 夜雨聆风
夜雨聆风





本地部署 AI 文档助手,PDF 和 Word 直接变成可对话的知识库
本地部署 AI 文档助手,PDF 和 Word 直接变成可对话的知识库
聊天机器人能回答通用问题,但它回答不了”我们合同第三条到底怎么规定的”。Kotaemon 做的事很简单:让你直接跟自己的文档对话,答案从文件里来,不是从训练数据里编的。
GitHub 地址
https://github.com/Cinnamon/kotaemon
官网
https://cinnamon.github.io/kotaemon/
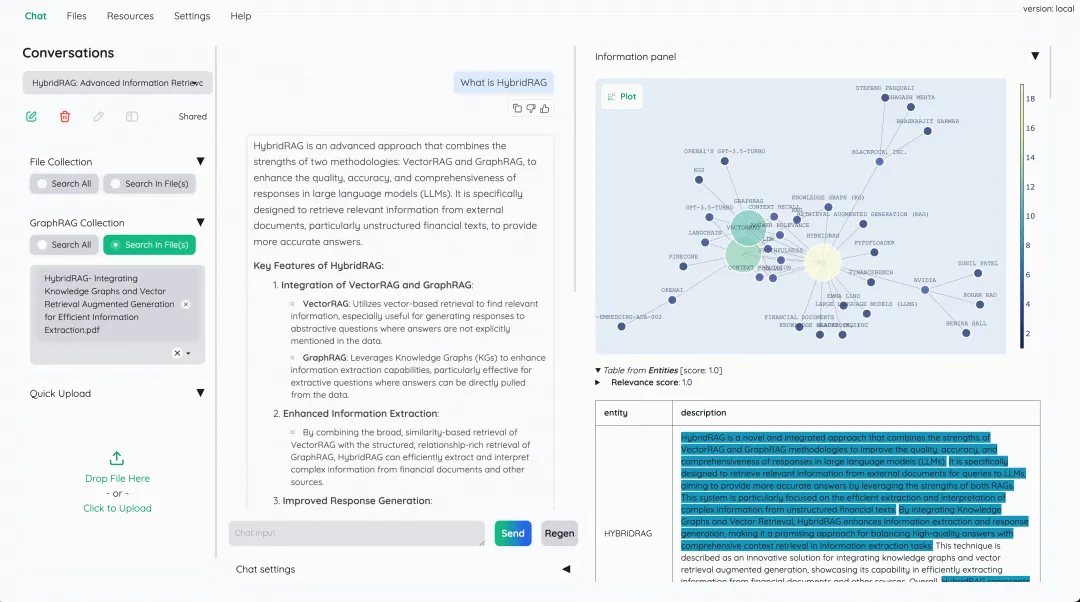
为什么需要这个项目?
截至 2026-04-14,Cinnamon/kotaemon 在 GitHub 上约有 25,273 个 Stars、2,114 个 Fork。它同时出现在 GitHub Daily 和阮一峰科技爱好者周刊的推荐列表中。
- 痛点 1:文档越来越多,找到关键信息越来越难。 无论是技术文档、合同、报告还是论文,篇幅一长,人工翻找的效率就直线下降。
- 痛点 2:通用 AI 聊天工具不懂你的文件。 你可以把内容贴进去,但它没有上下文索引,回答经常不够精准,也没法告诉你”这个答案来自哪一页”。
- 痛点 3:隐私不能接受上传到云端。 很多文档涉及商业机密、客户信息或内部策略,直接扔给第三方 AI 服务并不现实。
- 痛点 4:现有 RAG 方案搭建成本太高。 从零搭一套文档问答系统,要处理分段、向量化、检索、重排、对话,门槛不低。
Kotaemon 把这些环节全部打包好了,Docker 一键启动就能用。
核心内容
1. 上传文档,直接提问
把 PDF、Word、TXT 或图片丢进去,用自然语言问任何关于文档内容的问题。系统会从文件中检索相关段落,生成带引用的回答。
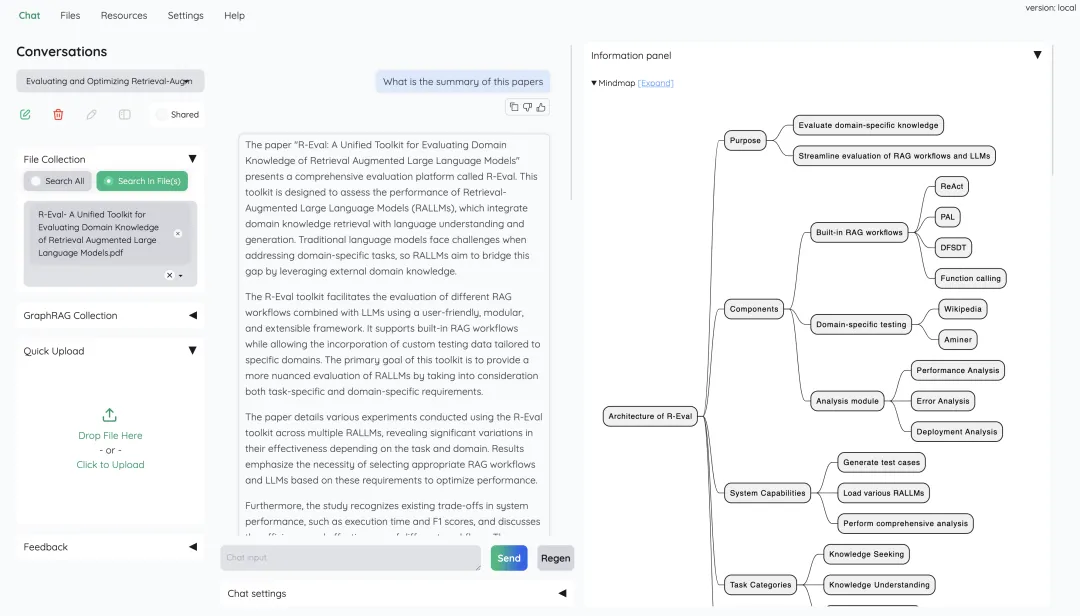
2. 混合检索,准确率更高
很多 RAG 工具只做向量检索,遇到精确关键词匹配时反而会漏掉。Kotaemon 同时使用全文检索和向量检索,再经过重排序,确保关键信息不被遗漏。
3. 支持本地模型,数据完全不出你的机器
不想用 OpenAI API?Kotaemon 支持 Ollama 等本地推理框架,所有文件解析和对话推理都在本地完成。对于有数据合规要求的场景,这一点很关键。
4. 多模态文档也能处理
不只是纯文本 PDF。带图表、表格的文档也能被解析和理解。对于技术报告、财务报表这类内容,直接问”第三季度的营收是多少”就能拿到答案。
5. 多人协作,支持文件共享
Kotaemon 提供多用户登录和文件集合管理。你可以把一份文档设为公开,让团队成员都能查询,也可以设为私有,只自己用。
6. 可扩展架构,支持 GraphRAG
如果你对检索精度有更高要求,Kotaemon 支持 GraphRAG、NanoGraphRAG、LightRAG 等高级索引策略。不需要从零搭建,直接在配置里切换就行。
技术亮点
- 开箱即用。 Docker 一行命令就能跑起来,不需要手动配置分段策略、向量数据库或检索管道。
- 混合检索已经是默认行为。 不用额外调参,全文加向量加重排的组合在大多数场景下效果已经够好。
- 引用溯源。 每个回答都会标注出处段落和页码,你可以直接跳到原文核实,避免 AI”看似自信但其实在编”。
- Apache 2.0 协议。 商业使用、修改、分发都没有问题。
适合人群
需要频繁查阅长文档的人
技术文档、合同、报告、论文——任何”太长不想读但又要找关键信息”的场景都适用。
需要私有化部署文档问答的团队
企业知识库、合规审查、客户支持——数据不能出域,但又需要 AI 来提升检索效率。
正在做 RAG 应用的开发者
如果你在搭建自己的文档问答系统,Kotaemon 的混合检索和可扩展架构值得参考,也可以直接基于它做二次开发。
如何开始
最快的方式:Docker
“`bash
docker run -e GRADIO_SERVER_NAME=0.0.0.0 \
-e GRADIO_SERVER_PORT=7860 \
-v ./ktem_app_data:/app/ktem_app_data \
-p 7860:7860 -it –rm \
ghcr.io/cinnamon/kotaemon:main-lite
“`
启动后打开 http://localhost:7860,上传文档,开始提问。
如果要用本地模型:
拉取 ollama 镜像替代 lite 镜像,然后配置本地模型路径即可。官方文档有详细步骤。
如果只是想先体验:
项目提供了 HuggingFace Space 上的在线 Demo,不需要本地部署就能试用。
许可与注意事项
- 协议:Apache License 2.0,可自由用于商业项目。
- 模型依赖: 首次使用需要配置 LLM 和 Embedding 模型。支持 OpenAI API 和本地模型,按需选择。
- 硬件要求: 如果全部使用本地模型,需要一定的 GPU 资源;如果用云端 API,普通电脑就能跑。
写在最后
文档问答不是一个新概念,但大多数方案要么要自己搭,要么要付费,要么数据得上传到别人服务器。Kotaemon 把这三个痛点同时解决了:开源、可本地部署、开箱即用。
如果你最近正被”文档太多找不到东西”困扰,或者团队需要一个私有的文档知识库,这个项目值得花半小时试一下。
如果对你有帮助,别忘了给它一个 Star。