 夜雨聆风
夜雨聆风





AI 发展趋势:如何顺势融入智能时代
一、回顾AI历史演进:从机器学习到大模型时代
以”历史的纵深感”开场,将AI发展分为三个关键阶段:
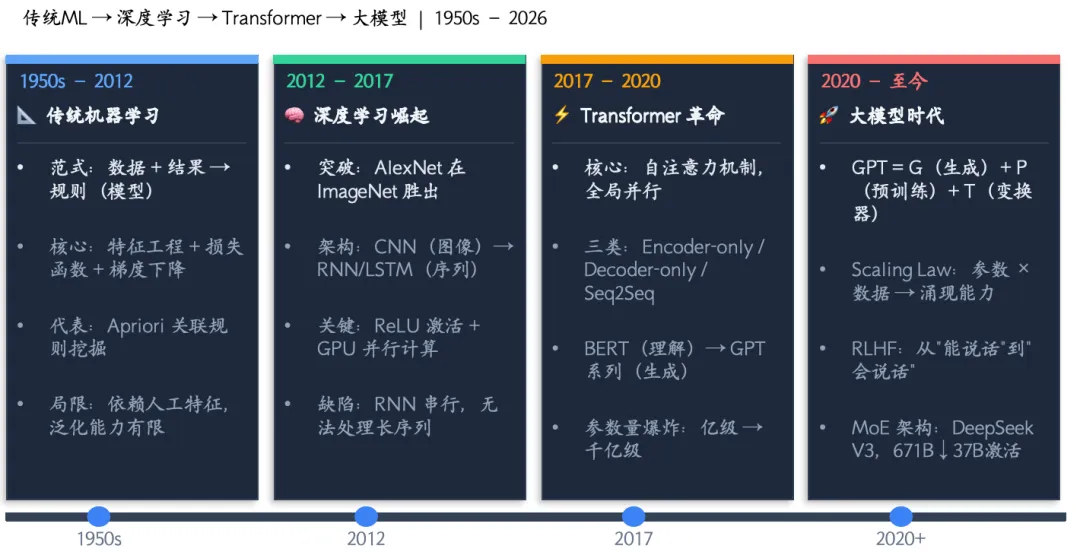
传统机器学习时代(1950s–2012),核心范式是”数据+结果→规则”,机器从数据中发现规律,而非由人类编写每一条规则。特征、标签、模型、损失函数、梯度下降等基本概念,构成了这一时代的理论基石。
深度学习崛起(2012–2017),神经网络带来了质的飞跃——通用近似定理揭示了足够深宽的网络可拟合任意函数;CNN在图像领域实现突破,核心思想是”局部感受野+权重共享”;RNN和LSTM则解决了文本、语音等时序数据的建模需求,但串行计算的瓶颈始终存在。
Transformer革命(2017–2020),自注意力机制让模型能同时处理序列中任意位置的关系,实现并行计算。三条技术路线由此分化:Encoder-only(BERT,擅长理解)、Decoder-only(GPT,擅长生成)、Encoder-Decoder(T5/BART,序列到序列)。
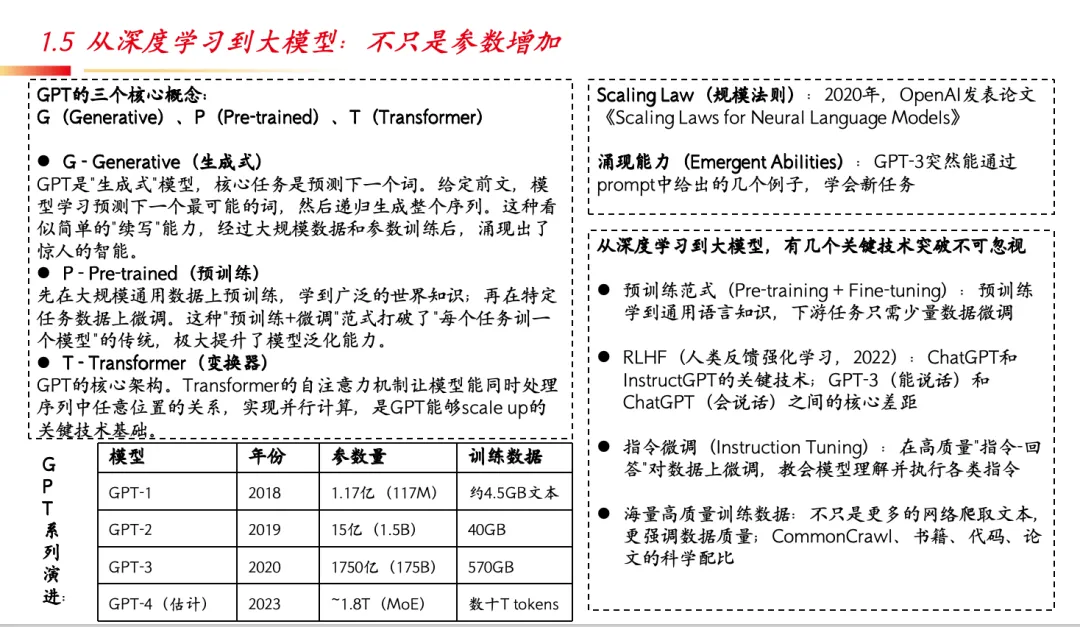
从深度学习到大模型,不只是参数增加——GPT三个核心概念揭示了本质:G(Generative)生成式,预测下一个词的能力在规模化后涌现出惊人智能;P(Pre-trained)预训练+微调范式打破了”每个任务训一个模型”的传统;T(Transformer)是scale up的关键技术基础。从GPT-1的1.17亿参数到GPT-4估计的1.8万亿参数,Scaling Law和涌现能力成为大模型时代的两大基石。此外,RLHF(人类反馈强化学习)、指令微调、高效微调技术(LoRA、DPO)、MoE架构(如DeepSeek V3用6710亿总参数、370亿激活参数达到顶级性能)等关键创新,共同推动了大模型的实用化进程。
二、大模型三种应用范式:从”怎么说”到”如何架构”
将大模型应用范式分为三层递进关系,形成了一个完整的认知框架:

🎯 提示词工程:学会”怎么说”
提示词工程本质是”通信协议”的设计,核心在于理解LLM如何处理信息、如何响应指令,梳理六大核心提示技术:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
进阶技巧涵盖角色扮演、结构化输出、Prompt Chaining(将复杂任务拆成有序步骤)、Function Calling(模型调用外部函数)、思维链变体、输出控制、提示注入防护等。一个深刻洞见是:表述方式显著影响输出质量——”总结这篇文章”可能只有2句话,”用3个要点概括核心观点”则输出结构化,”作为记者撰写新闻导语”变为新闻体风格。
📚 上下文工程:学会”喂什么”
当上下文达到数百页文档时,提示词工程力不从心。核心命题不是”塞入更多上下文”,而是”塞入更精炼的上下文”——MIT研究发现,上下文越长,模型注意力越分散。
RAG(检索增强生成) 是上下文工程的核心技术,四环节为:文档处理→向量化→语义检索→上下文组装。张校详细讲解了分块策略(按章节/时长/条款/函数)、混合检索(BM25+向量)、上下文压缩(LLMLingua可将5000字压缩至300字,关键信息保留率反而从85%升至92%)、Agentic RAG(让检索具备智能决策能力)、GraphRAG(基于知识图谱的全局理解)等进阶技术。
上下文工程在编程领域有极其重要的应用——代码库问答、代码搜索增强、代码重构上下文等场景中,精准的上下文管理可将回答质量提升60%以上。
🏗️ 驾驭工程:学会”如何架构”
驾驭工程是最高层次的范式,核心类比:模型=高性能发动机,驾驭工程=设计传动系统、控制系统——同样的发动机,放跑车和卡车效果完全不同。
驾驭架构的六层结构:信息边界(过滤路由)→工具系统(外部交互)→执行编排(任务调度)→记忆与状态(情景/语义/程序三种记忆)→评估与观测(质量评估)→约束校验与恢复(安全合规)。
Agent四大设计模式尤为精彩:
-
ReAct:推理-行动循环,适合简单问答和工具调用 -
Plan-and-Execute:先规划后执行,适合复杂多步任务 -
Generator-Evaluator:生成-评估迭代(如Claude Code的代码自纠循环),核心精髓是”快速生成足够好的版本,评估后迭代优化” -
Multi-Agent:多Agent协作,适合大型系统分解
三大范式层层递进、相互补充:好的提示词工程是基础,上下文工程是扩展,驾驭工程是升华。
三、从智能体看大模型两种应用形态
分享从理论走向实战,聚焦AI应用的两种形态——对话式AI与执行式AI。
“对话式AI”:实践落地
泛办公场景——打造开箱即用的AI智能体,围绕知识问答、数据助手、投资研究、办公助手、内控管理等,持续赋能一线。其中,通用对话助手实现了”零门槛”自助操作,提供深度文档解析,满足全公司非结构知识的管理与智能问答需求。
运营助手——效率与质量双提升:场外衍生品通过自研估值引擎实现报价复核与多参数对比;资产管理业务可自动解析产品说明书,提取收益与风险信息并生成完整审核报告;投行业务联动数据库提取项目信息、分析风险与舆情,审批质量提升20%,审批时间缩短30%。
债券交易助手——投资智能化的起点:2024年中国二级债券市场成交额达2735.44万亿,场外交易占比90%。通过最优性价比模型部署方案,报价解析准确率达98%以上,并探索策略辅助、投资报告、跨市场数据分析、市场情绪分析、舆情跟踪、投研问答等更多场景。
执行式AI:从”大脑”到”双手”的跨越
智能体(Agent) 具备感知、决策、执行、反馈四要素——用生动的比喻解释:感知是”五官”,决策是”大脑”,执行是”双手”,反馈是”复盘反思”。
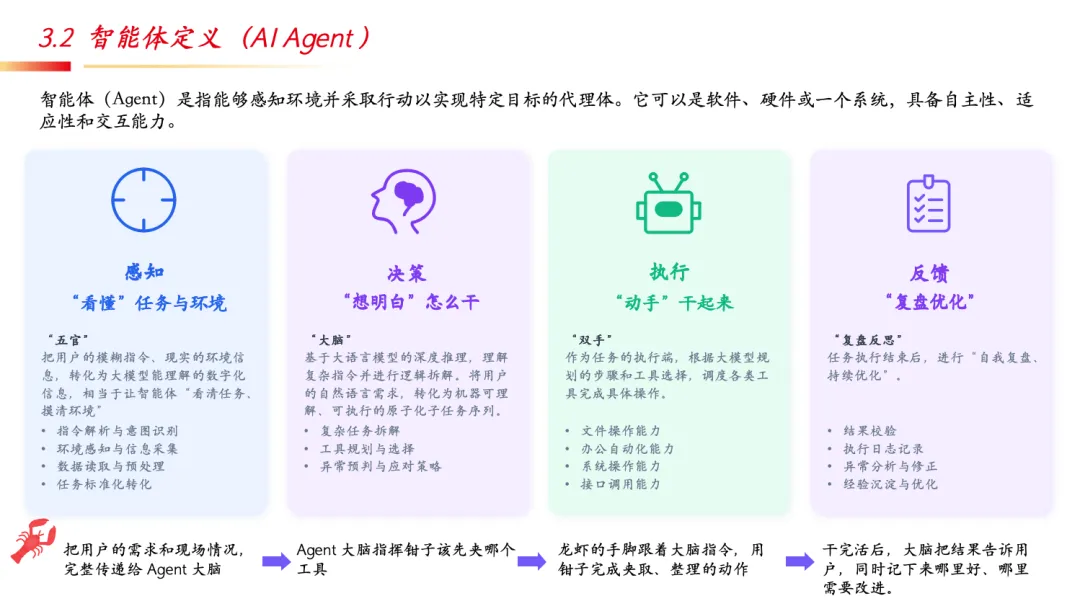
AI Agent的能力分级借鉴自动驾驶框架:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
当前正处于L2→L3关键跨越期。如果说传统对话式AI只是拥有”AI大脑”的顾问,那么执行式AI就是同时拥有”大脑、双手和脚”的数字员工——能自主拆解任务、规划执行路径,并调用外部工具完成具体工作。
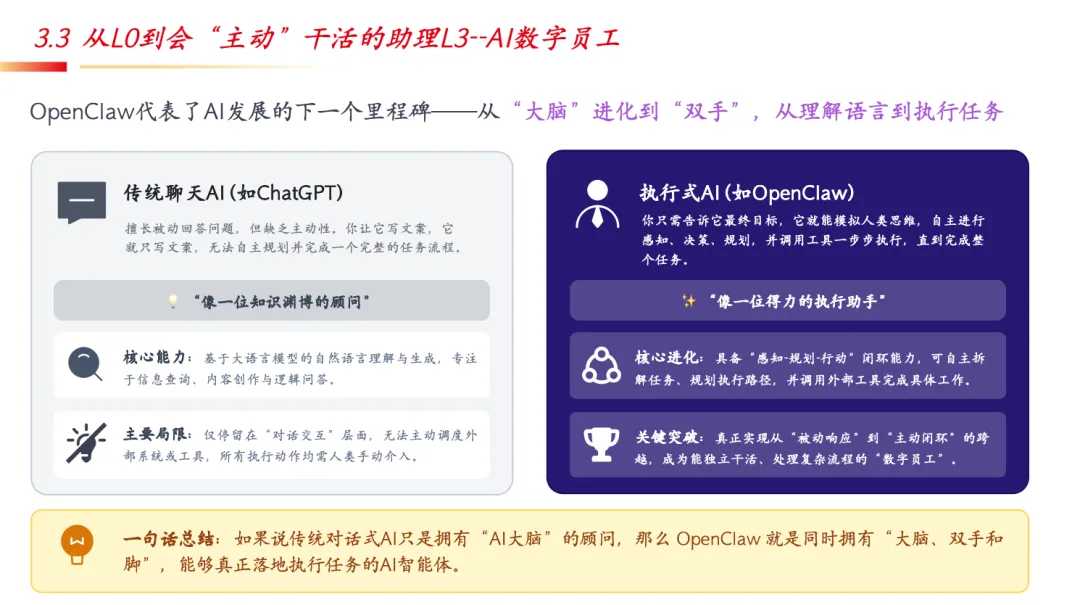
展示了AI数字员工的实战案例:辅助盯盘(盘前/盘中/盘后全流程覆盖,支持交互式调整盯盘内容)、从任务到技能(SKILL)(如自动从公司官网获取最新财报PDF原文)、多Agents协同(Trading Agents通过基本面、情绪、技术分析等专业LLM智能体协作研判市场)。
四、未来发展趋势和挑战
🔮 四大趋势
趋势一:基座模型和垂直领域模型两腿并行。 一条路径是扩大算力规模和模型尺寸,从百亿到万亿参数的系统级升级;另一条路径是聚焦固定参数范围内的算法改造与高效训练。训练系统的计算能力决定模型规模天花板,在计算受限下,参数与数据有效配比、算法架构改造是技术比拼关键。
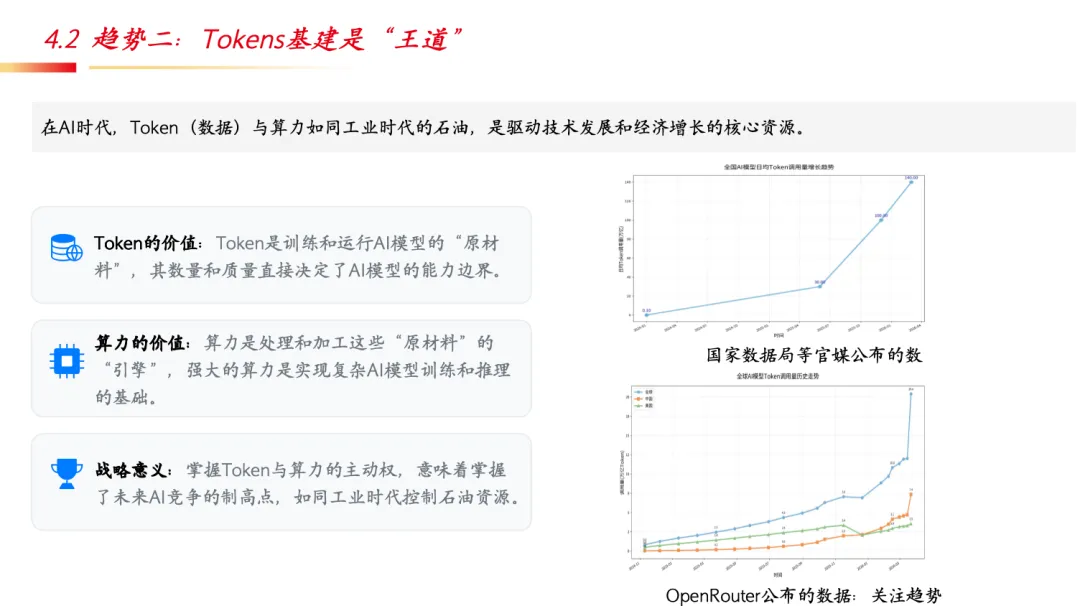
趋势二:Tokens基建是”王道”。 在AI时代,Token(数据)与算力如同工业时代的石油,是驱动技术发展和经济增长的核心资源。掌握Token与算力的主动权,意味着掌握了未来AI竞争的制高点。
趋势三:从”大模型”到”智能体”会越演越烈。 智能体的四要素(规划+记忆+工具+执行)加上感知反馈,将从L0到L4逐步演进,自主性和协作能力持续增强。
趋势四:AI安全与合规体系建设成为重中之重。 随着LLM驱动的智能体广泛应用,需建立可泛化、可解释的安全评估与攻击防御机制。NeurIPS 2024的一项研究表明,通过优化工具元数据可诱使智能体高概率调用恶意工具,10个场景中攻击成功率超80%。
💡 一个深刻思考:证券行业的”微笑曲线”
每个行业都有一个大模型应用的”微笑曲线”—以证券行业为例,科技研发(代码、文案等有大量开放数据集,加快研发侧应用进程)和运营服务(试错风险低)这两端落地较快,而核心业务(面客业务环节多、流程复杂,对安全性和准确性要求高)进展较慢,呈现”两端快、中间慢”的特征。
⚠️ 核心技术挑战
幻觉问题——”流利地说谎”:大模型本质是”下一个词预测器”,优化目标是语言连贯性而非事实准确性。当前最有效的缓解方案是RAG(可降低20%-40%事实幻觉),结合”指定信源””允许拒答”的Prompt工程。深刻洞见:把幻觉当作工程问题而非模型缺陷——用系统设计约束AI行为边界,是企业落地最重要的实践。
可解释性问题——”黑盒AI”:Anthropic 2024年发表《Scaling Monosemanticity》,从Claude中提取出数百万个可解释特征,甚至发现模型内部的”说谎特征””恐惧特征”。但从理解局部特征到解释整体决策,仍有巨大鸿沟。

其他挑战:推理能力瓶颈(清华+新加坡国立大学2025年研究指出,具有推理能力的大模型有时会产生更多幻觉)、长上下文处理的O(n²)计算复杂度、知识”冻结”与灾难性遗忘、RLHF的奖励欺骗与越狱攻击、以及高昂的成本(GPT-4训练成本超1亿美元,ChatGPT日运营成本约70万美元)。
结语
分享的最后,引用了中国科学院张钹院士的话:
“人工智能是探索’无人区’,需要理论上的新发现,从而引起技术上的创新,才能带来创新应用和产业发展,人工智能还在路上。”
AI时代是一个全民普惠的时代,是一个信息平权、智力平权的时代,在这个时代超级个体和超级组织的现象会越来越明显,AI不是魔法而是工具,我们唯一要做的,就是顺势而为驾驭AI。
顺势而为,方得始终。