 夜雨聆风
夜雨聆风





PDF为什么能跨平台保持版面一致?从存储结构、绘制指令到渲染流程讲透
引言
很多人都有过这种体验:同一份 Word 文档,在自己的电脑上排版完美,发给别人后却出现换行错位、字体变化、表格变形。问题往往不在内容本身,而在于文档依赖了外部环境,比如字体、排版引擎、系统设置和软件版本。
PDF(Portable Document Format,便携式文档格式)之所以长期被用于合同、论文、手册和印刷交付,不是因为它“更像文档”,而是因为它更像一份「页面最终呈现结果的描述文件」。它的核心目标不是“方便编辑”,而是“尽可能稳定地复现版面”。
理解这一点,就能理解 PDF 为什么常被称为“所见即所得”,也能理解为什么 PDF 的文字提取、表格识别和二次编辑往往没有想象中那么简单。
一、PDF解决的根本问题:不是保存内容,而是保存页面结果
在 PDF 出现之前,电子文档交换主要依赖两种方式:
-
「原始文件交换」:例如 Word、PageMaker 或其他排版软件格式。这类文件保留了大量“可编辑信息”,但也严重依赖创建时的软件环境。 -
「打印输出」:纸质打印能保证版面一致,但失去了电子文档的搜索、复制、传输和归档优势。
1990年代,Adobe 推出的 PDF 试图解决的核心问题是:「如何把一页文档最终应该长什么样,稳定地交给另一台机器复现出来。」
所以从设计哲学上说,PDF更接近:
-
一份“页面说明书” -
一套“绘制命令集合” -
一个“排版结果快照”
而不是传统意义上“带结构的可编辑文档源文件”。
二、PDF里存的到底是什么:不是段落本身,而是绘制指令
很多人会自然地以为,PDF 内部保存的是“标题、段落、表格、图片”这些高级结构。但从底层看,PDF 更接近一种「页面描述语言」。
阅读器看到的不是“这里有一段正文”,而是类似这样的信息:
-
在页面某个坐标 (x, y)开始绘制 -
使用某种字体和字号 -
绘制某个字形(glyph) -
画一条线、一个矩形或一段曲线 -
把某张图像放到指定区域
也就是说,PDF 存储的核心不是“文档语义”,而是“如何把这一页画出来”。
一个非常简化的内容流示意如下:
BT % Begin Text/F1 12 Tf % 选择字体 F1,字号 12100 700 Td % 把文本起点移动到 (100, 700)(Hello PDF) TjET % End Text100 680 m % move to300 680 l % line toS % stroke其中常见内容大致可以分为三类:
-
「文本对象」:字形、字体、字号、位置 -
「图形对象」:直线、矩形、贝塞尔曲线、描边和填充 -
「图像对象」:位图资源及其放置方式
这也是理解 PDF 的第一把钥匙:「PDF 本质上不是在“存文章”,而是在“存绘制结果”。」
三、为什么它能“看起来几乎一致”:因为它尽量把渲染所需信息一起带走
PDF 跨平台一致性的基础,在于它尽量把页面呈现所需的资源和指令封装在文件里,而不是依赖接收方环境临场决定。
1. 字体信息尽量内嵌
字体差异是文档走样的主要来源之一。PDF 常见的做法包括:
-
「完整嵌入字体」:把字体程序或相关字形信息放进 PDF -
「子集嵌入」:只嵌入实际用到的字符,以减小体积 -
「保留字体描述信息」:即使没有完整嵌入,也尽量给出足够信息帮助阅读器处理
但这里要注意,PDF 并不天然保证“所有字体都一定嵌入”。如果字体缺失,阅读器可能会用本地字体替代,而这正是不同设备偶尔仍会出现差异的原因。
2. 坐标和绘制命令是设备无关的
PDF 页面通常使用设备无关的坐标体系来描述元素位置。阅读器负责把这些坐标映射到屏幕像素或打印机分辨率。
因此,PDF 关注的是:
-
元素应该在页面什么位置 -
以什么大小绘制 -
使用什么颜色、线宽、透明度和混合方式
而不是“当前这台电脑的窗口宽度是多少”“系统默认字体是什么”。
3. 矢量图形让缩放和打印更稳定
PDF 中大量图形和文字轮廓可以以矢量方式描述。矢量内容不是按像素点死存,而是按几何规则来画,因此放大或打印时通常比位图更稳定。
当然,这里也不能理解成“无论怎么放大都绝对不会失真”。最终显示仍然要经过阅读器栅格化到具体设备上,边缘平滑、文字 hinting、颜色管理等实现细节,仍可能带来细微差异。
四、PDF文件怎么组织:它不是一团文本,而是一套对象系统
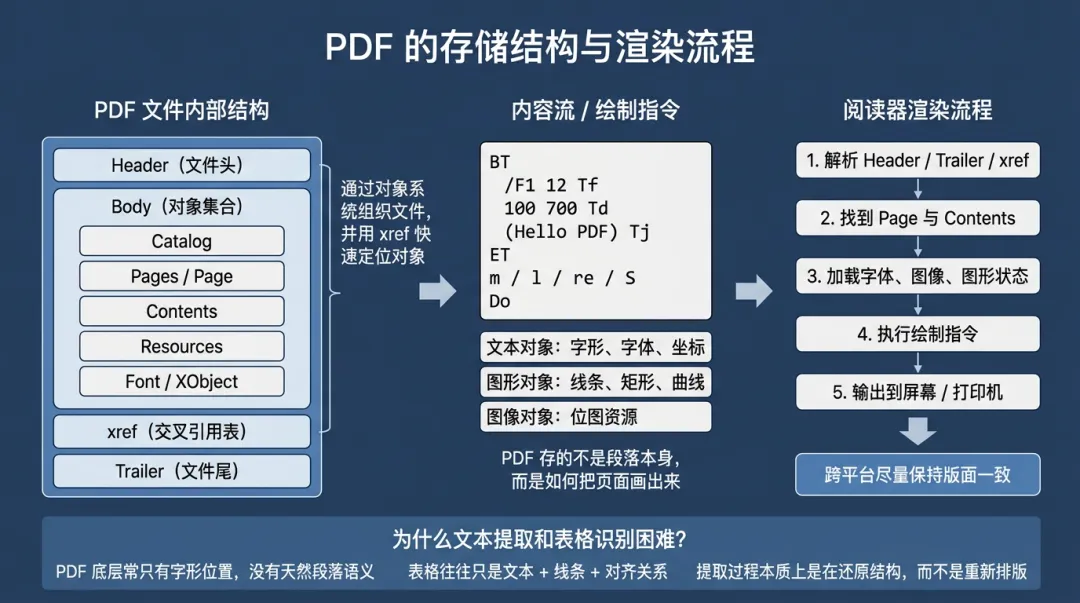
PDF 文件内部不是简单顺序写入的纯文本,而是由一组对象构成的结构化容器。典型结构可以概括为四部分:
1. 文件头(Header)
用于声明这是 PDF 文件,以及它遵循的大致版本,例如 %PDF-1.7。
2. 文件体(Body)
这里存放真正的对象,例如:
-
「Catalog 对象」:整份文档的入口 -
「Pages / Page 对象」:页面树和单页定义 -
「Contents 对象」:页面内容流,也就是绘制指令 -
「Resources 对象」:字体、图像、颜色空间等资源 -
「Font / XObject 等对象」:具体资源的定义
3. 交叉引用表(Cross-Reference Table,xref)
它记录“每个对象在文件中的偏移位置”。阅读器无需从头到尾扫描整份文件,就能快速跳到指定对象。
4. 文件尾(Trailer)
这里会告诉阅读器:
-
根对象是谁 -
xref 在哪里 -
整个对象系统该从哪里开始解析
可以把它粗略理解成:
Header -> Body(objects) -> xref -> Trailer这种对象化组织方式,让 PDF 既便于随机访问,也有机会在部分损坏时做一定程度的恢复。
五、从“存储”到“显示”:PDF阅读器到底做了什么
当你双击一个 PDF,阅读器并不是“把文章显示出来”这么简单,而是在执行一套从文件结构到图形输出的流程。
1. 解析文件结构
阅读器先读文件头、文件尾和 xref,找到文档根对象,再顺着页面树找到每一页对应的内容流和资源。
2. 解析页面内容流
接着它会读取该页的绘制指令,例如:
-
进入文本对象 -
切换字体和字号 -
移动到新坐标 -
绘制字形 -
画线、画表格边框、填充图形 -
引入图像资源
这一阶段本质上是在“解释执行页面脚本”。
3. 加载字体、图像和图形状态
如果字体或图像资源嵌在 PDF 中,阅读器就直接使用;如果某些资源没有完整嵌入,阅读器则需要做兼容处理或替代。
图形状态也会被逐步维护,例如:
-
当前字体 -
当前颜色 -
当前线宽 -
当前变换矩阵 -
当前透明度和混合模式
4. 输出到屏幕或打印设备
最后,阅读器把这些设备无关的页面描述,转换为当前输出设备能理解的像素或打印命令。
因此,PDF 的“所见即所得”并不是魔法,而是因为:
-
页面是什么样,文件里描述得足够具体 -
需要什么资源,文件里通常会一起提供 -
阅读器的任务不是自由排版,而是尽量忠实执行这些描述
六、为什么PDF文字提取和表格识别经常很难
理解 PDF 的存储方式后,就能明白一个常见误区:「PDF 看起来像文档,但底层未必真的保留了文档语义。」
1. PDF里不一定有“段落”这个概念
在很多 PDF 里,阅读器真正拿到的只是:
-
某个字形画在什么位置 -
几个字形之间间距是多少 -
哪些线条组成了边框
至于“这几行是不是同一段”“这里是不是一个表格单元格”,往往不是文件直接告诉你的,而是后续工具根据位置关系推断出来的。
2. 文本提取常常是在“还原结构”
像 PyMuPDF、Poppler 这类工具,很多时候不是在做 OCR,而是在「解析 PDF 内部对象和编码映射」。
如果映射完整,工具能直接得到:
-
字符或字形信息 -
每个字符的 bounding box -
字体和位置数据
然后再根据坐标关系去推断:
-
哪些字符属于同一行 -
哪些行属于同一块文本 -
哪些间距意味着空格、列分隔或换段
所以 PDF 文本抽取的难点通常不是“识别笔画”,而是“从绘制结果中还原阅读结构”。
3. 表格识别更难,因为表格常常根本不是“表格对象”
在很多 PDF 里,表格并不是一个高层语义对象,而只是:
-
一堆文本 -
几条横线和竖线 -
或者甚至连线都没有,只靠对齐来表现列结构
于是表格识别工具只能综合判断:
-
文本块的横纵坐标 -
对齐关系 -
线条和矩形边框 -
空白区域分布
这就是为什么同样一份表格,在“看起来很规整”的情况下,程序提取结果仍可能很差。
七、PDF为什么能跨平台,但又不是“绝对一致”
PDF 的目标是最大化跨平台版面一致性,但它并不意味着“任何 PDF 在任何设备上都 100% 完全相同”。
常见差异来源包括:
-
字体没有完整嵌入,阅读器发生替代 -
不同渲染引擎对抗锯齿、hinting、透明度混合的实现不同 -
颜色管理、ICC 配置和打印链路不同 -
表单、JavaScript、多媒体、3D 等高级特性支持程度不同 -
某些老旧或非标准 PDF 文件本身就存在兼容问题
所以更准确的说法是:「PDF 通过标准化的页面描述和资源封装,让文档在不同平台上尽量稳定复现,而不是绝对消灭一切差异。」
八、标准化为什么重要
PDF 最初由 Adobe 推出,后来逐步标准化。2008 年,PDF 1.7 成为 ISO 32000 国际标准,这意味着:
-
不同厂商可以依据统一规范实现解析与渲染 -
市场上出现了丰富的阅读器和库实现 -
跨平台兼容性不再只依赖单一厂商
这里可以举的例子包括:
-
商业阅读器:Adobe Acrobat、Foxit -
浏览器/开源实现:PDF.js -
桌面生态中的常见引擎与阅读器:Preview、Evince、Okular 等
标准化并不能保证所有实现“像素级完全一样”,但它极大提高了“同一份 PDF 被大致一致解释和渲染”的概率。
九、PDF的优势与局限
1. 优势
-
「版面稳定」:适合合同、论文、票据、印刷交付 -
「跨平台强」:对系统、软件环境依赖较小 -
「适合归档和分发」:格式成熟、阅读器普及 -
「可容纳复杂页面元素」:文本、矢量图、图像、表单、注释等
2. 局限
-
「不擅长深度编辑」:因为它保存的是排版结果,不是创作过程 -
「语义结构常常不足」:对重排、抽取、结构化分析不友好 -
「移动端自适应较差」:不如 HTML、EPUB 这类流式格式 -
「复杂特性兼容不完全一致」:尤其是表单脚本、多媒体和打印链路
总结
PDF 之所以能在不同设备上保持“看起来几乎一致”,关键不在于它把“文章内容”保存得多聪明,而在于它把“页面该如何被画出来”描述得足够具体。
从底层看,PDF 的核心是三件事:
-
「用对象系统组织文件结构」 -
「用内容流保存页面绘制指令」 -
「用设备无关的方式描述文本、图形和图像的呈现」
而从使用体验看,PDF 的本质可以概括为一句话:
「它更像“最终排版结果的可移植封装”,而不是“可自由编辑的内容源文件”。」
这也解释了两个现象:
-
为什么 PDF 特别适合分发、打印、归档和跨平台查看 -
为什么 PDF 的文本抽取、表格识别和二次编辑,往往比想象中更难
如果你真正理解了“PDF 存的是绘制结果,而不是天然的语义结构”,那么 PDF 的显示一致性、编辑困难,以及各种解析工具的行为逻辑,都会一下子变得清晰起来。