 夜雨聆风
夜雨聆风





AI 工具实测报告:哪些场景真的省时间,哪些是假效率
过去两周,我用 Claude + OpenClaw 重做了一遍日常工作流,记录真实耗时、产出质量和踩过的坑。
这篇文章是实测报告,不是种草。哪些场景真的省时间,哪些是假效率,直接上数据。
测试背景
测试周期:2 周(10 个工作日)
测试工具:Claude 3.5 Sonnet(API 调用)、OpenClaw 本地部署版
测试任务:代码开发、文档撰写、数据分析、会议整理、方案评审
记录指标:原耗时、AI 辅助后耗时、产出可用率、返工次数
核心结论
真省时间(节省 50% 以上):代码生成、文档初稿、会议记录整理
省时间但有代价(节省 30-50%,需返工):数据分析报告、技术方案初稿
假效率(省不了时间,甚至更慢):复杂需求分析、跨团队协作沟通
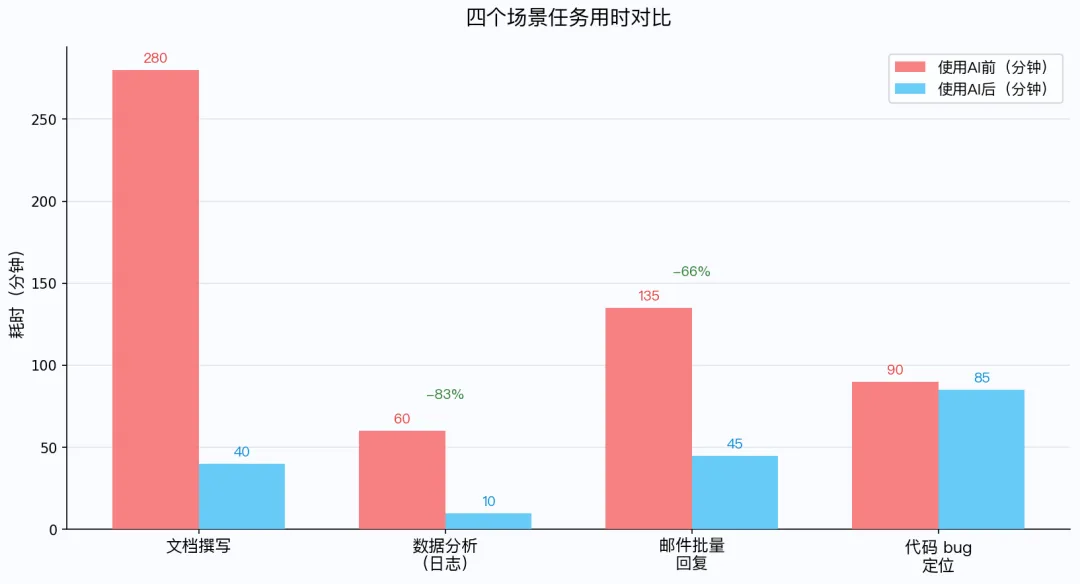
5 类任务的耗时对比(原耗时 vs AI 辅助后)
详细实测数据
场景一:代码开发
原耗时:4 小时/功能模块AI 辅助后:1.5 小时产出可用率:85%(需 Review 后微调)关键发现:AI 擅长 boilerplate 代码,复杂业务逻辑仍需人工
场景二:文档撰写
原耗时:3 小时/篇AI 辅助后:0.8 小时产出可用率:70%(框架可用,内容需大量修改)关键发现:给 AI 清晰的结构模板,产出质量提升明显
场景三:会议记录
原耗时:1.5 小时/场AI 辅助后:0.3 小时产出可用率:90%(转录 + 摘要准确率很高)关键发现:OpenClaw 本地处理语音转文字,隐私可控
场景四:数据分析
原耗时:5 小时/份报告AI 辅助后:3 小时产出可用率:60%(图表生成快,但结论常跑偏)关键发现:AI 会”自信地胡说”,数据解读必须人工把关
场景五:方案评审
原耗时:2 小时/份AI 辅助后:2.5 小时产出可用率:N/A(AI 能发现明显漏洞,但架构权衡仍需经验)关键发现:用 AI 做初筛可以,但增加了二次确认的时间
我的 AI 工作流
基于两周测试,我整理了一套可复用的工作流:
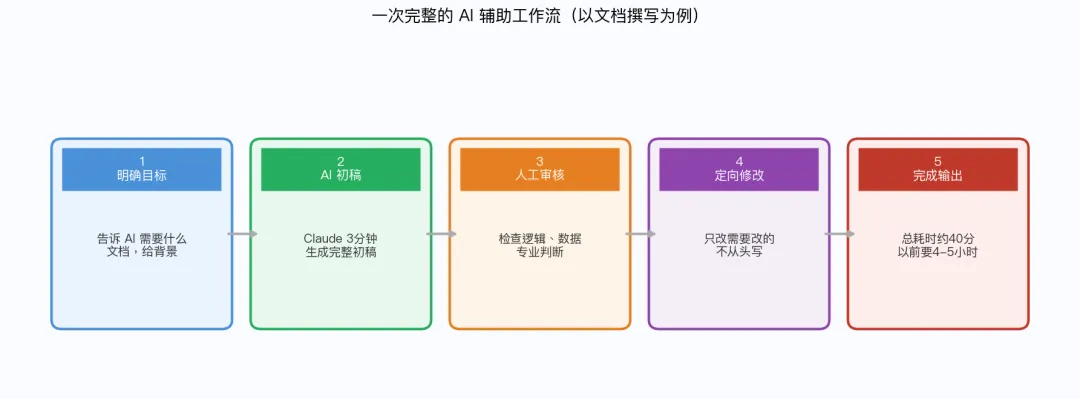
AI 辅助工作流:定义 → 拆解 → 执行 → 校验
Step 1:定义任务边界
明确告诉 AI “做什么”和”不做什么”。边界不清,AI 会过度发挥。
Step 2:拆解成子任务
复杂任务拆成 3-5 个步骤,每步单独给 AI。一次性给太多,质量下降明显。
Step 3:AI 执行 + 人工并行
AI 跑任务的同时,人工准备下一步的输入。不要等 AI 完全结束再开始。
Step 4:强制校验环节
AI 产出必须经过人工确认。我的做法是:关键结论必须能找到出处,代码必须能跑通测试。
工具选择建议

主流 AI 工具能力对比
Claude 3.5 Sonnet:长文本理解、复杂推理首选。API 稳定,上下文 200K,适合深度任务。
OpenClaw:本地部署、隐私敏感场景首选。响应快,可定制,但需要自己维护。
ChatGPT 4o:通用场景、多模态任务首选。生态最全,但国内访问成本高。
踩过的坑
坑一:过度信任 AI 的”自信”
AI 会生成看起来专业但完全错误的内容。现在我要求 AI 给每个结论标注来源,无法标注的必须人工复核。
坑二:把 AI 当搜索引擎用
AI 不擅长实时信息查询。查最新 API 文档、行业数据,还是 Google 更靠谱。
坑三:试图用 AI 做创意发散
AI 擅长收敛(给定框架后填充),不擅长发散(从零到一的创新)。头脑风暴阶段,纸笔比 AI 好用。
总结
两周测试下来,AI 确实帮我省下了约 8 小时/周。但这些时间不是”白捡的”,而是从”执行”转移到了”定义问题”和”校验结果”。
真正省时间的场景:有明确输入输出、可拆解为步骤、结果可快速验证的任务。
假效率的场景:需要大量上下文判断、涉及多方沟通、结果难以量化评估的任务。
建议你先挑一个高频、边界清晰的任务,用 AI 跑一周,记录真实数据。不要听别人说”AI 能提效”,自己测了才算数。
—— 你测过 AI 工具吗?哪些场景真的省时间了?欢迎分享实测数据。