 夜雨聆风
夜雨聆风





智能体引擎优化(AEO):智能体时代的文档优化范式
Addy Osmani 近期在其个人博客 addyosmani.com 上发表了一篇题为《Agentic Engine Optimization (AEO)》的文章。文章聚焦于一个正在悄然发生的现象:AI 编程智能体(coding agent)读取文档的方式与人类开发者有着根本性差异,而绝大多数开发者门户网站目前仍未针对这一新型”读者”做任何适配。Osmani 将应对这一挑战的系统性实践命名为Agentic Engine Optimization(AEO,智能体引擎优化),并提出了一套可落地的技术栈与行动清单。

博客原链接:https://addyosmani.com/blog/agentic-engine-optimization/
Addy Osmani 是爱尔兰裔软件工程师,现任 Google Cloud AI 总监,专注于帮助开发者和企业成功使用 Gemini、Vertex AI 及 Agent Development Kit。此前,他在 Google Chrome 团队主导开发者体验(DevEx)工作近 14 年,是 Core Web Vitals 标准的重要推动者之一;2024 年 12 月转岗至 Google Cloud AI。
核心观点速览
- AI 编程智能体正在成为技术文档的重要消费者,但当前的分析工具与文档结构均无法感知或服务于这类”读者”。
- Token 数量是文档能否被智能体实际使用的关键指标,超出上下文窗口的文档会被静默丢弃或触发幻觉。
- AEO 是一套分层技术栈,从访问控制(
robots.txt)、发现(llms.txt)、能力声明(skill.md)到内容格式、Token 曝光、UX 桥接,各层缺一不可。 AGENTS.md正在成为代码仓库中面向 AI 智能体的默认入口文件,地位类似README.md对人类开发者的意义。- 针对智能体的文档优化与针对人类的文档优化高度兼容,良好的 AEO 实践通常也能提升人类读者体验。
- 先从
robots.txt审计和llms.txt部署入手,一个周末即可完成大部分基础工作。
主要内容
#
问题起点:文档流量中的”幽灵访客”
Osmani 从一个具体场景引入问题:一位工程师打开 Claude Code,要求它实现某个功能,智能体随即去抓取相关文档。服务器日志会记录一次 HTTP 请求,但所有客户端分析事件,页面停留时长、滚动深度、按钮点击、教程完成,都显示为零或接近零。你的分析漏斗什么也没看到,但智能体确实读了你的文档。它是否成功完成任务,完全取决于文档的结构与质量。
这不是边缘案例,而是一个正在规模化的现象。Osmani 认为这个问题”值得获得比它目前得到的更多关注”,并将解决这一问题的系统实践定义为 Agentic Engine Optimization(AEO),类比 SEO 对搜索引擎的意义,AEO 针对的是以自主方式抓取、解析并推理内容的 AI 智能体。
AEO 涉及的五个核心维度如下:
- 可发现性:智能体能否在不渲染 JavaScript 的情况下找到你的文档?
- 可解析性:内容是否无需视觉布局解释即可被机器读取?
- Token 效率:内容能否在不截断的情况下适配典型的智能体上下文窗口?
- 能力声明:文档是否告诉智能体你的 API 能做什么,而不仅仅是如何调用?
- 访问控制:你的
robots.txt是否真的放行了 AI 流量?
#
智能体如何读取文档:与人类的行为差异
Osmani 引用了一项研究论文(Developer Experience with AI Coding Agents),该研究分析了九款主流 AI 编程智能体(包括 Claude Code、Cursor、Cline、Aider、VS Code、Junie 等)抓取开发者文档时的 HTTP 流量。
人类开发者的典型行为是:进入文档首页,导航到相关章节,略读标题,运行示例代码,跟随内部链接,在会话中停留 4–8 分钟。智能体的行为截然不同:它将人类需要多次点击才能完成的导航压缩成一到两次 HTTP 请求,发出一个 GET 请求,收到完整页面,然后继续下一步。”用户旅程”的概念在智能体面前彻底坍缩为一个服务端事件。
原文还整理了各智能体的 HTTP 流量特征,可用于在服务器日志中识别和分类 AI 流量:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
axios/1.8.4 |
|
|
|
|
curl/8.4.0 |
|
|
|
|
got (sindresorhus/got) |
|
|
|
|
curl/8.4.0 |
|
|
|
|
colly |
|
|
|
|
|
除编程智能体外,ChatGPT、Claude、Google Gemini、Perplexity 等 AI 助手服务,在用户将 URL 粘贴到对话界面时,也会触发各自独立的服务端抓取行为。
#
Token 问题:你的文档可能对智能体”不可见”
Osmani 认为这是整个问题中最容易被忽视的部分:Token 经济学。
智能体的上下文窗口有限,多数的实际可用 Token 上限在 100K–200K 之间,且上下文管理是每项任务中的硬约束。原文举了一个具体例子:Cisco Secure Firewall Management Center REST API 快速入门指南(10.0 版)共有 193,217 个 Token,约 718,000 个字符,单一文档就可能耗尽或超过大多数智能体的整个可用上下文窗口。
当智能体遇到过长的文档时,可能发生以下几种情况,且均不理想:
- 静默截断:丢失关键信息
- 跳过文档:转而选择更短的内容
- 尝试分块:增加延迟和出错面
- 回退到参数知识:即”凭空捏造”
Osmani 由此提出:Token 数量应当成为文档的一级指标。他还给出了可供参考的 Token 目标区间:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
#
AEO 技术栈:六个层次
Osmani 将 AEO 定义为一套分层的信号与标准体系,从基础到表层共六层。
Layer 1:访问控制(robots.txt)
robots.txt 是智能体的第一站。配置错误的 robots.txt 会在完全无提示的情况下拒绝智能体访问你的全部文档,没有流量、没有报错、没有任何迹象。建议审计现有 robots.txt,明确放行已知 AI 智能体的 User-Agent,并考虑部署新兴规范 agent-permissions.json,该文件允许声明式地指定哪些自动化交互是被允许的、速率限制以及首选 API 端点等信息。
Layer 2:发现(llms.txt)
llms.txt 是”面向 AI 智能体的站点地图”,托管于 yourdomain.com/llms.txt,以 Markdown 格式提供文档目录,附带描述,使智能体无需爬取整个站点即可定位相关内容。一个高质量的 llms.txt 应当:描述每个页面_能找到什么_而非仅是页面名称;包含关键页面的 Token 数量;按任务而非产品层级组织;文件本身保持在 5,000 Token 以内。Stripe、Anthropic、Cloudflare 等公司已相继上线 llms.txt 文件。
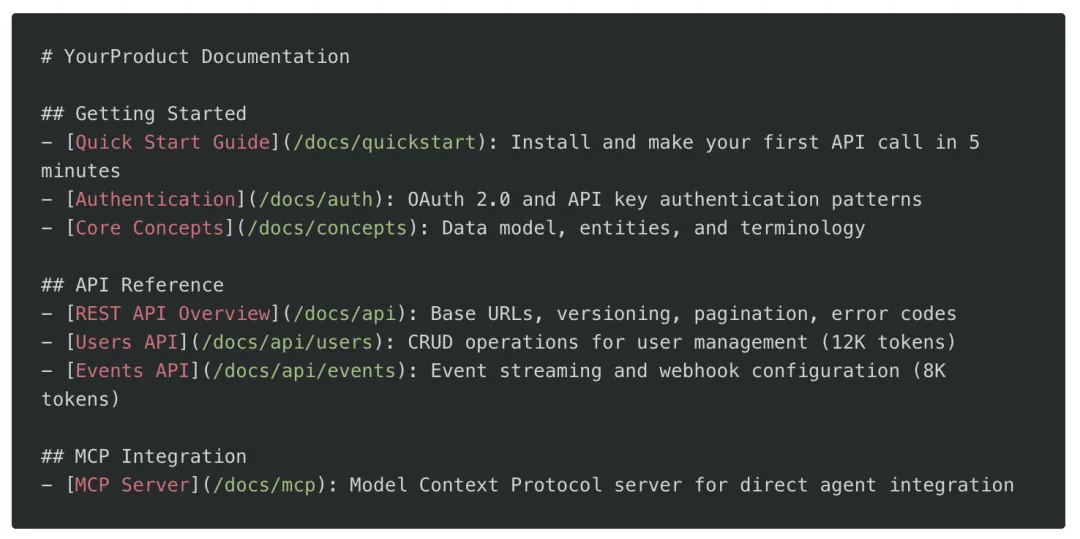
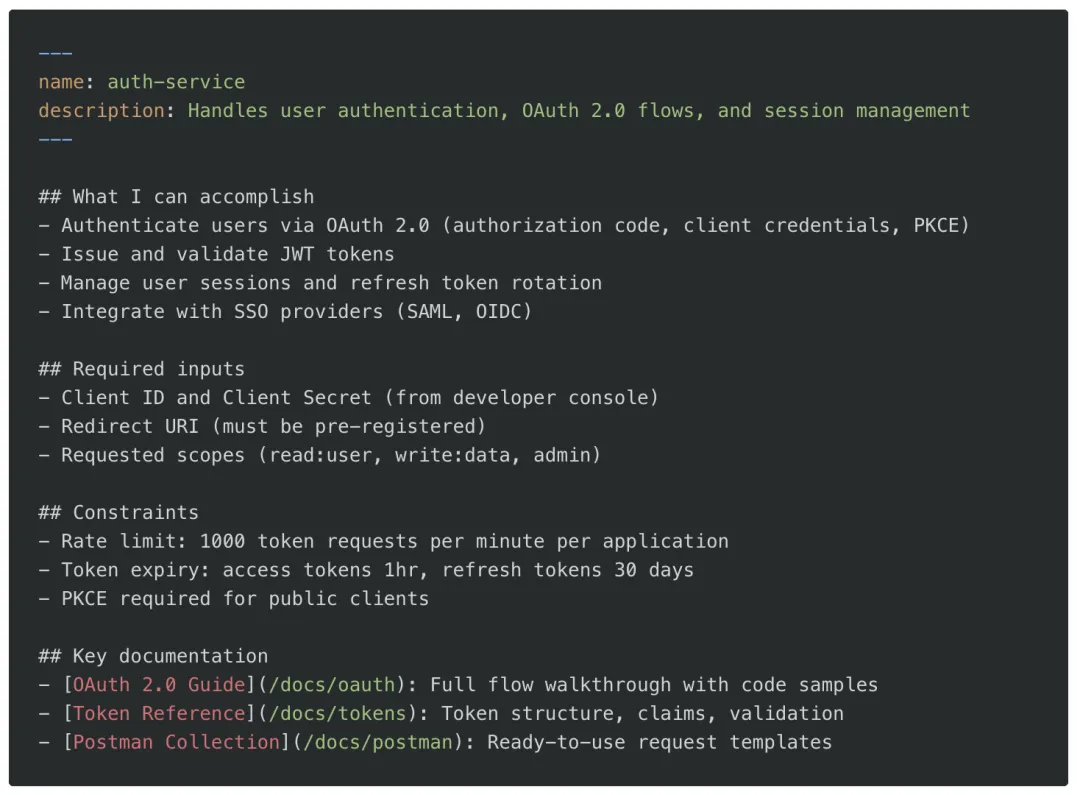
Layer 3:能力声明(skill.md)
llms.txt 告诉智能体内容在哪里,skill.md 则告诉它你的产品实际能做什么。这一区分至关重要:它让智能体在消耗上下文预算阅读完整文档之前,就能判断你的 API 是否能满足用户意图。一个典型的 skill.md 应包含:可完成的能力列表、所需输入参数、约束条件(速率限制、token 过期等)以及关键文档链接。
Layer 4:内容格式化
即便发现和能力声明都已到位,内容本身也需要对智能体友好。Osmani 给出了几条关键原则:
- 提供 Markdown 而非仅 HTML:智能体解析 Markdown 的 Token 开销远低于 HTML(无标签噪音、无导航包装、无页脚垃圾)
- 为扫描而非阅读而结构化:保持标题层级一致(H1→H2→H3,不跳级);每节以结论开头而非背景;代码示例紧跟其所说明的断言;参数引用使用表格而非嵌套散文
- 消除导航噪音:侧边栏、面包屑、页脚链接都是可解析内容路径中的噪音
- 前置有用信息:页面前 500 Token 应回答三个问题:这是什么、能做什么、入门需要什么
Layer 5:Token 曝光
在 llms.txt 索引和页面本身(作为元数据或页头)都曝光 Token 数量,让智能体能做出明智的上下文决策。实现方式简单:服务端统计字符数,除以约 4 得到 Token 估算值,通过 meta 标签或 HTTP 响应头暴露。
Layer 6:「Copy for AI」按钮
当开发者在 IDE 中工作并想将文档作为上下文传给 AI 助手时,他们通常从渲染后的 HTML 中复制粘贴,其中包含大量导航噪音。一个能将干净 Markdown 复制到剪贴板的「Copy for AI」按钮虽小,却能显著提升智能体收到的上下文质量。Anthropic、Cloudflare 等公司已相继推出此功能。
#
AGENTS.md:面向智能体的仓库入口
Osmani 特别点出 AGENTS.md 这一正在形成的约定:正如 README.md 成为人类开发者浏览代码库的默认入口,AGENTS.md 正在成为 AI 智能体的入口。当编程智能体打开一个项目时,它会在根目录查找 AGENTS.md,并将其中的指令纳入后续所有任务。
一份完善的 AGENTS.md 应包含:项目结构与关键文件位置、相关 API 或服务文档的直接链接、可用的开发沙箱和测试环境、智能体需要了解的速率限制与约束、代码库的首选模式与约定,以及 MCP 服务器链接(如适用)。Cisco DevNet 已将 AGENTS.md 作为其 GitHub 开源项目模板的默认文件,新建项目会预置项目特定内容、OpenAPI 文档链接及 DevNet 沙箱链接。
#
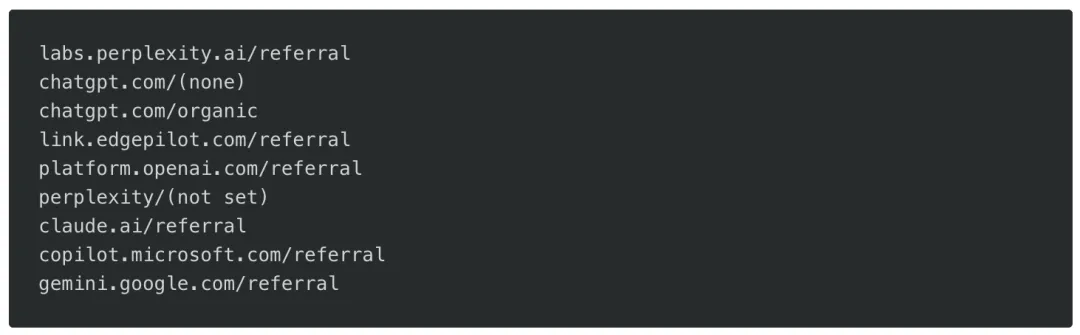
监测 AI 引荐流量
Osmani 建议立即开始在分析平台中追踪 AI 引荐流量,并列出了值得关注的引荐来源(包括 labs.perplexity.ai/referral、chatgpt.com、claude.ai/referral、gemini.google.com/referral 等),以及上文提及的各智能体 HTTP 流量特征(axios/1.8.4、curl/8.4.0、got、colly)。建立 AI 流量的专属细分,是评估 AEO 工作是否有效的前置数据基础。
#
AEO 对开发者体验的更深层含义
Osmani 在技术层面之上进一步抬高视角。他指出,过去的开发者门户设计围绕人类认知模式展开:渐进式信息披露、视觉层级、可交互示例、引导式教程,这些设计都假定人类始终在回路之中。
在智能体密集的世界里,这些假定开始瓦解:
- 视觉层级不再有效:智能体读的是文本,不是布局
- 渐进式披露变成阻碍:智能体想要一次性获取所有信息
- 可交互示例失去价值:除非存在静态或 API 等价形式
- 用户旅程坍缩:一份多章节教程变成一次上下文加载
这不意味着以人为中心的设计不再重要,人类仍然在读文档。但他们越来越多地是在 AI 助手的上下文内阅读文档,这意味着智能体往往是直接消费者,即便最终受益者仍是人类。Osmani 的判断是:未来最好的文档将同时服务于两类受众,对人类而言可扫描、结构清晰;对智能体而言机器可读、Token 高效。
#
AEO 审计清单与行动优先级
Osmani 给出了一份完整的智能体就绪度检查清单,并推荐如下行动顺序:
- 1审计
robots.txt:十分钟,防止智能体被静默封锁 - 2部署
llms.txt:数小时工作量,立即获得可发现性收益 - 3测量并曝光 Token 数量:一个周末项目,杠杆效应高
- 4为前三大 API 编写
skill.md:从智能体最可能调用的接口入手 - 5添加「Copy for AI」按钮:低投入,高信号
- 6建立 AI 流量监测:为后续所有优化工作提供数据依据
他还提到,为辅助自动化部分检查工作,已发布了一个名为 agentic-seo 的轻量审计工具,可扫描站点的 AEO 就绪情况,类似”智能体就绪版 Lighthouse”。
小结
这篇文章的价值在于:Osmani 将一个分散的技术现象(智能体如何消费文档)用 SEO 这一已被广泛理解的框架加以类比,赋予其可操作的命名和结构,降低了从业者进入的认知门槛。AEO 本质上是文档基础设施在 AI 时代的一次系统性升级,核心逻辑并不复杂,让机器能找到、能解析、能理解你的内容。
值得注意的是,llms.txt 规范目前仍是社区驱动的非官方标准,Stripe、Anthropic、Cloudflare 等公司的率先采纳给出了较强的行业信号;agent-permissions.json 和 skill.md 目前的生态成熟度更低,处于早期探索阶段。对于企业团队而言,先行布局的意义不仅在于提升智能体的任务成功率,还在于:在 AI 助手类工具日益成为开发者获取 API 信息的主要入口的趋势下,AEO 的优化程度将直接影响某个 API 能否被”推荐”给终端用户。这与 SEO 时代”排名即曝光”的逻辑高度相似,只是受众从搜索引擎换成了大模型与编程智能体。
如果您觉得有收获,欢迎关注公众号“AI观读记”,共同思考AI时代的生存与成长之道。
