 夜雨聆风
夜雨聆风





你的AI助手为什么每次都像失忆
事情是这样的。
前几天,我在宿舍里赶一个课程项目的前端页面,用Copilot来帮我写React组件。写了一半,Copilot帮我搭了一个挺漂亮的数据卡片组件,配色、布局、响应式都处理得很好。我当时还挺满意的,跟舍友说了一句,你看这玩意,比我手写强多了。
舍友瞥了一眼屏幕,说了句,行啊,那你让它明天帮你写另一个页面的组件,看看它还记得你的配色风格不。
我当时没当回事。
今天下午,我新开了一个Copilot的会话,让它写另一个页面的组件。我把需求描述丢进去,然后等了十几秒,结果出来了。
配色完全不一样。布局风格也变了。甚至连之前我特意让它用的那个圆角参数,它都给我改成了直角。
就好像昨天那个会话,从来没有发生过一样。
我盯着屏幕看了大概有五秒钟,脑子里就一个念头。
又来了。
这种感觉,其实我早就习惯了。用Copilot写代码,用Cursor做项目,每次新开一个会话,AI就像一个刚入职的新员工,什么都不知道,什么都得从头交代一遍。你昨天跟它说的那些偏好、那些踩过的坑、那些「不要这样写要那样写」的经验,它一个字都不记得。
我舍友更夸张。他前阵子用AI帮他写了一份商业计划书,改了好几版,终于改到一个他自己觉得挺满意的状态。然后他关了电脑,第二天重新打开,新会话,让AI继续优化。
AI问他,请问您的项目是做什么的?
我舍友当时那个表情,我至今都记得。
他不是生气,他是那种,真的无语了的感觉。就好像你跟一个人聊了三个小时,把你的创业想法从头到尾讲了一遍,对方频频点头,还给了你很多不错的建议。然后第二天你去找他,他看着你,一脸真诚地问,你好,请问我们认识吗?
这不是bug。
这是AI的架构特性。
上期我们聊了系统论,聊了AI不是一个工具而是一个系统,有组分有结构有功能有环境。如果你还没看,强烈建议回去补一下,因为今天要聊的东西,是上期的延续。
上期结尾我说过,下一期我们要深入到系统的内部运作,看看它到底是怎么运转的。今天,我们就来拆这件事。
AI的「失忆」,其实是理解整个AI系统运作机制的一个绝佳入口。因为当你搞明白它为什么会失忆,你也就搞明白了,怎么让它不再失忆,甚至,怎么让它越用越强。
先说一个概念,叫上下文窗口。
这个词听起来很技术,但其实特别好理解。你可以把它想象成AI的「工作台」,或者更直白一点,AI的「短期记忆」。
每次你跟AI对话,你说的每一句话,AI回复的每一个字,系统提示词里的每一条规则,工具定义里的每一个参数,全部都塞在这个上下文窗口里。AI能「看到」和「处理」的所有信息,就是这个窗口里的东西。
关键来了。
这个窗口是有容量的。
Claude最新的Sonnet 4.6和Opus 4.6已经支持100万token的上下文窗口了,GPT-4.1也是100万,Gemini 2.5 Pro同样是100万,后续还要扩展到200万。听着很多对吧,但你要知道,一段中等长度的代码加上对话历史,几万token就没了。如果你让它读一个大型项目的代码库,一个上下文窗口可能根本塞不下。
更关键的是,这个窗口是瞬时的。
什么叫瞬时?就是会话结束,窗口清空,一切归零。你昨天跟AI聊的那三个小时,那些精心调整的参数、反复讨论的方案、踩过的每一个坑,在会话结束的那一刻,就全部蒸发了。不存在了。好像从来没有发生过。
这就是AI「失忆」的根源。
它不是故意不记得你。它是从架构上就没办法记住你。上下文窗口的设计,决定了AI只能活在「当下」,只能看到当前会话里的信息。一旦会话关闭,它的世界就重置了。
说到这里,我突然想起了以前自学《系统之美》的时候,德内拉·梅多斯在书里反复提到的一个概念。
存量与流量。
梅多斯是Jay Forrester的学生。Forrester是谁?MIT的教授,系统动力学的创始人,1960年代就在MIT搞出了这套东西。他当时用存量-流量模型来分析城市人口、供应链、全球经济,几乎所有复杂系统都能用这个框架来拆解。
存量-流量模型的核心思想特别简单,简单到你可能会觉得「就这?」
存量是系统的状态,流量改变存量。
就这么一句话。但这个框架的威力在于,它几乎可以解释一切。
一个水库,水位是存量,流入的雨水和流出的灌溉用水是流量。

一个银行账户,余额是存量,存入和取出是流量。一个人的体重,当前的公斤数是存量,每天吃进去的卡路里和消耗的卡路里是流量。
你发现没有,存量是相对稳定的,而流量是持续变化的。存量是系统「记住」的东西,流量是系统「正在经历」的东西。
回到AI这个系统。
上下文窗口里的所有信息,对话历史、用户输入、系统提示词、工具返回结果、RAG检索出来的文档,全部都是流量。
它们在会话进行的时候持续流动,持续被AI接收和处理。但它们是瞬时的,会话一结束就消失了。就像流过水库的水,如果没有被蓄起来,就白白流走了。
那存量是什么?
存量就是那些被持久化、可以跨会话复用的东西。
比如你写在一个文件里的规则,告诉AI「我的项目用TypeScript,不要用JavaScript,组件风格遵循Atomic Design,配色用我定义的那套Design Token」。这个文件,不管你开多少个新会话,AI都能读到。它就是存量。
比如你把上次踩坑的经验写进了一个文档里,「这个API在并发超过100的时候会超时,要用队列处理」。下次新会话,AI读到了这个文档,就不会再犯同样的错。这也是存量。
比如你把常用的代码模板、项目结构、部署脚本都整理好了放在仓库里。AI每次新会话都能访问到这些文件。这还是存量。
流量决定了AI「当下能做多好」。你这次会话的上下文质量越高,AI这次的输出就越好。但一旦会话结束,这些高质量的上下文就没了,下次又得从头来。
存量决定了AI「长期能走多远」。你积累的规则文件、经验文档、知识库越丰富,AI每次新会话的起点就越高,不需要每次都从零开始。
所以问题就变成了一个特别朴素的公式。
存量等于流量乘以沉淀效率。
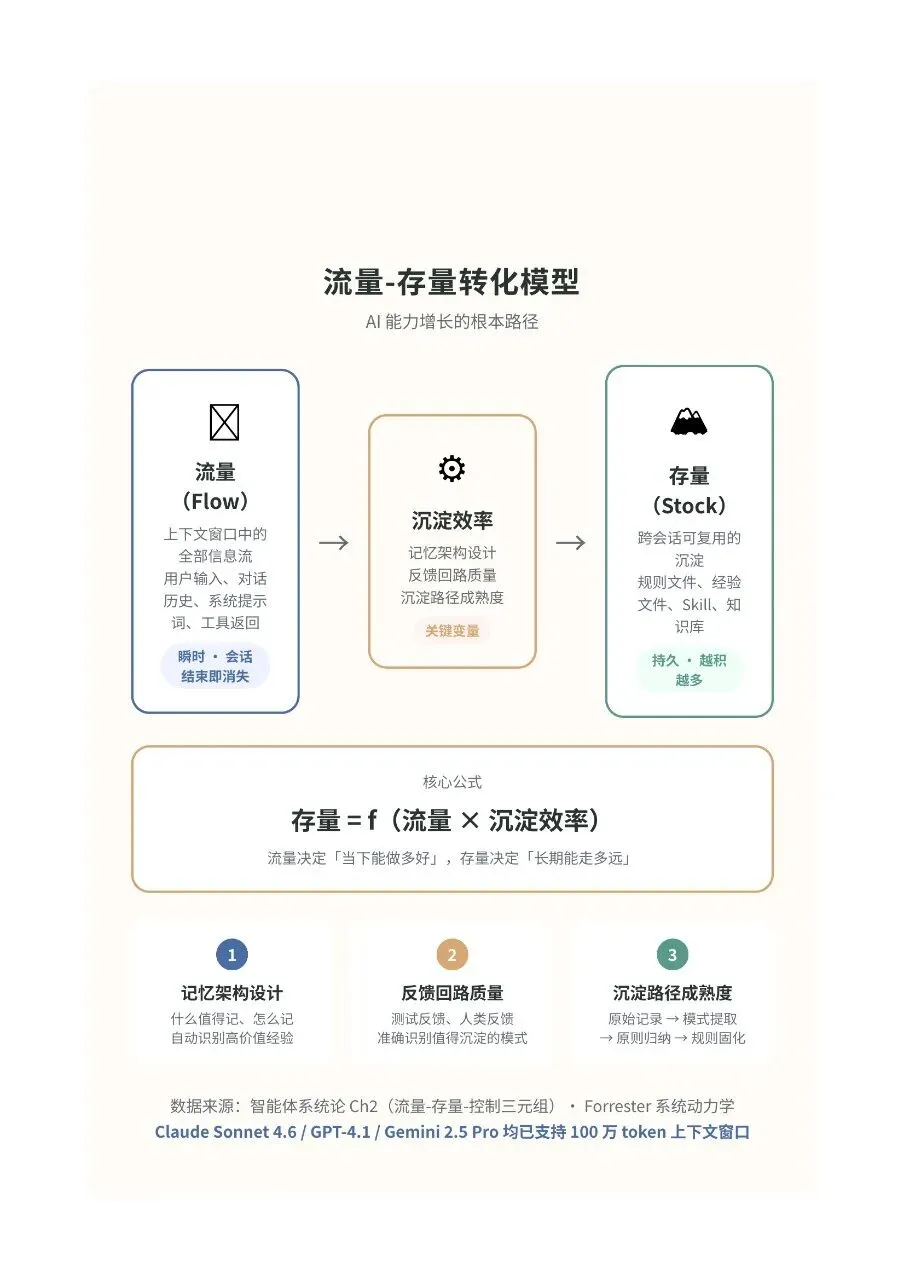
流量就是你跟AI交互过程中产生的所有有价值的信息,你的需求描述、你的反馈修正、你踩过的坑、你总结出的最佳实践。
沉淀效率就是这些信息里,有多少被你有效地保存下来了,变成了跨会话可复用的存量。
这个公式的妙处在于,它把一个看似玄学的问题「怎么让AI越用越强」,变成了一个可以操作的工程问题。你要做的就两件事,要么增加流量中的有价值信息,要么提高沉淀效率。
但坦率的讲,增加流量这件事,其实不太需要刻意去做。只要你持续使用AI,持续跟它交互,流量自然就在产生。真正拉开差距的,是沉淀效率。
沉淀效率取决于三个东西。
第一个,记忆架构设计。就是你有没有一套系统化的方式来组织和管理AI的记忆。不是随便写个文档丢在那里,而是有一套清晰的结构,AI知道去哪里找什么信息。比如用AGENTS.md来存项目基本信息和工作规范,用MEMORY.md来存历史经验和关键决策,用专门的Skill文件来封装反复使用的操作流程。这些东西不是拍脑袋想出来的,是一套有设计感的架构。
第二个,反馈回路质量。就是你有没有把使用AI过程中产生的反馈,有效地回流到存量里。AI这次犯了一个错,你纠正了它,但如果只是纠正了就完了,下次新会话它还会犯。你得把这个纠正记录下来,写进规则文件或者经验文档里,让下次的AI能读到。这就是反馈回路。没有反馈回路的系统,就像一个永远不会从错误中学习的人,永远在同一个地方摔倒。
第三个,沉淀路径的成熟度。就是从「发现一个有价值的经验」到「把它变成存量」这个过程,有多顺畅、多自动化。如果你每次都得手动复制粘贴、手动整理文档,那沉淀路径就很粗糙,你的惰性迟早会让你放弃。但如果这个过程是半自动化的,比如AI自己会在会话结束前把关键经验写入记忆文件,那沉淀效率就完全不一样。
说到控制机制这个事,其实还有一层更深的逻辑。
系统动力学里有个概念叫控制机制,分两种,前馈控制和反馈控制。
前馈控制,就是在事情发生之前就设定好规则,指导系统该怎么运作。放在AI系统里,System Prompt、AGENTS.md、Skill指令、Tool Schema,这些全都是前馈控制。它们在AI开始工作之前就告诉它,你是谁,你的工作规范是什么,遇到什么情况该怎么处理。
反馈控制,就是在事情发生之后根据结果来调整。测试反馈、人类反馈、实践反馈,这些是反馈控制。AI写了一段代码,跑不过,这是测试反馈。你觉得它写的不好,让它改,这是人类反馈。用了几天发现某个方案有问题,回头调整规则,这是实践反馈。
这两种控制缺一不可。
没有前馈控制,AI就没有一致性,每次都按自己的理解来,风格、规范、质量全靠运气。没有反馈控制,AI就无法从错误中学习,永远在原地踏步。
其实你想想看,这不就是人学习的模式吗。你上学的时候,老师教你的知识、课本上的公式、爸妈告诉你的道理,这些是前馈控制,在你遇到问题之前就给了你一套框架。而你做题做错了、考试考砸了、工作踩坑了,然后反思总结,这些是反馈控制,让你在错误中成长。
AI也一样。只不过AI更极端,因为它天然没有跨会话的记忆能力,所以它的前馈控制和反馈控制,必须由你来设计和维护。
这也是为什么,同样是用AI,有些人用了一年还是觉得「AI也就那样」,而有些人用了几个月就已经能让AI成为真正的生产力工具。区别不在于谁更聪明,在于谁更早想明白了流量和存量的关系,谁更早开始有意识地把流量转化为存量。
我自己的感受是,这个转变其实挺微妙的。
一开始用AI的时候,你不会觉得有什么问题。每次新会话,重新描述一下需求,AI就能干活,感觉还挺方便的。但随着你用得越来越深,项目越来越复杂,你会发现你花在「重新交代背景」上的时间越来越多。你开始烦躁,开始觉得AI怎么这么蠢,昨天不是已经说过了吗。
这个阶段,大部分人会怎么做?要么忍着,要么换一个「更好」的AI工具,觉得是工具的问题。
但其实问题不在工具,在于你还没有建立一套让AI「记住」的机制。
当你开始有意识地把经验、规则、偏好沉淀成文件,当你开始为AI设计一套记忆架构,你会发现一个特别神奇的事情。
AI真的变强了。
不是因为它本身变聪明了,而是因为它的起点变高了。每次新会话,它不是从零开始,而是站在你之前所有积累的基础上。你踩过的坑它不用再踩,你总结的最佳实践它可以直接用,你的工作规范它已经了然于胸。
这就是存量复利。
回到Forrester。
1960年代,他在MIT创建了系统动力学,提出了存量-流量模型。这个模型最初是用来分析工业系统的,后来被应用到城市规划、供应链管理、环境政策,甚至全球经济模型。Forrester的学生德内拉·梅多斯后来写了《系统之美》,把这套思想推广给了更广泛的受众。
但我觉得,Forrester最大的洞察不在于他发明了这个模型,而在于他看到了一个很多人看不到的事实。
存量-流量关系,是理解所有系统的钥匙。
不管是水库、银行账户、人体新陈代谢,还是一个AI助手的工作记忆,底层都是同一套逻辑。流量在持续变化,存量在相对稳定中缓慢积累。系统好不好用,不取决于某一刻的流量有多大,而取决于有多少流量被有效地转化成了存量。
你跟AI交互产生的每一次对话、每一条反馈、每一个经验,都是流过系统的水。如果你不建水库,这些水就白白流走了,你的AI永远在原地打转。如果你建了水库,哪怕一开始很小,只要水在持续流入,存量就会不断增长。
时间一长,差距就出来了。
其实说到这里,我还想承认一件事。
我自己也还在摸索这套东西。我说的这些道理,听起来挺清楚的,但真正落地的时候,你会发现有很多细节要处理。什么时候该沉淀,什么时候不该沉淀,沉淀的信息怎么组织,怎么避免信息过载,这些都是需要在实际使用中不断调整的。
我不是什么AI专家,也不是什么系统论大师。我就是一个AI编程的实践者,自学了一点系统动力学的知识,然后在日常使用AI工具的过程中,慢慢发现了一些规律。这些规律可能还不成熟,但我觉得,分享出来,至少能帮一些跟我一样在摸索的人少走一点弯路。
所以,屏幕前的你,下次再遇到AI「失忆」的时候,别急着骂它蠢。
停下来想一想,这个问题,是不是因为我没有给它足够的存量?
我是不是每次都让它从零开始,然后期望它表现得像记住了一切?
我是不是只顾着往系统里灌流量,却从来没有认真建过水库?
如果你开始想这些问题,恭喜你,你已经比大部分AI用户往前走了一大步。
下期,我们会聊一个更具体的话题,让AI记住经验,从一条规则开始。我会手把手地展示,怎么把你在使用AI过程中积累的经验,变成一条条可执行的规则,让AI每次新会话都能站在你肩膀上。
如果你现在就已经迫不及待想试试,可以先做一件事。打开你的AI工具,新开一个会话,把你最常用的那条工作规范写下来,保存成一个文件。就一条,不用多。
你会发现,下次新会话的时候,AI好像突然变聪明了一点点。
就一点点。
但这一点点,就是存量复利的起点。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。