 夜雨聆风
夜雨聆风





飞书为什么要开源 CLI?因为下一代办公软件,不会只服务人类
3 月 28 日,飞书官方开源了 larksuite/cli,发布 v1.0.0。如果只看名字,你很容易把它当成“飞书开放平台的命令行工具”;但如果认真看 README、安装方式、权限模型和配套仓库,会发现它想解决的问题远不止“在终端里调 API”这么简单。
它的官方定位非常直接:面向 humans and AI Agents;覆盖 11 个业务域、200+ 命令、19 个 AI Agent Skills。仓库开源后很快拿到 2k+ Star,这说明它触发的不是一个小众 CLI 需求,而是开发者对“AI 如何真正进入办公系统执行动作”这件事的强烈兴趣。
真正值得关注的是:飞书开源的不是一个命令行壳,而是一层 AI 可执行的工作接口。
它把消息、日历、文档、多维表格、邮箱、会议纪要这些原本属于“协同软件 UI 层”的能力,重新压缩成了可以被人类、脚本、Agent 同时调用的统一入口。这个变化的意义,比“多了一个 CLI”大得多。
一、为什么说它不是普通 CLI,而是 Agent 的执行入口
lark-cli 的 README 里有一句很关键:它不是单纯给开发者用的,而是 built for humans and AI Agents。这决定了它的设计目标从第一天起就不是“让人手敲命令更方便”,而是“让 AI 能可靠地调用飞书能力”。
所以你会看到它一上来就不是先讲 API 列表,而是先讲 Agent-Native Design、结构化 Skills、智能默认值、结构化输出、安全控制,以及如何让 AI 在后台完成配置与授权。
更能说明问题的是它的安装流程。README 明确要求除了安装 CLI 本体,还要执行:
npx skills add larksuite/cli -y -g也就是说,飞书并不是把 CLI 当成一个孤立工具,而是把它当成一个可被 AI 托管调用的能力包。这在传统开放平台工具里并不常见。过去我们习惯的是“SDK + API 文档 + 示例代码”;而 lark-cli 明显在往“CLI + Skills + 授权链路 + 安全约束”的方向设计。
从能力面看,它覆盖消息、云文档、云空间、多维表格、电子表格、日历、任务、知识库、通讯录、邮箱、会议记录等核心业务域;从 Skills 看,又拆成了 lark-calendar、lark-im、lark-doc、lark-drive、lark-base、lark-mail、lark-vc、lark-minutes、lark-openapi-explorer 乃至 workflow 级的 meeting-summary 与 standup-report。
这意味着它已经不只是“调接口”,而是在把办公对象抽象成 AI 可以理解和执行的工作语义单元。
二、它的技术结构,到底做对了什么
如果把 lark-cli 抽象成一张图,它大概是这样的:
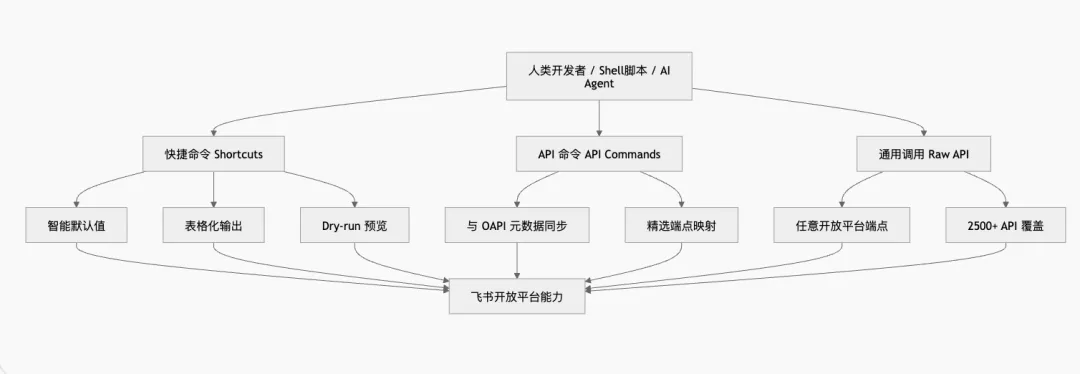
-
• 第一层是 +agenda、+messages-send 这样的 Shortcuts,面向人和 AI,参数更短、默认值更聪明、支持表格输出和 –dry-run; -
• 第二层是 API Commands,从飞书 OAPI 元数据自动生成,与平台端点一一对应; -
• 第三层是 Raw API,直接请求任意开放平台端点,覆盖 2500+ API。
这套分层很重要,因为它解决了 Agent 落地最难的一个问题:不同任务需要不同抽象粒度。
简单动作,比如“查看今天议程”或“发一条消息”,用 Shortcut 最合适;中等复杂度的结构化动作,用 API 命令最稳;遇到平台刚开放的新端点或长尾能力,再退到 Raw API。
这比“只有 SDK”或者“只有 MCP 工具”更灵活,因为它同时兼顾了上手效率、执行稳定性、平台覆盖率。
1)它是 Go 运行时,但用 npm 做分发层
从仓库结构看,main.go 非常薄,核心只是 os.Exit(cmd.Execute()),说明执行逻辑主要都沉在 cmd 和内部模块里;go.mod 则显示它基于 Go 1.23,依赖里包括 spf13/cobra、larksuite/oapi-sdk-go/v3、zalando/go-keyring 等,意味着它在工程上走的是典型的 Go CLI 架构。
但它没有把“安装 Go 环境”当成默认路径。package.json 表明 npm 包本身只是个很薄的入口:bin 指向 scripts/run.js,安装阶段通过 postinstall 执行 scripts/install.js;而 .goreleaser.yml 显示它会构建 macOS、Linux、Windows 三个平台,覆盖 amd64 与 arm64。
这实际上是一种非常务实的选择:用 Go 做可执行运行时,用 npm 做跨平台分发入口。
对普通开发者来说,这种方式比“自己编译一个 Go CLI”更低门槛;对 AI 工具生态来说,npm 也是天然更容易接入的一层。
2)它把“授权”设计成了可被 AI 执行的流程
这也是我认为它最像“Agent Runtime”的地方。
README 专门区分了“人类用户快速开始”和“AI Agent 快速开始”,而且 AI 路线里明确写了:config init –new 和 auth login –recommend 可以在后台运行,命令会产出授权链接,AI 只需要提取链接发给用户,等用户在浏览器完成确认后,流程会自动结束。
这意味着它已经开始把传统 OAuth 流程拆成可编排的人机协同链路。
再往下看,认证部分还支持:
-
• auth login –no-wait:立即返回验证 URL,不阻塞 -
• auth login –device-code :稍后恢复轮询 -
• –as user / –as bot:以用户或机器人身份执行命令 -
• auth check / auth scopes:检查 scope、列出可用权限
这些设计非常不“传统 CLI”,但非常“Agent”。因为 AI 最怕的不是不会调用,而是被授权链路卡死。飞书在这里已经明显意识到:如果一个工具不能把授权做成“可中断、可恢复、可切换身份”的流程,它就很难真正进入 Agent 工作流。
3)它默认假设 AI 会犯错,所以把安全做成了前置条件
README 在“为什么选 lark-cli”里把安全写进卖点:输入防注入、终端输出净化、OS 原生密钥链存储凭证;而在“使用前必读”里又非常直接地提醒了模型幻觉、提示词注入、越权调用、敏感数据泄露等风险,并明确建议不要把这类机器人随便拉进群聊。
这点其实很关键。
很多所谓“AI 办公自动化”只谈效果,不谈边界;而 lark-cli 的设计思路是:先承认 Agent 不可靠,再为不可靠设计保护层。
它给了 –dry-run、结构化输出、scope 检查、身份切换这些能力,本质上都不是为了炫技,而是为了控制风险。
在 AI 真正开始写文档、发消息、建日程、处理会议纪要之后,这种默认保守的设计会比“功能多”更重要。
三、把它放进飞书整体布局里看,才能看懂它真正想做什么
单看 lark-cli,你会觉得这是一个“终端入口”;但如果把它和飞书最近在推进的 OpenAPI MCP、OpenClaw 飞书插件 放在一起,就会发现它其实是更大布局里的一块拼图。
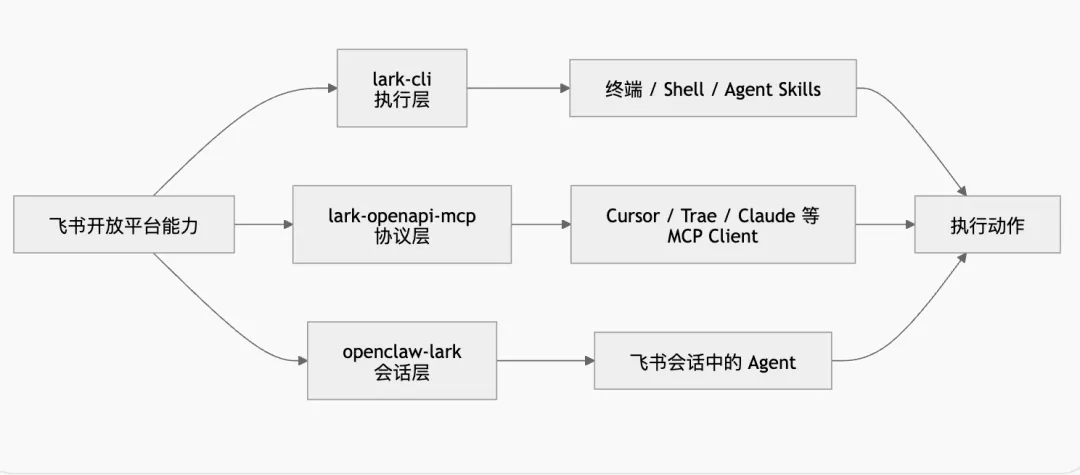
飞书官方的 lark-openapi-mcp README 写得很清楚:它是官方 OpenAPI MCP 工具,目标是帮助 AI Agent 直接调用飞书开放平台能力,实现文档处理、会话管理、日历安排等自动化场景;同时,官方文档也强调了 MCP 是面向 AI 场景对 OpenAPI 的“工具化封装”,并支持和主流 AI 工具集成。
但与此同时,官方 MCP 也明确提示目前仍在 Beta 阶段,功能与 API 可能变化;README 还特别写了两条限制:暂不支持文件上传下载,暂不支持直接编辑飞书云文档内容(仅支持导入和读取)。而 lark-cli 这边,README 已经把上传下载、文档创建更新、表格写入、邮箱、会议纪要等能力直接列入功能清单。这说明在当前阶段,MCP 更像是标准协议入口,而 CLI 更像是更全能力、更强控制的执行底座。
再看 openclaw-lark。这个官方插件不是简单的“把工具挂到聊天窗口”,它支持消息、文档、多维表格、日历、任务等读写能力,还支持 交互式卡片、流式回复、敏感操作确认、私聊/群聊权限策略、每个群单独的 allowlist 和系统提示词配置。这已经不是“AI 调个接口”了,而是在构建 AI 在飞书内部协同工作的会话操作面。
所以,飞书这条线其实已经非常清楚:
-
• lark-cli:把能力做成可执行命令 -
• lark-openapi-mcp:把能力做成标准协议工具 -
• openclaw-lark:把能力做成会话中的 Agent 行为
这不是三个分散项目,而是同一个方向的三种入口。
四、它接下来会演变成什么样
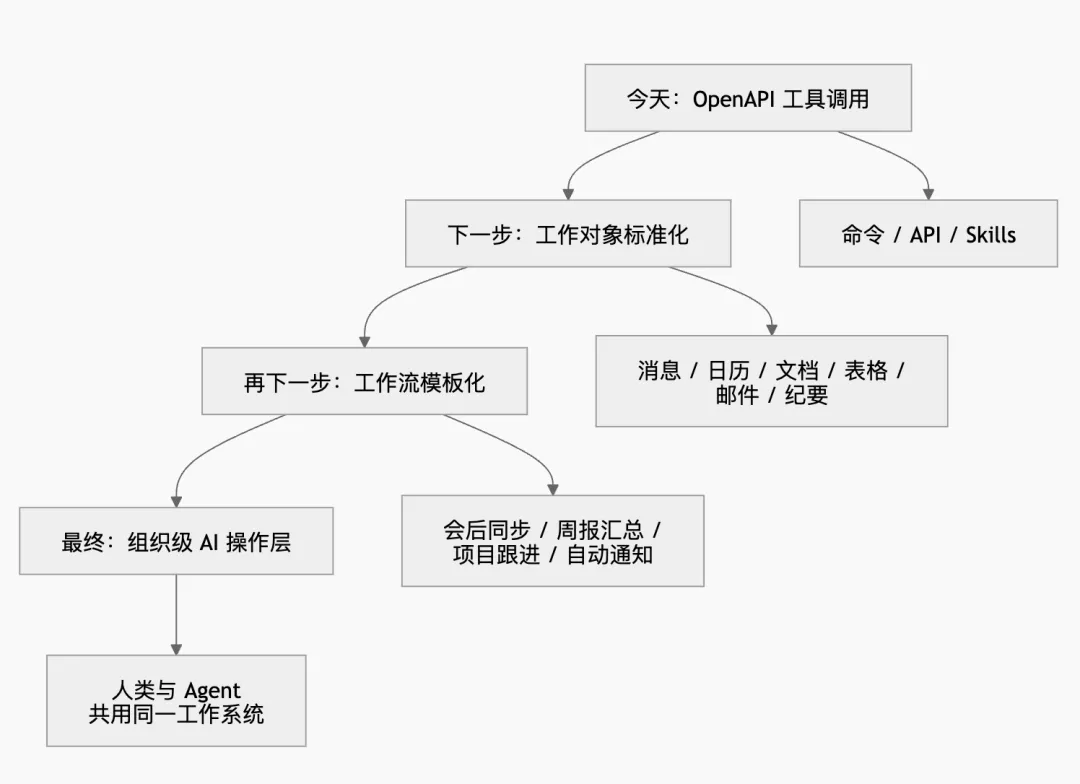
我的判断是,lark-cli 接下来大概率会沿着三个方向继续演化。
方向一:从“命令集合”变成“工作流集合”
现在它已经不只是 CRUD 工具了。Skills 列表里已经出现了 lark-workflow-meeting-summary、lark-workflow-standup-report 这种 workflow 级能力。这说明飞书团队并不满足于“让 AI 能发消息、建日程”,而是在尝试沉淀办公场景的标准动作链:读会议纪要、抽待办、写总结、更新任务、同步文档、发消息通知。
这一步一旦走深,CLI 就不会再是 API 操作工具,而会变成企业工作流模板的执行器。到那时,大家调用的可能不是“发消息接口”,而是“会后同步”“日报汇总”“项目状态对齐”这类更高层的动作。
方向二:从“Agent 能调”进化成“Agent 受治理地调”
真正的难点从来不在“能不能打通”,而在“谁能调、什么时候调、以谁的身份调、调完如何追责”。lark-cli 已经提前暴露出这个方向:scope 检查、身份切换、–dry-run、默认安全保护、群聊风险提醒;openclaw-lark 也已经把敏感操作确认和权限策略做进去了。
所以它下一阶段最值得期待的,不一定是命令数量翻倍,而可能是:
-
• 更强的策略系统 -
• 更细粒度的身份与权限边界 -
• 更好的审计日志 -
• 更强的确认与回滚机制
换句话说,未来真正决定企业是否敢大规模放权给 Agent 的,不是“功能多不多”,而是“治理够不够强”。
方向三:CLI 会成为本地执行层,MCP 会成为通用接入层
从官方文档和仓库状态来看,MCP 是明确在推进的,而且是飞书面向 AI 工具生态的标准入口;但在短中期内,CLI 仍可能是能力最全、动作最可控的执行层。这两者不会互相替代,而更可能形成分工:
-
• MCP 负责让 AI 客户端“会调用” -
• CLI 负责让动作“能完整执行” -
• 会话插件负责让交互“更适合人类协作”
这是一个很典型的 协议层 / 执行层 / 交互层 分化。
如果把这个演进过程画出来,大概会是这样:
五、它会对未来造成哪些改变
1)对开发者:办公自动化会更像软件工程,而不是脚本拼装
过去做飞书集成,典型路径是:读文档、申请权限、写后端服务、调 SDK、处理 OAuth。未来更自然的路径可能会变成:先让 AI 或自动化脚本通过 lark-cli / MCP 跑通动作,再决定哪些部分需要沉到业务代码。这会显著缩短“从想法到原型”的距离,也会让办公自动化从零散脚本,逐步变成一种更工程化、更可复用的工作系统开发方式。
2)对协同软件:飞书会从“信息承载平台”升级成“执行承载平台”
协同软件过去主要解决的是“信息怎么流动”;而当消息、文档、表格、日历、任务都被标准化成 AI 可调用的动作之后,它开始解决的是“工作如何被执行”。这意味着飞书不再只是员工工作的地方,也会逐渐变成 AI 真正干活的地方。
3)对企业软件行业:入口会从 UI 转向可授权的动作层
过去的软件入口是菜单、按钮、页面;未来的软件入口,很可能会变成一组可授权、可治理、可审计、可编排的动作。谁先把自己的业务对象变成这样的动作系统,谁就更可能成为 Agent 时代的系统入口。从飞书同时推进 CLI、MCP、会话插件的节奏看,它显然已经在为这件事铺路。
结语
如果只把 lark-cli 看成一款新开源工具,那你看到的是“飞书多了一个命令行”。但如果把它放进飞书最近的 AI 布局里看,你会发现它真正代表的是另一件事:
飞书正在把开放平台,从“给开发者调用的 API”,重新做成“给人类和 AI 共同执行工作的操作层”。
这也是为什么我觉得它值得被认真看待。因为它背后对应的,不是一个工具的流行,而是一种软件形态的变化:未来的协同平台,不只是让你“看见工作”,还要让你和 AI 一起“完成工作”。