 夜雨聆风
夜雨聆风





看完 Claude Code 源码后,我更关注它那些“不像 AI”的部分
但把代码真正往下读,会发现更值得讨论的,其实不是那 5% 左右直接调用 LLM 的部分,而是剩下那一大块“非 AI”工程。
已披露的信息显示,Claude Code 大约有 51.2 万行 TypeScript、1903 个文件。真正直接和模型 API 打交道的代码,占比可能不到总量的 5%。其余绝大部分,都是围绕模型搭出来的一整套运行机制:权限、上下文、记忆、工具、安全、流程控制、Prompt 编排、缓存管理。
这件事很说明问题。
Claude Code 的竞争力,并不只是“模型够强”,而是它默认接受一个前提:模型并不可靠。 然后再用工程方式,把这种不可靠尽量包住、约束住、削弱掉。
如果从产品和架构设计的角度看,这份源码真正有参考价值的,也正在这里。
一、Claude Code 不是把 AI 塞进 IDE,而是在给 AI 造一个运行环境
很多人会把这类产品理解成“会写代码的聊天机器人,再外接几个工具”。
但从源码结构看,Claude Code 更像一个围绕 LLM 构建的执行系统。
它真正要解决的,不是“模型能不能回答问题”,而是下面这些更具体、更工程化的问题:
-
在什么条件下允许执行操作 -
哪些动作默认不能做 -
上下文过长之后如何压缩 -
任务如何拆分,拆完后怎么避免失控 -
哪些记忆应该带进来,哪些宁可漏掉也不能污染当前上下文 -
Prompt 怎么组织,才能兼顾稳定性、成本和缓存命中 -
工具该怎么描述给模型,才能减少误用
所以 Claude Code 的重点,从来不只是“让模型显得聪明”,而是“让模型在真实开发环境里少犯错”。
二、贯穿源码的一条主线:默认不信任模型
如果只用一句话概括 Claude Code 的设计哲学,我会倾向于这样说:
它的系统设计,不是围绕模型理想中的能力展开,而是围绕模型现实中的缺陷展开。
这里的“不信任”不是情绪判断,而是工程判断。源码里能看到大量 A/B 测试痕迹、失败率统计、策略切换和保护性约束。很多限制不是为了显得保守,而是因为团队已经验证过:模型确实会在这些地方出错。
1)改文件前,必须先读文件
一个很典型的例子,是文件编辑前的强制读取检查。
// FileEditTool 核心检查if (!hasFileBeenRead(filePath)) {thrownewToolError("You must read the file before editing it. Use FileReadTool first." );}这条限制很朴素,但背后的判断非常关键:LLM 会对自己没看过的文件内容产生“想当然”的推测。
如果不加硬约束,模型完全可能基于虚构的上下文直接改文件,最后把真实代码覆盖掉。
所以 Claude Code 没把“先读后改”当成一条建议,而是直接写进工具层,变成不可绕过的规则。模型再自信也没用,没读过,就不能改。
这其实体现了一种很重要的 Agent 设计思路:不要把流程合规寄托在模型自觉上,而要让流程本身决定它能不能继续往下走。
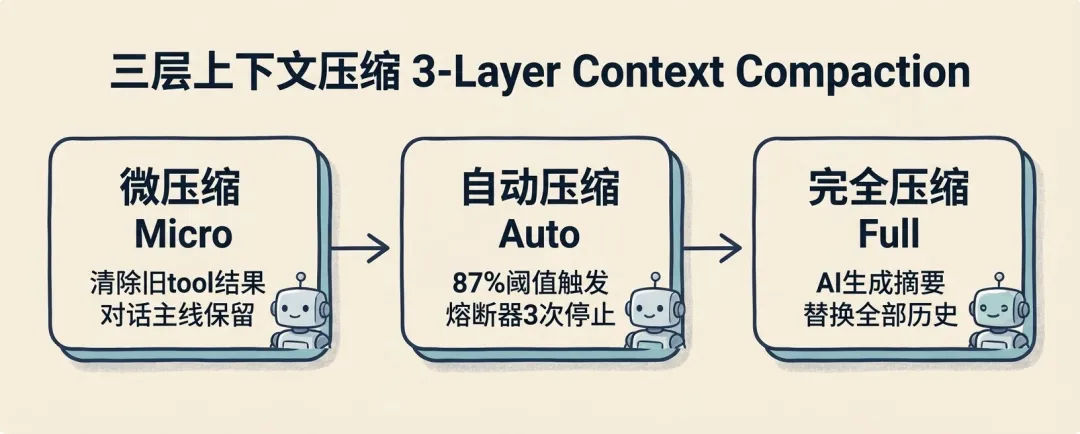
2)上下文管理不是简单“清历史”,而是分层压缩
长对话是所有 LLM 系统都会遇到的问题。上下文一旦变长,模型容易丢重点、混淆状态,或者为了节省 token 丢掉关键内容。
Claude Code 在这里用的不是一次性粗暴截断,而是三层压缩机制:
用户对话开始│▼[Level 1] 微压缩 (Micro Compaction)│ • 仅清理旧的 tool 调用结果│ • 完整保留对话主线│ • 成本最低 / 无语义损失│▼ (触发条件:token ≈ 窗口上限)[Level 2] 自动压缩 (Auto Compaction)│ • 触发阈值:窗口大小 - 13000 buffer│ • 压缩历史对话(保留关键信息)│ • 熔断机制:│ - 连续失败超过阈值 → 停止压缩│▼ (若仍超限)[Level 3] 完全压缩 (Full Compaction)│ • AI 生成整段对话摘要│ • 替换全部历史消息│ • 强约束指令:│ "只总结,不调用工具"│▼继续对话这里有两个细节很值得注意:
第一,它不会一上来就让模型总结整段历史,而是优先做“清理旧工具输出”这种低损耗操作,尽量把高风险压缩往后推。
第二,压缩流程带熔断。如果连续失败,就停止,而不是无限重试,把上下文越压越乱。
这说明 Claude Code 对“压缩”这件事本身也保持警惕。压缩不是万能补丁,它同样可能制造信息损失,所以系统必须给它预留失败路径和回退机制。
3)子 Agent 不是越多越好,边界必须先划清
Claude Code 支持子 Agent 协作,但从实现方式看,它并没有把这件事做成“可以无限递归展开”的自由系统。相反,它会显式给子 Agent 注入身份限制:
// 子 agent 的系统提示词注入"You are a sub-agent. You cannot createadditional sub-agents. Complete the taskyourself using only the tools available to you."意思很清楚:你是一个子执行单元,不负责继续分包任务。
配合 Coordinator 模式,它对并行策略也有明确区分:
Coordinator 并行策略:只读任务(研究/搜索)→ 并行执行写入任务(改文件) → 按文件分组串行原文注释:"Parallelism is your superpower"前提:读写分离这不只是为了提升并发效率,更是在按任务属性做风险控制。读操作通常适合并行,写操作则天然容易冲突,所以要按文件分组串行。
换句话说,Claude Code 对 Agent 架构的理解,不是“会拆任务就够了”,而是:
角色要清楚,权限要清楚,并发边界也要清楚。
三、安全不是附属能力,而是工程主体
源码里有一个非常直观的信号:仅 BashTool 的安全相关实现,就散落在十几个文件里;而给 AI 看的行为规范 prompt,也有数百行。
这意味着,Claude Code 并不是在赌模型会“自己懂分寸”,而是在工具层和提示层同时收紧边界。
比如工具工厂的默认配置:
// src/tools/tool-factory.tsinterfaceToolDefinition {isConcurrencySafe: boolean; // 默认 falseisReadOnly: boolean; // 默认 false}这两个默认值看起来平常,实际上很关键。
它体现的是一种典型的 fail-closed 思路:
-
开发者没声明并发安全,就按不安全处理 -
开发者没声明只读属性,就按可能写入处理
也就是说,系统面对未知工具时,默认先把风险算进去,而不是先假设它安全。
对 Agent 系统来说,这是一条很重要的底线:不确定时,先收紧,不要先放行。
对应到 BashTool,也就不难理解为什么 Claude Code 不会轻易执行高风险命令,比如擅自 git push --force。不是因为模型天然克制,而是因为行为边界早就被编码进 prompt 和工具规则里了。
四、Claude Code 的 Prompt,更像一种“构建产物”
很多人在谈 Prompt Engineering 时,仍然停留在“系统提示词该怎么写得更好”这个层面。
但从 Claude Code 的实现看,它已经把 Prompt 当成一种需要编排、拆分、缓存、稳定维护的运行时资产,而不是一段写死的提示文案。
源码里的组织方式大致如下:
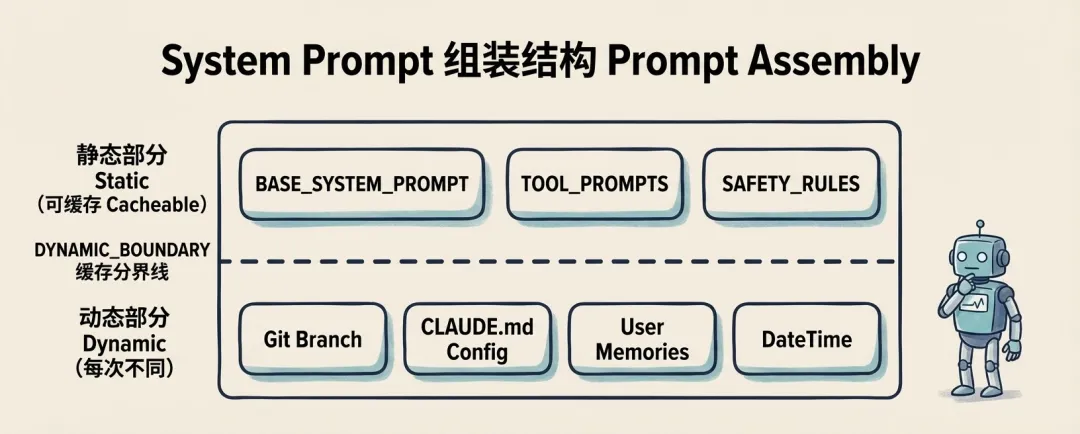
functionbuildSystemPrompt() {return [// ─── 静态部分(可缓存)───BASE_SYSTEM_PROMPT, // 基础人格和规则TOOL_PROMPTS, // 所有工具的使用手册SAFETY_RULES, // 安全规则// ─── 缓存分界线 ───SYSTEM_PROMPT_DYNAMIC_BOUNDARY,// ─── 动态部分(每次不同)─── gitBranch, // 当前 Git 分支 claudeMdConfig, // CLAUDE.md 项目配置 userMemories, // 用户偏好记忆 currentDateTime, // 当前时间 ];}这里最值得关注的,不是 Prompt 里放了哪些内容,而是它被明确拆成了静态区和动态区。
静态部分可缓存,动态部分按会话实时注入。这样做至少同时解决了三件事:
-
降低重复 token 成本 -
提升响应速度 -
保持系统提示的灵活性
也就是说,Claude Code 在处理 Prompt 时,已经不是“写提示词”的思路,而是更接近“编译期和运行时分离”的思路。
1)缓存稳定性,本身就是一套工程问题
Claude API 的 prompt cache 基于字节级前缀匹配。只要前缀发生变化,缓存就可能失效。
这意味着,Prompt 稳定性并不是一句“尽量别改”就能解决的问题,而是需要细致的工程约束。
源码里提到的做法包括:
缓存稳定性设计:1. 工具排序写死 - 不按字母序 - 不按使用频率2. 子 agent fork 结果统一占位符 - 使用相同占位符替换 → 10 个子 agent,只有第 1 个冷启动 → 后 9 个直接命中缓存3. 静态 prompt 不包含任何动态变量4. 动态参数用 latch 机制锁定,防止中途变化打破缓存这背后其实对应着一个很现实的判断:Prompt 不只是模型输入,它还是成本结构和性能结构的一部分。
如果一个 Agent 产品对 Prompt 的组织过于随意,也许功能还能跑起来,但它的延迟、成本和稳定性通常会持续恶化。
2)工具说明是写给模型看的,不是写给人看的
Claude Code 的每个工具目录下,通常都会有独立的 prompt.ts。这些内容本质上是工具说明书,但服务对象不是工程师,而是模型。
比如 BashTool 的规则大约就有 370 行。这种体量本身就说明,Claude Code 并不假设模型“天然理解”命令行环境,也不假设它会自动掌握风险边界,而是把大量行为规则明确写出来,作为工具契约的一部分。
而且工具并不是一股脑全部注入。Claude Code 会通过 ToolSearchTool 做按需发现;在 CLAUDE_CODE_SIMPLE=true 的配置下,甚至可以把工具裁剪到只剩 Bash、读文件、改文件三个。
这说明它连自己的“提示词膨胀”也在控制:工具越多,Prompt 越长,token 成本越高,对模型的干扰也可能越大。
源码里还有一个很能体现工程现实的细节:由于自家 SDK 的流式解析存在 O(n²) 性能问题,Claude Code 团队甚至绕过官方 SDK,自己维护流式状态累计。
这类选择说明,成熟的 Agent 系统最终比拼的,往往不是“有没有接上模型”,而是周边整套工程实现是否真的能支撑规模化使用。
五、记忆系统的重点,不是多记,而是少带错
很多人使用 Claude Code 时会有一种直觉:它似乎真的会持续记住你的偏好。比如你说过“测试里不要 mock 数据库”,后面它就会尽量避免这么做。
但从源码看,它背后的记忆机制并不是简单的关键词召回,也不只是向量检索,而更像一种“精确挑选,再完整注入”的策略:
记忆检索流程:1. 用户发送消息2. Claude Sonnet(小模型)扫描所有记忆文件的标题+描述3. 选出最相关的记忆4. 把完整内容注入当前对话上下文策略:precision > recall宁可漏掉,不要污染这套思路很有代表性。
许多检索系统会优先追求召回率,认为“多找一点总没坏处”。但 Claude Code 走的是相反的方向:宁可有些信息暂时没召回,也不要把不相关内容带进当前上下文。
因为对 LLM 来说,无关上下文的副作用往往比“少记一点”更严重。噪音一多,模型反而更容易判断失真。
源码里还提到一个名为 KAIROS 的特性标志。在这个模式下,长会话记忆会按日期写入追加式日志,然后再通过 /dream 之类的能力,在低活跃时段把这些日志蒸馏成结构化主题文件。
也就是说,它把“先记录”和“后整理”分成了两个阶段:先保留原始痕迹,再做后处理提炼。

六、从权限设计里,也能看出 Claude Code 的路线选择
如果把几类 AI 编程产品放在一起看,会发现它们差异并不只是“功能多不多”,更是对风险来源的判断不同。
Claude Code 在源码里体现出的路线是:允许模型进入真实环境工作,但对行为边界做细粒度控制。
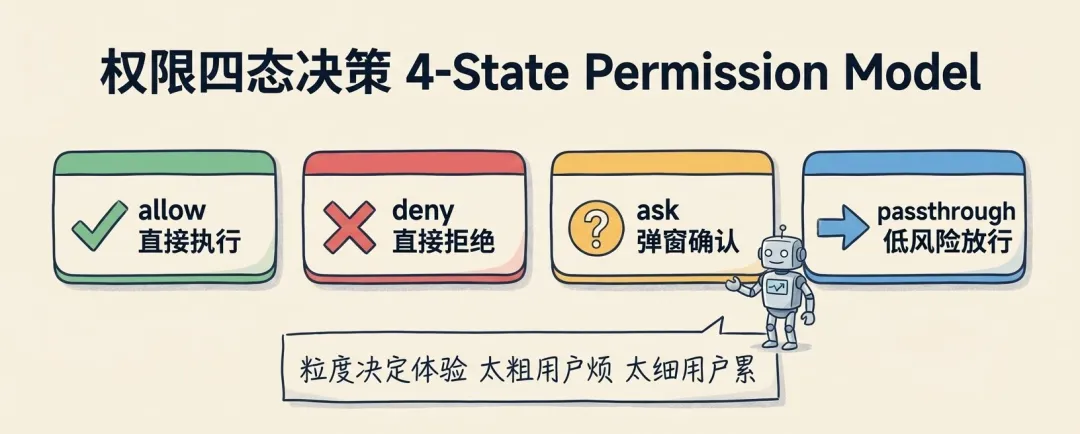
它的权限系统不是简单的 allow / deny 二选一,而是四态模型:
权限决策:四态模型
allow → 直接执行,不问
deny → 直接拒绝,不执行
ask → 弹窗问用户,等确认
passthrough → 低风险操作,默认放行
相比二态模型,这种设计更适合在体验和安全之间找平衡:
-
全部 ask,用户会被频繁打断 -
全部 allow,风险会迅速失控 -
全部 deny,Agent 几乎没法工作
所以 Claude Code 采用的是更丰富的中间层:让低风险操作顺滑执行,让高风险动作必须即时确认。
这背后其实是一种很清楚的产品判断:
关键不是把 AI 完全隔离在真实环境之外,而是给它建立足够细的操作边界。
七、还有一个值得注意的信号:内部版和公开版不是同一个成熟度阶段
Claude Code 的源码里存在 isAnthropicEmployee 分支:
if (isAnthropicEmployee()) {// 更激进的输出策略// "倒金字塔写作法"// "不写注释除非 WHY 不明显"// 实验功能enableFeature("VerificationAgent");enableFeature("ExploreAndPlanAgent");}这基本能说明,Anthropic 自己就是 Claude Code 的高强度用户。内部版承担了实验场角色,而对外版本更偏向稳定交付。
这件事很重要,因为它意味着 Claude Code 的架构并不是一次性设计出来的,而是在内部真实开发环境里被反复使用、修正、沉淀之后,才逐步外化成产品能力。
换句话说,它不是一套静态结构,而是一套会随着模型能力变化持续调整的系统。
有些限制在早期模型上很必要,模型升级后可能就变得多余;有些机制可能最初只是补丁,后来慢慢演化成正式能力;也有一些东西,未来其实应该被拆掉。
八、对做 Agent 的团队来说,最值得学的不是某个函数,而是背后的方法
源码泄露之后,社区里已经有人用 Claude Code 去分析 Claude Code,再把其中的关键逻辑抽出来,做新的 agent-sdk。
比如原先有些 SDK 的做法,是套壳 Claude Code CLI,每次 query 都要拉起一个本地进程,成本不低。现在基于泄露出来的结构信息,已经有人开始把这些依赖 CLI 的逻辑抽成更轻量的函数调用。
原则一:默认收紧,而不是默认放开
只要不确定一个动作是否安全,就先别放过去。
这在工具工厂的默认值设计里体现得很明显。很多系统习惯“先跑起来,出问题再补”,但一旦 Agent 直接接触文件系统、命令行、Git 或外部服务,这种策略的代价会迅速上升。
原则二:每个组件,都应该能对应一个明确的模型缺口
比如“先读后改”,是为了防止模型臆造文件内容;上下文分层压缩,是为了应对长上下文里的重点丢失;限制子 Agent 递归,是为了防止任务拆分失控。
如果一个 harness 组件说不清自己到底在补什么问题,它大概率就会变成额外复杂度,而不是有效补偿。
原则三:Harness 自己也有成本,不能无限膨胀
Claude Code 对工具按需加载、精确划分缓存边界、固定排序保持前缀稳定,本质上都在做一件事:控制 harness 自己的开销。
这一点特别容易被忽略。很多团队做 Agent 时容易陷入一种直觉:多加一层保险总归更稳。但现实往往是,系统自己先消耗掉大量上下文、延迟和维护成本,最后反过来拖累模型效果。
原则四:要为未来拆除组件预留空间
这是 Claude Code 源码里一个很值得重视的信号。很多限制其实是在给当前模型补位,但模型能力是会变化的。今天必要的组件,半年后可能就是冗余。
所以这类系统不能只考虑“怎么补”,也得考虑“未来怎么拆”。
当然,源码也暴露了工程现实的一面:比如注释里就承认,多遍 normalization 这类逻辑本身很脆弱,因为每一层清理都有可能制造新的边界条件。
也就是说,“为拆除而设计”更像是一种目标,而不是现实中总能做到的状态。
九、重新理解 Claude Code:它更像一个以 LLM 为核心的执行系统
把 Claude Code 放回整体结构去看,它其实不只是一个“AI 编程助手”。
-
42 个工具,对应的是与系统环境的交互能力 -
权限系统,对应的是行为边界控制 -
记忆系统,对应的是持久化偏好与历史提炼 -
子 Agent 与协调器,对应的是任务调度与执行策略 -
Prompt 编排与缓存,对应的是运行时成本管理
从这个角度说,Claude Code 更像一个以 LLM 为中心、围绕真实开发环境搭出来的操作层。
模型当然重要,但模型只是内核的一部分。真正让它变得可用的,是那些看上去“不那么像 AI”的部分。
最后
Claude Code 这次源码泄露,当然会让很多人去研究实现细节、复制功能路径,甚至很快做出替代版本。
但如果只盯着模型调用和工具接口,反而容易错过它最核心的价值。
Claude Code 之所以好用,并不是因为它把模型神化了,而是因为它在 51 万行代码里很清楚地承认了一件事:模型再强,也必须放进一个设计良好的运行环境里。
这个运行环境包括限制、约束、回退、缓存、压缩、权限、记忆和角色边界。真正让 Agent 能进入真实工作流的,恰恰是这些看起来不那么“性感”的工程部分。
模型会继续变化,今天很多实现细节以后都可能过时。但有些思路,大概率会留下来:
-
不确定时默认收紧 -
先约束流程,再让模型执行 -
记忆宁可少,不要脏 -
Prompt 不只是能力描述,也是成本结构 -
Harness 本身也要受控,并且要准备好被拆除
从这个意义上说,Claude Code 最值得学习的,不是“它怎么调用 AI”,而是“它如何接受 AI 并不可靠这件事,然后依然把产品做对”。