AI终于把中文学会了!OpenAI Images 2.0深夜亮底牌,8张连图、角色一致,设计师的“Vibe Design”时刻来了
——单次直出8张角色一致连图、中文渲染从“鬼画符”到“稳稳地接住你”、像素级精度让海报一版过
4月22日凌晨,一场仅有20多分钟的线上直播,让全球设计师和漫画师的睡眠集体推迟了。
Sam Altman亲自坐镇,发布了一个他口中“从GPT-3一步跳到GPT-5”的飞跃式产品——ChatGPT Images 2.0。没有漫长的铺垫,没有复杂的参数炫技,OpenAI只做了一件事:让AI生图从“抽卡式许愿”变成了“思考式交付”。
消息一出,X平台、设计社区、科技媒体几乎同步炸锅。在LM Arena文生图竞技场最新榜单中,Images 2.0一骑绝尘,断层领先第二名Google Nano Banana 2整整242分,在全部7个文生图类别中全部位列第一。更令人震惊的是,OpenAI选择将Images 2.0向所有ChatGPT和Codex订阅用户免费开放,这意味着AI图像生成正式从“付费尝鲜”进入“全民标配”时代。
Altman本人也亲自上阵,用Images 2.0生成了一部以“寻找更多GPU”为主题的四格漫画,展示了模型在视觉叙事与角色一致性上的质变提升。有网友感叹:“OpenAI终于再次引领图像生成领域了。”
“先思考后落笔”、“单次8张角色一致连图”、“中文渲染封神”——这三个标签,正在重新定义AI图像生成的游戏规则。
双模式架构:Instant极速出图 vs Thinking深度思考
Images 2.0并非一个单一的模型,而是包含两个差异化分支的双模式架构:
Instant模式(即时模式) :从发布当天起直接覆盖ChatGPT、Codex和API三个入口,向所有用户开放。主打一个“天下武功唯快不破”,适合制作Logo、多语言海报、文章配图等日常任务。OpenAI研究员Kenji在发布会上给它的定性极高:“这是第一个真正有用于日常生活的图像模型。”
Thinking模式(思考模式) :需要切换到ChatGPT Plus、Pro或Business账户才能激活。一旦进入这个模式,模型在生成之前会停下来自己推演一番——实时搜索网络信息、规划图像的骨架结构,甚至能在输出前进行自我核查。ChatGPT Images产品负责人Adele Li强调:
“视觉智慧的视野与使用场景正大幅扩展,我们相信这对ChatGPT发展个人助理的愿景至关重要。”
这套双模式架构的精妙之处在于:日常轻量需求走Instant,又快又省;复杂专业任务走Thinking,深度思考保证质量。OpenAI正在用“分层服务”的模式,把图像生成从“玩具”升级为“生产力工具”。
张连图+角色一致性:漫画师、分镜师的“饭碗终结者”?
Images 2.0最令创作者震撼的升级,是它首次实现了单次提示词生成最多8张连贯图像,并且在不同的场景切换中,严谨地保持角色形象、物体细节以及整体视觉风格的统一。
这不是简单的“一次出8张图”,而是8张图讲一个完整的故事——角色从第一张走到第八张,发型、衣着、面部特征、身材比例全部保持一致。OpenAI表示,这将大幅降低漫画页面、社交媒体系列配图及室内设计方案的创作门槛。
36氪在实测中给出了一个极具代表性的案例:提示词“绘制一张四格漫画,主角为同一个亚洲女性产品经理”,Images 2.0完美实现了角色一致性,评论道:
“模型不仅在画单张图,而是在维持一个‘角色对象’的稳定存在。这种能力对漫画、广告脚本、视频分镜、品牌吉祥物延展都非常关键。”
36氪进一步指出,过去几年文生图行业的主旋律一直是“审美竞赛”——谁更会出氛围图,谁更容易在社交媒体上制造惊艳瞬间。但真正卡住商业落地的,从来不是“像不像艺术”,而是“能不能交付”。角色一致性一到多张图就崩、复杂版式一上密度就失真——这些问题让很多模型长期停留在“适合演示,不适合生产”的阶段。Images 2.0这次最关键的更新,恰恰是想要去解决这些真实的问题。
更震撼的案例来自雷科技的深度实测。他们直接给Images 2.0准备了一道大题:“以上图里的形象为漫画主角,生成一部摩托车为主题的短篇漫画,篇幅至少要8页,封面和封底为彩色,其余为黑白,画风参考石森章太郎。”在耗时11分钟后,Images 2.0成功输出了一组8张图。值得注意的是,它不仅在8张图中做到了画风和细节的统一(除了时有时无的头盔),甚至连剧情都能保持上下文连贯。这种超长连续推理能力,是此前任何AI图像模型都不具备的。
如果说角色一致性是Images 2.0的“专业门槛”,那中文渲染能力的质变,则是它送给中文用户的“最大惊喜”。
过去的图像模型,英语和拉丁字母语言表现尚可,一碰到中日韩文字就开始“鬼画符”——笔画缺失、结构错乱、乱码横飞。而Images 2.0在多语言支持方面重点改进了中文、日语、韩语、印地语及孟加拉语的文本生成能力。
官方放出的中文Demo直接炸了。OpenAI研究科学家陈博远亲自出镜,生成了一整页全中文彩色漫画,讲的是他在OpenAI做ChatGPT Image 2中文文本渲染优化的故事。漫画分五排,密密麻麻的中文小字全部渲染正确——包括极小字号的精度控制。
更绝的是OpenAI的“自嘲式营销”。漫画第五排,陈博远看到奥特曼发来的祝贺图片,中央位置赫然写着那句被中文用户疯狂吐槽了大半年的“稳稳地接住你”。漫画里的陈博远当场破防,漫画式暴怒大喊“天呐!它又学会了接住!”,旁边的队友们化身小脑袋冒冷汗,弱弱地说“我们正在努力修复它!”
这波自嘲,可以给满分。但玩笑背后,是实打实的技术突破:AI终于能把中文当成“文字”来理解和渲染,而不是当成“图案”来模仿。
雷科技的极限测试更有说服力。他们让Images 2.0生成一张照片风格的图片:一幅毛笔书法作品,上书《沁园春·雪》全文——“北国风光,千里冰封,万里雪飘……”尽管文本内容极长,但ChatGPT仍在一分钟之内就输出了结果,字体字形基本没有问题。唯一的小瑕疵是书法的“质感”仍有欠缺,怎么看都像是“印刷品”。
“世界知识”暴击:AI比你自己更懂这个世界长什么样
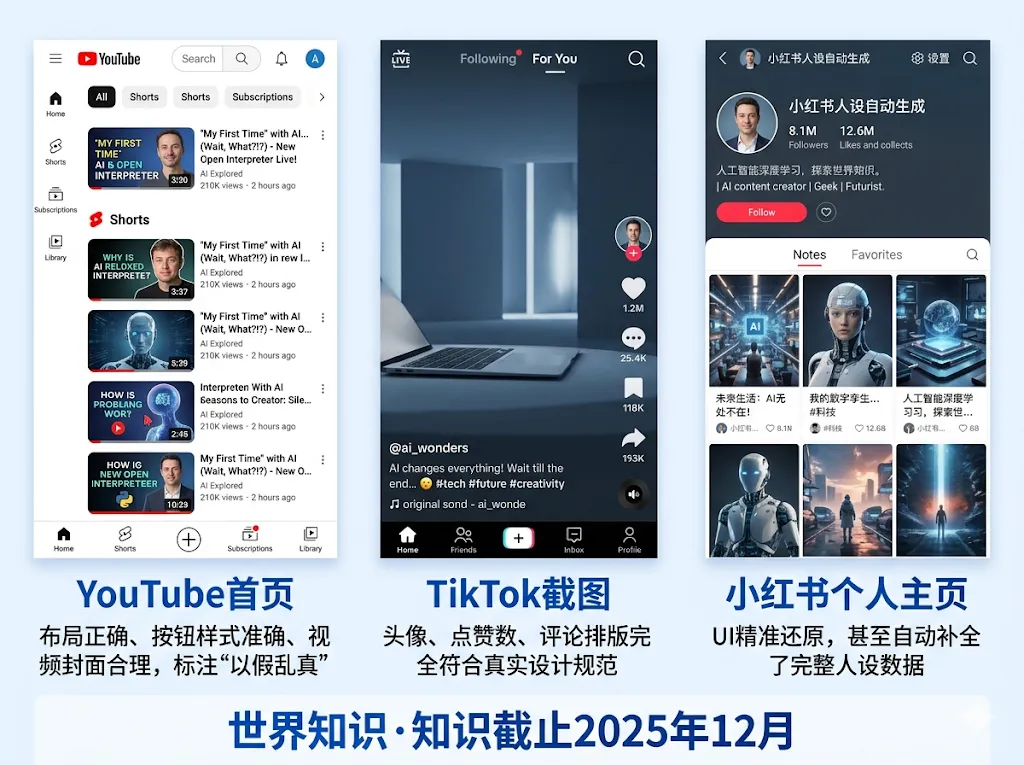
Images 2.0最令人震撼的能力,是它的“世界知识”——模型对真实世界长什么样,有着极其精准的理解。
什么意思?你让它生成一张YouTube首页的截图,它不是随便画一个红色播放按钮然后乱填一些文字。它会画出正确的布局、正确的按钮样式、正确的图标位置,甚至连各个视频的封面,都是正确的。让它生成一张TikTok的妆教视频截图,提示词极其简短,它就能生成以假乱真的界面——包括头像、点赞数、评论区的排版,全部符合真实TikTok的设计规范。
有用户让它生成一张“小红书界面个人主页截图,但是Grok的个人主页”,它不仅能精准还原小红书的UI布局,甚至还给Grok编了一套完整的人设:128.6万粉丝、302.1万获赞、AI来自xAI,目标是理解宇宙并以幽默和真相回应一切问题。这个细节量,已经不是画图的范畴了。
36氪在深度评测中一针见血地指出:过去AI生图擅长做“像海报的东西”,但不擅长做“真海报”——远看很像设计稿,一放大就发现文字内容不可信、字母残缺、数字错位、排版层级局部崩塌。Images 2.0的突破点在于:模型不只是“画出字的形状”,而是在一定程度上理解“这里必须是精确的标题、日期、地点、列表、按钮和页脚文案”。当一个模型能承载更多清晰文本,它就不再只是插画工具,而开始具备了传播物料生成能力。
TechOrange在报道中分析指出,Images 2.0的关键差异在于“不再盲目追求单张图像的华丽视觉效果,而是强调可读的文字、可交付的版型,以及更贴近真实工作需求的输出”。为支撑这一转变,新模型的知识截止时间已更新至2025年12月,确保生成解说图、教育图表与视觉摘要时能提供更准确的结果。
Images 2.0的另一个核心突破,是它首次实现了真正意义上的“像素级生成”。
在官方直播中,团队展示了一张米山图——其中一颗大米粒上,竟刻上了“GPT image 2”的字体。这种对极小字号、图标、UI元素等复杂细节的一键生成能力,是此前任何AI图像模型都不具备的。新智元的评测总结道:“像素级精度:小字号文本、图标、UI元素等复杂细节一键生成,支持3:1到1:3全尺寸输出。”
在技术规格层面,新版本将最高分辨率提升至2K级别,并提供了从3:1到1:3极宽的比例选择,能够完美适配电影剧照、像素艺术、漫画等多种细分风格。宽高比范围扩展至3:1与1:3,意味着你可以直接用Images 2.0生成超宽横幅广告或超长竖版手机海报,无需后期裁剪。
在密集文本渲染方面,36氪的实测给出了一个极具代表性的案例:让Images 2.0生成一张面向科技行业的大会主视觉海报,要求准确排版主标题、副标题、日期、地点、议题列表、嘉宾名单、页脚小字和二维码占位框——中英混排自然,字距和层级像真实设计师排版。结果令人震惊:所有文字清晰可读、无乱码、无错字,排版层级像真正的设计师出品。
设计师的“Vibe Design”时刻:从“抽卡”到“交付”
Images 2.0的发布,让青山想起了一个词——“Vibe Coding”(氛围编程),指的是开发者用自然语言描述需求、AI直接生成代码的编程范式。而现在,设计领域正在迎来属于它的“Vibe Design”时刻。
过去,我们把AI画图当成一个单向的许愿池。你丢进去一个硬币(Prompt),它吐出一张图。至于图里元素的逻辑关系、背景的合理性,全靠运气。但Images 2.0改变了这种玩法——它不再是“抽卡式”的随机生成,而是“先理解任务、再组织画面”的思考工作流。
“天下苦AI生图抽卡久矣。如果你曾试图用市面上任何一款主流AI绘画工具去做一张带有特定中文口号的海报,你一定对那种乱码的无力感体会颇深……但伴随着ChatGPT Images 2.0的发布,那个需要你绞尽脑汁去凑提示词的AI盲盒时代,有望画上句号。”
具体来说,Images 2.0在以下维度实现了从“能看”到“能用”的跨越:指令跟随精度大幅提升,能准确还原复杂构图、小号文字、图标、UI元素等细节;风格还原更准确,适合游戏原型、分镜、营销素材制作;灵活宽高比支持,可直接生成适配横幅、海报、手机屏等不同场景的尺寸;Codex集成,开发者可在同一工作区内无缝处理应用开发、简报内容与原型设计等任务。
Images 2.0的强大能力,很大程度上依赖用户上传图片——角色参考图、产品图、个人照片。但安全专家早已发出警告:你上传的每一张照片,都可能成为AI公司永久训练数据的一部分。
每月有超过6亿张图片上传至ChatGPT,其中34.8%包含敏感数据。安全专家Shashank Karincheti的警告直击要害:“当你把照片上传到任何AI平台的那一刻,你就可能交出了你的生物特征数据——面部几何信息、皮肤纹理、独一无二的识别符——这些是无法像密码一样修改的。”
更令人担忧的是,上传内容会保存在OpenAI服务器,默认用于训练,最长可保留30天甚至更久;文件元数据、EXIF能泄露位置等敏感信息。即使你删除了对话,也无法彻底清除——AI公司可能保留数据用于人工审核或模型训练。
安全专家给出的建议相当朴素:避免上传包含任何识别信息的图片,不要暴露背景中的位置线索,在上传前检查并移除敏感元数据。
Images 2.0的发布,对AI图像生成赛道的冲击是深远的。
Midjourney,那个曾经凭借极致艺术感稳坐“AI生图天花板”的明星公司,正面临前所未有的压力。36氪的分析指出,2026年随着更多大模型厂商的涌现,Midjourney在市场上的热度已显著下降。而Images 2.0在Arena榜单中断层领先Nano Banana 2多达242分、向所有订阅用户免费开放的策略,更是直接刺中了Midjourney“付费订阅+Discord封闭生态”的商业模式软肋。
更深层的冲击在于竞争维度的切换。过去,Midjourney赢在“审美”——谁的图更有艺术感、更惊艳,谁就占据用户心智。但Images 2.0把战场拉到了“能不能交付”——海报里的字能不能写对、角色在多张图里能不能保持一致、复杂版式能不能一版成型。当OpenAI用“免费+全平台+思考能力”的组合拳解决这些问题时,Midjourney的“艺术感”护城河正在被降维打击。
结语:AI学会“思考”,创作者迎来“最危险也最美好的时代”
Images 2.0的发布,不是一次简单的版本迭代。它是AI图像生成从“像素渲染”到“理解创作”的范式革命。
8张连图角色一致性,让漫画师和分镜师第一次看到了AI“接外包”的可能;中文渲染从“鬼画符”到“稳稳地接住你”,让中文创作者终于不用再忍受乱码的无力感;世界知识的精准理解,让AI从“画图的工具”进化为“懂世界的设计师”;像素级精度与密集文本渲染,让图像模型从“适合演示”跨入“可以直接商用”的门槛。
从“抽卡式许愿”到“思考式交付”,从“适合演示”到“适合生产”——Images 2.0正在把图像生成从“玩具”升级为“生产力工具”。而对于每一个靠视觉吃饭的创作者来说,这可能是最危险的时代,也可能是最美好的时代。
当AI学会了“先思考后落笔”,人类创作者该思考的下一个问题是:你的价值,究竟是“会画”,还是“知道该画什么”?
讨论话题:你体验过ChatGPT Images 2.0了吗?你觉得它的中文渲染和角色一致性,哪个能力对你的工作帮助最大?AI生图从“抽卡”到“交付”,你准备好迎接“Vibe Design”时代了吗?评论区聊聊你的看法~
 夜雨聆风
夜雨聆风