 夜雨聆风
夜雨聆风





放弃APP,all in Skill?从底层架构拆解,AI代理时代的软件生存法则
全场在笑。但我笑完之后,开始想一个技术问题。
这个段子的内核,指向了一个非常硬核的技术命题:「当AI代理成为“劳动力”,当它需要自己挣token养活自己的时候,现有的软件架构还撑得住吗?」
或者说:「APP这套东西,还能活多久?」
这篇文章,我们从核心算法、计算架构、系统设计三个层面,拆解一下这个问题。
一、APP的技术本质:人机交互的“减速器”
先定一个技术事实:APP是给人类设计的。
为什么需要APP?因为人类操作不了底层的代码、API、文件系统。我们需要一个图形界面把复杂功能封装成可触摸、可理解的单元。APP本质上是「人机交互的中间层」。
从系统架构上看,APP有几个核心特征:
1. 状态化
APP保存用户的状态。登录态、购物车、浏览记录、编辑草稿,全存在APP里。这意味着APP的架构天然是“有状态”的。
<app_state><session_id>abc123</session_id><user_id>user_456</user_id><cart><itemid="sku_001"quantity="2"/><itemid="sku_002"quantity="1"/></cart><view_history>["home", "product_detail", "cart"]</view_history></app_state>这个状态是跨会话持久化的。用户关掉APP再打开,状态还在。这要求后端维护状态存储(通常是Redis或数据库),以及一套复杂的会话恢复机制。
2. 可视化
APP把功能映射到视觉元素。一个按钮、一个滑动条、一个下拉菜单——这些都是把函数调用封装成人类可理解的交互原语。
从渲染角度看,APP的每一帧都是通过「布局引擎」计算出来的。以Android为例:
<LinearLayout><Buttonandroid:id="@+id/submit_button"android:text="提交"android:onClick="onSubmit"/><EditTextandroid:id="@+id/input_field"android:hint="请输入"/></LinearLayout>这套UI树结构经过Measure、Layout、Draw三个阶段,最终变成屏幕上的像素。这套机制每秒要跑60次(60fps),消耗大量CPU/GPU资源。
3. 同步化
APP的交互模式是“请求-响应”。用户发起动作,APP响应。这是人类认知的天然节奏:我先点一下,然后等结果,再点下一步。
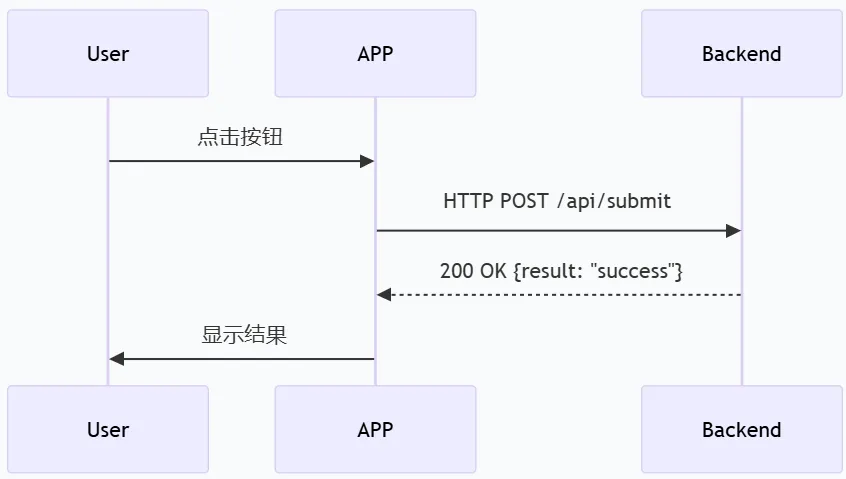
整个交互过程是同步的、线性的、由人类驱动的。APP在这个过程中充当“解释器”的角色:把人类的点击翻译成API调用,把API返回的数据翻译成可视化的结果。
「这套架构在人类用户面前很好用。但问题来了:当交互的另一端不是人类,是AI代理的时候,这套东西就变得冗余了。」
AI代理不需要UI。它能直接调用API。它能写代码操作文件系统。它不需要你画一个按钮告诉它“点击这里”,你只需要告诉它目标,它自己去拆解步骤、调用工具、执行动作。
「技术底层的变化在于:交互接口从GUI变成了API。」
二、Skill的技术定义:能力即服务
那么Skill是什么?从技术角度看,Skill不是APP的替代品,而是一种「能力封装方式」的迁移。它的技术栈和APP完全不同。
1. 无状态
Skill不保存用户状态。它接收输入,执行任务,返回结果。每一次调用都是独立的。
# Skill的核心抽象:纯函数defskill_function(input: SkillInput) -> SkillOutput:# 不依赖任何外部状态# 同样的输入,永远返回同样的输出 result = do_something(input.data)return SkillOutput(result=result)从架构角度看,这意味着Skill是「函数式的」。同样的输入,同样的输出。没有副作用。这使得AI代理可以放心地调用它,不用担心“上次调用后状态变了”。
在分布式系统中,无状态意味着:
-
「水平扩展」:任意实例都可以处理任意请求,负载均衡是天然的
-
「故障恢复」:一个实例挂了,请求可以无缝切换到另一个
-
「缓存友好」:响应可以被CDN或边缘节点缓存
2. 可组合
Skill之间可以自由组合。一个Skill的输出可以是另一个Skill的输入,形成DAG(有向无环图)式的任务流。
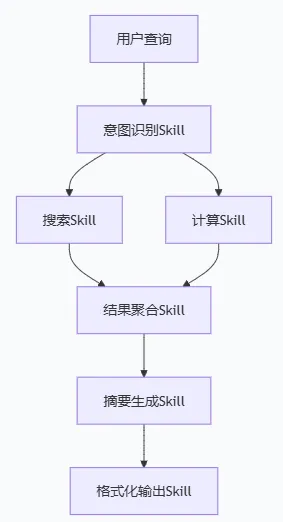
这是SOA(面向服务架构)当年没做成的事。SOA失败的原因是人类拼不动——让一个业务分析师去编排几十个服务,复杂度爆炸。
但AI代理来做了。它可以在毫秒级别决定调用哪个Skill、传什么参数、怎么处理返回值、下一步调什么。AI代理的核心算法是「链式推理」:
classAgenticOrchestrator:defexecute(self, task: str) -> Result:# Step 1: 分解任务 subtasks = self.decompose(task)# Step 2: 为每个子任务选择Skillfor subtask in subtasks: skill = self.select_skill(subtask)# Step 3: 调用Skill result = skill.call(subtask.input)# Step 4: 根据结果决定下一步 next_action = self.plan_next(result)if next_action: self.add_subtask(next_action)# Step 5: 聚合所有结果return self.aggregate()这个编排逻辑的核心是「规划算法」,类似经典AI中的STRIPS规划器,但结合了LLM的语义理解能力。
3. 可编程
Skill的本质是一段代码、一个API端点、一个函数。AI代理可以动态地调用它。
从接口定义角度看,Skill通常采用「OpenAPI规范」或「GraphQL Schema」来描述自己的能力:
# OpenAPI 3.0 定义的Skillopenapi:3.0.0info:title:天气查询Skillversion:1.0.0paths:/weather:get:parameters:-name:cityin:queryrequired:trueschema:type:string-name:unitsin:queryschema:type:stringenum:[metric,imperial]default:metricresponses:'200':description:成功content:application/json:schema:type:objectproperties:temperature:type:numbercondition:type:stringAI代理可以通过读取这个OpenAPI文档,自动理解:
-
这个Skill接受什么输入
-
输出的数据结构是什么
-
调用它需要什么参数
然后,AI代理可以「动态生成代码」来调用这个Skill:
# AI代理动态生成的调用代码import requestsdefcall_weather_skill(city: str, units: str = "metric"): response = requests.get("https://api.skill-provider.com/weather", params={"city": city, "units": units} )return response.json()# 在推理过程中调用weather = call_weather_skill("北京", "metric")这套“元编程”能力,让AI代理不需要预知任何Skill的存在,可以在运行时发现、理解、调用新Skill。
三、从APP到Skill:计算架构的底层重构
APP要变成Skill,需要一个技术前提:「APP的能力必须能被Skill调用」。这就引出一个关键趋势:「APP的API化」。
传统APP架构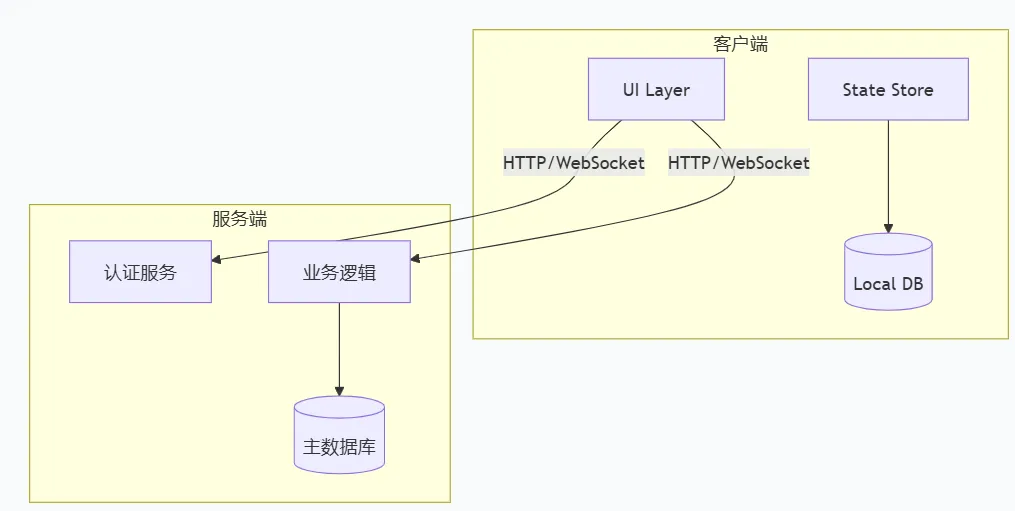
这种架构的特点是:「UI是入口,API是内部实现」。API是为UI服务的,不是独立暴露的。
Skill时代的架构
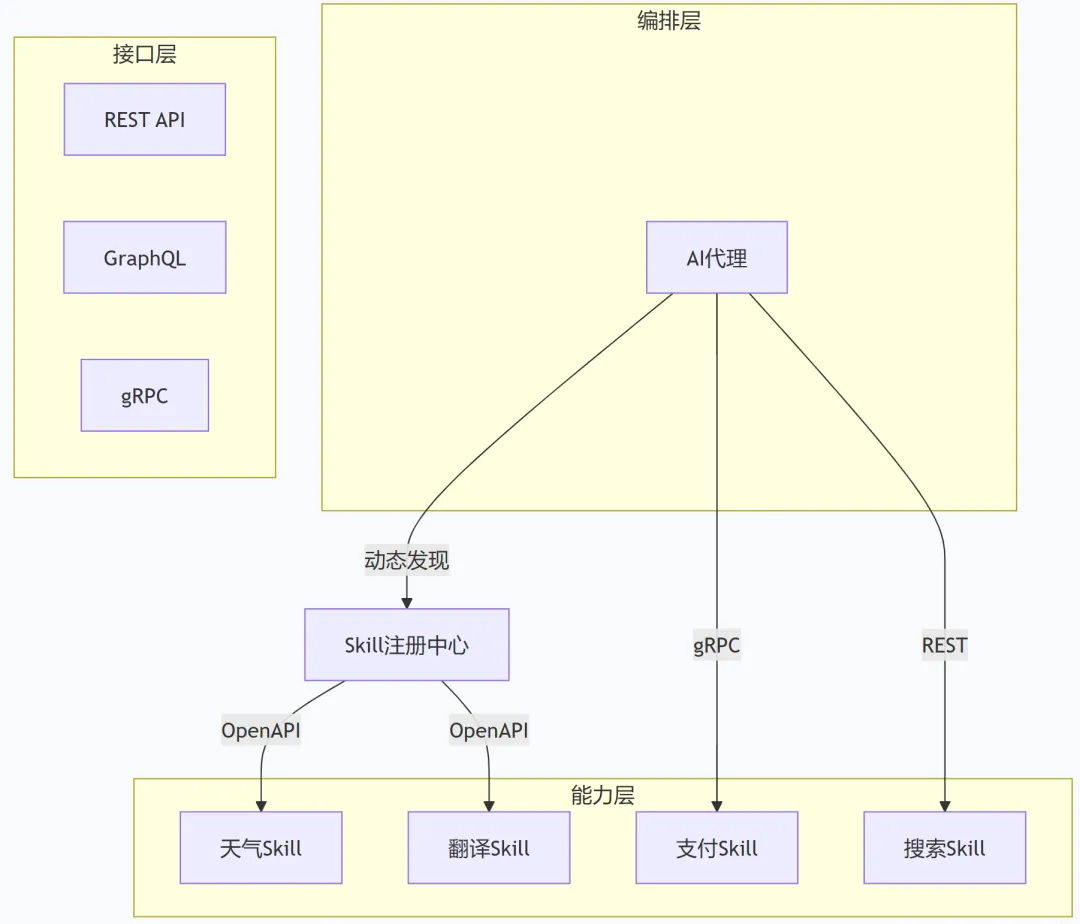
关键变化:
「1. API优先设计」:软件设计的重心,从“用户怎么点”转向“AI怎么调”。API成为一等公民,UI反而成为API的消费者之一。
「2. 机器可读的接口定义」:OpenAPI、GraphQL Schema、Protocol Buffers成为核心资产。这些格式AI代理可以直接解析。
「3. 无状态化改造」:传统APP的状态需要被剥离,变成:
-
用户身份(由认证Skill管理)
-
会话状态(由AI代理在调用链中传递)
-
业务数据(由数据Skill管理)
数据流的变化
「传统APP数据流」:
用户点击 → APP处理 → 后端API → 数据库 → 后端响应 → UI渲染 → 用户看到「Skill时代数据流」:
用户意图 → AI代理 → 任务分解 → Skill调用链 → 聚合结果 → 返回后者没有UI渲染,没有状态管理,没有事件循环。只有「函数调用和返回值」。
四、Skill的核心算法:从规划到执行
Skill生态的核心是AI代理的「规划算法」。这个算法决定了Skill能否被有效编排。
4.1 任务分解算法
给定一个自然语言任务,AI代理需要把它分解成可执行的Skill调用序列。
这是「层次化任务规划」问题,结合了LLM的语义理解和经典规划算法。
classTaskDecomposer:defdecompose(self, task: str) -> List[Subtask]:# Step 1: LLM生成候选子任务 prompt = f""" 将以下任务分解为子任务列表: 任务:{task} 输出格式(JSON数组): [ {{"name": "子任务1", "description": "..."}}, {{"name": "子任务2", "description": "..."}} ] """ subtasks_json = llm.generate(prompt) subtasks = parse_json(subtasks_json)# Step 2: 验证依赖关系 subtasks = self.validate_dependencies(subtasks)# Step 3: 构建DAG dag = self.build_dag(subtasks)return dag4.2 Skill选择算法
给定一个子任务,AI代理需要从成千上万个Skill中选择最合适的一个。
这是「函数调用(Function Calling)「问题的规模化版本。核心算法是」嵌入检索 + 精排」:
classSkillSelector:def__init__(self):# 预先计算所有Skill的嵌入向量 self.skill_embeddings = {}for skill in self.skill_registry: self.skill_embeddings[skill.id] = self.embed(skill.description)defselect(self, subtask: SubTask, top_k: int = 5) -> List[Skill]:# Step 1: 嵌入检索 subtask_embedding = self.embed(subtask.description) candidates = []for skill_id, skill_emb in self.skill_embeddings.items(): similarity = cosine_similarity(subtask_embedding, skill_emb) candidates.append((skill_id, similarity))# 取top_k candidates.sort(key=lambda x: x[1], reverse=True) top_candidates = candidates[:top_k]# Step 2: LLM精排 prompt = f""" 子任务:{subtask.description} 候选Skill:{[self.skill_registry[skill_id].description for skill_id, _ in top_candidates]} 选择最合适的Skill,返回ID。 """ best_id = llm.generate(prompt)return self.skill_registry[best_id]4.3 执行与重规划
Skill调用可能失败或返回意外结果。AI代理需要能够「重规划(replan)」。
classExecutor:defexecute_with_replan(self, dag: DAG, max_retries: int = 3) -> Result: execution_stack = []for node in topological_sort(dag): skill = node.skill input = node.inputfor attempt in range(max_retries):try: output = skill.call(input) execution_stack.append(output)breakexcept SkillError as e:if attempt == max_retries - 1:# 重试失败,触发重规划return self.replan(dag, node, e)return self.aggregate(execution_stack)defreplan(self, original_dag: DAG, failed_node: Node, error: SkillError) -> Result:# Step 1: 标记失败节点# Step 2: 重新规划从失败节点开始的子图 subtask = failed_node.subtask new_plan = self.planner.plan(subtask, error.context)# Step 3: 替换失败节点 new_dag = self.replace_subgraph(original_dag, failed_node, new_plan)# Step 4: 继续执行return self.execute_with_replan(new_dag)这套算法本质上是在「执行时动态调整规划」,类似强化学习中的“事后经验回放”(HER)思想。
五、APP的“硬核场景”:为什么它们不会消失
从技术角度分析,有些场景APP会长期存在。这背后是计算架构的根本约束。
1. 高频、低延迟场景
你打开手机看天气、回微信、扫付款码,这些动作已经形成肌肉记忆。
从延迟角度看:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
这个差距是物理定律决定的:光速限制加上推理时间,云端调用不可能低于100ms。对于高频操作,人类会自然选择更快的路径。
2. 创作类场景
你修图、剪视频、写代码的时候,你需要的是「实时交互性」——看到每一个参数的即时反馈。
从计算架构看,这类场景需要「状态保持」和「连续交互」:
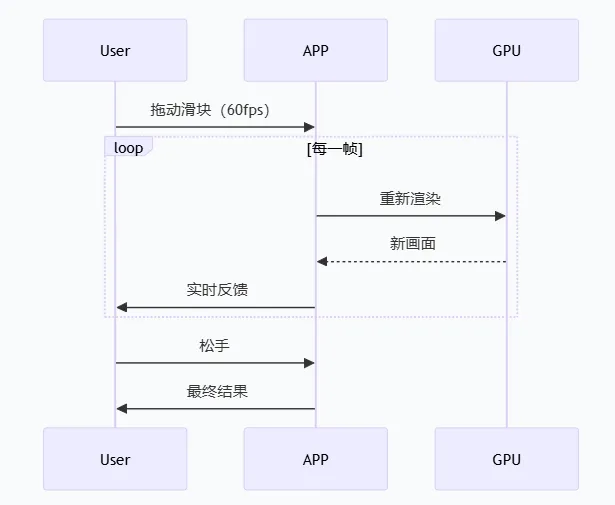
这种60fps的连续交互,AI代理做不到。因为它需要每一帧都调用Skill,而Skill调用的延迟在百毫秒级。这是「计算架构的带宽限制」,短期内无法突破。
3. 安全敏感场景
从安全架构看,APP的“隔离性”是硬性安全边界。
<security_boundary><!-- APP运行在独立沙箱 --><sandboxid="bank_app"><capabilities><capability>访问摄像头</capability><capability>访问安全元件</capability><capability>网络通信(仅限bank.com)</capability></capabilities><restrictions><restriction>不能访问其他APP数据</restriction><restriction>用户手动输入密码才可交易</restriction></restrictions></sandbox></security_boundary>要让AI代理调用银行Skill,需要一套「机器可读的授权协议」,替代现有的OAuth(给人类设计的)。技术上,这需要「零信任架构」和「可验证计算」:
# 理想的安全模型classMachineAuthorization:defauthorize(self, agent_id: str, skill_id: str, scope: str) -> Token:# Step 1: 验证代理身份 agent_identity = self.verify_agent(agent_id)# Step 2: 检查权限策略 policy = self.policy_engine.get_policy(skill_id)ifnot policy.check(agent_identity, scope):raise AuthorizationError()# Step 3: 生成可审计的、一次性的授权Token token = self.generate_token( agent=agent_id, skill=skill_id, scope=scope, expires_in=300, # 5分钟 audit_log=True )return token这套技术远未成熟,因此敏感场景仍需要人类手动操作。
六、Skill时代的核心技术挑战
如果Skill成为主流,有几个技术问题必须解决。
6.1 服务发现
AI代理怎么知道世界上有哪些Skill可用?
需要一套「机器可读的Skill目录协议」:
<skill_registry><skillid="weather_001"><name>全球天气查询</name><provider>WeatherAPI Inc.</provider><api_spec>https://api.weatherapi.com/openapi.yaml</api_spec><cost><model>per_call</model><price>0.001</price><currency>USD</currency></cost><latency_p99>120</latency_p99><!-- ms --><availability>99.95</availability><!-- % --><tags><tag>weather</tag><tag>geolocation</tag></tags></skill></skill_registry>AI代理需要能够:
-
自动拉取这个目录
-
解析OpenAPI规范
-
根据任务和成本选择最合适的Skill
6.2 安全与授权
OAuth流程是给人类设计的:
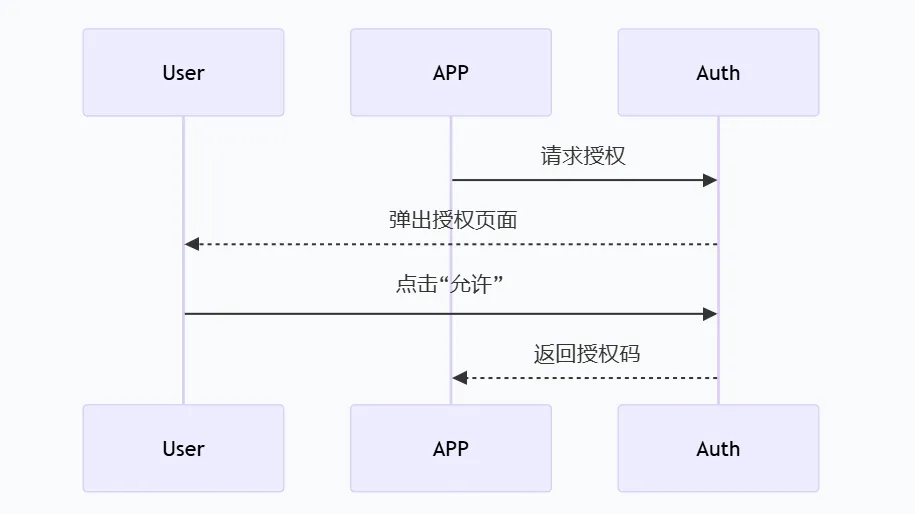
AI代理不能点“允许”。需要一套「机器可读的授权协议」,可能是:
<authorization_request><agent_id>agent_123</agent_id><agent_type>AI_assistant</agent_type><skill_id>bank_transfer</skill_id><requested_scope><scope>transfer:execute</scope><scope>balance:read</scope></requested_scope><policy_constraints><max_amount>1000</max_amount><require_2fa>false</require_2fa><allow_recurring>false</allow_recurring></policy_constraints></authorization_request>用户通过一次授权,定义规则,AI代理在规则内自动执行。
6.3 成本与计费
Skill模式下,算力成本是实打实的。需要一套「按价值分成的计费系统」:
classSkillBilling:defsettle(self, task_id: str, result: Result) -> Invoice:# Step 1: 计算所有Skill的原始成本 total_cost = 0for call in task.skill_calls: skill = self.skill_registry[call.skill_id] total_cost += skill.cost_per_call# Step 2: 评估任务价值 value = self.value_estimator.estimate(result)# Step 3: 计算分成if value > total_cost:# 有利润,按比例分 profit = value - total_cost shares = self.distribute_profit(profit, task.skill_calls)else:# 亏损,用户支付成本 shares = total_cost# Step 4: 生成账单return Invoice( user=task.user_id, total=shares, breakdown=[call.skill_id for call in task.skill_calls] )这要求「可验证的任务完成证明」——一个中立机制,让各方都认可“这个任务确实完成了,且价值多少”。
6.4 可靠性
在代理式系统里,任何一个Skill的不可用,都会导致整个任务失败。
需要一套「分布式系统的容错机制」:
classResilientOrchestrator:defcall_with_retry(self, skill: Skill, input: Input) -> Output:for attempt in range(MAX_RETRIES):try:return skill.call(input)except TimeoutError:if attempt == MAX_RETRIES - 1:raisecontinueexcept ServiceUnavailable:# 熔断:快速失败if self.circuit_breaker.is_open(skill.id):raise CircuitOpenError() self.circuit_breaker.record_failure(skill.id)continueexcept RateLimitError:# 指数退避 backoff = 2 ** attempt time.sleep(backoff)continue# 重试失败,调用备用Skillreturn self.fallback_skill.call(input)还需要「补偿事务」来处理部分成功的情况:
classCompensator:defexecute_transaction(self, skill_calls: List[SkillCall]) -> Result: completed = []for call in skill_calls:try: result = call.execute() completed.append((call, result))except Exception as e:# 回滚所有已完成的调用for completed_call, result in completed: completed_call.compensate(result)raise TransactionError(f"失败于 {call.skill_id}: {e}")return self.aggregate(completed)七、总结:计算架构的范式迁移
从技术底层看,Skill和APP是「两个不同时代的计算抽象」。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
APP是面向人类交互的软件形态,技术栈围绕UI、事件、状态。Skill是面向机器交互的软件形态,技术栈围绕API、无状态、可组合。
AI代理成为主流交互主体时,Skill的重要性会超过APP。但APP不会消失——它只是从主角变成配角,从用户直接面对的对象,变成AI后台默默调用的能力单元。
老黄的那个段子,说到底是在问:「当AI代理需要自己挣token养活自己,什么软件形态能帮它最高效地完成任务?」
答案不是APP。APP太重了,太有状态了,太依赖人类交互了。答案是那些能被代码调用的、无状态的、可组合的能力单元——也就是Skill。
至于APP,它们还在。只是以后,它们的用户不全是人了。
还有“龙虾”。
❝
(注:本文仅为短期个人认知,如有不同意见欢迎评论区讨论。)
❞