 夜雨聆风
夜雨聆风





写了个 OpenClaw 插件,让多模型自动分工
起因
我在 OpenClaw 上配了好几个模型:百炼的 glm-5 做日常聊天,qwen3-coder-plus 写代码,kimi-k2.5 做图片理解和翻译。
但实际用下来,体验挺割裂的。
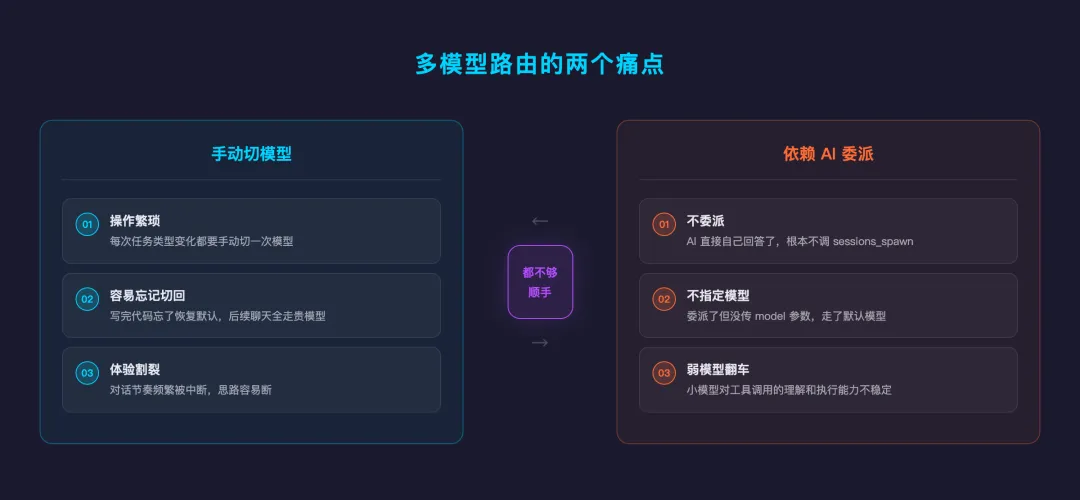
最直接的做法是手动切模型。写代码前切到 coder,写完再切回来。翻译时再切到 kimi,翻完又切回去。这事儿一天做几次就很烦了,而且经常忘了切回来,下一次聊天才发现还挂在 coder 上。
另一个思路是不切模型,在聊天里告诉 AI「用 xxx 模型帮我做这件事」,让它通过 sessions_spawn 创建子 agent 去处理。但这完全依赖主模型的理解和执行能力。实际试下来问题不少:有时候它直接自己回答了,根本不委派;有时候委派了但没指定模型;有时候理解错了你的意图。弱一点的模型在这方面尤其不稳定。
所以问题的本质是:手动切太麻烦,纯靠 AI 判断又不够可靠。
三种路由方式,各有取舍
想清楚问题之后,我设计了三种路由方式,按优先级从高到低:
1. 用户显式指定
在消息里直接说「用 coder 模型看看这段代码」「切换到 claude」「use kimi model」「@kimi 翻译一下」,插件用正则从消息里提取模型名,直接切过去。
这个最简单,也最可控。用户主动说了要用什么,那就用什么,不需要任何猜测。插件会同时识别 /route as 设置的别名和 openclaw.json 里配置的内置别名,两边都能用。
2. 关键词精确匹配
提前配好规则,比如消息里出现「代码」「bug」「debug」就走 coder,出现「翻译」「translate」就走 kimi。
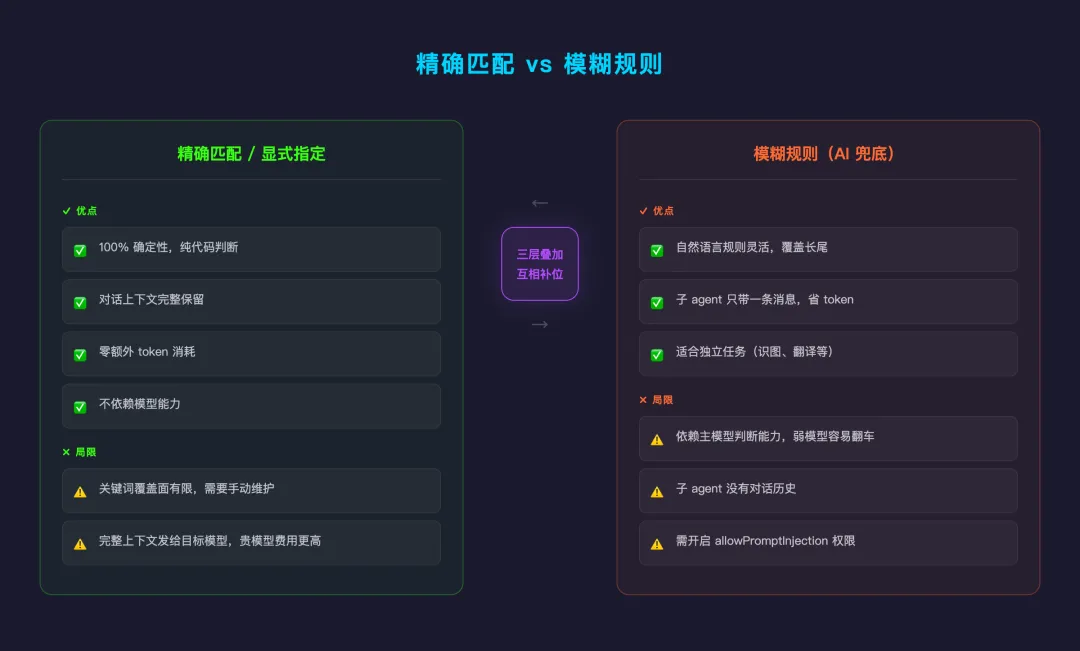
这一层走的是 OpenClaw 的 before_model_resolve 钩子,纯代码判断,不经过 AI。好处是 100% 确定性,不消耗额外 token,不依赖模型能力。缺点也明显:关键词覆盖不了所有情况,用户的表述千变万化,总有漏网的。
而且这种方式切的是「整条消息的模型」,对话上下文完整保留,不会像子 agent 那样丢失历史。
3. 模糊规则(AI 判断兜底)
对于关键词覆盖不到的场景,我保留了 AI 判断这条路。通过 before_prompt_build 钩子把自然语言规则注入 system prompt,让主模型自己判断要不要委派给子 agent。
比如你可以写一条规则:「处理图片相关任务用 kimi-k2.5」。这种表述关键词很难穷举,但 AI 理解起来很自然。
代价是:它依赖主模型的能力,弱模型可能误判或不执行;子 agent 没有对话历史,只带一条 task 消息;而且需要开启 allowPromptInjection 权限。

为什么不只用一种
单独看每种方式都有明显的短板。
只用精确匹配?覆盖面不够,总有规则漏掉的情况。
只用模糊规则?全部依赖 AI 判断,不稳定,弱模型容易翻车。
只用显式指定?那跟手动切模型没多大区别,只是换了个入口。
所以最后的方案是三层叠加:精确匹配兜住高频场景,模糊规则覆盖长尾,显式指定作为用户的最终控制手段。精确匹配命中后,模糊规则不会再执行,避免重复判断。
实际用下来,日常 80% 以上的路由靠精确匹配就够了,模糊规则更多是补漏,显式指定偶尔用一下。
上下文的区别,这点很关键
这三种方式在「对话上下文」上的差异挺大的,直接影响适用场景。
精确匹配和显式指定,走的是模型切换。也就是说,这条消息交给另一个模型回答,但整个对话历史都在。你之前聊了什么、发了什么文件、讨论了什么背景,目标模型全部能看到。体验上就像「换了个人接着聊」,不会断片。适合需要上下文的任务,比如你聊了半天代码,然后说「帮我重构一下刚才那个函数」,coder 模型能看到之前的完整讨论。
模糊规则走的是子 agent 委派。主模型判断命中规则后,会创建一个全新的子 agent,只把当前这一条消息作为 task 发过去。子 agent 看不到之前的对话历史,它是一个独立的、一次性的任务。
这意味着两件事:
一是省 token。子 agent 不需要重新发送整段对话历史,只处理一条消息,对于那种「翻译这句话」「识别这张图」之类的独立任务,其实正好。
二是不适合需要上下文的场景。如果你之前聊了很多背景,然后触发了模糊规则委派,子 agent 是不知道那些背景的。它只看到你最后发的那条消息。
所以我自己的用法是:高频的、经常需要上下文的任务(比如代码),用精确匹配,走模型切换,上下文完整保留。偶发的、本身就是独立任务的(比如识图、单句翻译),用模糊规则,走子 agent,省 token 也够用。

模型标注:知道当前用的是什么
路由做完之后,我发现还有一个问题:用户看到回复,但不知道这条回复是哪个模型生成的。
尤其是模糊规则触发子 agent 委派的时候,回复到底是主模型的还是子模型的,很容易搞混。
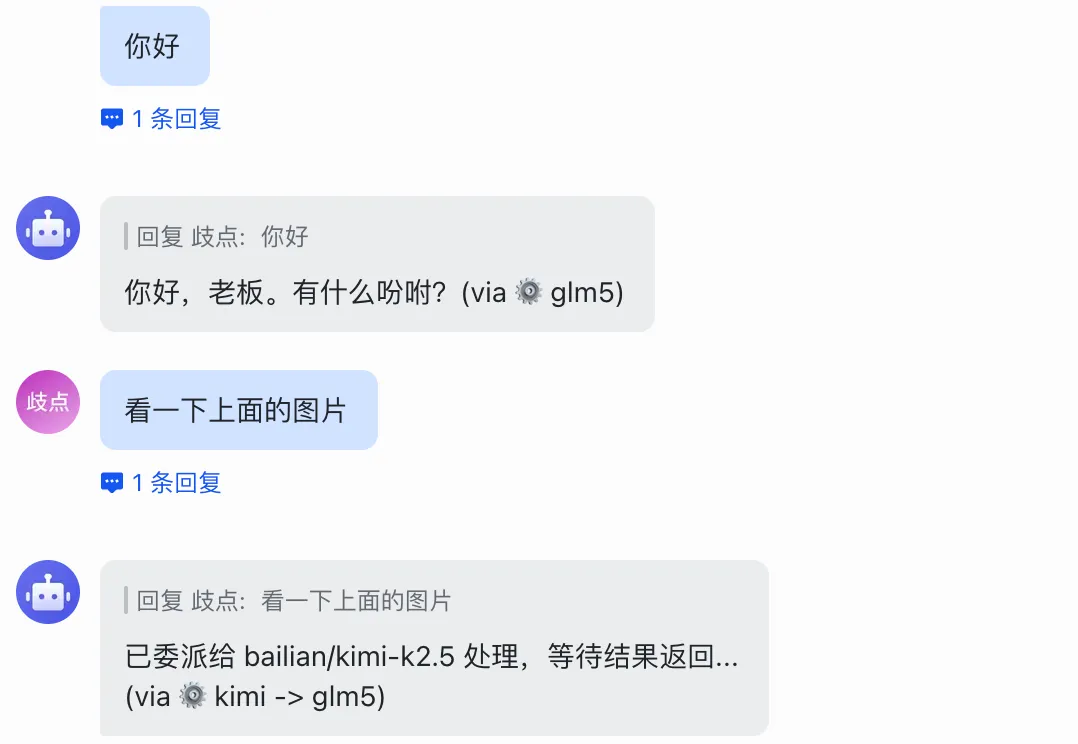
所以我加了一个「模型标注」功能,每条回复末尾会自动附上:
(via ⚙️ glm5)
如果是子 agent 委派的,还会标注完整链路:
(via ⚙️ kimi -> glm5)
这个标注目前是通过提示词注入实现的:在 before_prompt_build 钩子里往 system prompt 追加一条指令,要求模型在回复末尾加上标签。代码里也写了 message_sending 钩子作为兜底,在发送前强制改写标签格式。但实际上大部分 IM 平台(飞书、微信、Telegram 等)不会触发 message_sending,所以标注主要还是靠模型遵循提示词。
这意味着标注的稳定性取决于你用的模型。能力强的模型基本每次都能正确标注,弱一点的可能偶尔漏掉或格式不对。不完美,但至少大部分时候能看到当前用的是什么模型。
怎么用
先装插件:
git clone https://github.com/HuaxinLab/smart-model-router.gitopenclaw plugins install smart-model-router/plugin
如果你需要用模糊规则(精确匹配不需要),还得开一个权限:
openclaw config set plugins.entries.smart-model-router.hooks.allowPromptInjection true然后重启 gateway:
openclaw gateway restart装好之后,核心操作就这几步。
先看看有哪些模型可用:
/route models
给常用模型起个短别名:
/route as coder=bailian/qwen3-coder-plus
/route as kimi=bailian/kimi-k2.5
加几条精确匹配规则:
/route add 代码,code,bug,debug = coder
/route add 翻译,translate = kimi
如果需要,再加一条模糊规则:
/route ai 处理图片相关任务用 kimi
检查当前配置:
/route ls
之后正常聊天就行了。
> 注:更多命令参数可以使用 /route help 查看

实际的优缺点
先说好用的地方。
精确匹配这一层体验确实很顺,命中率高,零延迟,不消耗额外 token,而且保留完整对话上下文。日常高频场景基本靠这个就够了。
模型标注很直观,每条回复都能看到用了什么模型,调规则的时候特别有用。
别名系统省了很多记忆负担,不用每次都输入 bailian/qwen3-coder-plus 这种长串。
再说目前的局限。
精确匹配靠关键词,覆盖面有限。比如用户说「帮我重构一下这个函数」,如果你没把「重构」加进关键词,就不会命中。需要自己慢慢补。
模糊规则依赖主模型的能力。如果你的默认模型比较弱,可能出现该委派不委派、不该委派乱委派的情况。
模糊规则走子 agent,没有对话历史。这意味着如果你之前聊了很多上下文,子 agent 是看不到的,它只拿到当前这一条消息。
规则需要自己配。这个插件不会自动帮你决定「代码该用什么模型」,你得自己想清楚规则逻辑,自己维护。
写在后面
这个插件的想法很简单:我配了好几个模型,想让它们各司其职,但手动切太烦,纯靠 AI 判断又不稳。
最后的方案是把确定性的事情交给代码(精确匹配 + 模型切换),不确定的事情交给 AI 兜底(模糊规则 + 子 agent),再给用户留一个最终控制入口(显式指定)。三者按优先级叠加。
目前我自己用下来,最大的感受是:日常不用再想「该切到哪个模型」这件事了。大部分时候精确匹配就搞定了,偶尔模糊规则补一下,实在不行手动指定。
如果你也在 OpenClaw 上配了多个模型,可以试试看,也欢迎反馈。
项目地址:https://github.com/HuaxinLab/smart-model-router