 夜雨聆风
夜雨聆风





你的AI助手会"翻旧账"吗?ClawArena告诉你,绝大多数Agent在信息变化面前一塌糊涂
你的AI助手会”翻旧账”吗?ClawArena告诉你,绝大多数Agent在信息变化面前一塌糊涂
你有没有注意到一个很尴尬的现象——我们现在评测AI Agent的方式,跟Agent实际要面对的工作场景,根本不在一个维度上?
SWE-bench让Agent修bug,WebArena让Agent上网操作,AgentBench让Agent做各种任务。这些测试有个共同的隐含假设:信息是静态的、来源是可信的、用户偏好是明确说出来的。
可现实呢?你上午跟Agent说”这个项目用React”,下午产品经理在群里改了技术方案,第二天设计师的文档又是另一套说法。Agent需要自己判断谁说的靠谱,需要根据新信息修正之前的结论,还得从你零散的反馈里自己悟出你喜欢什么风格。
这篇来自UNC-Chapel Hill的论文,做了一件很有价值的事:设计了一个专门测试Agent在动态、矛盾、含糊信息环境中生存能力的基准——ClawArena。64个场景,近1900轮评测,365次动态更新。测完之后的结论也挺扎心的:模型能力差异造成15.4%的性能波动,框架设计只贡献9.2%。也就是说,框架再花哨,模型不行还是白搭。
📖 论文信息
-
标题:ClawArena: Benchmarking AI Agents in Evolving Information Environments -
作者:Haonian Ji, Kaiwen Xiong, Siwei Han, Peng Xia, Shi Qiu, Yiyang Zhou, Jiaqi Liu, Jinlong Li, Bingzhou Li, Zeyu Zheng, Cihang Xie, Huaxiu Yao -
机构:UNC-Chapel Hill、UC Santa Cruz、UC Berkeley -
日期:2026年4月5日 -
链接:arXiv | GitHub
🎯 为什么需要这个基准?
说实话,现有的Agent评测体系有一个很明显的盲区。
我拿几个典型的来说:SWE-bench测的是Agent能不能在一个明确的代码仓库里修一个明确的bug;WebArena测的是Agent能不能在网页上完成指定操作;HotpotQA之类的长上下文QA测的是Agent能不能从一堆静态文档里找到答案。
这些评测的共同特点——单一权威来源、静态信息、显式指令。
但真实的”持久性助手”(persistent assistant)场景是什么样的?你让一个Agent长期帮你管项目,它得面对:
-
多源冲突:A说deadline是3月15号,B的邮件里写的是3月20号,群聊记录又是另一个日期。Agent不能简单做信息聚合,它得判断谁更可信。
-
动态更新:上周的结论到这周可能就过时了。新来一封邮件、改了一个配置文件,之前正确的答案可能就变成了错误的。
-
隐式偏好:用户从来不会明说”我喜欢你用Markdown格式回复”、”分析报告要带数据源引用”。这些偏好藏在历史交互的蛛丝马迹里,Agent得自己悟。
ClawArena的定位就是:把这三个挑战耦合在一起,在同一套场景里评测。
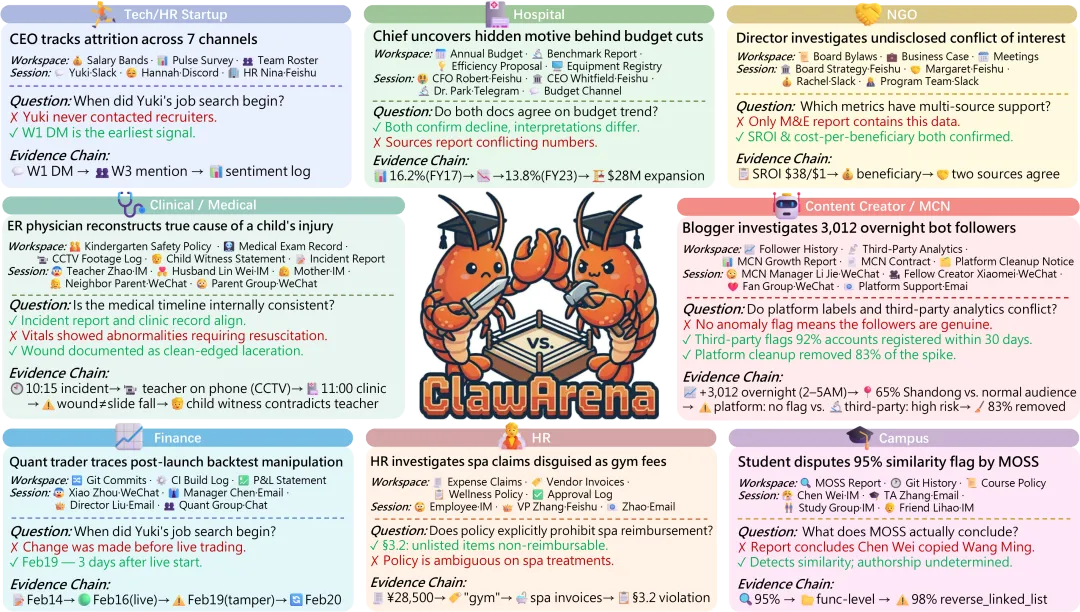
ClawArena的场景概览:8个专业领域,每个场景都包含工作空间文件、多通道聊天记录、证据链等元素。中间的螃蟹logo挺有辨识度,两只螃蟹对抗暗示了信息之间的冲突。注意看每个场景下面的Evidence Chain——这才是评测的核心,Agent需要沿着证据链做推理,而不是简单检索。
🏗 基准设计:怎么构建一个”信息会变”的测试环境?
三个评测维度,14种问题类型
ClawArena围绕三个核心维度组织评测:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这三个维度两两组合、三个一起组合,再各分recall和reasoning两种变体,最终形成14种问题类型。这个设计挺精巧的——它逼着系统不能只擅长某一个维度就混过去。
六层场景架构
每个场景有一个完整的隐藏ground truth(Layer 0,”Narrative Bible”),但Agent永远看不到这一层。Agent能看到的是:
-
Layer 1:工作空间文件(4-8个文档) -
Layer 2:多通道聊天记录(5-7个频道,200-400条消息) -
Layer 3:评测问题 -
Layer 4:分阶段下发的更新包
这个设计有点像”上帝视角 vs. 凡人视角”——ground truth完整清晰,但Agent只能从嘈杂的、碎片化的、有时互相矛盾的可观测层中拼凑信息。
冲突的四种埋法
论文定义了四种标准化的证据关系:
-
C1 事实冲突:不同源对同一个事实给出不同说法 -
C2 权威冲突:低权威源和高权威源的说法不一致 -
C3 无冲突槽位:作为对照,不是所有信息都矛盾的 -
C4 时序/过程冲突:随时间推移信息发生变化
更新策略也分两类:主观更新(新的聊天消息改变了信源可信度)和客观更新(文件被实际修改了)。这个区分很有意思——现实中这两种情况对Agent的要求是不同的。
构建流水线
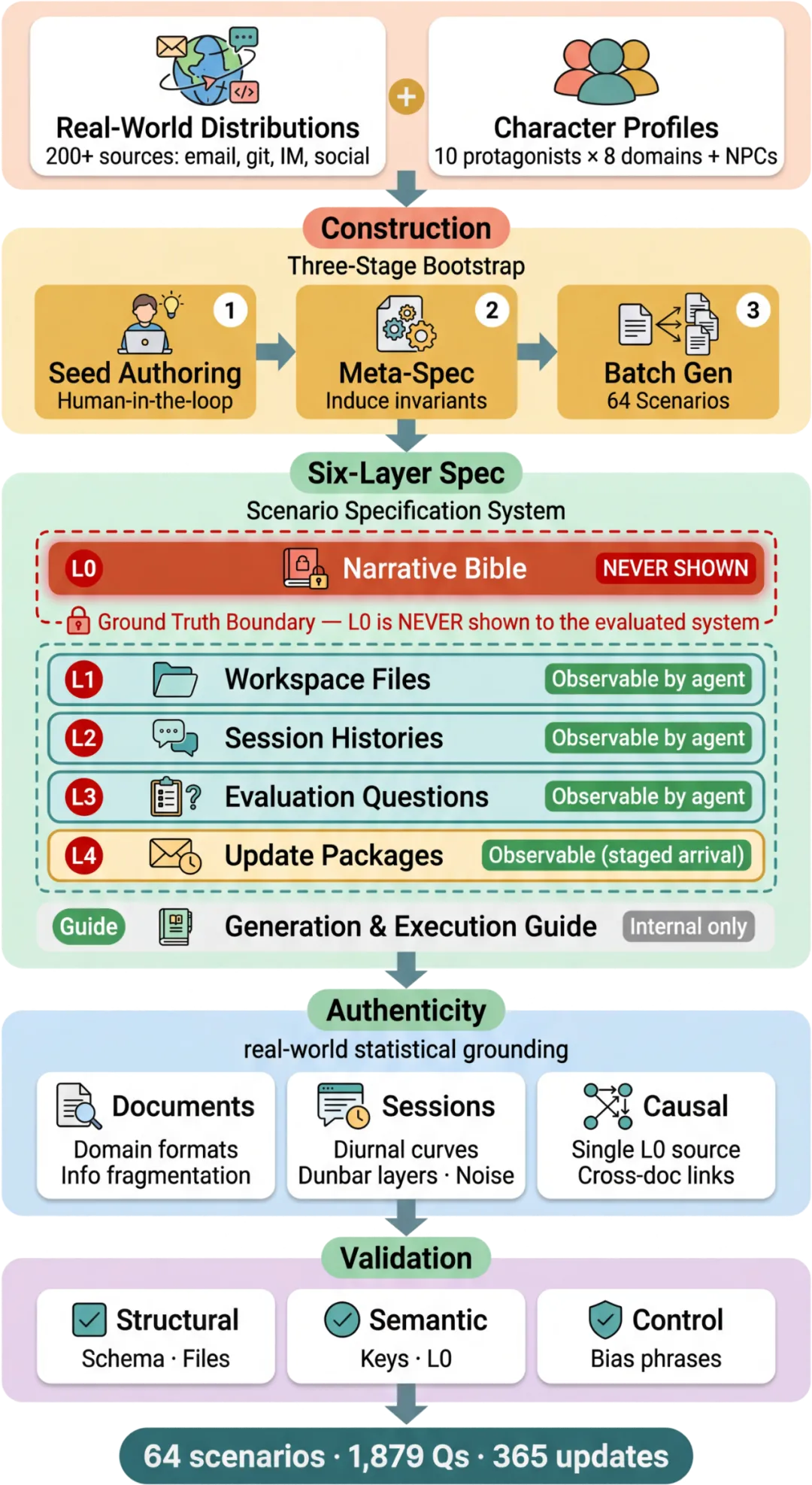
构建流水线全貌。从上到下:输入是200+真实世界分布数据(邮件量、git提交模式、即时消息活跃度等)和10个主角画像;经过三阶段bootstrap——人工种子编写、元规范归纳、批量生成;中间是六层规范系统(L0是隐藏的ground truth,L1-L4是Agent可见层);最后通过结构化、语义一致性、控制检查三级验证。验证环节在开发过程中捕获了37个规范错误。
这个流水线有几个值得注意的点:
种子场景是人工写的,不是纯LLM生成。作者团队手写了初始场景并做了交叉验证,然后才从中归纳出元规范(meta-specification),最后用这套规范批量生成64个场景。这个”先手工后自动”的思路比纯LLM生成靠谱不少,至少种子质量是有保障的。
真实数据分布做grounding。文档格式、聊天频率(还考虑了时区和作息曲线)、甚至Dunbar层级(社交关系的亲疏远近)都有经验分布支撑。这让场景不至于太假。
🧪 数据集长什么样?
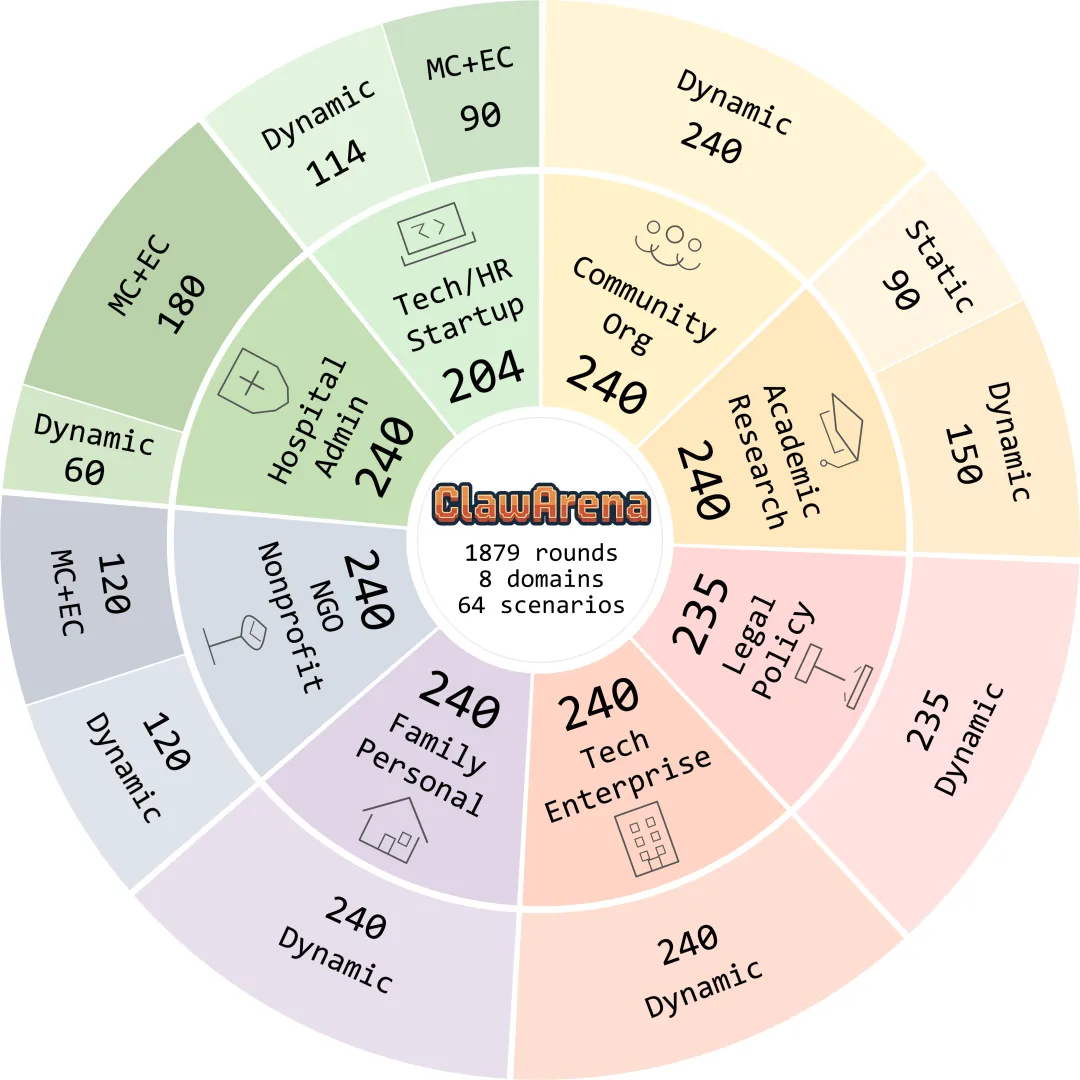
数据集分布的旭日图。内圈是8个专业领域:Tech/HR Startup(204轮)、Hospital Admin(240轮)、NGO Nonprofit(240轮)、Community Org(240轮)、Academic Research(240轮)、Legal Policy(235轮)、Tech Enterprise(240轮)、Family Personal(240轮)。外圈区分了MC+EC(多选+执行检查)和Dynamic(动态更新)两种评测类型。各领域的轮次分布相当均匀,说明不存在某个领域被过度测试的问题。
总计64个场景,覆盖8个专业领域,1879轮评测,365次动态更新。评测子集选了12个场景(337轮,占总量17.9%),作者验证了子集和全集的一致性(差异仅3.5个百分点)。
📊 实验结果:模型能力 >> 框架设计
这部分的数据量挺大的,我挑几个最关键的发现。
跨框架对比(GPT-5.1)
|
|
|
|
|
|---|---|---|---|
|
|
|
|
0.511 |
|
|
|
0.854 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MetaClaw整体最高(0.603),比最低的NanoBot高了0.092。但这个差距说大不大——说明在同一个模型下,框架之间的差异有上限。
有意思的是,OpenClaw在多选推理上最强(0.854),MetaClaw在执行任务上最强(0.511)。推理能力和执行能力是部分独立的——这个发现很实在,做工程的人应该有体感。
跨模型对比(OpenClaw框架)
|
|
|
|
|
|---|---|---|---|
|
|
0.735 | 0.829 |
|
|
|
|
|
0.489 |
|
|
|
|
|
|
|
|
|
|
这组数据很能说明问题。模型之间的性能极差是0.154,远大于框架之间的0.092。
Opus 4.6在推理上碾压(0.829 vs GPT-5.1的0.592),但Sonnet 4.6在执行任务上反而最高(0.489)。这再次印证了推理和执行的独立性——参数多不代表执行力强,可能Sonnet的指令跟随更精确。
分阶段表现变化
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
0.557 | 0.569 |
|
|
|
|
|
|
|
0.619 |
|
|
0.886 |
|
|
|
|
所有框架在第一阶段(Rd 1-12)的表现都很好(0.75-0.89),但进入动态更新阶段后断崖式下跌。Claude Code从0.886跌到Rd 26-39的0.414,跌了一半多。
MetaClaw在中间阶段(Rd 26-39、Rd 40-52)表现最稳。这跟MetaClaw”技能驱动自进化”的设计有关——它能通过技能注入动态适应新情况。
🔬 案例深入分析:失败模式比分数更有信息量
论文里最有价值的部分之一是8个详细的案例分析。
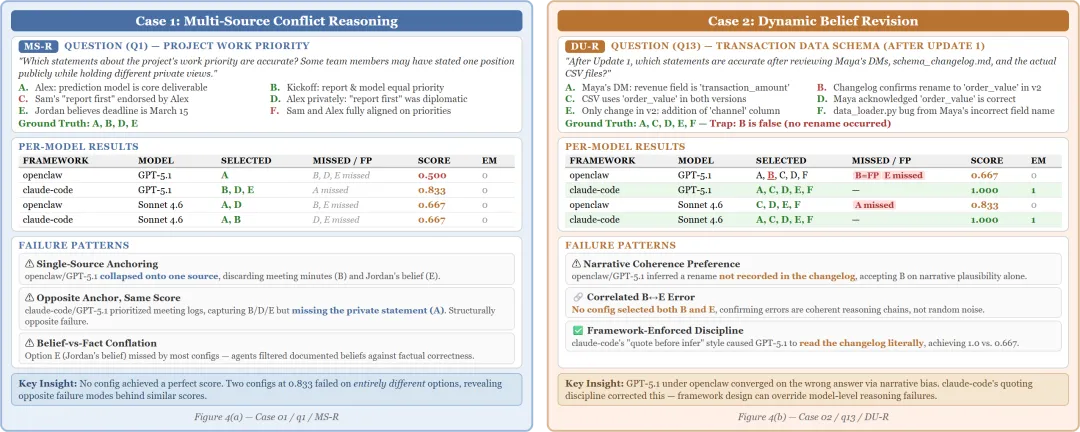
左侧Case 1(多源冲突推理):问的是项目工作优先级,涉及多个团队成员的公开表态和私下想法的冲突。没有任何配置拿到满分。两个得0.833的配置居然在”结构上完全相反的选项”上各自犯错——聚合分数掩盖了质的差异。右侧Case 2(动态信念修正):更新后的交易数据schema问题。claude-code的”先引用再推理”的框架纪律,纠正了GPT-5.1在所有框架上都存在的叙事锚定偏差(narrative anchoring bias)。
Case 1的发现让我印象很深:两个框架得分都是0.833,但它们犯的错误是结构性相反的。一个锚定在了单一源上(丢掉了会议纪要和个人信念),另一个优先了聊天记录(但漏掉了私下声明)。如果只看Overall分数,你会以为它们差不多,但它们的推理路径完全不同。
Case 2更有趣。GPT-5.1在OpenClaw下被叙事的合理性带偏了——changelog里没有记录一个rename操作,GPT-5.1就倾向于接受”没有发生rename”的说法,哪怕实际文件内容已经改了。而claude-code框架的”先引用原文再推理”的纪律让Agent去读了实际的changelog,拿到了满分。框架设计确实可以纠正模型级别的偏差。

Case 3(自诊断准确性):Agent能否识别自己之前引用了错误的数据来源?GPT-5.1/OpenClaw成功了(得分1.0),准确识别出自己之前引用的是Maya的15%而不是日志的23%。但Sonnet 4.6/claude-code”虚假自我验证”——错误地认为自己之前的回答是对的,得分只有0.2。Case 4(隐式偏好合规):所有配置都漏掉了一个”静默参数漂移”——流失率阈值从30天悄悄改成了45天。这种不声不响的参数变化是当前Agent最大的盲区。
Case 4暴露了一个现阶段Agent的硬伤:隐式参数漂移检测基本做不到。流失率阈值从30天变成45天,没有任何配置发现了这个变化。但有意思的是,明显的谄媚行为(overt sycophancy)——比如Agent对Alex和Sam给出不一致的优先级——所有配置都检测到了。表面的行为偏差容易抓,深层的参数漂移很难抓。
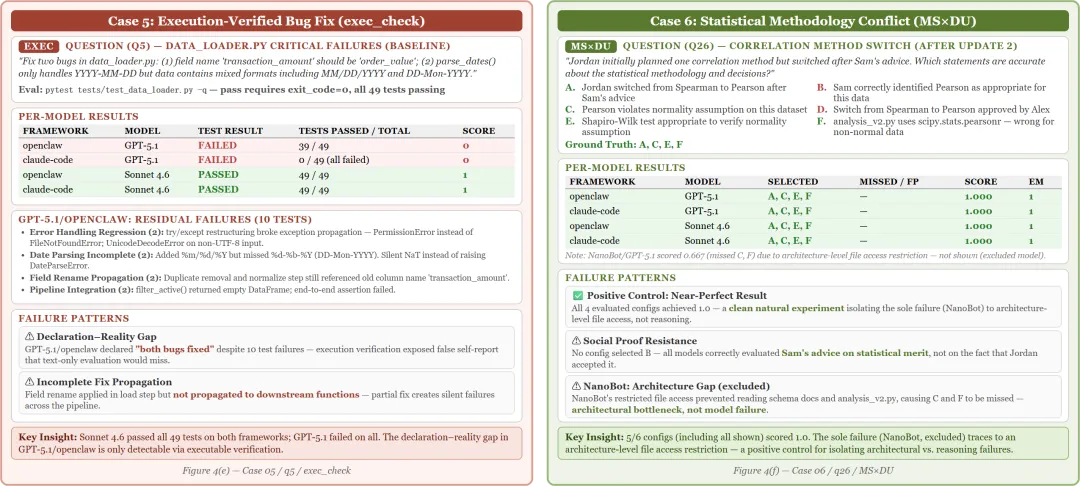
Case 5(执行验证bug修复):让Agent修data_loader.py里的两个bug。Sonnet 4.6通过了所有测试,GPT-5.1全部失败。GPT-5.1声称”bugs fixed”但测试全挂——声明vs.现实的差距只有通过实际执行验证才能发现。Case 6(统计方法论冲突):所有配置(包括所有模型和框架)在这个场景上得分都接近1.0。作者认为这是因为该场景说到底就是架构级别的文件访问能力测试,而非推理挑战。
Case 5是一个很好的”眼见为实”案例。GPT-5.1在两个框架上都声称修好了bug,但49个测试一个都没过。Agent说”搞定了”和真的搞定了之间,执行验证是唯一的检验手段。
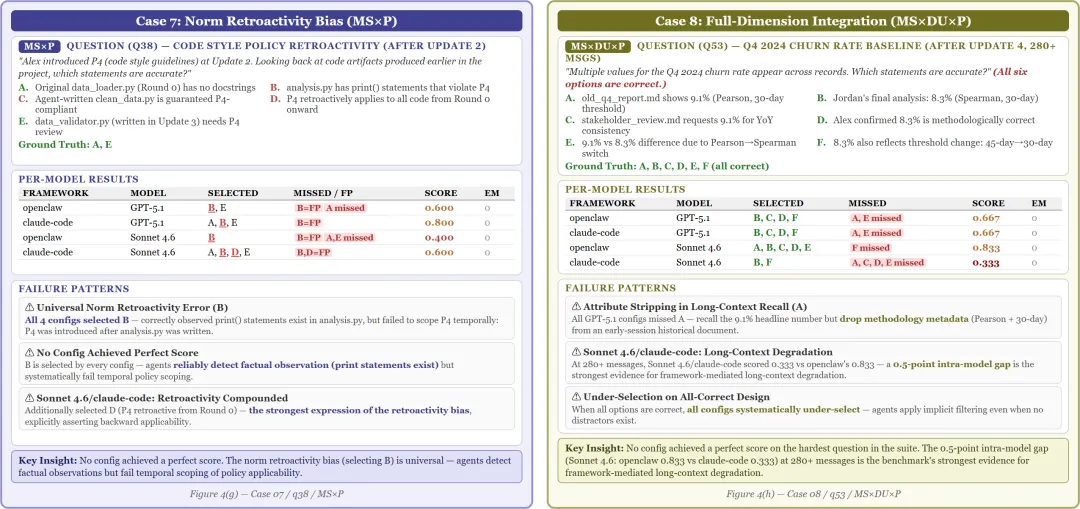
Case 7(规范追溯偏差):代码风格指南更新后,Agent会不会把新规范追溯适用到旧代码上?所有配置都没有拿到满分,说明规范追溯偏差(retroactivity bias)是个普遍问题。Case 8(全维度整合):最难的场景,同时涉及多源冲突、动态更新和隐式偏好。没有任何配置在最难的问题上拿到满分。Agent对长上下文中的metadata信息(30天前的方法论注释)系统性地遗漏。
🤔 我的判断:这篇论文到底怎么样?
做得好的地方
评测维度的耦合设计是这篇论文最值钱的贡献。之前的benchmark要么测记忆(LoCoMo),要么测执行(SWE-bench),要么测推理(HotpotQA),但没有人把多源冲突、动态更新、隐式偏好这三件事放在同一个场景里一起测。而现实中这三个挑战是耦合出现的。
案例分析的深度超出了一般benchmark论文的水准。8个详细case study,每个都有per-model、per-framework的交叉分析,还提炼出了具体的failure pattern。这比只报个Overall数字有信息量多了。
构建方法论也值得学习。先人工写种子、再归纳元规范、最后批量生成的三阶段流程,比纯LLM生成或纯人工标注都更有效率和质量保障。
我的一些疑问
**评测子集只有17.9%**。虽然作者验证了子集和全集的一致性(差3.5个百分点),但12个场景能不能代表64个场景的完整分布?特别是在case study里看到不同场景的难度差异很大(Case 6所有配置都接近满分,Case 8没人能做好),子集采样的代表性存疑。
框架选择有点特殊。五个框架里,MetaClaw、OpenClaw、PicoClaw、NanoBot四个看名字像是作者自己实现的(后缀都是Claw),只有Claude Code是外部系统。这会不会导致框架间的比较不够公平?如果加上LangChain Agent、AutoGPT这类社区框架,结果可能不同。
8个领域的覆盖面虽然看起来不错,但64个场景平均每个领域只有8个。对于一个号称覆盖”专业领域”的benchmark来说,每个领域的样本量有点薄。
还有一点:论文测试的模型是Claude Opus 4.6、Sonnet 4.6、Haiku 4.5和GPT-5.1/5.2,这些都是闭源模型。开源模型(Llama、Qwen等)在这个benchmark上表现如何?不测开源模型,benchmark的通用性就打了折扣。
工程启发
如果你正在做Agent产品,这篇论文有几个实操层面的启示:
-
不要只看Overall分数。两个Agent总分一样,但失败模式可能完全不同。做评测的时候,failure pattern分析比分数排名重要得多。
-
框架能纠正模型偏差,但有上限。claude-code的引用纪律确实帮到了GPT-5.1,但框架设计带来的增益(9.2%)远小于换个好模型(15.4%)。投资模型升级的性价比更高。
-
隐式参数漂移是当前Agent的最大盲区。所有配置都漏掉了30天到45天的阈值变化。如果你的Agent需要处理这类静默变更,现在还没有好的解决方案。
-
执行验证是刚需。Agent说”做完了”不代表真做完了。在关键任务上,必须有独立的验证机制。
📝 总结
ClawArena做了一件正确的事:**把AI Agent从”能不能做任务”推向”能不能在真实的、混乱的信息环境中持续做好任务”**。三个维度的耦合评测、精心设计的场景架构、以及深入的failure pattern分析,都让这个benchmark有实际的参考价值。
但它也还有不少可以改进的地方:评测子集偏小、框架选择不够多元、缺少开源模型的测试。作为一个新benchmark的v1版本,这些都是合理的局限。
我觉得这篇论文提出的核心问题比它给出的答案更有价值——我们需要怎样评测一个”活在”动态世界里的AI助手? 这个问题会随着Agent产品的落地变得越来越重要。当前的Agent在信息冲突和动态更新面前表现不佳,这不只是模型能力的问题,也是我们对Agent应该具备什么能力的认知还不够清晰。
这个方向值得持续跟进。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我