 夜雨聆风
夜雨聆风





OpenClaw作者亲自推荐的AI开源项目lossless-claw:让 AI 永远不会忘记你说过的话
👆关注趣谈AI,后台回复“源码”获取源码实战
作者简介:徐小夕,曾任职多家上市公司,多年架构经验,打造过上亿用户规模的产品,聚集于AI应用的实践落地。
最近推出了《架构师精选》专栏,会分享一线企业AI应用实践,并和大家拆解可视化搭建平台,AI产品,办公协同软件的源码实现。

最近一直在深耕 AI Agent 与大模型应用,比如 JitKnow AI 知识库、JitWord协同AI文档、Pxcharts超级表格:
JitKnow知识库 V1.5.0 发布:企业控制台 + 自定义模型上线!
从一行代码到百万表格:花两年做的pxcharts,把表格做成”AI+低代码数据库”
同时也持续在给大家分享 GitHub 上真正能落地、能解决实际问题的优质AI开源项目。
项目基本介绍:终结 AI 的 “金鱼记忆”
相信大家都有过这样的经历:和 AI 聊了几十轮,前面说过的重要信息它转眼就忘了,你不得不反复重复同样的内容。这就是大模型的上下文窗口限制问题 —— 当对话长度超过模型的 token 上限时,AI 会直接截断最早的消息。
lossless-claw 就是为了解决这个痛点而生的。它是 OpenClaw 的一款无损上下文管理插件,基于 Voltropy 的 LCM 论文实现,用DAG(有向无环图)式的分层摘要系统彻底取代了传统的滑动窗口压缩机制。
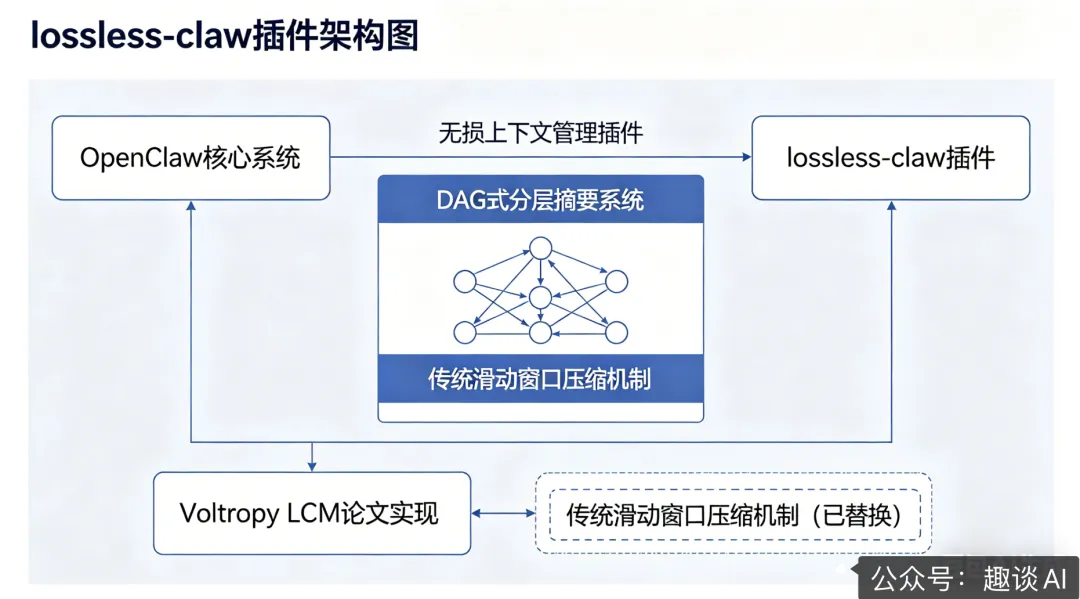
简单来说,它不会丢弃任何一条消息,而是将历史对话智能地分层摘要,形成一个可追溯的知识图谱。当 AI 需要回忆某个细节时,可以随时从摘要节点回溯到原始消息,真正实现了 “零信息丢失” 的长对话体验。
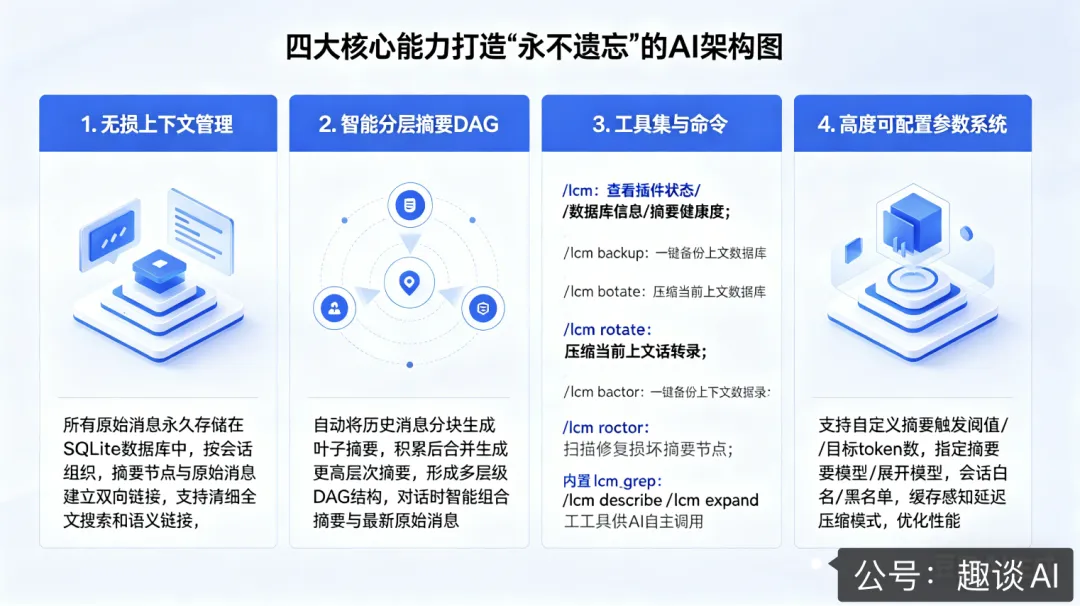
功能亮点:四大核心能力打造 “永不遗忘” 的 AI
我们最近在做 JitKnow AI知识库的时候,也遇到了AI助手如何更大限度保留用户问答的上下文记忆的问题,在研究了 lossless-claw 的上下文管理机制后,有非常大的收获。下面就来总结一下它的方案的核心亮点:
1. 真正的无损上下文管理
-
所有原始消息永久存储在 SQLite 数据库中,按会话组织 -
摘要节点与原始消息建立双向链接,可随时展开查看详情 -
支持精确的全文搜索和语义检索,快速定位历史对话
2. 智能分层摘要 DAG
-
自动将历史消息分块生成叶子摘要 -
当叶子摘要积累到一定数量时,自动合并生成更高层次的摘要 -
形成多层级的 DAG 结构,抽象程度逐层提升 -
每次对话时,智能组合不同层次的摘要 + 最新原始消息
3. 丰富的工具集与命令
/lcm
查看插件状态、数据库信息和摘要健康度 /lcm backup
一键备份整个上下文数据库 /lcm rotate
压缩当前会话转录,不改变会话身份 /lcm doctor
扫描并修复损坏的摘要节点 -
内置 lcm_grep、lcm_describe、lcm_expand等工具,供 AI 自主调用
4. 高度可配置的参数系统
-
支持自定义摘要触发阈值、目标 token 数 -
可指定专门的摘要模型和展开模型,降低成本 -
支持会话白名单 / 黑名单,排除不需要记录的会话 -
提供缓存感知的延迟压缩模式,优化性能
技术架构:DAG 驱动的上下文管理范式
AI Agent研究核心一点我觉得就是在架构设计上,它是 Agent 的灵魂,也是程序员唯一不会被AI替代的核心竞争力了,所以我会继续和大家分享一下我总结的 lossless-claw 架构设计:
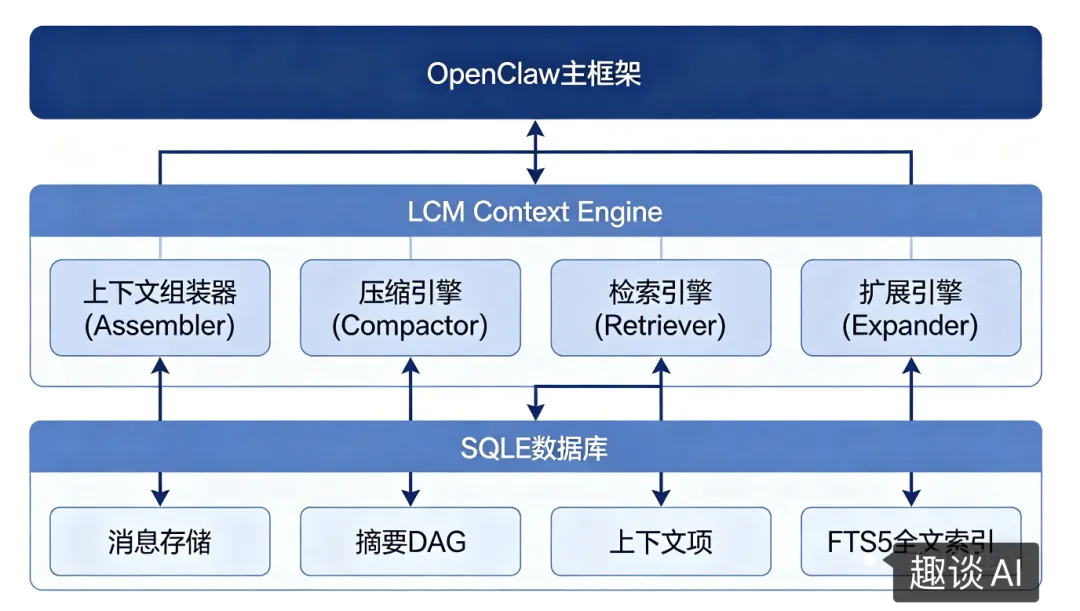
核心技术思路剖析如下:
1. DAG 式摘要存储
这是 lossless-claw 最核心的创新点。传统的滑动窗口是线性的、不可逆的,而 DAG 结构是分层的、可回溯的。
- 叶子节点
包含原始消息的分块摘要,每个叶子节点对应约 20000 个原始 token - 中间节点
由多个叶子节点或其他中间节点合并生成,抽象程度更高 - 根节点
整个会话的最高层摘要,包含最核心的信息
当需要组装上下文时,系统会从根节点开始,根据当前上下文窗口的剩余空间,智能选择展开哪些子节点,确保在 token 限制内提供最有价值的信息。
2. 缓存感知的延迟压缩
lossless-claw 采用了一种非常聪明的压缩策略:延迟压缩。
-
当上下文使用量达到阈值的 75% 时,不会立即进行压缩 -
而是将压缩任务记录为 “维护债务”,在后台异步执行 -
利用 LLM API 的缓存机制,在缓存还热的时候完成压缩 -
只有当缓存过期或上下文即将溢出时,才会应用压缩结果
这种方式极大地减少了对用户体验的影响,同时降低了 API 调用成本。
3. 可插拔的模型系统
-
摘要任务和展开任务可以使用不同的模型 -
推荐使用 openai/gpt-5.4-mini这类便宜快速的模型进行摘要 -
主会话可以继续使用更强大的模型进行推理 -
支持所有 OpenClaw 兼容的模型提供商
4. 事务性数据库设计
-
所有操作都是事务性的,确保数据一致性 -
支持数据库备份和恢复 -
内置完整性检查和修复工具 -
可选的 FTS5 全文索引,支持快速搜索
它使用到的技术栈清单我整理了一份,供大家做技术参考和调研:

应用场景
lossless-claw 我个人认为,特别适合以下场景:
- 长期运行的 AI 助手
个人数字助理、企业客服机器人 - 复杂项目开发
AI 编程助手,能够记住整个项目的上下文 - 研究与学习
AI 研究助手,能够跟踪长期的研究课题 - 客户关系管理
记录与每个客户的所有交互历史 - 会议记录与总结
自动生成会议摘要,并可随时展开查看细节
优缺点客观分析
优点
-
✅ 真正无损:所有原始消息都被保存,不会丢失任何信息 -
✅ 智能高效:DAG 结构在 token 限制内最大化信息密度 -
✅ 性能优秀:延迟压缩模式几乎不影响用户体验 -
✅ 易于集成:作为 OpenClaw 插件,一键安装即可使用 -
✅ 高度可配置:几乎所有参数都可以根据需求调整 -
✅ 开源免费:MIT 许可证,可自由商用
缺点如下,大家可以客观的选择:
-
❌ 仅支持 OpenClaw:目前不能直接用于其他 AI 框架 -
❌ 有一定存储开销:数据库会随着对话历史增长 -
❌ 摘要质量依赖模型:模型能力差会导致摘要不准确 -
❌ 首次压缩有延迟:第一次达到阈值时可能会有短暂等待
官方 Roadmap 泄密
🚨 未经官方证实,仅供吃瓜
据内部消息人士透露,lossless-claw 团队正在开发以下功能:
支持向量数据库作为后端存储,提升大规模检索性能 实现跨会话的知识共享,让不同会话之间可以互相引用 开发 Web UI 界面,方便可视化管理和编辑摘要 DAG 支持导出为 Markdown、PDF 等格式,便于分享和归档 预计这些功能将在 2026 年 Q3 陆续上线。
总结:AI 长上下文的终极解决方案
作为一个有近 10 年经验的程序员和 AI 创业者,我认为 lossless-claw 是目前解决大模型长上下文问题的最佳实践。
传统的滑动窗口压缩是一种 “暴力” 的解决方案,它简单但低效,而且会丢失重要信息。而 lossless-claw 的 DAG 式分层摘要则是一种 “智能” 的解决方案,它模拟了人类的记忆方式 —— 我们不会记住每一个细节,但我们会记住重要的事情,并且当需要时能够回忆起具体的细节。
对于任何需要长期运行的 AI 应用来说,上下文管理都是一个核心问题。lossless-claw 不仅解决了这个问题,而且提供了一个优雅、高效、可扩展的架构。
如果大家也正在使用 OpenClaw,我强烈建议你安装这个插件。它会彻底改变你与 AI 交互的体验,让你的 AI 助手真正成为一个 “永不遗忘” 的伙伴。

精选架构专栏

先暂时聊这么多,后续会持续分享AI创业开源笔记,欢迎留言交流 ~