 夜雨聆风
夜雨聆风





给YOLO动三刀,文档版面分析快又准?常州团队的SL-YOLO,我们来扒一扒
AI 分析文档版面:不同区域用不同颜色标记
计算机视觉目标检测文档AI
论文:SL-YOLO — A Document Image Layout Analysis Algorithm Based on Improved YOLOv8s
作者:游晶等,常州大学 & 常州检测认证院
发表:IEEE Access 2026 | DOI: 10.1109/ACCESS.2026.3674930
先说问题:文档版面分析为什么难?
你拍了一张纸质合同的照片,想让AI帮你提取里面的标题、正文、表格、印章。这件事叫文档版面分析(Document Layout Analysis),本质上是一个目标检测任务——告诉机器:这块是标题,那块是表格,角落那个是Logo。
听起来简单?来看看实际的坑:
-
文档里的”目标”长得太像了——标题和正文可能只是字号不同 -
版面结构千变万化——学术论文、银行单据、发票、简历,风格完全不同 -
真实场景拍照有倾斜、遮挡、光照不均

文档AI的永恒命题:速度与精度的平衡
目前主流方案分两派:
精度派以Faster R-CNN为代表,两阶段检测,先找候选区域再分类。准是真准,但慢也是真慢——动不动十几毫秒一帧,大规模文档扫描根本用不起。
速度派以YOLO系列为代表,端到端一步到位。快是真快,但面对文档这种”密集小目标+纹理高度相似”的场景,精度总差那么一口气。
SL-YOLO的目标很明确:在YOLO的速度基础上,把精度往上再拱一拱。
三刀改造:SL-YOLO做了什么?
SL-YOLO基于YOLOv8s,做了三处改动。不是推倒重来,而是”微创手术”。先看整体架构:
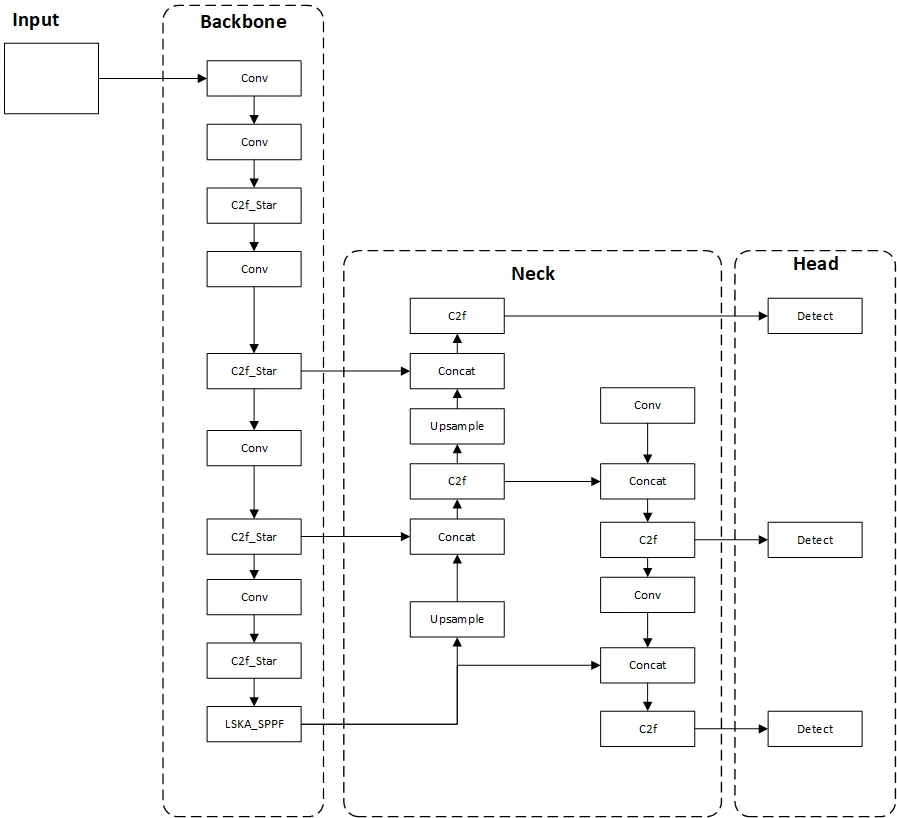
SL-YOLO 网络架构(论文 Fig.1)
我们一个个看。
第一刀:C2f_Star —— 给特征提取加个”星形交叉路口”
YOLOv8s的骨干网络用了一个叫C2f的模块来提取特征。你可以把它想象成一条流水线,图像信息从头流到尾,每一站做一次加工。
问题在于:文档图像的纹理太”均匀”了。一大片文字区域,像素值变化很小,梯度信息容易在流水线上被”磨平”。
SL-YOLO的做法是在C2f里塞入一个叫StarBlock的结构。StarBlock的核心思想:用元素级乘法代替传统的加法残差连接。
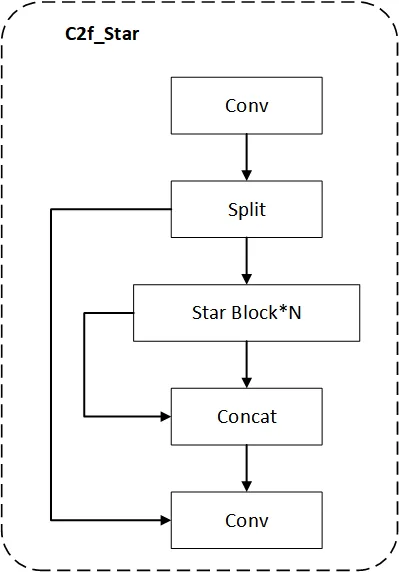
C2f_Star 模块结构(论文 Fig.2)
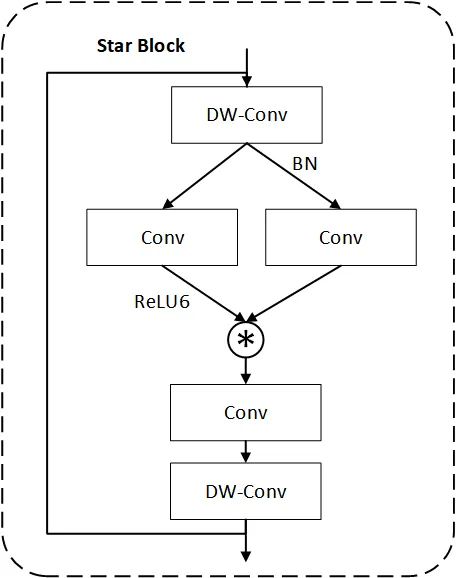
Star Block 内部结构(论文 Fig.3)
打个比喻:传统残差连接就像高速公路上的直线匝道,信息顺着跑就行;StarBlock则像一个星形交叉路口,信息从多个方向汇入、交叉、相乘,然后再分发出去。这种乘法操作天然能捕捉特征之间的高阶交互——通俗说就是”不仅看每个像素本身,还看像素之间的关系”。
第二刀:LSKA_SPPF —— 用”拆卷积”换来大视野
SPPF是YOLO系列的经典组件,负责聚合多尺度特征。但标准SPPF的感受野有限——它只能”看到”局部区域。
文档版面分析有个痛点:一个表格可能占半页纸,模型需要足够大的”视野”才能把整个表格框住。直觉上,用更大的卷积核就行了。但大核卷积的计算量是平方级增长——核从7变到21,计算量翻9倍。
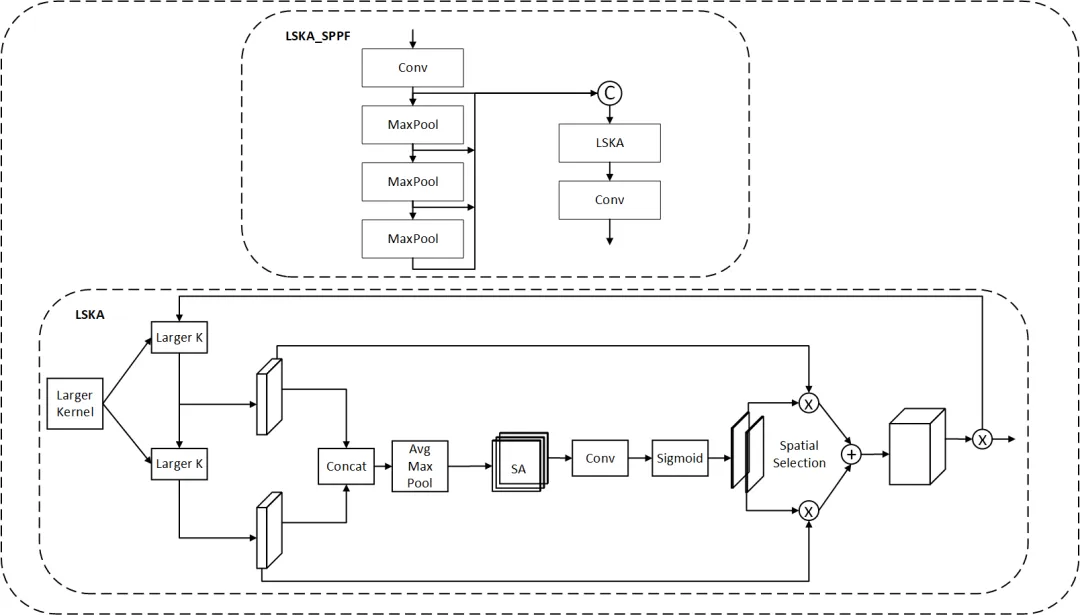
LSKA_SPPF 模块架构(论文 Fig.4)
LSKA的思路很聪明:把一个大的2D卷积拆成两组级联的1D卷积。就像你要在一张照片上画一个大方框,与其直接画矩形,不如先横着扫一遍、再竖着扫一遍——结果一样,但笔画少得多。
感受野大幅扩展,但GFLOPs几乎没涨。”用巧劲办大事”。
第三刀:WIoUv3损失函数 —— 教模型”忽略烂标注”
这一刀不动网络结构,动的是训练策略。
文档数据集的标注质量参差不齐。传统的IoU损失函数会”一视同仁”地让模型学习所有标注,包括那些质量很差的。
WIoUv3引入了一个动态非单调聚焦机制。说人话就是:它会自动评估每个训练样本的”可靠程度”,对于质量差的样本,降低它们的梯度权重。
类比:好老师不会因为一两道印刷错误的习题就改变教学方向,而是把注意力集中在高质量的练习题上。
数据说话:效果到底怎么样?
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
+3.6% |
|
|
|
|
|
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
其中:Logo检测提升了13.3%,说明改进确实强化了对”非文字类”小目标的识别能力。
冷静一下:这些数字意味着什么?
好的一面:CDLA上+3.6%,GFLOPs降38.4%,性价比确实不错。
不那么好的:LA数据集上只提升了0.6%,基本在波动范围内。
🤔 一个关键观察:SL-YOLO的改进在”简单版面”上收益甚微,在”复杂版面”上才明显发力。这反过来说明——对于版面规整的文档,YOLOv8s本身已经够用了。

真实场景:各类文档的版面分析
纯视觉路线还能走多远?
SL-YOLO走的是纯视觉路线——只看图像像素,不理解文字内容。而当下文档AI的大趋势是多模态:LayoutLMv3、ERNIE-Layout、DocPedia,都在把视觉信息和文本语义结合起来。
纯视觉的优势:不需要OCR前置,速度快(4-5ms),模型小(6.1M),边缘设备友好。
纯视觉的劣势:无法理解文字语义,面对新文档类型泛化有限,论文也没有和多模态方法直接对比。
两条路线并非对立。实际产品中完全可以用SL-YOLO做快速版面分割,再用多模态模型做精细理解。速度和深度各取所长。
写在最后
SL-YOLO是一篇典型的”工程改进型”论文:不发明新范式,而是在成熟框架上做精细调优。这类工作在学术上可能不够”性感”,但在工业界往往是最实用的——因为从70.6%到71.2%,可能就是产品能不能上线的差距。
不过,如果你问我文档AI的未来在哪里——我不认为答案是”继续给YOLO换模块”。纯视觉路线在文档理解上有天花板,因为文档本质上是视觉+语义的双重编码。
SL-YOLO的价值,在于它证明了:在轻量级、低延迟的约束下,纯视觉路线还没有被榨干。6.1M参数、5ms推理,如果能做到86.9%的mAP,那在很多场景中它比几百M的多模态大模型更有用。
工程的美感,从来不在于用了多复杂的方法,而在于用最小的代价解决最大的问题。
📺 程序员谈天 | 公众号: coder_says