或(x-)(y-),(x-)2的值;
i i i i i
②利用公式计算回归系数a,b;
③写出回归直线方程y=bx+a.
2、回归模型的拟合效果:利用相关系数r判断,当|r|越趋近于1时,两变量的线性相关性越强.
【典例1】(24-25高三上·河北沧州·月考)2024年2月初某地骤降大雪,给开车回家过年的人们带来很大
麻烦,地面积雪会影响汽车的行驶安全,车胎凹槽深度是影响汽车刹车的因素,汽车行驶会导致轮胎胎面
磨损.某实验室通过试验测得行驶里程与轮胎凹槽深度成负相关,且相关性较强的数据如下:
行驶里程x/万km 0.00 0.64 1.29 1.93 2.57 3.22 3.86 4.51 5.15
轮胎凹槽深度y/mm 10.02 8.37 7.39 6.48 5.82 5.20 4.55 4.16 3.822.57 6.20 115.10 29.46 25.09
附:经验回归方程 中: , .
(1)求轮胎凹槽深度y与行驶里程x的经验回归方程( 、 计算结果精确到0.01);
(2)若轮胎凹槽的深度小于2.5mm时,需要换轮胎,则预测汽车行驶多少里程就需要换轮胎(计算结果精确
到0.01)?
【答案】(1) ;(2)5.84万km
【解析】(1)由题意得, ,
,
所以经验回归方程为 .
(2)由题意, ,解得 ,
所以当汽车行驶5.84万km时,需要更换轮胎.
【典例2】(23-24高三下·湖北武汉·模拟预测)随着科技发展的日新月异,人工智能融入了各个行业,促
进了社会的快速发展.其中利用人工智能生成的虚拟角色因为拥有更低的人工成本,正逐步取代传统的真人
直播带货.某公司使用虚拟角色直播带货销售金额得到逐步提升,以下为该公司自2023年8月使用虚拟角
色直播带货后的销售金额情况统计.
年月 2023年8月 2023年9月 2023年10月 2023年11月 2023年12月 2024年1月
月份编号 1 2 3 4 5 6
销售金额 /万
15.4 25.4 35.4 85.4 155.4 195.4
元
若 与 的相关关系拟用线性回归模型表示,回答如下问题:
(1)试求变量 与 的样本相关系数 (结果精确到0.01);
(2)试求 关于 的经验回归方程,并据此预测2024年2月份该公司的销售金额.( ,均保留一位小数)
附:经验回归方程 ,其中 ,样本相关系数
参考数据: .
【答案】(1)0.96;(2) 万元
【解析】(1)
,
所以 .
(2)由题意 ,
所以 ,
所以 关于 的经验回归方程为 ,
所以预测2024年2月份该公司的销售金额为 万元.
七、独立性检验的一般步骤
(1)根据样本数据制成2×2列联表.
(2)根据公式 计算.
(3)比较 与临界值的大小关系,作统计推断.
【典例1】(24-25高三上·广东深圳·月考)(多选)某中学为更好地开展素质教育,现对外出研学课程是
否和性别有关做了一项调查,其中被调查的男生和女生人数相同,且男生中选修外出研学课程的人数占男
生总人数的 ,女生中选修外出研学课程的人数占女生总人数的 .如果依据 的独立性检验认为
选修外出研学课程与性别有关,但依据 的独立性检验认为选修外出研学课程与性别无关,则调查
人数中男生可能有( )
附:,其中 .
A.150人 B.225人
C.300人 D.375人
【答案】BC
【解析】设男生人数为 ,根据题意可得 列联表如下:
男生 女生 合计
选修外出研学课程
不选修外出研学课
程
合计
则 ,
依据依据 的独立性检验认为选修外出研学课程与性别有关,
但依据 的独立性检验认为选修外出研学课程与性别无关,
则 ,解得 ,
则 .故选:BC.
【典例2】(24-25高三上·重庆沙坪坝·开学考试)某学生兴趣小组在研究所在学校的学生性别与身高(身
高分为低于 和不低于 )的相关关系时,记事件 “学生身高不低于 ”,事件 “学
生为女生”.据该校以往的统计结果显示, .
(1)求 ;
(2)若从该校的其中一个班随机抽取36名学生、依据该校以往的统计结果,完成下列列联表,并依据小概
率值 的独立性检验.分析学生的性别与身高是否不低于 有关?
性 身高 合计别
2-3 低于 不低于
女
男
合
计
参考公式及数据: .
0.01 0.005 0.001
6.635 7.879 10.828
【答案】(1) ;(2)列联表见解析,有关
【解析】(1)易知 ;
又 ,
由全概率公式可得 ,解得 ;
(2)由题意知女生抽取24人,不低于170cm的4人;男生抽取12人,不低于170cm的有8人,
完成列联表如下:
性
身高 合计
别
2-3 低于 不低于
女 20 4 24
男 4 8 12
合
24 12 36
计
零假设为 :学生的性别与身高是否不低于 无关,
根据列联表中的数据,经计算得到 ,根据小概率值 的独立性检验,我们推断 不成立,
即认为学生的性别与身高是否不低于 有关,此推断犯错误的概率不大于0.005..
易错点1 对统计图表中的概念理解不清,识图不准确
点拨:求解统计图表问题,重要的是认真观察图表,发现有用信息和数据。对于频率分布直方图,应注意
图中的每一个小矩形的面积是落在该区间上的频率,所有小矩形的面积和为 1,当小矩形等高时,说明频
率相等,计算时不要漏掉其中一个.
【典例1】(23-24高三下·广东·模拟预测)(多选)降雨量是指从天空降落到地面上的雨水,未经蒸发、
渗透、流失,而在水平面上积聚的水层深度,一般以毫米为单位.降雨量可以直观地反映一个地区某一时
间段内降水的多少,它对农业生产、水利工程、城市排水等有着重要的影响.如图,这是 两地某年上
半年每月降雨量的折线统计图.
下列结论正确的是( )
A.这年上半年A地月平均降雨量比B地月平均降雨量大
B.这年上半年A地月降雨量的中位数比B地月降雨量的中位数大
C.这年上半年A地月降雨量的极差比B地月降雨量的极差大
D.这年上半年A地月降雨量的 分位数比B地月平均降雨量的 分位数大
【答案】ACD
【解析】由题意可知:A地月降雨量按升序排列可得: ,
B地月降雨量按升序排列可得: ,
对于选项A:可知A地月平均降雨量为 ,
B地月平均降雨量为 ,
因为 ,所以这年上半年A地月平均降雨量比B地月平均降雨量大,故A正确;
对于选项B:A地月降雨量的中位数为 ,B地月降雨量的中位数为 ,因为 ,所以A地月降雨量的中位数比B地月降雨量的中位数小,故B错误;
对于选项C:A地月降雨量的极差为 ,B地月降雨量的极差为 ,
因为 ,A地月降雨量的极差比B地月降雨量的极差大,故C正确;
对于选项D:因为 ,
可知A地月降雨量的 分位数为42,B地月降雨量的 分位数为40,
且 ,所以A地月降雨量的 分位数比B地月平均降雨量的 分位数大,故D正确;
故选:ACD.
【典例2】(23-24高三下·四川·模拟预测)某市教育主管部门为了解高三年级学生学业达成的情况,对高
三年级学生进行抽样调查,随机抽取了1000名学生,他们的学业达成情况按照从高到低都分布在
五个层次内,分男、女生统计得到以下样本分布统计图,则下列叙述正确的是( )
A.样本中 层次的女生比相应层次的男生人数多
B.估计样本中男生学业达成的中位数比女生学业达成的中位数小
C. 层次的女生和 层次的男生在整个样本中频率相等
D.样本中 层次的学生数和 层次的学生数一样多
【答案】B
【解析】对于AC,设女生学业达成频率分布直方图中的组距为 ,
由 ,得 ,
所以女生学业达成频率分布直方图中 层次频率为 , 层次频率为 ,
层次频率为 , 层次频率为 , 层次频率为 ,
因为男、女生样本数未知,所以 层次中男、女生人数不能比较,即A选项错误;
同理, 层次女生在女生样本数中频率与 层次男生在男生样本数中频率相等,都是 ,
但因男、女生人数未知,所以在整个样本中频率不一定相等,即C选项错误;
对于D,设女生人数为 ,男生人数为 ,但因男、女生人数可能不相等,
则 层次的学生数为 ,层次的学生数为 ,
因为 不确定,所以 与 可能不相等,即D选项错误;
对于B,女生 两个层次的频率之和为 ,
所以女生的样本学业达成的中位数为B,C层次的分界点,
男生 两个层次的频率之和为 ,显然中位数落在C层次内,
所以样本中男生学业达成的中位数比女生学业达成的中位数小,B选项正确.故选:B.
易错点2 对样本数字特征认识不到位
点拨:统计学的另一基本思想是通过科学合理地获取样本,再通过对样本数据的处理,用样本数字特征去
估计总体的相应数字特征。对此我们要有一个辩证的理解,即有时会出现偏差,而解决这一问题的方法是
适度增加样本容量,当样本容量越大,它对总体接近程度越大,可信度越高。
【典例1】(24-25高三上·云南玉溪·开学考试)某公司对员工的工作绩效进行评估,得到一组数据
,后来复查数据时,又将 重复记录在数据中,则这组新的数据和原来的数据相比,一定
不会改变的是( )
A.平均数 B.中位数 C.极差 D.众数
【答案】C
【解析】平均数是所有数据之和再除以这组数据的个数,故平均数有可能改变,
中位数是按照顺序排列的一组数据中居于中间位置的数,故中位数也可能改变,
极差表示一组数据中最大值与最小值之差,将 重复记录在数据中,最大值与
最小值并未改变,所以极差一定不变,
众数是一组数据中出现次数最多的数,有可能改变.故选:C
【典例2】(23-24高三下·广东广州·模拟预测)已知数据 ,且满足 ,若去掉
, 后组成一组新数据,则新数据与原数据相比,有可能变大的是( )
A.平均数 B.中位数 C.极差 D.方差
【答案】A
【解析】由于 ,所以原来的极差为 ,新数据的极差为 ,故极差变小,
原来和新数据的中位数均为 ,故中位数不变,
去掉 , 后,数据波动性变小,故方差变小,
因此可能变大的是平均数,比如 ,原数据的平均数为6.6,去掉1和12后,新数据的平均数为 ,但 ,故A正确.故选:A
易错点3 求解独立性检验问题对 的值理解不准确
点拨: 构造一个随机变量 ,其中 为样本容量.如果
的观测值 ,就认为“两个分类变量之间有关系”;否则就认为“两个分类变量之间没有关系”.
我们称这样的 为一个判断规则的临界值.
【典例1】(23-24高三下·江苏苏州·模拟预测)设研究某两个属性变量时,作出零假设 并得到2×2列联
表,计算得 ,则下列说法正确的是( )
A.有99.5%的把握认为 不成立 B.有5%的把握认为 的反面正确
C.有95%的把握判断 正确 D.有95%的把握能反驳
【答案】D
【解析】依题意, ,因此有95%的把握反驳 ,故选:D.
【典例2】(23-24高三下·山东枣庄·一模)某儿童医院用甲、乙两种疗法治疗小儿消化不良.采用有放回
简单随机抽样的方法对治疗情况进行检查,得到两种疗法治疗数据的列联表:
疗效
疗法 合计
未治愈 治愈
甲 15 52 67
乙 6 63 69
合计 21 115 136
经计算得到 ,根据小概率值 的独立性检验(已知 独立性检验中 ),则
可以认为( )
A.两种疗法的效果存在差异
B.两种疗法的效果存在差异,这种判断犯错误的概率不超过0.005
C.两种疗法的效果没有差异
D.两种疗法的效果没有差异,这种判断犯错误的概率不超过0.005
【答案】C【解析】零假设为 :疗法与疗效独立,即两种疗法效果没有差异.
根据列联表中的数据, ,
根据小概率值 的独立性检验,没有充分证据推断 不成立,
因此可以认为 成立,即认为两种疗法效果没有差异.故选:C.
