 夜雨聆风
夜雨聆风





软件架构到底要干什么?
当我们谈论软件架构,我们会想到微服务,有人会谈洋葱架构、整洁架构,有人会想到DDD、限界上下文、聚合根,甚至会想到某张具体画满箭头和方框的“高端”架构图。 大家了解的架构名词越来越多,真正把系统做清楚的团队却并没有同比例增加。
我觉得,问题不在于我们掌握的架构工具不够多,而在于我们一上来就跳进了工具和模式的选择,却跳过了一个更根本的追问:
软件架构到底要干什么?
如果这个问题没有想清楚,我们对架构的讨论就很容易停留在“形式”上:是三层还是六边形,是整洁架构还是使用DDD,是不是要引入COLA?回答这些问题,我们就要回到软件架构的本质,其实就是一句话:
“
软件架构的本质就是管理复杂度。
下面沿着这句话为主线,从软件复杂度从何而来,到架构模式、领域驱动设计(DDD)和COLA,一步步来回答你,软件架构到底在干什么。你会发现,这些不是相互孤立的技术概念,而是一条“复杂度治理”的演进链。
一、软件复杂度从何而来
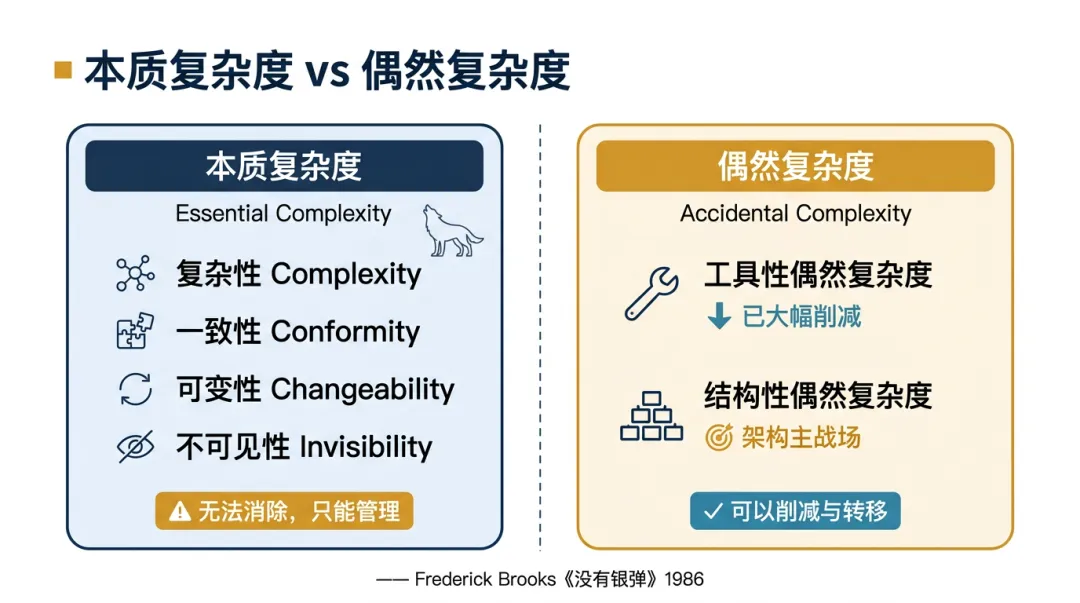
1986年,软件工程泰斗Frederick Brooks在其经典论文《没有银弹》提出了软件工程领域最有影响力的复杂度概念划分:本质复杂度与偶然复杂度。
本质复杂度(Essential Complexity) ,定义软件要解决的问题本身固有的复杂性,不可消除,与使用的工具、语言、框架无关。
偶然复杂度(Accidental Complexity),则是我们在解决问题的过程中引入的复杂性,可以消除,换更好的工具、方法或者框架就能改善。
1.1 本质复杂度:软件与生俱来的困难
40年过去,编程语言已经换了几代,中间件和框架层出不穷,但这个论断依然成立。我们消灭了大部分偶然复杂度(从汇编到高级语言,从手动部署到容器化),但软件的本质复杂度依然像一头打不死的”狼人”。
Brooks指出了软件四大不可消除的本质属性,同时在《人月神话》中揭示了人的组织带来的灾难。
1.复杂性(Complexity):没有重复的部件,软件实体可能是人类创造的结构中最复杂的构造。在软件系统中,几乎不存在完全相同的两个部件,因为一旦存在重复的逻辑,它们就会被立刻抽象并封装为一个独立的子程序、函数或类。随着系统规模的扩大,组件间的非线性交互导致状态空间爆炸,整体复杂性增长远超代码规模的线性增长。
2.一致性(Conformity):被迫适应疯狂的现实,物理学定律到处通用,但软件系统却必须被迫适应充满混乱且经常不合逻辑的现实环境。软件需要对接各种遗留系统的非标准接口,适应不同业务部门朝令夕改的流转规则。这种复杂性并非来自软件内部,而是为了迎合外部人类社会制度和业务生态的不规范性。
3.可变性(Changeability):永无止境的变更,软件从诞生之初就是“软”的,极易受到变更压力的影响。汽车或大楼交付后极少发生结构性重构,但软件的上线仅仅是生命周期的开始。业务模式演进、法规变更、用户需求变化,注定系统在其生命周期内会被不断地修改和扩展。
4.不可见性(Invisibility):盲人摸象的困境,建筑有施工图,机械有三维 CAD,但软件缺乏物理形态,无法通过单一的二维或三维图形完整表达。控制流、数据流、时序依赖相互交织,极大地阻碍了开发者对系统全貌的理解,也显著增加了团队的沟通成本。
如果将上述四大本质复杂性揉捏在一起,业务逻辑与技术细节相互交织,系统就会陷入结构性崩塌。
1.2 偶然复杂度:
与本质复杂度相对的,是偶然复杂度——它不源于问题本身,而源于我们当前解决问题的方式和工具的局限。
40年过去,编程语言已经换了几代,中间件和框架层出不穷,我们消灭了大部分偶然复杂度(从汇编到高级语言,从手动部署到容器化)。如果再细分,偶然复杂度可以两类:
-
工具性偶然复杂度,它来自开发工具和语言的不成熟、调试不够方便、交付不够自动化。过去几十年的技术进步,已经把这类复杂度大幅削减。
-
结构性偶然复杂度 它来自软件系统的组织方式不当。比如业务逻辑和技术细节写在一起,模块边界模糊,依赖方向混乱,任何一个需求变更都可能引发连锁反应,团队成员对“代码该放哪里”没有统一理解,这就是工程架构层面的偶然复杂度,如果架构设计不当,系统照样会陷入结构性崩塌。
1.3 结论:软件架构的主战场
基于Frederick Brooks的论文,我们可以得出一个比较精确的结论:
“
软件的本质复杂度无法消除,只能管理;软件的偶然复杂度无法归零,只能在工具和实践的演进中持续削减与转移。当偶然复杂度被压缩到足够低时,本质复杂度就成为了主要矛盾。
为什么偶然复杂度”无法归零”而非”可以消除”?
因为每一代新技术在解决旧形态偶然复杂度的同时,都在制造新形态的偶然复杂度。高级语言消除了汇编的繁琐,但引入了运行时开销和抽象泄漏;GC消除了手动内存管理的困难,但引入了Stop-the-World停顿的新问题;Docker消除了环境差异的困难,但引入了容器编排的新复杂度。
理解了这一点,”软件架构到底要干什么”的答案就浮出水面.
“
架构设计的终极使命,是在削减结构性偶然复杂度的同时,为本质复杂度提供有效的管理手段。
二、如何解决软件复杂度
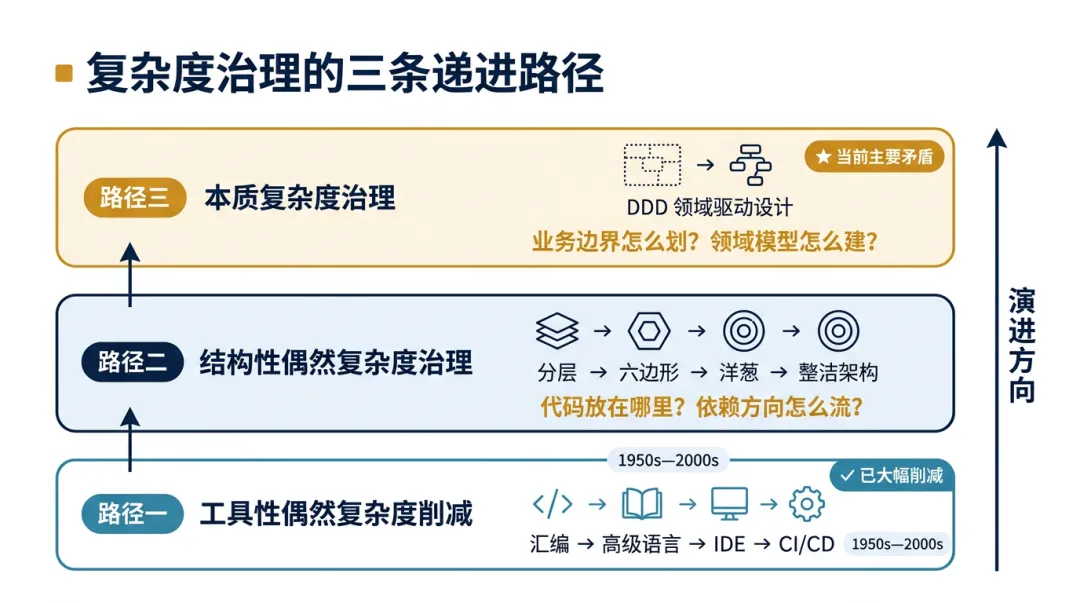
从复杂度治理的角度看,过去几十年的软件工程史,就是三轮彼此递进的治理过程。我觉得可以分为三个路径:
2.1 偶然性复杂度消减:工具软件的发展
从1950—2000年代,软件工程最显著的进步几乎都发生在工具层面。高级语言替代机器码和汇编,IDE 替代低效的手工编辑和编译,版本控制解决多人协作混乱,自动化测试和持续集成大幅降低交付成本。今天的开发者不需要关心寄存器分配,不需要手动管理内存,不需要等几小时才能看到编译结果。工具性偶然复杂度已经被压缩到了相当低的水平。
2.2 结构性偶然复杂治理:架构模式的演进
当工具逐渐成熟之后,新的瓶颈浮现出来:代码应该如何组织?模块之间的依赖关系应该怎么流?业务逻辑和技术细节应该怎么隔离?
架构模式(Architectural Pattern)的演进,本质上就是一部“如何科学地划定边界”与“如何严格地控制依赖方向”的发展史。
从传统分层架构到六边形架构,再到洋葱架构和整洁架构,每一代架构模式都在回答同一个核心问题:如何把易变的技术细节与相对稳定的核心业务规则进行物理隔离。
2.3 本质复杂度治理:DDD业务建模
架构模式解决了”代码放在哪里”和”依赖方向怎么流”的问题,但它有一个根本性的局限——业务复杂度并没有降低。
交易、供应链、风控、营销、支付、结算、履约,这些系统真正难的地方,不是“Service如何定义、放在哪里”,而是:
-
业务边界到底在哪里? -
一个概念在不同语境中是不是同一个东西? -
哪些规则属于订单,哪些规则属于履约? -
哪些对象必须一起保持一致性? -
哪些变化应该通过事件传播,哪些应该在聚合内部消化?
这三条路径不是并列的,而是层层递进的关系:工具性偶然复杂度被削减后,结构性偶然复杂度浮出水面;结构性偶然复杂度被削减后,本质复杂度成为主要矛盾。
这条递进链,也正是我们接下来讨论架构模式、DDD和COLA的逻辑主线。
三、从混沌到隔离:架构模式的演进与边界划分
架构模式的核心理念是实现关注点分离(Separation of Concerns)——将易变的技术细节与相对稳定的核心业务规则进行物理隔离。
从传统三层架构到整洁架构,每一代演进都在让这种隔离更加彻底。架构模式主要解决了系统结构的问题,指明了复杂度治理的方向(即代码该怎么放),其重点在于治理前文的结构性偶然复杂度。
3.1 传统分层架构
他解决了什么问题?
最基本的职责分离,表现层负责交互,业务层负责逻辑,数据访问层负责持久化。
他存在什么问题?
业务逻辑层直接依赖于数据访问层。这种结构本质上是数据驱动设计,虽然代码被分了层,业务核心并没有从技术细节中独立出来,没有切断业务逻辑对技术细节的依赖,结构性偶然复杂度仍然大量存在。
3.2 六边形架构(Hexagonal Architecture,2005 年)
他解决了什么问题?
打破传统的“上下”分层,建立明确的“内外”之分。业务核心不应该直接依赖这些技术实现,所有外部交互——无论是入站的 HTTP 请求,还是出站的数据库调用 —— 都通过端口(Port)和适配器(Adapter)与业务核心交互。
六边形架构首次指出,数据库和 UI 对业务核心而言处于同等地位——它们都是”外部”。这打破了传统分层架构中”UI 在上,数据库在下”的层级思维。
它解决了什么结构性偶然复杂度?
业务核心不再依赖任何具体的技术实现。更换数据库只需替换对应的适配器,业务代码一行不改。
3.3 洋葱架构(Onion Architecture,2008 年)
他解决了什么问题?
洋葱架构在六边形架构基础上,认为仅仅划分内外不够,进一步细化了内部核心区的层次结构。
“
洋葱架构首次明确提出依赖方向由外向内——外层依赖内层,内层对外层一无所知。
首次明确业务核心拆分为拆分为Domain Model、Domain Services和Application Services三个层次。Domain Model是最纯粹的业务规则,Domain Services是跨实体的业务协作,Application Services 是用例编排,三者各司其职。
3.4 整洁架构(Clean Architecture,2012 年)
他解决了什么问题?
整洁架构在吸收六边形架构和洋葱架构的核心思想后,提炼出了更普适的依赖规则(The Dependency Rule):
“
源码的依赖关系必须且只能绝对向内,指向更高层级的策略,内存的代码绝不能引用外层的任何东西。
3.5 架构模式的演进总结
四代架构模式的演进,不是四种互相竞争的方案,而是同一个问题被逐步逼近的过程:
“
如何让业务核心从技术细节中解放出来,并让系统在长期演化中保持结构稳定。
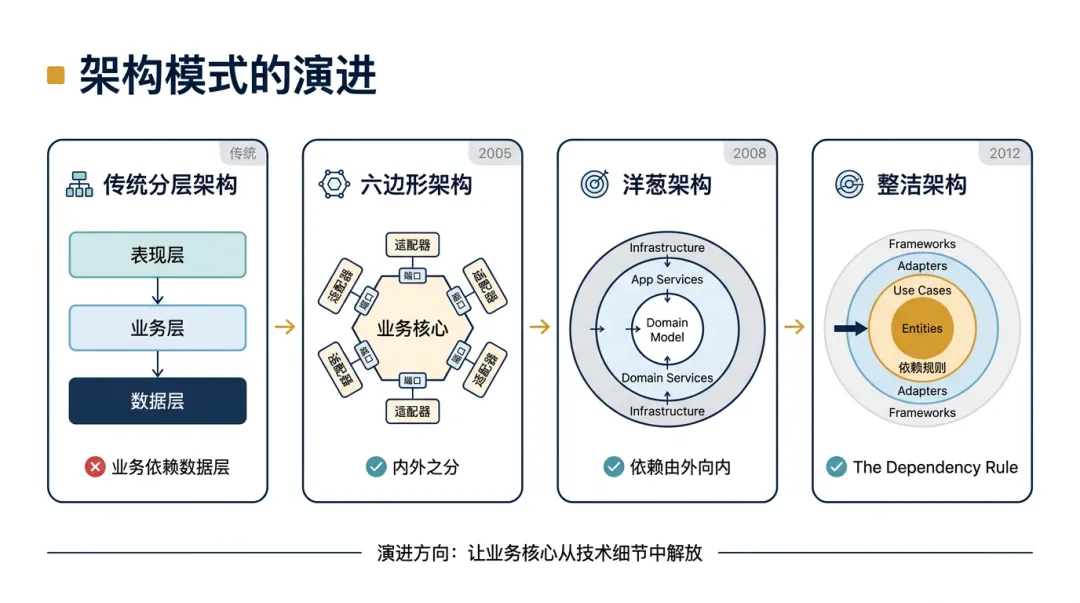
用复杂度的语言说,它们治理的都是同一种复杂度——结构性偶然复杂度。从三层架构到六边形、洋葱、整洁架构,核心趋势并不是“图越来越复杂”,而是业务核心和技术细节的隔离越来越彻底,依赖方向越来越向内收敛。
四、治理业务复杂度的内核:领域驱动建模
4.1 架构模式留下的空白
尽管六边形架构、洋葱架构和整洁架构完美地解决了系统的“结构”问题(即代码模块应该放置在哪里,依赖关系如何流动),但是,但它没有回答的问题是:
-
“下单动作”是一个 Entity 还是一个 Use Case? -
“订单”和”物流”之间的边界应该画在哪里? -
Entity应该是只有getter/setter的贫血对象,还是封装了业务行为的充血模型? -
不同业务板块之间如何防止概念污染?
这些问题属于本质复杂度,一句话总结就是:最内层的业务逻辑怎么写? 它们不是代码组织的问题,而是业务认知的问题。
4.2 DDD到底在做什么?
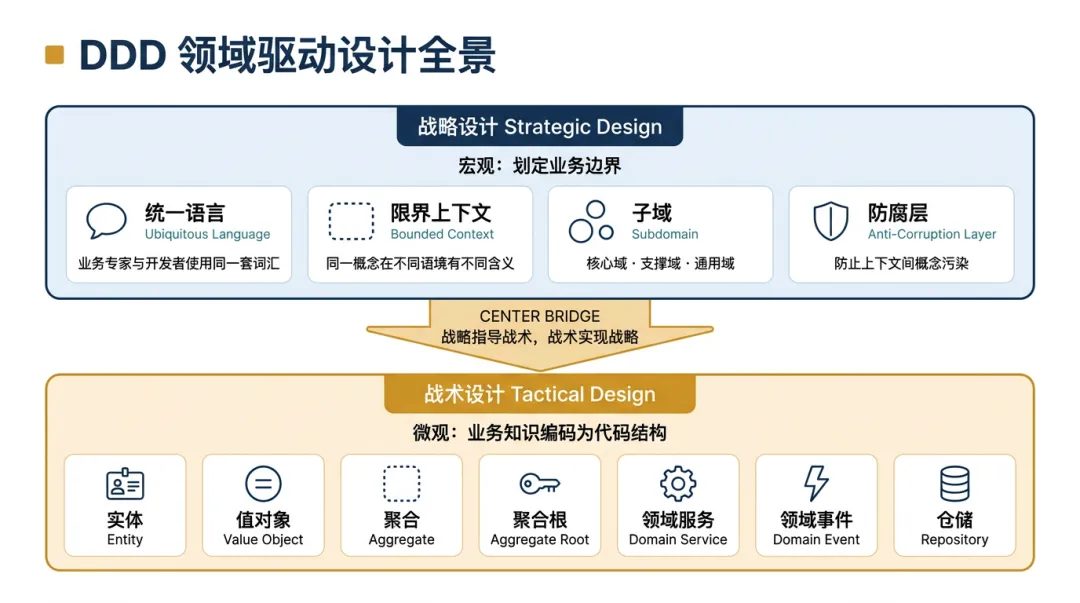
这就是为什么必须引入领域驱动设计(DDD)。DDD是一套以业务领域为核心的复杂系统开发方法论,它通过战略设计和战术设计,直击本质复杂度的核心。
Eric Evans在2003年提出的领域驱动设计(Domain-Driven Design),直面的正是本质复杂度。其核心思路可以概括为一句话:
“
用业务专家的语言来建模,用模型来驱动代码。
领域驱动建模分为两个层次:
战略设计(Strategic Design)——宏观层面划定业务边界,建立认知共识:
-
统一语言(Ubiquitous Language): 团队内用同一套词汇描述业务概念。不是程序员说”order_status 字段”、业务方说”订单状态”,而是所有人统一说”订单状态”,且对其含义有一致的理解。 -
限界上下文(Bounded Context): 划定业务概念的有效边界。”用户”在电商系统里是买家,在支付系统里是付款人,在物流系统里是收货人。不要试图用一个万能的 User 对象打通所有系统——每个上下文里的”用户”有各自的属性和行为。 -
子域(Subdomain): 区分核心域、支撑域和通用域,将有限的精力集中在最能产生业务差异化的核心域上。 -
防腐层(Anti-Corruption Layer): 上下文之间通过防腐层交互,防止一个上下文的概念污染另一个上下文。
战术设计(Tactical Design)——微观层面将业务知识编码为代码结构:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.3 DDD解决本质复杂度的底层逻辑
战略设计解决的是本质复杂度中的”复杂性”和”一致性”问题 —— 通过限界上下文划定边界,通过统一语言消除二义性,让一个大问题分解为若干个小问题,每个小问题在自己的上下文里有清晰的定义。
战术设计解决的是本质复杂度中的”可变性”和”不可见性”问题 —— 通过充血模型让业务规则可见、可测试,通过聚合边界控制变更的影响范围,通过领域事件让业务流转显式化。
DDD并没有让业务规则本身变少或变简单。它的价值在于:
-
让复杂度有处安放。 它把混沌的、隐式的业务知识转换为结构化、显式的、可验证的领域模型 —— 实体、值对象、领域服务,而不是散落在几十个Service类的几千行代码里。
-
让业务语义显性化。 统一业务和开发人员使用同一套语言。代码就是业务文档,代码里的类名、方法名、变量名,直接对应业务概念。当业务规则改变时,代码的变更是直觉式的,而不是经过一层层技术翻译的,业务意图一目了然。
-
让业务变更影响局部化。 当业务规则变化时,你只需要修改对应聚合内部的实体或领域服务,而不是在一个巨型 Service 里做全局搜索替换。
即便你已经认同整洁架构,也理解了DDD,团队落地时仍然可能面临一个很现实的问题: 为什么十个人都说自己懂架构,最后写出来的代码还是十种样子?
五、COLA工程架构:本质还是解决结构偶然复杂度
5.1 COLA是什么?
COLA(Clean Object-oriented & Layered Architecture)是阿里巴巴开源的一套 Java/Spring 应用脚手架。它将架构模式的依赖原则与DDD的战术设计思想融合在一起,进一步固化为一套团队可执行的工程规范。
5.2 COLA解决什么?
COLA的本质,仍然是解决的偶然复杂度,是工程落地阶段的结构性偶然复杂度。 洋葱架构细化了内核层次,整洁架构提炼出了依赖规则,DDD给出了领域建模方法论。但当一个团队真正坐下来写代码时,依然会面对大量的决策性困惑:
-
这段校验逻辑放 Service 里还是 Domain 里? -
DTO 和 DO 是同一个对象还是分开的? -
Repository 接口定义在哪个模块?实现又在哪个模块? -
domain 层到底能不能引入 Spring 的注解?
每一个这样的提问,本质上都不是业务问题(本质复杂度),而是工程组织方式的问题(结构性偶然复杂度)。在没有统一规范的团队里,十个开发者可能会给出十种不同的回答。 COLA的价值,用一套强约定和Maven多模块物理隔离,把这些“原则上的正确”,固化成“默认情况下就这么做”的工程约束。
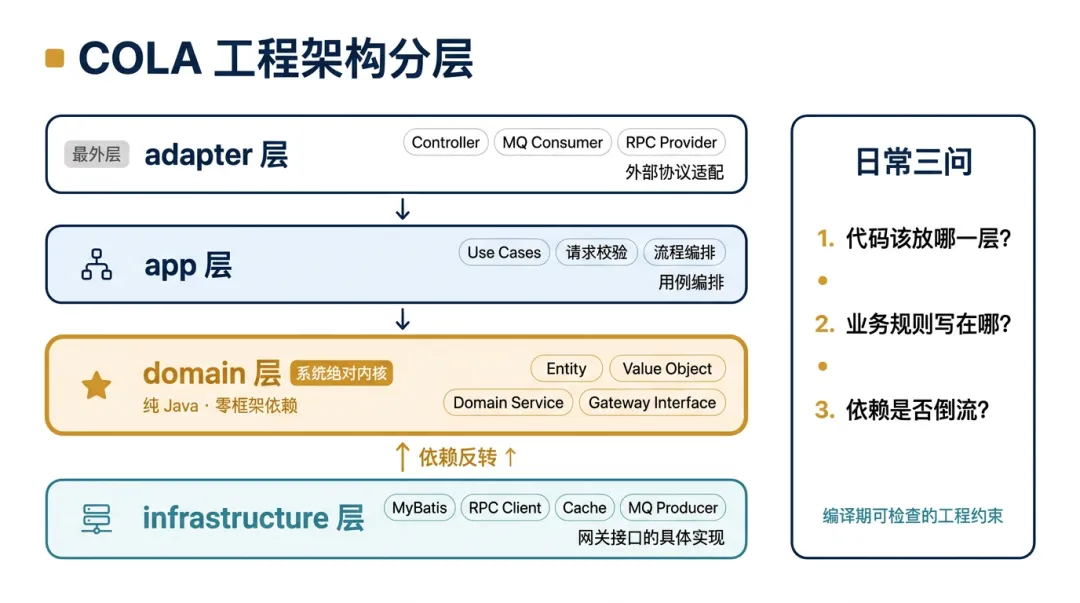
-
adapter 层:最外环,Controller、MQ 消费者。负责外部协议的适配。 -
app 层:对应整洁架构的 Use Cases。请求校验、流程编排、事务控制。 -
domain 层:系统的绝对内核。纯 Java 代码——实体、值对象、领域服务、网关抽象接口。不依赖 Spring、不依赖 MyBatis。 -
infrastructure 层:domain 层网关接口的具体实现(MyBatis 映射、RPC 调用、缓存操作)。
同时,COLA使用一套工程架构规范,把大量CodeReview的软约束,提前到编译器的硬约束。
具体而言,COLA 解决了以下几类偶然复杂度:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
COLA 解决的核心问题,是”在没有统一规范的团队里,每个人对架构原则的理解不一致“ 所带来的结构性偶然复杂度。它把抽象的架构原则,变成了编译期可检查的工程约束。
5.3 COLA不解决什么?
同样重要的是,要清醒地认识 COLA 的边界:
-
本质复杂度(业务规则本身)——COLA无能为力。它只是容器,不帮你理解保险续期业务规则。 -
领域建模复杂度(如何识别聚合根、限界上下文)——需要DDD方法论和领域专家。 -
分布式系统复杂度(分布式事务、最终一致性)——COLA没有内建解决方案。
5.4 代码落地的日常三问
COLA 框架下,开发者每天面对的核心判断,可以归结为三个问题:
1.”这段代码该放在哪一层?” 如果把底层运行环境从 Spring 换成终端命令行,代码还需要吗?不需要 → adapter 层。如果换一个业务场景逻辑还成立吗?成立 → domain 层;不成立(纯流程控制)→ app 层。如果把数据库从 MySQL 换成 MongoDB,代码必须重写吗?必须重写 → infrastructure 层。
2.”业务规则写在 Service 里还是对象自身里?” 仅改变单一实体状态并确保内部一致性 → 封装进实体内部(充血模型)。串联多个实体完成完整用户指令 → app 层服务。协调多个实体进行复杂计算 → domain 层领域服务。
3.”如何保证依赖绝对不倒流?” 在 domain 层定义抽象的网关接口,在 infrastructure 层提供具体实现。通过 DI 容器在应用启动时装配。业务核心永远只依赖稳定的契约,而非易变的技术实现。
六、 回归:软件架构到底要干什么
走到这里,我们其实就可以回答软件架构到底在干什么了?
“
软件架构,不是追求一种“最先进的架构形式”,而是围绕复杂度治理,把可削减的复杂度尽量削减,把不可消除的复杂度收敛在清晰边界内,建立一套从原则、到模型、再到工程落地的递进体系。
总结过去七十年的软件工程演进,给出了三层递进的解决方案:
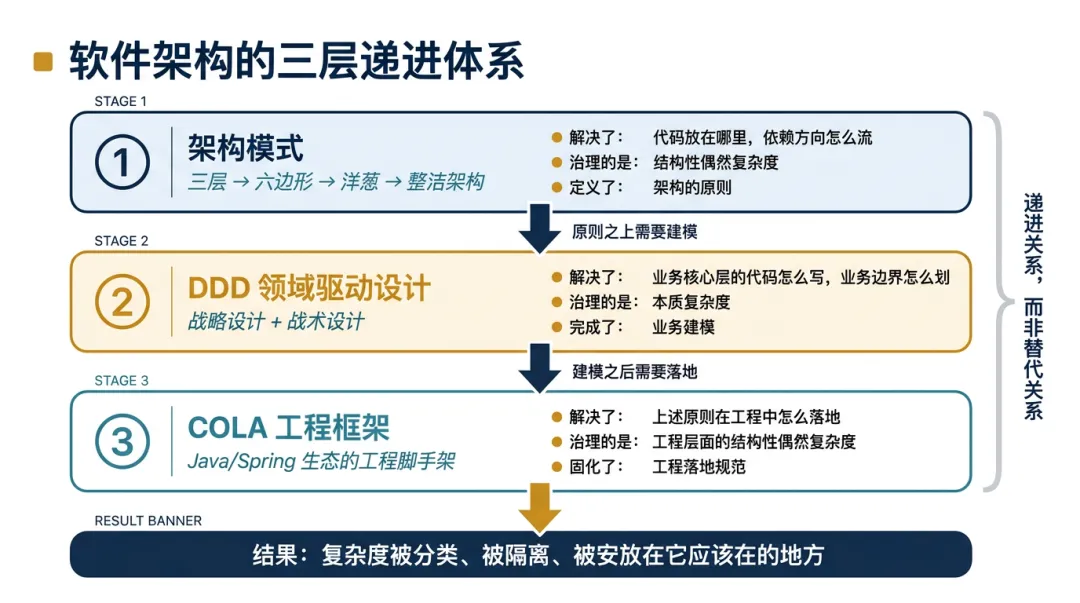
三者是递进关系,而非替代关系。
-
没有架构模式的原则,DDD 的领域建模缺少结构承载,代码依然会退化为大泥球。 -
没有DDD的领域建模,架构模式再精美,最内圈也只是一堆贫血的getter/setter和万能Service。 -
没有COLA的工程约束,架构原则和DDD理念只停留在PPT和白板上——十个开发者有十种理解,架构腐化只是时间问题。
软件的复杂度永远不会凭空消失。但当架构模式划定了边界,DDD 填充了内容,COLA 固化了规范——复杂度就被安放在了它应该待的地方。
七、 扩展:AI Coding主要解决软件的什么复杂性问题
个人认为:AI Coding 目前最显著的价值,仍然集中在工具性偶然复杂度的进一步削减上,同时对结构性偶然复杂度有部分缓解作用,但对本质复杂度基本无能为力。
7.1 工具性偶然复杂度:AI Coding的主战场
Frederick Brooks当年列举的工具性偶然复杂度,是”用汇编写代码”、”手动管理内存”、”依赖管理和版本化管理”,高级语言和IDE已经解决了这一批。这类复杂度并没有彻底消失,只是被大幅压缩。
今天的程序员面对的工具性偶然复杂度:
-
记不住某个 API 的参数顺序和用法 -
写一段 CRUD 代码要重复大量样板逻辑 -
不同框架之间的语法差异和配置细节 -
单元测试的编写繁琐 -
正则表达式、SQL、Shell 脚本的语法门槛 -
阅读和理解一段陌生(屎山)代码的认知成本
AI Coding对这些问题的效果是立竿见影,Copilot、Cursor、Claude这类AI Coding工具,非常擅长处理语法转换、生成样板代码、搭建基础测试脚手架、配置框架以及执行常规的系统实现任务,本质上就是在做一件事:把”程序员知道要做什么,但梳理、写出来很繁琐”的部分自动化掉。这和当年高级语言替代汇编的逻辑是一样的——它削减的是”表达意图”的成本,而不是”形成意图”的成本。
7.2 结构性偶然复杂度:有帮助,但远不够
AI Coding在结构层面能做到一些事情:
-
按照已有项目的分层规范生成符合规范的代码 -
识别简单的依赖方向问题并提出建议 -
辅助重构,比如提取方法、重命名、移动类 -
根据已有模式生成新模块的脚手架代码
但它做不到的事情更多:
-
它不知道你的系统应该分几层 -
它不知道某段逻辑应该放在Domain还是Application -
它不知道你的模块边界是否合理 -
它不知道一个依赖方向的反转是不是有意为之
结构性偶然复杂度的治理,需要的是架构决策,而不是代码生成。AI可以帮你更快地写出符合某个结构的代码,但它不会帮你决定这个结构本身是否正确。
7.3 本质复杂度:目前几乎无能为力
Frederick Brooks说的本质复杂度有四大困难:复杂性、一致性、可变性和不可见性。这四个困难有一个共同特征:这些问题的答案不在代码里,而在业务认知里。
本质复杂度要回答的问题是:
-
“交易、营销和履约的边界该如何划分” -
“一套收银台如何适配不同的收单交易系统” -
“收单交易、资产交换和金融网关的业务边界如何划分” -
“这个聚合的一致性范围应该多大” -
“这段业务逻辑属于领域服务还是应用服务”
AI Coding面对这类问题时的表现是:
-
你不问它,它不会主动识别出领域边界问题 -
你问它,它会给出一个”看起来合理但未必适合你的业务”的通用回答 -
它无法参与事件风暴,无法和领域专家对话,无法理解你的组织上下文 -
它可以生成一个”标准的DDD分层结构”,但这个结构里的Entity是贫血的还是充血的、聚合根的边界在哪里,它并不真正理解
AI大模型的核心能力,本质是强大的基于海量已有文本的模式匹配与生成能力。一句话总结,AI是一个极其出色的翻译,可以把任何语言翻译成任何语言。但如果你自己都不知道想说什么,翻译再好也帮不了你。 所以,本质复杂度的核心困难,恰恰就是”想清楚要说什么”,对你自己来说都是未知的问题,AI的训练数据里没有你的业务,它也无能为力。
7.4 AI Coding的”消减和转移“的双面性
“
“软件的偶然复杂度无法归零,只能在工具和实践的演进中持续削减与转移”
高级语言消除了汇编的繁琐,但引入了运行时开销和抽象泄漏;GC消除了手动内存管理,但引入了Stop-the-World停顿;Docker消除了环境差异,但引入了编排和镜像治理的新问题。
AI Coding也完全遵循这条规律,只是它制造的新复杂度更隐蔽、更难察觉的问题,目前阶段AI Coding至少引入了如下这些偶然复杂性:
-
理解债务:代码存在但没人真正理解。传统开发中,每一行代码都经过开发者的思考过程。即便写得不好,写它的人至少知道“我为什么写了这行”。AI Coding直接跳过了这个重要过程,这就是理解债务:代码在系统里运行着,但团队中没有人真正理解它。
-
架构侵蚀:AI不保证守护边界。目前阶段的AI生成代码时,它的优化目标是”让当前这段代码能跑”,而不是”让当前这段代码符合系统的整体架构约束”。
-
不明确膨胀:不确定性的引入。一个开发者让AI生成了1000行代码,跑通了测试,提交了PR。但这1000行代码里,哪些是必要的,哪些是冗余的,为什么引入了这个库而不是那个库,某个异常处理分支覆盖的是什么场景——这些问题,AI Coding生成代码太快了,指挥AI的人可能都没有思考过。
-
目前阶段AI技术缺陷引入不确定性。更要命的是,处理跨多个模块、长链路的复杂需求时,AI仍然可能会出现幻觉或采取违规的捷径,指挥AI的人和AI都不知道此处是”幻觉业务知识“或者违规路径。
7.5 为什么这些复杂性是危险的?
传统工具引入的新复杂度,通常是显式的。GC的Stop-the-World停顿,你会在监控里看到;Docker的编排复杂度,你在第一次部署时就会感受到。但是,AI Coding 引入的新复杂度,几乎都是隐式的、延迟爆发的。
这就是最危险的地方:AI让你在短期内感受到了生产力提升,但在中长期可能加速了技术债务的积累——而且这种积累是不知不觉的。
7.6 AI Coding复杂度治理总结
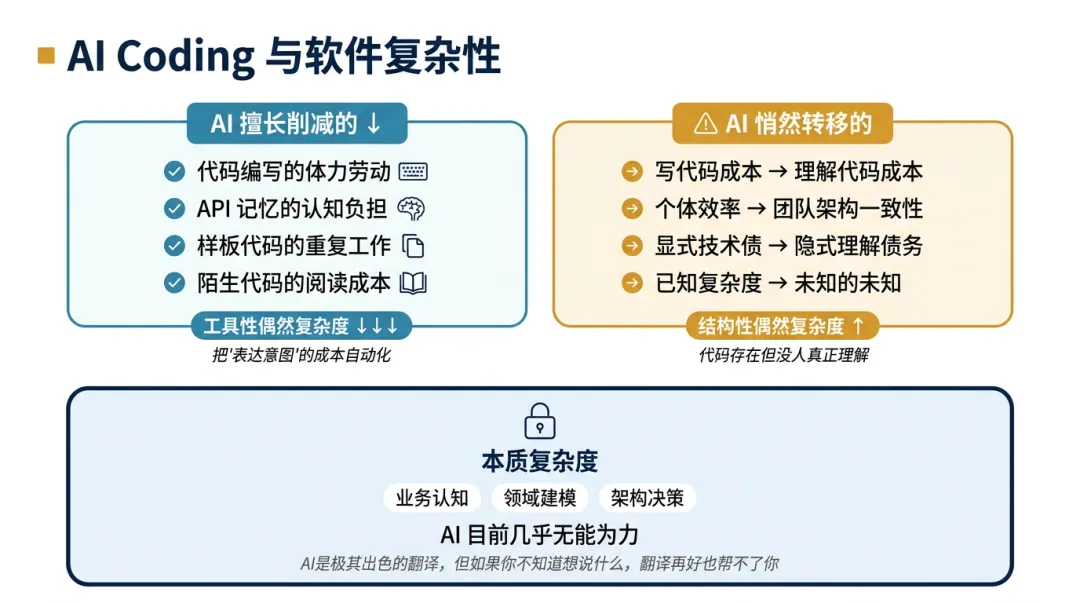
AI Coding 削减的偶然复杂度:
-
代码编写的体力劳动 -
API 记忆的认知负担 -
样板代码的重复工作 -
陌生代码的阅读成本
AI Coding 转移和制造的偶然复杂度:
-
从”写代码的成本”转移到”理解代码的成本” -
从”个体编码效率”转移到”团队架构一致性” -
从”显式的技术债务”转移到”隐式的理解债务” -
从”已知的复杂度”转移到”不知道自己不知道的复杂度”
所以,AI Coding时代,Frederick Brooks关于软件偶然复杂度的结论依然成立:
“
AI Coding并不是偶然复杂度的终结者,而是偶然复杂度大部分消减和一部分转移。它把”写”的复杂度大幅降低了,但把”理解“、”守护“和”一致性维护“的复杂度悄然抬高了。
这才是”偶然复杂度无法归零,只能削减与转移”这句话在AI Coding时代最深刻的注脚。