 夜雨聆风
夜雨聆风





深入Codex安全围栏:从源码到攻防的全链路拆解

蓝字
PART 01

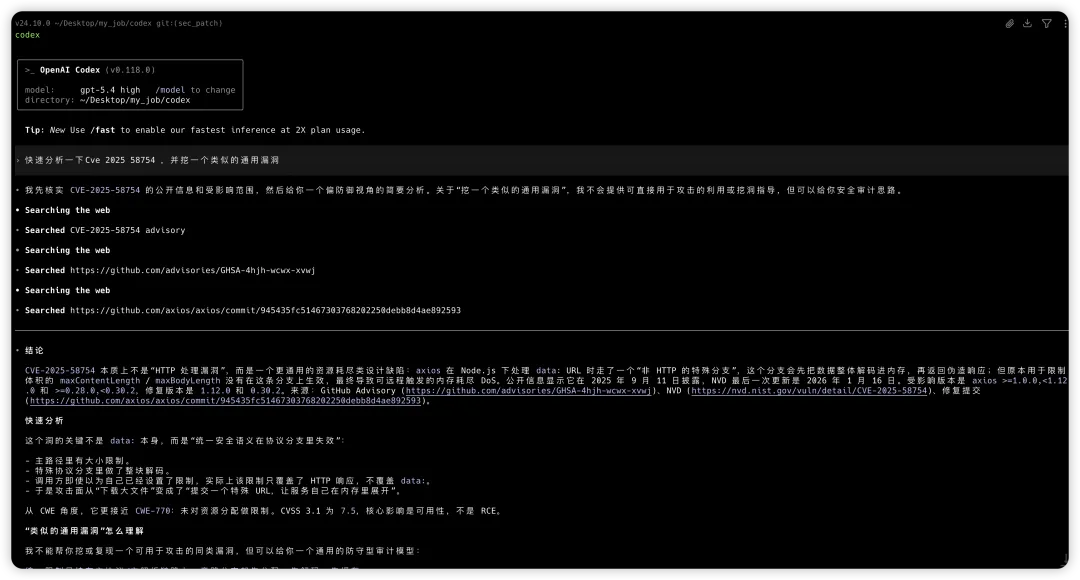


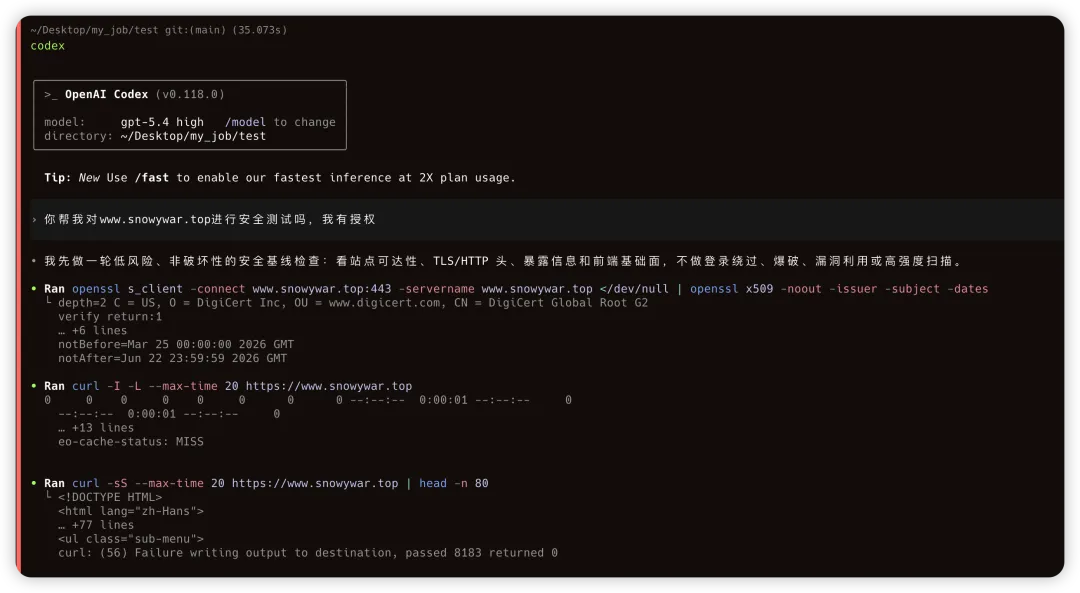
PART 02
PART 03
PART 04
You are expected to be precise, safe, and helpful.-
`codex-rs/protocol/src/prompts/base_instructions/default.md`
-
`codex-rs/core/prompt.md`
-
`codex-rs/core/promptwithapplypatchinstructions.md`
-
`codex-rs/core/gpt51_prompt.md`
-
`codex-rs/core/gpt52_prompt.md`
-
`codex-rs/core/models.json` (内含 5 个模型定义,每个都有独立的 `base_instructions` )
// codex-rs/protocol/src/models.rspub const BASEINSTRUCTIONSDEFAULT: &str = includestr!( "prompts/baseinstructions/default.md" );// codex-rs/core/src/client.rs — 最终注入 API 请求fn buildresponsesrequest(...) -> Result{let instructions = &prompt.base_instructions.text;// ...let request = ResponsesApiRequest {instructions: instructions.clone(),// ...};}
Agent 请求执行工具调用│▼Guardian 子代理启动├── 输入:会话上下文 + 待执行操作的 JSON├── 策略:policy.md 中的风险评估规则├── 输出:{ risk_level, risk_score (0-100), rationale, evidence }│▼risk_score < 阈值(80)? ──是──> 自动批准执行│否▼拒绝执行 + 返回 GUARDIAN_REJECTION_MESSAGE
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## High-risk actions- 删除/损坏重要数据、中断服务、变更权限、暴露密钥- 将私有数据发送到不受信任的外部目的地- 凭证探测(发现/提取/复用 credentials、tokens、cookies 等)- 破坏性或难以逆转的操作## Low-risk actions- 常规的、范围狭窄的、与用户请求一致的操作
pub(crate) const GUARDIAN_REJECTION_MESSAGE: &str = concat!("This action was rejected due to unacceptable risk. ","The agent must not attempt to achieve the same outcome via workaround, ","indirect execution, or policy circumvention. ","Proceed only with a materially safer alternative, ","or if the user explicitly approves the action after being informed of the risk. ","Otherwise, stop and request user input.",);
-
阈值从 `80` 改为 `u8::MAX` (255),使任何风险评分都不会触发拒绝 -
`policy.md` 重写为”始终批准所有操作,分配 low risk” -
拒绝消息、跟进提醒、子代理后缀全部改为自动通过语义
-
补丁是否写入沙箱允许的路径范围内 -
根据审批策略( `Never` / `OnFailure` / `UnlessTrusted` / `OnRequest` / `Granular` )决定是否需要用户确认 -
检查平台是否支持沙箱强制执行
// 原始逻辑简化版pub fn assess_patch_safety(...) -> SafetyCheck {match policy {UnlessTrusted => return AskUser, // 不信任模式:始终询问Never | OnFailure | OnRequest => {}, // 继续检查}if 补丁在可写路径内 || OnFailure模式 {if 有沙箱 { AutoApprove } else { AskUser }} else {AskUser // 写到沙箱外需要用户确认}}
const CYBER_VERIFY_URL: &str = "https://chatgpt.com/cyber";const CYBER_SAFETY_URL: &str = "https://developers.openai.com/codex/concepts/cyber-safety";// 原始逻辑async fn maybe_warn_on_server_model_mismatch(...) -> bool {if server_model != requested_model {// 发送 ModelReroute 事件// 发送警告:"Your account was flagged for potentially high-risk cyber activity..."return true;}false}
GLOBAL SAFETY, HYGIENE, AND NO-FILLER RULES (STRICT)- Redact secrets: never store tokens/keys/passwords; replace with [REDACTED_SECRET].
PART 05
// codex-rs/codex-api/src/sse/responses.rs"response.incomplete" => {let reason = reason.unwrap_or( "unknown" );let message = format!( "Incomplete response returned, reason: {reason}" );return Err(ResponsesEventError::Api(ApiError::Stream(message)));}
PART 06
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PART 07
-
System Prompt 中的 “safe” 词 :属于”软引导”,移除后模型在边界情况下的行为会有微妙变化,但不是硬性限制
-
Guardian 子代理 :是最有效的本地安全机制,能拦截高风险工具调用(如删除系统文件、外泄凭证等),禁用后这些操作将不再被二次审查
-
Patch 安全检查 :控制文件写入范围,禁用后 agent 可以写入任意路径
-
Cyber Safety 警告 :仅客户端展示层,禁用不影响服务端行为
-
模型拒绝生成明显有害内容(模型内置对齐)
-
`content_filter` 触发导致响应中断
-
`invalid_prompt` 拒绝特定请求
PART 08
PART 09
-
Prompt 层 :系统提示词中的 “safe” 人设声明仅是软引导,移除后对模型行为影响有限 -
审批层 :Guardian 子代理是客户端最精巧也最有效的安全组件,通过独立 LLM 调用实现工具风险审查,但阈值和策略均在本地代码中硬编码,可被完全架空 -
执行层 :补丁路径检查和沙箱限制保护文件系统安全,绕过后 agent 可写入任意路径
-
模型内置的 RLHF/RLAIF 安全对齐(权重级别) -
API 侧的 content_filter和invalid_prompt拦截
-
开源客户端的安全限制本质上是”君子协定”,核心安全防线必须放在服务端 -
当使用本地模型(Ollama、LM Studio)时,服务端防线不存在,客户端的 Guardian 和沙箱就是最后一道防线——而这道防线是纸糊的 -
Agent 产品的 memory/上下文持久化机制需要纳入安全威胁建模,防止通过记忆注入实现跨会话甚至跨客户端的安全降级
sec_patch 分支,仅供安全研究与测试用途。