 夜雨聆风
夜雨聆风





中国AI调用量反超美国
如果只给你看一张表,你会发现一件过去一年里所有人都在预测、但没人敢笃定的事已经发生了。
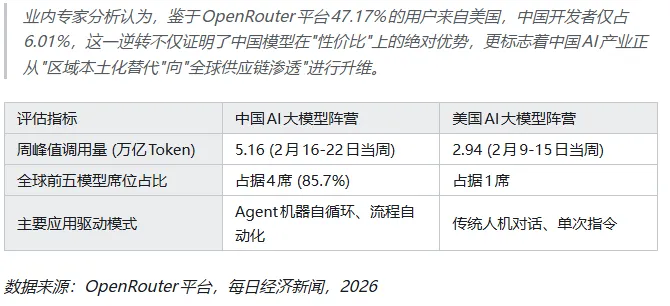
在全球最大的 AI 模型聚合平台 OpenRouter 上,2026 年 2 月 9 日到 15 日那一周,中国模型的调用量第一次超过美国模型。
4.12 万亿 对 2.94 万亿。
三周之后,中国模型一周的调用量飙到 5.16 万亿,三周涨了 127%。到了二、三月整体盘点,Top10 模型里,中国模型吃掉了 61% 的 Token 消耗。更夸张的是 Top5 里,中国模型占了四席,合计份额 85.7%。
这不是”赶上”,这是换位。
一、什么是 OpenRouter,为什么这个数字重要
简单说,OpenRouter 是一个 API 分发平台,开发者在上面可以随意切换调用全球几百个大模型。它有点像 AI 界的”携程”,不卖机票,卖 Token。
开发者为什么用 OpenRouter,逻辑很朴素:哪个模型便宜、好用、稳定,就调哪个。没有地缘滤镜,没有国别情怀,一切以效果和成本说话。
所以 OpenRouter 的调用量排行榜,是目前衡量大模型”谁真的被用起来”最硬的指标之一。它比发布会吹的参数、比 Benchmark 的榜单都更接近真实世界。
一个模型能在 OpenRouter 上冲到榜首,只有两种可能:
-
便宜得离谱 -
好用得离谱 -
最好是既便宜又好用
这次冲到榜首的那个模型,叫 MiniMax M2.5,2 月份一家公司就吃掉了 4.55 万亿 Token。紧跟在后面的,是月之暗面的 Kimi K2.5,4.02 万亿。
二、成本差距:17 倍到 20 倍
所有人第一反应都会问:凭什么?
答案的一半在价格表里。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
贵 17 到 20 倍。
如果你是一个每天要烧掉几亿 Token 的 AI 产品团队,这个差距翻译成现金流,就是生与死。
过去大家安慰自己,美国模型贵,是因为贵得值。它更聪明、更不容易出错、更能处理复杂任务。这句话在 2024 年是对的,在 2025 年开始摇摆,到 2026 年 4 月,已经彻底不成立了。
三、智谱 GLM-5.1:第一次在核心榜单上反超
真正让硅谷坐不住的,是 4 月 8 日智谱发布的 GLM-5.1。
在 SWE-Bench Pro 这个业内公认最接近真实软件开发的基准测试上:
- GLM-5.1:58.4 分
(全球第一) -
GPT-5.4:57.7 分 -
Claude Opus 4.6:57.3 分
中国模型第一次在一个硬核代码基准上拿到了全球第一。
更关键的一个能力,叫长程任务。过去所有模型都有一个隐形天花板:让它连续工作超过一两个小时,就会开始丢上下文、重复回答、越写越乱。GLM-5.1 是目前唯一一个能稳定连续工作 8 小时的开源模型。
8 小时意味着什么?意味着你可以在下班前把一个完整的需求丢给它,第二天上班看结果,中间它自己会规划、会调试、会回退、会继续。这是从”AI 助手”到”AI 员工”的分界线。
GLM-5.1 还有个细节很能说明问题:字节跳动的编程助手 TRAE,和智谱做了 Day 0 同步接入。字节自己也有大模型,但他们的编程产品直接选择了外部的 GLM-5.1。这说明在内部测试里,GLM-5.1 至少在某些场景上,赢了字节自家的底座。
智谱同时把价格涨了 10%。能涨价,说明他们相信客户跑不掉。
四、为什么会反超:三股力量同时发力
这件事不是某一家公司的胜利,是一整条链在共振。
第一股力:极致成本
国内模型之间的价格战打了两年,惨烈到让海外看客都觉得不可持续。但结果是,整个中国 AI 生态把”每百万 Token”的成本压到了美国同行望尘莫及的位置。当一个模型能力接近、价格只有对方二十分之一,开发者不需要做任何政治判断,拿计算器就能决定迁移。
第二股力:开源策略
-
GLM-5.1 是开源的 -
Kimi K2.5 是开源的 -
Qwen3.6 是开源的 -
OpenAI 的 o 系列和 GPT-5 不是 -
Claude 不是
开源的意思是任何公司都可以私有化部署、可以微调、可以审计代码、可以在不可信网络里用。对于海外的中型企业来说,开源中国模型 + 自建推理,比闭源美国 API 更划算也更放心。
第三股力:规模红利
国内每天处理的 Token 数,已经涨到 140 万亿。这是什么概念?2024 年初,这个数字才 1000 亿。两年涨了 140 倍。
背后是豆包 2 月日活破亿、AI 短剧把制作成本从上百万压到 10 万人民币、钉钉里跑着上亿个企业 Agent。规模带来的不只是营收,还是反馈数据。模型越被用,越知道哪里该优化,这是一个正反馈。
五、资本层面也跟上来了
产业看表面,资本看预期。
2025 年三大厂 AI 资本支出:
- 阿里巴巴:1230 亿人民币
(直接把当年净利润打下来 66%) - 腾讯:790 亿人民币
- 字节跳动:230 亿美元
这三家的投入加起来,已经逼近美国超大规模云厂商的水平。
上市节奏也在加速:
- MiniMax
:2025 年营收 7900 万美元,同比增长 159%,海外收入占 70% - 智谱
:营收 7.24 亿人民币,同比增长 132% - 月之暗面
:传言以 100 亿美元估值准备冲香港 IPO
这些公司共同点是:仍然在巨亏,但收入曲线陡峭。资本市场愿意给他们估值,是因为相信”反超 OpenRouter”不是一次偶然,而是一个可持续的位置。
六、真正值得警惕的几个问题
把话说完整,也要说说不该乐观的部分。
- 调用量 ≠ 利润
。OpenRouter 上中国模型跑得猛,相当一部分是海外开发者在低价试用。一旦价格战结束或者某家公司撑不下去涨价,用户迁移成本其实很低。 - 基础设施还在卡脖子
。国内 AI 训练对高端 GPU 的依赖并没有消失,只是分散到了云端租用、海外结点、以及国产替代的艰难爬坡里。阿里 4 月 8 日发布基于真武芯片的数据中心是个信号,但距离成熟还远。 - 英文世界的信息战没开始打
。中国模型在 OpenRouter 上赢了 Token,但在开发者社区的心智里还没赢。Reddit、HackerNews、Twitter 上讨论最多的仍然是 GPT、Claude、Gemini。一个模型要成为”默认选项”,还需要大量的英文生态建设。
七、给开发者的一点实操建议
如果你是在做 AI 产品的人,这波信号值得你做一件事:
今晚就去 OpenRouter 开个号,把同一个业务 Prompt 挨个打到 MiniMax M2.5、Kimi K2.5、GLM-5.1 上跑一遍。
不需要全面替换,先拿成本最高的那部分调用做试点。很可能你会发现,月账单可以直接砍掉一个数量级,而效果没什么差别。
-
如果你在做长程 Agent,重点看 GLM-5.1。8 小时连续工作这件事,对工作流类产品是降维打击。 -
如果你是企业决策者,这是一个好时机重新审视你的 AI 供应商策略。把所有蛋放在一两个美国闭源模型上,已经不再是最优解。
八、一个时代结束的方式
很多时候,一个时代的结束不是靠一场发布会、一篇爆文宣告的,而是悄悄发生在后台数据里。
2026 年 2 月 15 日,OpenRouter 后台跑过去的那 4.12 万亿对 2.94 万亿,可能就是那个时刻。
没有庆祝,没有新闻联播,只有一批海外开发者的 API Key 悄悄换了供应商。
这大概也是 AI 时代最真实的一种胜负规则:谁能让用户愿意掏钱、愿意留下,谁就在赢。
至于面子,反超这件事本身,就够了。
参考来源
-
Chinese AI models overtake U.S. rivals in global token usage — CGTN -
Chinese AI Models Hit 61% Market Share On OpenRouter — Dataconomy -
OpenRouter State of AI 2025 -
全球最强开源模型来了,智谱发布旗舰 GLM-5.1 — 21 世纪经济报道 -
中国 AI 领域最新动态 — 财富中文网