 夜雨聆风
夜雨聆风





AI 测试智能体火了:测试工程师别只学工具,要学会设计闭环
如果你最近搜索软件测试方向的热点文章,会发现一个明显变化:
大家不再只讨论“AI 能不能生成测试用例”。
更热的话题开始变成:
-
• AI 能不能理解页面和接口契约 -
• AI 能不能自己规划测试路径 -
• AI 能不能连接浏览器、接口、数据库和 CI -
• AI 生成的测试到底怎么验证、怎么复盘、怎么治理
这背后其实是同一个趋势:
软件测试正在从“AI 辅助写点东西”,走向“AI 测试智能体闭环”。
它不是单纯多一个工具,也不是把测试工程师换成聊天机器人。
它真正改变的是测试工作的组织方式:需求、页面、接口、代码变更、测试数据、执行结果和失败证据,开始被一个可观察的 Agent 流程串起来。
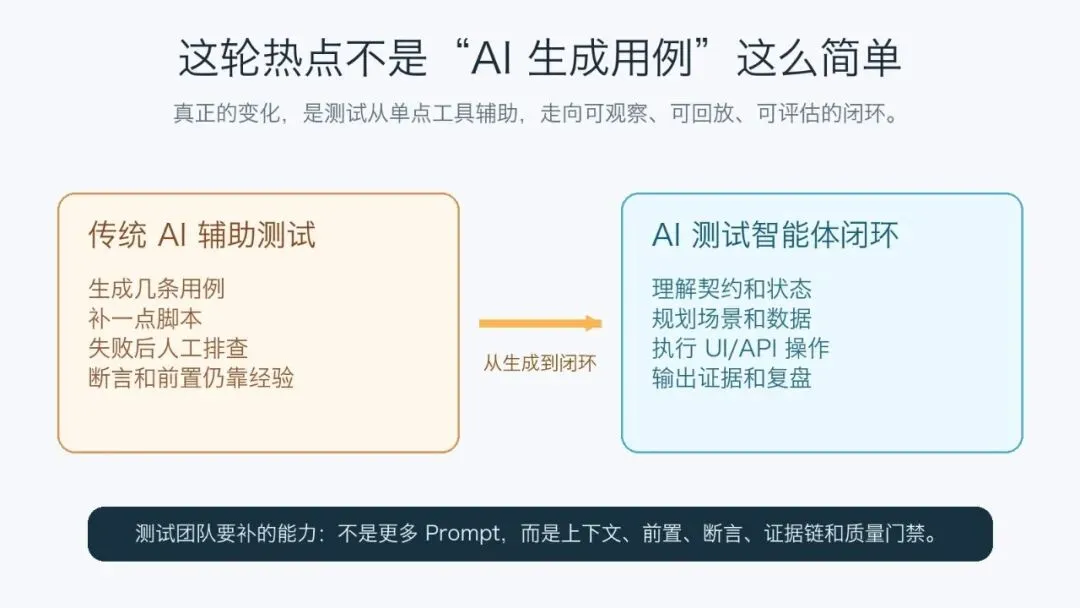
图 1:这轮热点的核心,不是多生成几条用例,而是把上下文、执行、断言和复盘串成闭环。
截至 2026 年 4 月 25 日,我看到的几个最新信号很集中:
-
• BrowserStack 在 2026 年 AI 软件测试报告里调研了 250+ 位工程和 QA 负责人,提到 61% 的组织已经在多数测试流程里使用 AI,37% 的团队把“接入现有流程”视为最大阻碍。 -
• Tricentis 在 2026 QA 趋势文章里明确把 QA 定位成 AI 交付的 accountability layer,也就是“问责和治理层”。 -
• Microsoft Learn 在 2026 年 4 月 17 日更新的 Playwright MCP 测试文档里,已经把“AI 连接真实浏览器、检查 DOM、生成 Playwright 测试”写成了可操作流程。 -
• 2026 年两篇研究也在往这个方向推:一篇研究 AI Agent 真实生成测试的质量,另一篇 ABTest 开始测试 AI 编码 Agent 的行为过程。
所以这篇文章不追单个工具热度,而是回答一个测试同学更关心的问题:
这件事和我的测试工作到底有什么关系?
一句话判断:测试团队要学的不是 Agent,而是闭环设计
先把结论放在前面。
AI 测试智能体真正值得关注的地方,不是它能自动点页面,而是它把测试活动从“人工拼流程”变成了“可约束、可观察、可回放的测试闭环”。
过去我们做自动化,经常是这样:
-
• 需求靠人读 -
• 用例靠人拆 -
• 数据靠人造 -
• 脚本靠人写 -
• 失败靠人看日志 -
• 复盘靠人补文档
AI 进来以后,很多团队第一反应是让它生成用例、生成脚本。
这当然有价值,但还不够。
因为测试真正难的地方,从来不只是“写步骤”。
更难的是:
-
• 需求和实现是否一致 -
• 状态流转有没有漏分支 -
• 前置数据能不能稳定构造 -
• 断言是不是只看了页面文案 -
• 失败时能不能区分环境问题、产品缺陷和测试脚本问题 -
• 回归结果能不能变成下一轮补测线索
这些问题,才是 AI 测试智能体真正应该接住的地方。
为什么 Playwright MCP 会成为这轮热点里的关键拼图
很多人最近关注 Playwright MCP,是因为它把 AI 和真实浏览器连接起来了。
简单说,Playwright MCP 是一个基于 Model Context Protocol 的浏览器自动化服务。AI 助手可以通过它访问真实浏览器会话,拿到结构化的页面信息,再执行点击、输入、等待、截图、网络请求检查等动作。
这件事对测试团队的意义不在于“又多了一个 MCP 服务”。
真正的意义是:
AI 不再只能靠截图猜页面,也不再只能靠文档猜选择器,而是可以观察真实页面结构,再生成更贴近实际页面的测试代码。
在复杂 UI 里,这个变化很实在。
比如:
-
• iframe 里面的控件怎么定位 -
• 列表项嵌套多层时怎么找稳定选择器 -
• 页面加载 30 秒才出现数据时怎么设计等待 -
• ARIA label、role、control name 这些信息怎么帮助定位 -
• 网络请求失败时怎么把证据带回来
这就是为什么测试工程师不能只把它当成“AI 写 Playwright 脚本”。
更准确地说,它让 Agent 开始具备一部分真实测试执行能力。
但也正因为这样,测试团队更要设计边界。
Agent 可以点页面,不代表它可以随便点。
Agent 可以生成脚本,不代表脚本可以直接进主干。
Agent 可以汇报“测试通过”,不代表我们可以相信它的口头结论。
测试智能体闭环,至少要有三层
如果团队真想试 AI 测试智能体,不建议一上来就问:
“用哪个 Agent?”
更应该先问:
“我们准备让 Agent 在测试流程里承担哪一段责任?它看到什么?能做什么?怎么证明自己没做错?”
一个比较稳的设计,至少分三层。
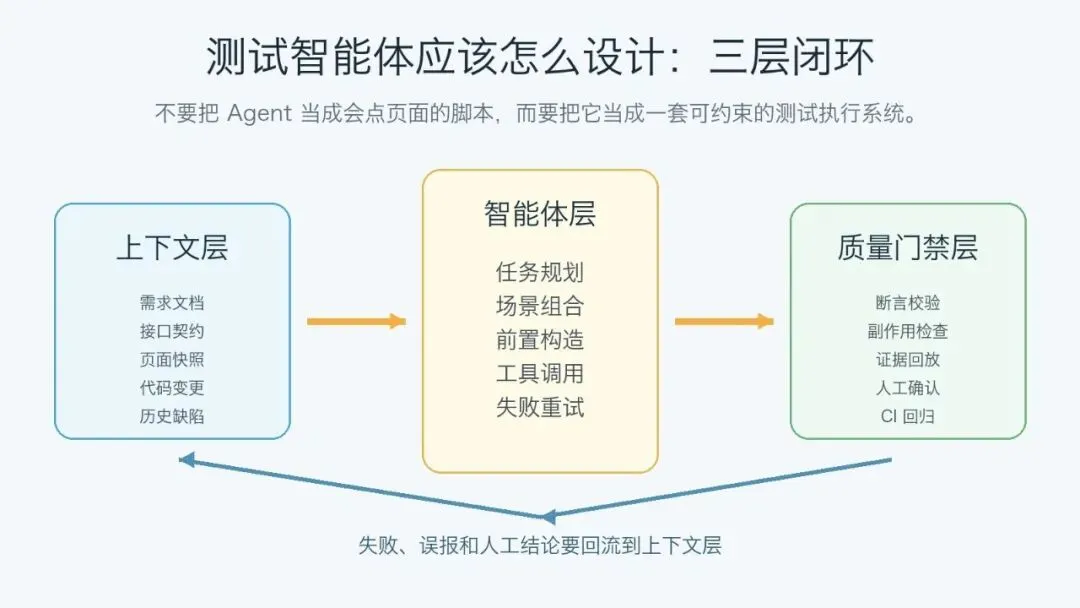
图 2:测试智能体不是单点工具,而是上下文层、智能体层、质量门禁层一起形成闭环。
1. 上下文层:先让 Agent 看懂测试对象
这一层负责告诉 Agent:
-
• 需求是什么 -
• 接口契约是什么 -
• 页面当前长什么样 -
• 这次代码改了哪里 -
• 历史上这个模块出过什么缺陷 -
• 哪些环境、数据和权限是特殊约束
这里的关键不是“塞越多资料越好”。
关键是让资料能服务具体测试动作。
比如订单退款链路里,Agent 真正需要的不是整套产品手册,而是:
-
• 订单有哪些状态 -
• 什么状态允许退款 -
• 退款失败后状态怎么回滚 -
• 库存、资金流水、消息通知有哪些副作用 -
• 这个模块历史上最常见的问题是什么
2. 智能体层:让 Agent 先规划,再执行
这一层负责把上下文变成测试动作。
比较合理的流程不是让 Agent 直接开跑,而是要求它先输出:
-
• 测试目标 -
• 前置条件 -
• 覆盖路径 -
• 需要调用的工具 -
• 关键断言 -
• 停止条件
然后再执行。
比如它可以连接浏览器观察页面,可以调用接口准备数据,也可以生成 Playwright 测试草稿。
但要有工具白名单。
能读什么、能写什么、能不能改数据库、能不能提交代码、失败后最多重试几次,这些都应该先定义好。
否则你测的就不是产品质量,而是在赌 Agent 的自控力。
3. 质量门禁层:别让“AI 说通过”成为测试结论
这一层最容易被忽略。
测试智能体必须输出证据,而不是只输出结论。
至少要留下:
-
• 执行日志 -
• 页面截图或 trace -
• 接口请求和响应 -
• 生成或修改的测试代码 diff -
• 断言通过和失败的明细 -
• 失败时的疑似原因 -
• 需要人工确认的风险点
这里有一个底线:
Agent 可以参与测试,但测试结论必须能被证据复核。
如果一个 AI 测试流程最后只有一句“测试已通过”,那它不是闭环,只是把人工风险换成了自动化风险。
它会具体改变哪些测试工作
从测试团队日常看,AI 测试智能体最可能先影响 5 类工作。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意,这里说的是“辅助和增强”,不是替代。
测试工程师的价值反而会更前移。
以前你可能花很多时间写重复脚本。
以后更重要的是定义:
-
• 哪些风险必须测 -
• 哪些动作允许 Agent 做 -
• 哪些断言才算有效 -
• 哪些失败必须人工确认 -
• 哪些结果可以进入 CI 门禁
这也是 Tricentis 提到 QA 成为 AI 交付问责层的原因。
AI 越能干,质量治理越不能空。
一个具体例子:订单退款链路怎么用 AI 测试智能体试点
不要从“全站自动化”开始试。
更好的试点,是选一个高价值、高风险、可验证的业务链路。
比如订单退款。
这个场景足够典型,因为它不只是点几个按钮,还涉及状态、金额、库存、支付回调、消息通知和幂等。
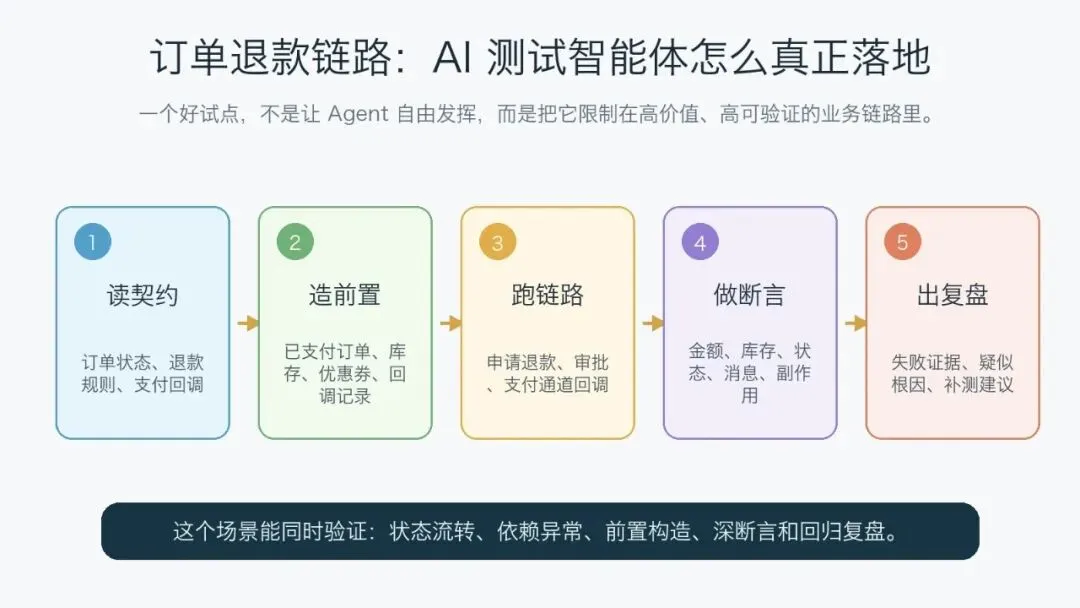
图 3:订单退款链路适合做试点,因为它同时覆盖状态流转、依赖异常、前置构造和副作用断言。
一个合理的 Agent 流程可以这样设计。
第一步:读契约,不急着生成脚本
先让 Agent 提取关键规则:
-
• 只有已支付订单允许发起退款 -
• 已发货订单和已完成订单走不同退款策略 -
• 退款成功后订单状态要更新 -
• 支付流水要产生退款记录 -
• 库存是否回补要看业务规则 -
• 重复回调不能重复退款
测试工程师要审这一步。
因为一旦契约理解错了,后面生成再多测试也没意义。
第二步:构造前置数据
让 Agent 输出前置清单:
-
• 一个已支付订单 -
• 一个使用优惠券的订单 -
• 一个库存已扣减的商品 -
• 一条支付成功流水 -
• 一个模拟支付通道回调 -
• 一个可复用的退款申请用户
这里最好先让 Agent 生成数据构造方案,而不是直接写数据库。
测试同学确认后,再决定用接口、脚本、fixture 还是测试平台来落地。
第三步:执行 UI 或 API 链路
如果走 UI,可以让 Agent 借助 Playwright MCP 观察真实页面,识别按钮、表格、弹窗和加载状态。
如果走 API,可以让 Agent 生成接口调用序列。
但无论 UI 还是 API,都要保留 trace。
否则失败以后很难判断:
-
• 是 Agent 点错了 -
• 是测试数据不对 -
• 是页面加载慢 -
• 还是产品真的有缺陷
第四步:做深断言
退款链路不能只断言“页面提示成功”。
至少要检查:
-
• 订单状态是否正确 -
• 退款单状态是否正确 -
• 支付流水是否正确 -
• 用户余额或原支付渠道是否更新 -
• 库存是否按规则回补 -
• 优惠券是否按规则恢复 -
• 消息通知是否只发一次 -
• 重复回调是否被幂等处理
这一步才是测试工程师最该把关的地方。
AI 可以帮你列断言,但断言有没有业务深度,还是要靠测试同学判断。
第五步:输出复盘,而不是只输出通过
好的 Agent 输出不应该只有 pass / fail。
它应该给出:
-
• 覆盖了哪些状态 -
• 没覆盖哪些状态 -
• 哪些断言通过 -
• 哪些断言失败 -
• 失败证据在哪里 -
• 疑似问题属于产品、环境还是测试实现 -
• 下一轮建议补哪些 case
这样它才真正进入测试闭环。
这件事对测试工程师的能力要求变了
AI 测试智能体火起来以后,测试同学最该补的不是“会不会写更花的 Prompt”。
更重要的是 5 个能力。
1. 契约理解能力
你要能把需求、接口、状态机翻译成明确测试约束。
Agent 可以帮你整理,但不能替你判断业务规则是否合理。
2. 场景建模能力
你要能从角色、状态、数据、异常依赖里拆出高价值场景。
否则 Agent 很容易生成一堆看起来完整、实际价值不高的 case。
3. 前置构造能力
AI 生成测试步骤不难。
难的是让测试数据稳定、可复用、可清理。
这直接决定智能体测试能不能进 CI。
4. 断言设计能力
未来测试的分水岭,不是“谁生成的脚本多”。
而是谁能设计出更深的断言。
页面文案、接口状态、数据库记录、消息队列、缓存、副作用,都可能是断言对象。
5. 证据复盘能力
Agent 执行越多,失败样本也会越多。
测试团队要能把这些失败沉淀成:
-
• flaky 识别规则 -
• 补测模板 -
• 失败归因库 -
• 回归风险地图
这才是长期收益。
如果你想试,不建议一上来采购平台或重构全套自动化。
可以从一个小闭环开始。
第一步:选一个小而硬的链路
优先选:
-
• 订单 -
• 支付 -
• 库存 -
• 会员 -
• 营销 -
• 结算
不要选纯展示页面。
因为纯展示页面很容易变成“AI 点点点”,体现不出测试价值。
第二步:写一份 Agent 测试契约
里面至少写清:
-
• 测试目标 -
• 允许使用的工具 -
• 允许读写的数据范围 -
• 必须覆盖的状态 -
• 必须检查的断言 -
• 失败后最多重试几次 -
• 哪些情况必须停止并交给人工确认
第三步:先让 Agent 生成计划,不直接执行
第一轮只要计划。
测试同学审计划,主要看:
-
• 有没有漏关键状态 -
• 有没有乱造业务规则 -
• 有没有缺少前置 -
• 有没有只做浅断言 -
• 有没有危险操作
第四步:隔离环境执行
执行时尽量放在:
-
• 测试环境 -
• 独立账号 -
• 独立数据 -
• 可回滚数据库 -
• 有 trace 的浏览器会话
不要让 Agent 直接碰生产数据。
也不要让它默认拥有写库、删数据、提交代码的权限。
第五步:用指标判断值不值得扩
不要只看“AI 生成了多少用例”。
更应该看:
-
• 人工设计时间减少了多少 -
• 有效断言增加了多少 -
• 失败定位时间下降了多少 -
• flaky 是否增加 -
• 误报是否可控 -
• 是否发现了人工原本容易漏掉的问题
如果这些指标没有改善,就别急着扩大范围。