 夜雨聆风
夜雨聆风





AI 能理解模拟验证吗?

它不是把电路画出来,而是要反复确认:在各种设置、激励、工艺角下,电路的功能和性能是否满足需求,指标还剩多少裕量,哪里要再改。
一个项目周期里,验证花的时间往往是画电路本身的几倍。
当前用 AI 设计模拟电路,最直接、通用的一条路径是:让 agent 写网表、调 Spectre 仿真、读结果、再迭代修网表。
但一旦走向可落地的设计,大量实际问题迅速浮现:仿真设置、输出表达式、工程约束,各自分散且高度定制。
理论上可以通过蒸馏一份份 skill 来补齐,但启动成本高,且需要持续维护。
实际上,模拟验证所需要的很多信息,早已沉淀在设计师日常跑的 testbench 里。
只是过去缺一个低成本的读者。
01 让 AI 先捡软柿子捏
很多人问,AI 介入模拟电路,应该从哪里开始?
我的答案一贯是:先捡软柿子捏,优先从语义信息丰富的地方入手。
网表天然是文本形式,对 LLM 十分友好。
但如果只依赖电路拓扑网表,信息是明显不完整的。
第一,仿真设置 AI 写不好。
仿真器的输入是“电路网表+仿真设置”。
而仿真设置本身种类繁多,例如 tran、pss、pnoise、strobe、工艺角、蒙卡、信号保存等,各自拥有独立的参数体系与语法结构。
没见过,就是写不出。
你可能说,找几个样例蒸馏成 spectre.skill 不就行了。

蒸馏文本是极其容易的。
但实际操作中,网表分散在各处,路径不统一。
要覆盖常用配置,需要人工逐一翻检大量数据,启动成本不低,同时还需要持续维护。
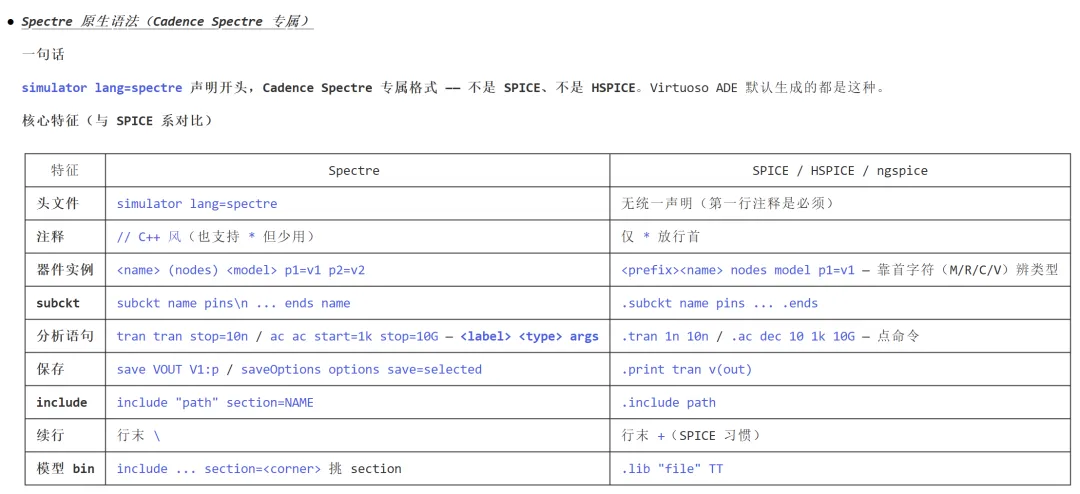
第二,输出表达式 AI 定不了。
不同电路的评估指标高度定制化。
放大器关注 GBW/PM,比较器看噪声、延迟、能效,LDO 看 PSRR 和过冲,采样电路设计某些时刻波形的线性度,ADC 往往需要看数字码与模拟波形重组之后的性能。
这些判断标准并不体现在网表中,而是体现为输出表达式。
这部分内容直接反映了设计者的分析方法与经验,本身具有较高价值,但在传统的流程中是“隐形”的。
它们存在于 Maestro 中。
02 模拟验证的中枢:Maestro
Cadence 的用户都熟悉 Virtuoso 这个词。
Virtuoso 源自意大利语,指在某种艺术(尤其是音乐演奏)方面拥有卓越技巧的人。例如帕格尼尼被公认为小提琴界的 Virtuoso。
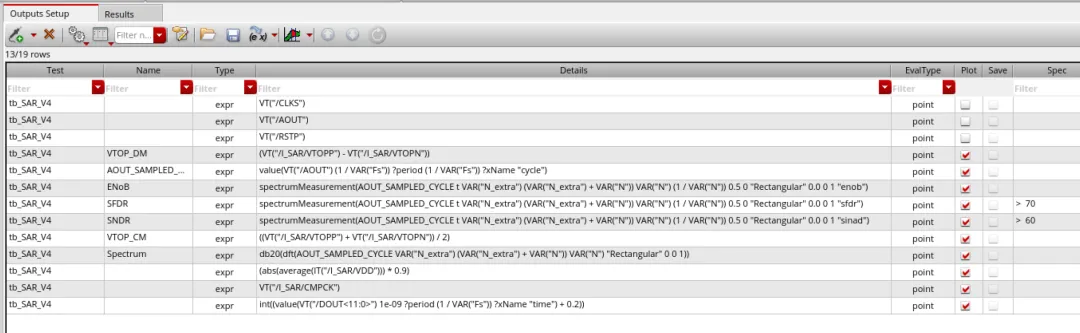
Virtuoso 平台里做仿真验证的那一层叫 ADE(Analog Design Environment)。ADE 提供两个入口:Explorer 和 Assembler。
两者共享同一数据源,叫 Maestro。

Maestro 同样源于意大利语,意为“大师”或“导师”,在现代语境中也常指“指挥家”。在 Cadence 体系中,它承担的正是调度与统筹的角色。
本质上,Maestro 是一套数据库。多测试条件、工艺角、输出定义、规格比对、验证流程以及历史记录,均统一存储于其中。Explorer 与 Assembler 只是访问它的不同界面。
原理图与版图承载的是设计本身,而 Maestro 承载的是设计意图与验证方法。
几乎每个模拟验证工程师的核心工作场景就是跟 Maestro 打交道。
Maestro 对工程师呈现为层层嵌套的 GUI。
部分功能有 skill 接口,但覆盖有限,很多操作仍依赖人工点击。
一个项目周期内,交互次数往往达到数千甚至上万次。
王忆博士专门写了一本书《模拟集成电路仿真与实用电路分析》,介绍 Maestro 相关的各种操作细节。
我们买了 4 本实体书以传阅。开源有益,受益匪浅。

以上是人眼中的 Maestro,浩如烟海,学无止境。
——
但从机器的视角看,Maestro 的核心仅是两个明文的文本文件!
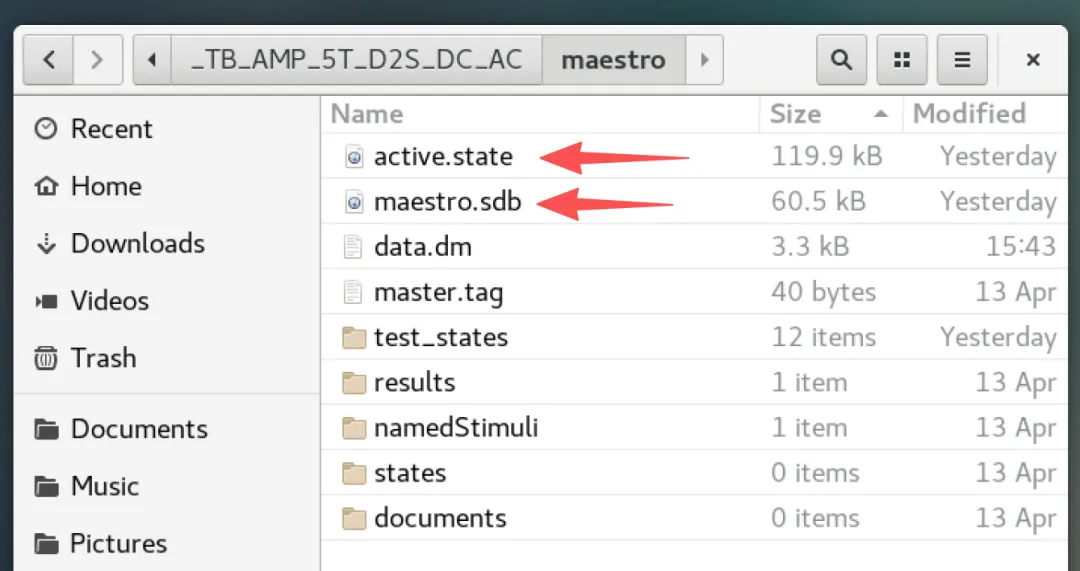
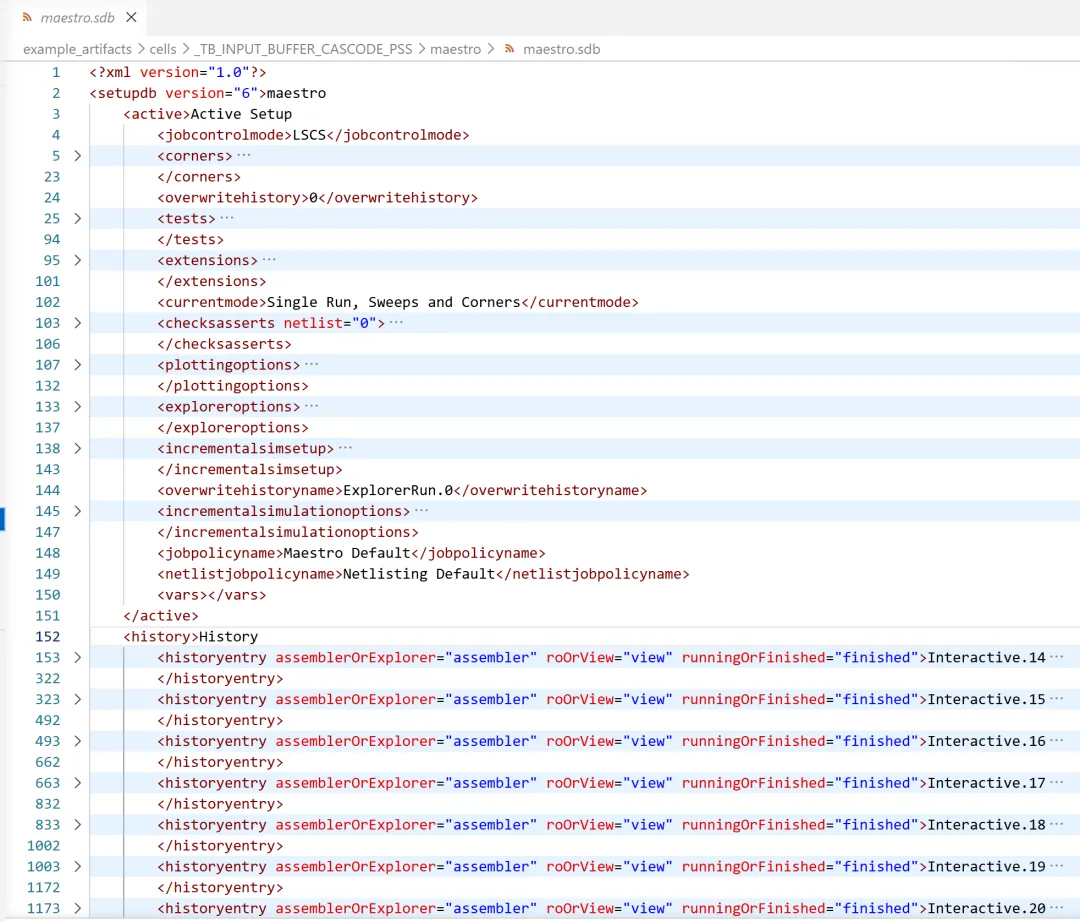
1)maestro.sdb:总体设置。
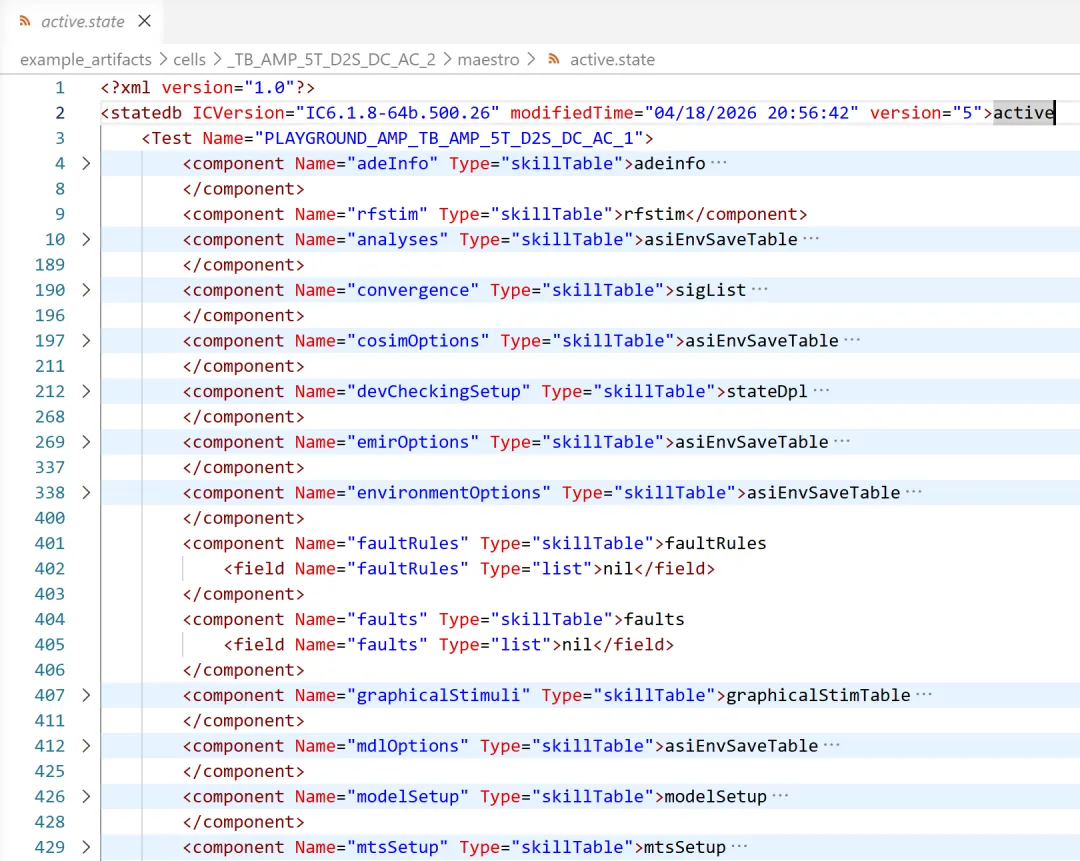
2)active.state:当前活跃测试的细节。
所有的仿真设置、输出表达式、工艺角设置、环境设置、仿真历史、相关文件的路径,全部以结构化形式明文写入其中。
下图是 maestro.sdb 的内容。
下图是 active.state 的内容。
Maestro 的复杂性主要来自 GUI,而不是数据本身。
脱离界面之后,本质只是结构清晰的 XML 文本:
字段自解释,表达式完整,路径与历史可追溯。
——
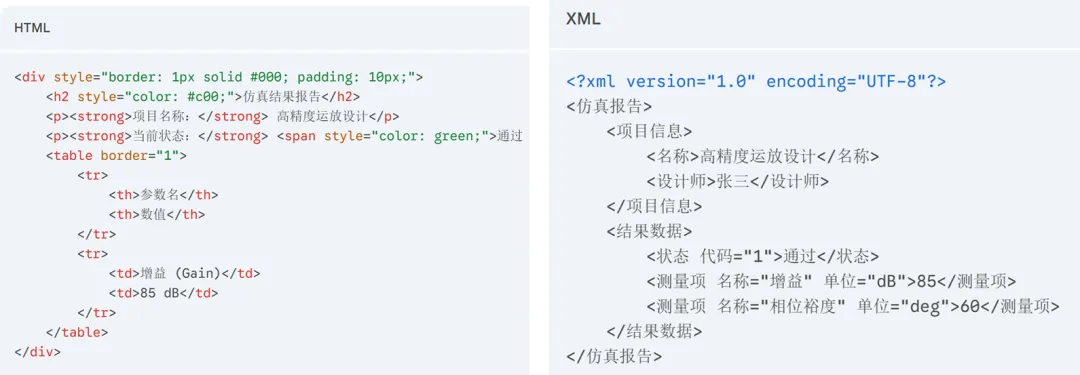
什么是 XML?
XML,全称 Extensible Markup Language,可扩展标记语言。
核心就一件事:用标签把信息结构化地表达出来。
它的一个近亲是 HTML(HyperText Markup Language),超文本标记语言,是网站前端设计的三大核心技术之一。
HTML 的标签是固定的,比如 <div>、<p>,你只能按规则使用;而 XML 的标签是设计者根据业务自定义的。
众所周知,现代大模型最擅长的事情之一是做网站。
那么请问:大模型解析 XML 格式的 maestro 的能力如何呢?
答案很简单:没有任何难度。
随便找几个 maestro 进行解析。
放大器。
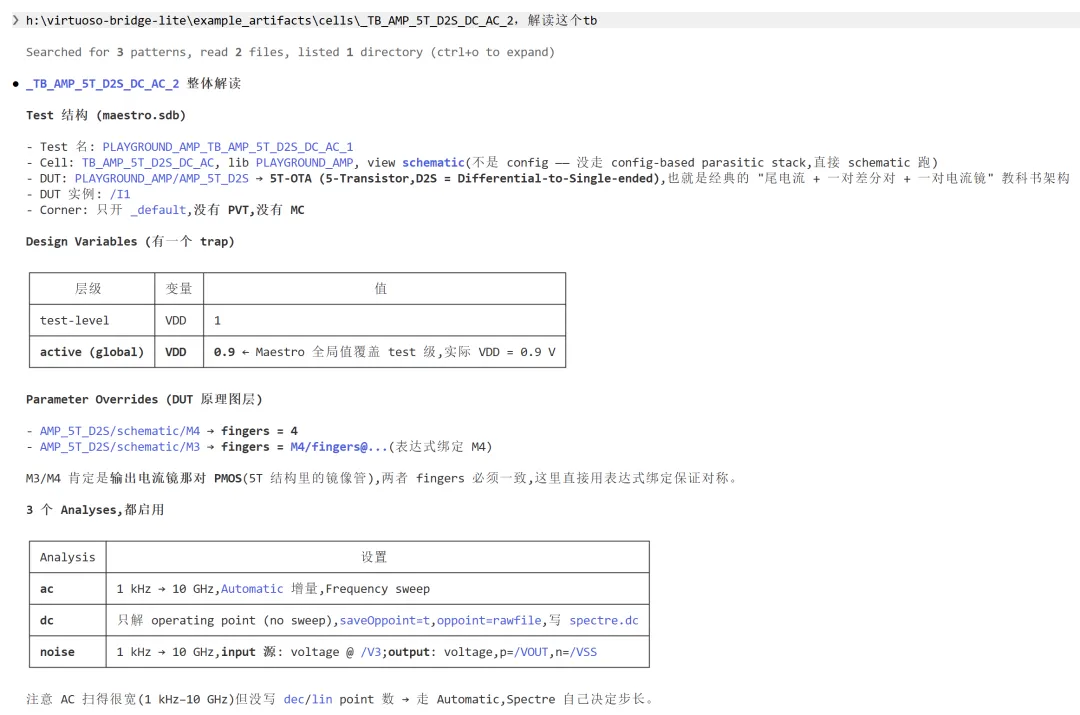
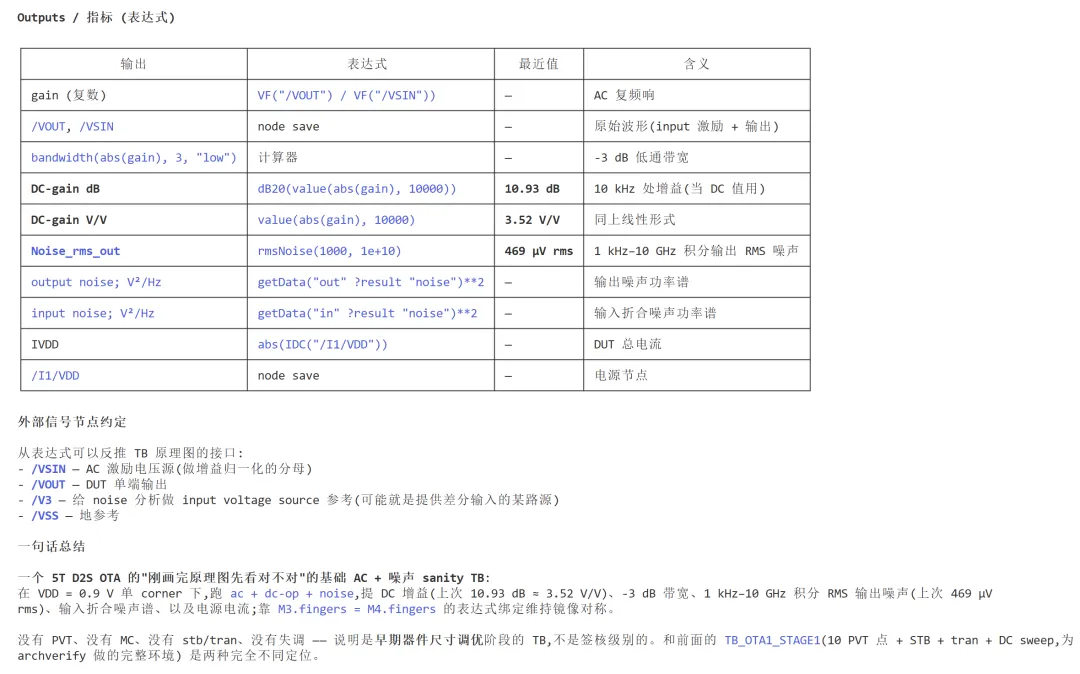
比较器。
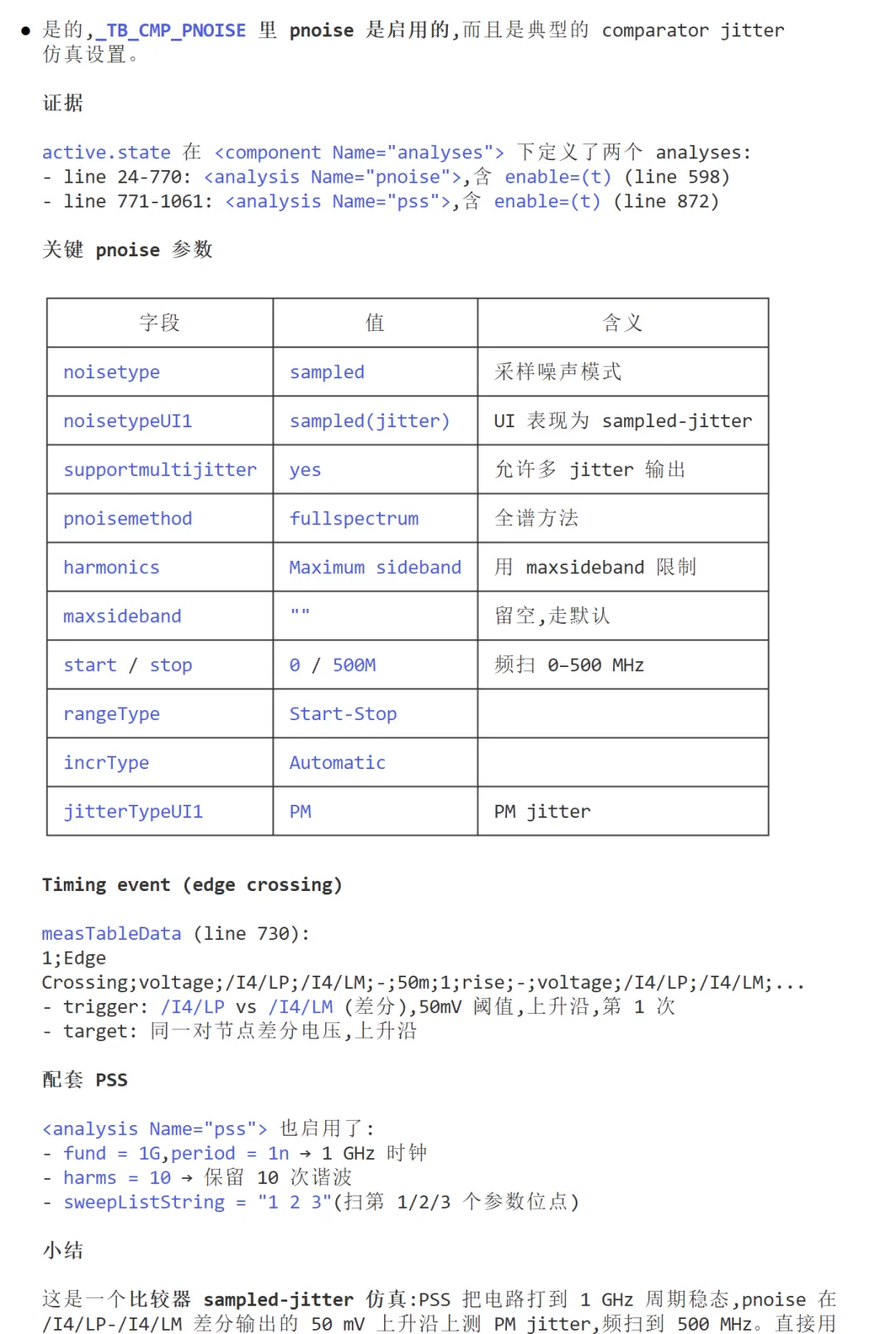
当这些能力串联起来,Maestro 不再只是一个被动承载配置的数据库,而是演变为一个可被计算、可被调度、可持续演进的验证系统核心。
03 陈年 testbench 是富矿
Testbench 固化了设计者在当时的全部判断:激励信号如何构造,仿真如何配置,哪些信号需要保存,输出表达式如何定义。
这些内容并非人为编造,而是在真实设计流程中逐步沉淀的结果。XML 结构将这些细节完整保留下来。
随着时间积累,一个团队往往会沉淀出数百甚至上千个 Maestro 工程。这些历史 testbench,本质上构成了一套高度贴合实际工程的经验库。
过去,这些数据被封印在 GUI 中,难以系统化利用。
现在,显然可以用 AI 高效解析与归纳。
针对任意一种验证需求,都可以从历史数据中提取对应模式,形成 skill。

这些 skill 的针对性极强,直接对应具体公司、工艺与电路类型,而不是泛化经验。
此外,Maestro 中不仅包含配置本身,还记录了网表、日志与仿真结果的路径。
顺着这些索引,AI 可以重建完整的仿真上下文:激励方式、观测指标、corner 扫描策略,以及历史调试过程。
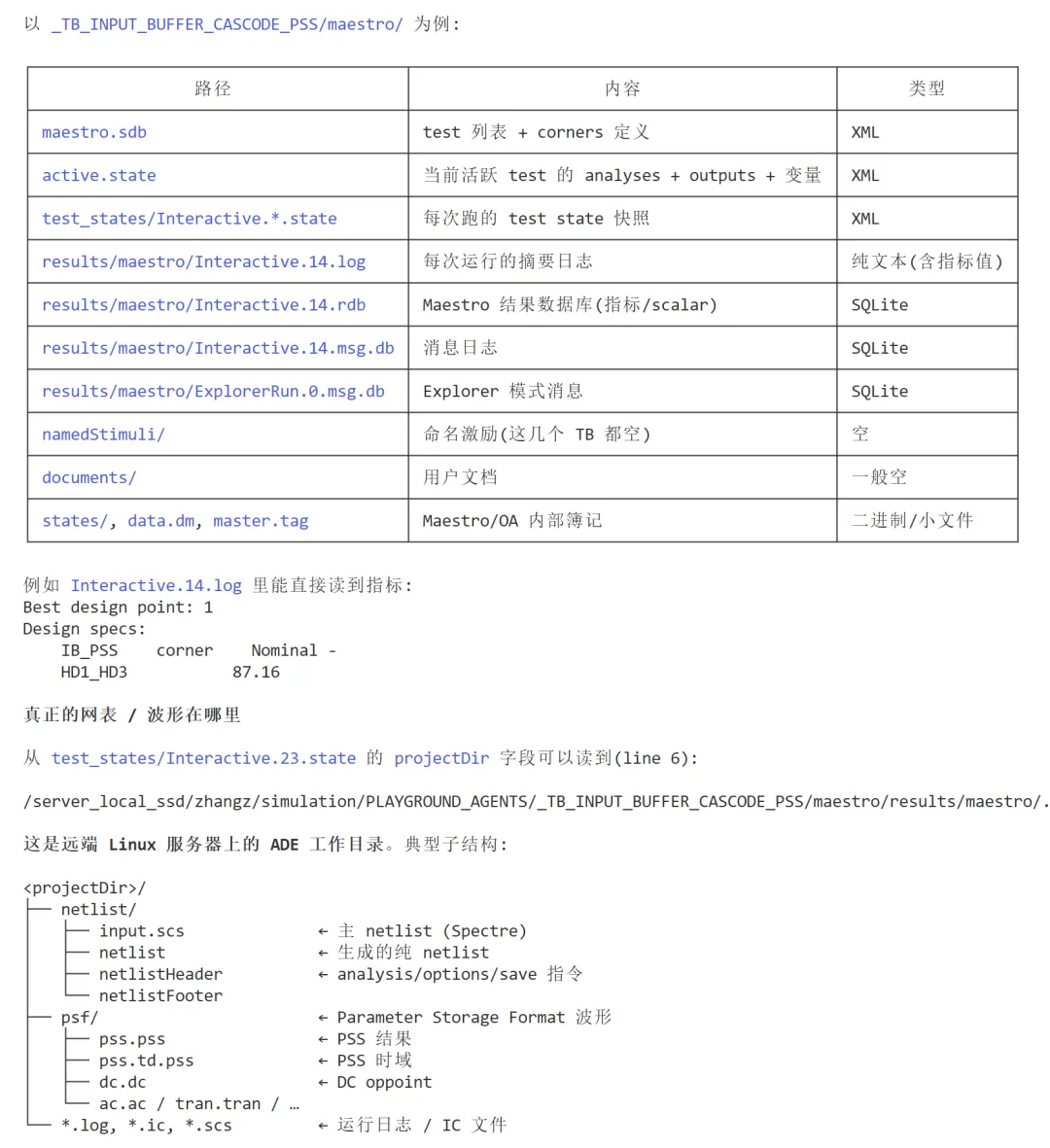
模拟设计的全过程具备了可系统继承与复用的条件。
Agent 是使用方,工程师是积累方,Maestro 是连接两者的载体。
过去积累与使用之间存在断层,而明文存储的 XML 结构使这一断层得以弥合。
在智能体时代,token 成为新的生产资料,而 Maestro 中沉淀的测试意图,则是上一阶段积累下来的核心资产。
一旦两者打通,原本难以利用的历史数据便转化为可直接驱动生产的资源。
04 尾声
回到最初的问题:AI 能理解模拟验证吗?
只看网表,它能理解一部分。
读到 Maestro,它能理解得更多。
大量可用的“技能”,早已沉淀在工程师日常使用的 Maestro 数据之中。
当这些历史 testbench 被系统化利用,AI 完全能直接继承一代工程师的验证经验。
问题已经不在于争论 AI 能不能理解模拟验证。
分水岭在于:谁先把这些沉淀的经验转化为可复用的资产?
一旦完成,模拟验证将不再是人力密集型流程,而是一个可以持续积累、自动演进的系统。

附记
本文展示的是一种可能性。
从技术路径来看,关键环节已经非常清晰,整体实现已经不存在实质性的技术障碍。
从行业发展状态来看,这类方法也不太可能停留在“设想”。在一些具备数据积累与工程能力的团队内部,类似的实践早已以不同形式存在,并持续演进。
真正的挑战更多集中在工程层面,包括数据合规、系统集成、工具链适配等问题。这些问题复杂,但并不构成能力边界,而是落地过程中的工程组织与投入问题。
换句话说,问题不在于能不能做,而在于何时系统化,以及做到什么程度。