 夜雨聆风
夜雨聆风





AI 短剧炸场!Seedance 2.0 vs 可灵 3.0,万元成本拍出电影级成片
3月初,短剧《霍去病》引爆全网,国民级IP的影响力与AI工业化生产的高效率形成双重共振,即便伴随显著的舆论争议,其技术突破也成功打破了IP运营与AI技术两大领域的壁垒,迅速催生出“IP+AI制播”的全新行业范式。彼时,当短剧行业仍深陷“百万成本、数月周期”的传统模式难以突破时,一场由AI技术驱动的行业“地震”,已悄然改写行业格局。
字节跳动Seedance 2.0与快手可灵3.0两大AI视频大模型的落地,成为这场行业变革的核心推手——它们将短剧制作成本从百万级压缩至万元级,制作周期从数月缩短至数天,彻底重构了从剧本构思到成片输出的全链路生产模式。这绝非简单的工具升级,更标志着短剧行业从“野蛮生长”向“精品化、数智化”转型的关键拐点已然到来。

双雄对决,Seedance 2.0 vs. 可灵3.0:技术路径各有侧重
Seedance 2.0:多模态全能,适配规模化工业生产
作为字节跳动推出的多模态AI视频模型,Seedance 2.0正如其官网所定位的——“面向专业创作的多模态AI视频引擎,主打‘一句话出电影级成片’”,支撑这份实力的,是Seedance 2.0背后的核心技术架构:字节自研Seed大模型 + 双分支音画同步扩散 + 时空一致性Transformer + 导演级叙事引擎。简单来说,它并非“一帧一帧盲目生成”,而是像专业创作者一样,先深度理解剧情内核,再规划镜头语言,最后同步生成画面与配音,全程确保角色形象、场景设定不跑偏、不崩坏。

其中,“双分支音画同步扩散”所采用的双分支扩散变换器(Dual-branch DiT, DB-DiT),是其技术核心亮点。这一架构是基于Diffusion Transformer (DiT) 发展而来的高级变体,核心创新在于将单一的去噪路径解耦为两个并行且功能分工明确的分支,通过专门化建模与动态融合,大幅提升视频生成的质量、时序连贯性与多模态同步能力。其核心原理是用Transformer架构替代传统扩散模型(Diffusion Model)的U-Net主干,将图像/视频分割为Patch Token,通过自注意力机制建模全局依赖,让生成内容更具逻辑性与完整性。
这两个核心分支各有侧重、协同发力:一是语义/结构/视觉分支,专注于语义理解与构图逻辑,确保人物姿态、场景布局、物体轮廓、文本对齐与角色身份的高度一致性;二是运动/细节/音频分支,精准控制帧间运动轨迹、纹理演化与声波相位,让人物眨眼频率贴合台词节奏、衣褶摆动呼应背景音乐BPM波动。为实现两分支的深度融合,DB-DiT引入跨分支注意力(Cross-Branch Attention, CBA)机制——在每个去噪层中,视觉分支的Token主动查询运动分支的时序特征,反之亦然,实现语义引导运动、运动反哺结构的双向调制;同时搭配可学习的动态门控融合(Dynamic Gated Fusion),在噪声逐步清除的过程中自适应平衡两个分支的权重,最终输出帧间过渡自然、口型精准、声画严丝合缝的高质量视频。
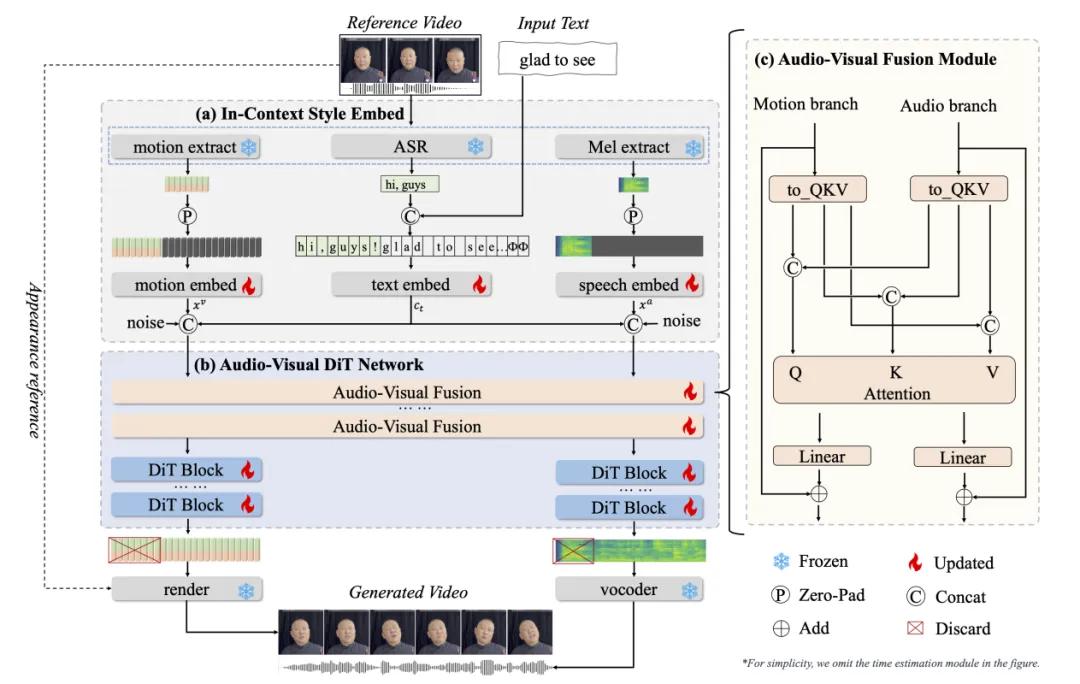
值得注意的是,Seedance 2.0还采用了Flow Matching扩散模型(而非传统高斯扩散)生成高清帧,并搭配时空一致性Transformer(Spatio-Temporal Consistency Transformer, STCT)。通俗来讲,通过扩散模型AI生成图像的效果更丝滑、更清晰、更稳定;STCT则如同拥有超强记忆的“AI导演”,时刻牢记所有角色、场景与动作细节,确保内容在空间与时间上的一致性。两者结合,不仅让生成画面更清晰稳定,更能在人物塑造中保持角色、场景、动作从头到尾统一,成为短剧工业化生产的优选。
可灵3.0:物理精准,主打专业影视质感
可灵3.0是快手推出的新一代多模态AI视频生成模型系列,其核心技术突破集中在All-in-One一体化架构、原生4K/60fps音画同步、主体一致性与物理拟真四大方面,标志着AI视频生成已从碎片化片段创作,迈向专业级影视制作的新阶段。
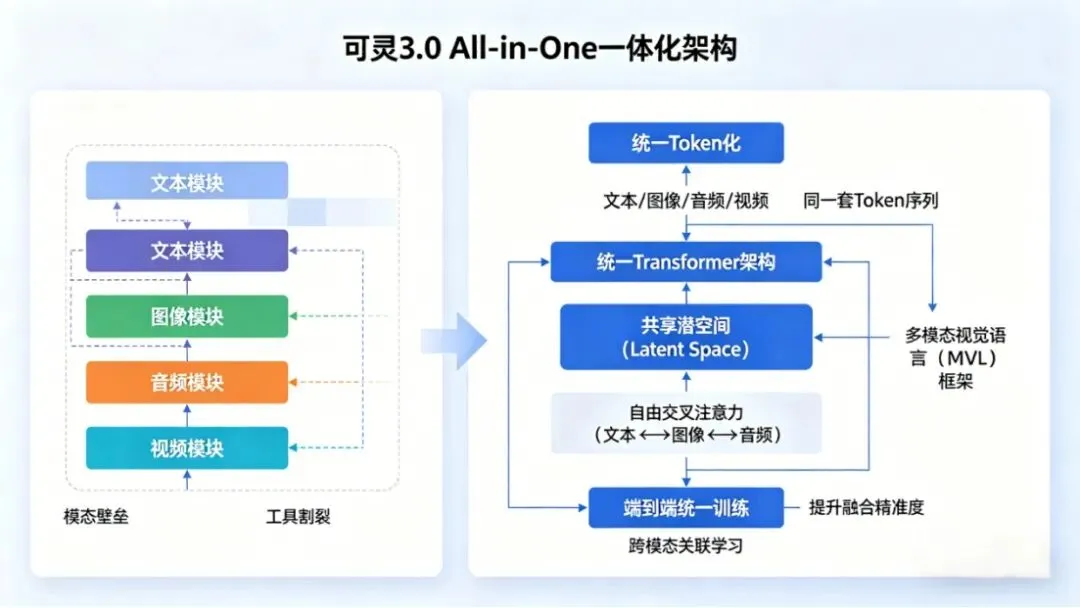
All-in-One一体化架构是可灵3.0的技术核心,其本质是一套统一的模型架构、表征空间与工作流,能够原生支持文本、图像、音频、视频等所有模态数据的输入、理解、融合、生成与编辑,实现“一站式”全链路处理,彻底打破了传统多模态系统的模态壁垒与工具割裂问题。与传统多模块拼接的模式不同,可灵3.0彻底重构了底层架构,采用多模态视觉语言(MVL)框架,在共享潜空间(Latent Space)内统一处理各类模态数据。
其技术逻辑主要分为三步:一是统一Token化,将文本、图像、音频、视频等所有模态数据编码为同一套Token序列,从根源上消除模态边界;二是统一Transformer架构,不再区分“文本大模型”与“视觉模型”,通过一个Transformer架构处理所有模态数据,实现任意Token间的自由交叉注意力(文本←→图像←→音频);三是端到端统一训练,将文本、图像、音频、视频数据同时输入模型,让模型自主学习跨模态关联,提升多模态融合的精准度。
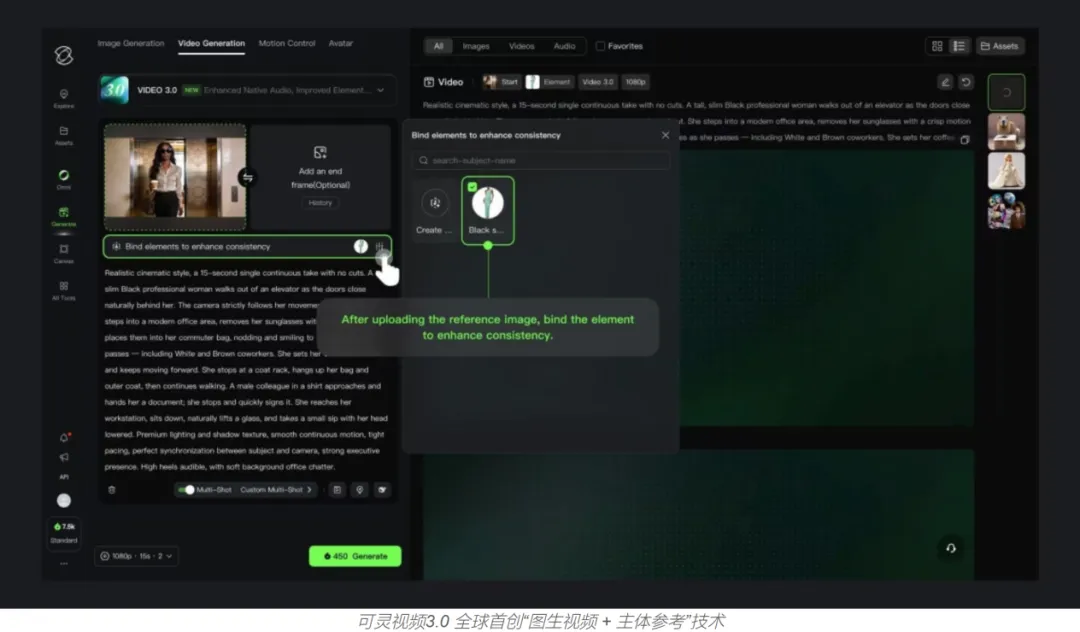
除了底层架构的革新,可灵3.0还有两大突出亮点。其一,图生视频+主体参考技术,这是可灵3.0最具标志性的功能,也是目前行业内最成熟的角色/物体锁定技术。通俗来讲,只需输入一张人物或物体照片,通过添加描述,模型就能让照片中的主体动起来,且无论动作如何变化,主体的外形、特征都不会变形、不会“变脸”,因为模型已通过输入的照片精准锁定了主体的核心特征。其二,物理引擎3.0,彻底解决了传统AI生成视频的“物理违和感”——以往的AI生成视频仅能模仿画面,却不懂真实物理规则,而可灵3.0搭载的物理引擎可在虚拟世界中精准模拟现实物理规律:人物不会凭空漂浮,手碰到身体不会出现“穿模”,风吹过时衣褶会自然摆动,关节不会出现反折,跑步时会有真实的惯性反馈。可以说,可灵3.0能够生成主体始终一致、且完全符合真实物理规律的动态视频,大幅提升了AI生成内容的专业质感。
AI不是淘汰人,是淘汰不会用AI的人
随着两大AI视频模型的落地,一个普遍的担忧随之而来:AI如此强大,短剧行业的演员、摄像、后期工作人员会不会面临失业?答案是否定的——AI淘汰的,从来不是“从业者”,而是“只会重复劳动、缺乏创意”的人;真正能在行业中站稳脚跟的,是那些“懂得运用AI、驾驭AI,将技术与创意结合”的人。
Seedance 2.0的核心价值,是帮从业者搞定批量生产的繁琐工作,降低规模化创作的门槛;可灵3.0的优势,则是帮从业者提升内容质感,实现专业级创作的低成本落地。但无论是批量生产还是质感提升,都只是“工具层面”的助力,短剧的核心——剧情创意、情感表达、价值观传递,始终离不开人的思考与创作。
2026年的短剧行业,竞争逻辑已彻底改变:不再是“谁更能吃苦、谁更能拼产量”,而是“谁更懂AI、谁能把AI工具与创意能力深度融合”。对于行业新手而言,无需畏惧行业壁垒,选对AI工具,就能以万元级成本、数天周期入局,实现“低成本试错”;对于行业老手而言,唯有主动升级能力,熟练运用AI工具赋能创作,才能打造属于自己的爆款IP,在行业变革中抢占先机。

「READING」
参考资料:
-
Zhongjian W et al., 2025, 《OmniTalker: Real-Time Text-Driven Talking Head Generation with In-Context Audio-Visual Style Replication》, Tongyi Lab, Alibaba Group https://humanaigc.github.io/omnitalker/ -
快手 可灵3.0系列模型全面上线 开启“人人皆可当导演”的新时代 https://kuaishou.gcs-web.com/zh-hans/news-releases/news-release-details/keling30xiliemoxingquanmianshangxian 20260205


【技术饭】
联想研究院 PCIE
唯一技术类公众平台
微信号
Technical Fan
喜欢我们的内容就点“在看”分享给小伙伴哦 
