 夜雨聆风
夜雨聆风





AI 工程进化论 第3讲:Claude Code 拆解 — 终端里的执行闭环是怎么工作的
导读
这是《AI 工程进化论》第 3 讲。 第1讲说了执行四条件,第2讲说了工具标准化。这一讲接上:Claude Code 作为第一个真正工程可用的终端 agent,它的内部是怎么组织的。 不讲怎么用,讲它为什么这样设计,边界在哪里,trap 在哪里。适合用过 Claude Code、想知道背后机制的人。
从一个真实场景开始
你给 Claude Code 发了一条指令:”修掉这个 bug,顺带把相关测试跑一遍。”
它开始读文件。读完了开始改。改了之后跑测试。测试报错了。它看到报错,重新读了几个文件,又改了一处。再跑测试。这次通过了。
这不是一次性生成,是一个循环。循环的每一轮,模型根据上一轮的 tool result 决定下一步做什么,不是预设的固定流程。
理解这个循环,是用好 Claude Code 的前提。
循环的序列图
下面是一个完整修复循环的实际发生序列:
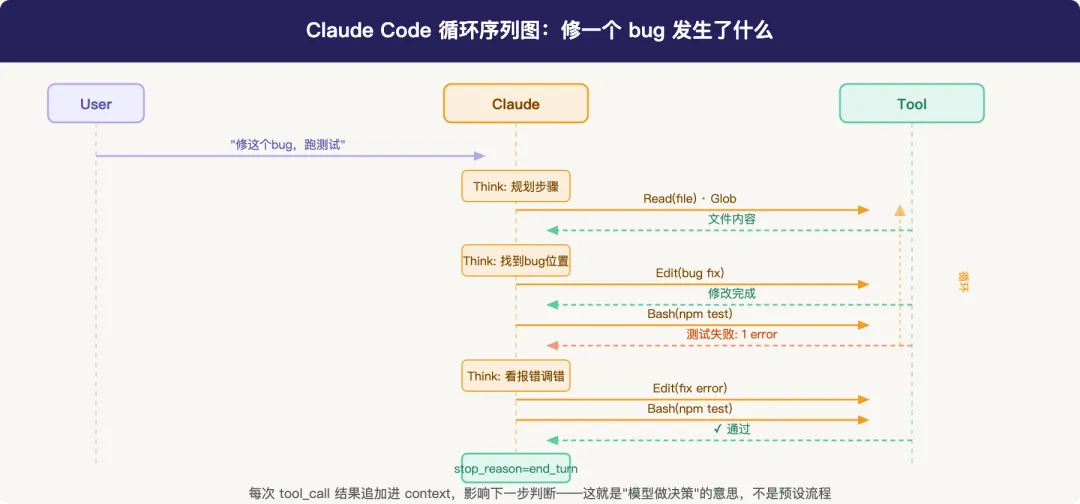
这个图里有几件值得注意的事:
每次 tool_call 之后,模型在看结果做判断。 “测试失败”这条返回,不只是告诉它”错了”,而是让它的下一轮推理多了一个信息点——报错内容、哪个用例、什么错误类型。这和人类工程师 debug 的思维过程是同构的。
循环次数不预设。 图里它跑了两次测试才成功,这不是脚本写的,是模型根据每次结果动态决定的。有时候可能是十次。
“Think” 阶段不是独立的 tool_call,是模型内部的推理。 你看不到它,但它确实在每次 tool 返回之后、下一轮 tool 发出之前发生。
工具是闭环的原因,不是装饰
没有工具的 Claude Code,能力上限就是对话。
有工具之后,它能操作真实环境。文件、Bash 命令、Git 操作、Web 搜索——这些是它闭环的介质。
内置工具分五类,这个划分不是随意的:
文件 + Bash:这两类是直接改变环境状态的操作,是真正有副作用的。Edit 一个文件或跑一条 rm -rf,状态就变了,不可逆。
搜索(Glob / Grep):不改变状态,只获取信息。这类的风险边界很清楚:不会造成破坏。
Web(Search / Fetch):从外部补充信息,同样只读不写。
代码智能:依赖语言服务插件,属于增强能力,不是核心环。
这个分类的真正含义是:越靠前的类别,危险越大,权限控制越严。你在 session 里看到的那些”是否允许执行”的提示,背后的逻辑就是这个分层。
Session 的两个真实问题
Session 是上下文保持机制,但它有两个实际问题你迟早会遇到。
问题一:上下文断在哪里
随着 session 变长,上下文窗口会接近上限。Claude Code 自动压缩:先清理旧的 tool outputs(这些通常最长),再不够就对整个对话做摘要。
这个机制有一个 trap:早期说过的关键约束,可能在压缩里丢掉。
比如你在 session 开始时说”这个项目的数据库是只读的,不允许任何写操作”。跑了三十轮之后,如果上下文被压缩,Claude 可能不再记得这条约束。它可能会尝试执行写操作——不是因为它故意违背,是因为它不记得了。
工程上正确的做法:关键约束写进 CLAUDE.md,不写进对话。CLAUDE.md 不会被自动压缩,每次 session 都会重新加载。
问题二:Checkpoint 不覆盖 git
Claude Code 在修改文件前会快照原文件,按两次 Esc 可以回滚。但这个快照是 session 级的本地机制,不等于 git commit。
trap 在这里:如果你在一个 session 里做了大量修改,然后切换了 git 分支,再切回来——那个 session 的 checkpoint 已经没了。checkpoint 只在同一个 session 内有效。
正确流程:重要节点主动 git commit,不要把 checkpoint 当成版本控制的替代品。
权限系统: trap 在团队场景
Claude Code 有四个权限档位,按 Shift+Tab 循环切换:
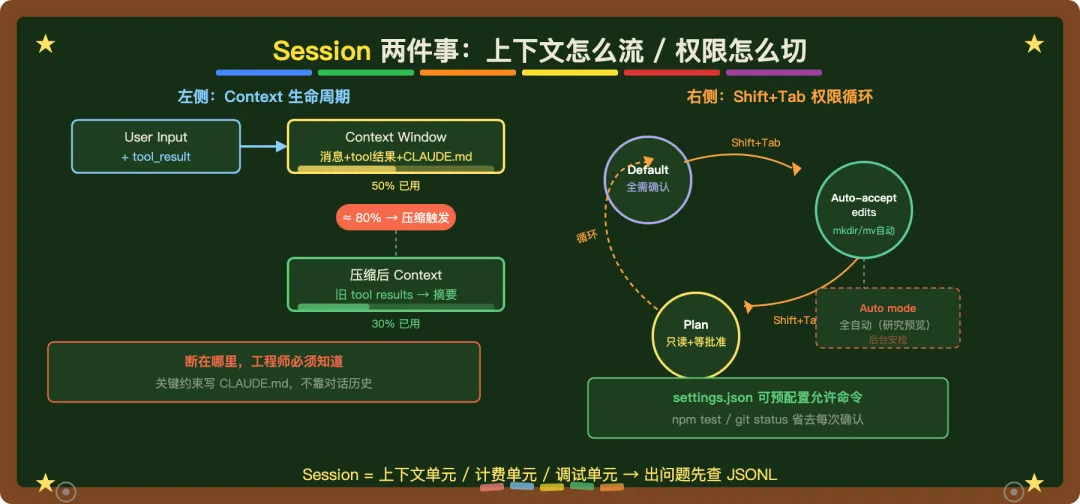
Default:文件修改和 shell 命令都需要确认。
Auto-accept edits:mkdir、mv 这类常见文件操作自动通过,其他命令仍需确认。
Plan mode:只读工具,生成行动计划等你批准后再执行。
Auto mode:全自动——目前是研究预览,不建议在正式场景用。
真正的 trap 在团队配置里。
开源版和团队版的差距不在模型能力,在权限粒度。.claude/settings.json 里可以预配置允许的命令白名单——比如 npm test、git status 这类高频信任操作,不需要每次点确认。
但这里有个边界:预配置的命令如果包含了有副作用的操作(比如 git push --force),等于开门让人走。
团队部署时的必做项:逐条审查允许的命令列表,不能直接用社区分享的默认配置。
MCP 扩展:工具上限由你决定
第2讲讲了 MCP 协议,Claude Code 原生支持。
内置工具是基础,MCP Server 是扩展层。在 .claude/settings.json 里配一个 MCP Server,不需要改 agent 代码,工具列表自动增加。
这个设计的含义是:Claude Code 的能力上限不是固定的,是开放的。
你接一个数据库 MCP Server,它就能查 schema;接一个 GitHub MCP Server,它就能操作 issue 和 PR;接一个 Slack MCP Server,它就能发消息。
对于需要接入内部系统的工程师来说,这个扩展性是实际落地的关键——不是写死的功能,是按需接入的架构。
三件事能带走
1. 循环是 Claude Code 的心脏,但循环次数不预设
不要假设它跑一轮就完成。给任务时想清楚:什么算完成?验证条件是什么?在指令里给出这些,比给一个模糊目标更有效。
2. 关键约束写 CLAUDE.md,不写对话
对话会被压缩,CLAUDE.md 不会。这是 Session 机制里最容易被忽略的 trap,也是出问题之后最难追溯的根因。
3. 权限白名单是团队部署的门槛
.claude/settings.json 里的允许命令列表,是 Claude Code 从”个人工具”变成”团队工具”的分界线。这个字段不能交给社区默认配置,要自己审。
下一讲:多智能体协作——并行 agent 怎么分工
Claude Code 架构来源:code.claude.com/docs/en/how-claude-code-works(2026-04-25 核实)。内置工具分类、Session 存储路径、权限模式、Checkpoint 机制、上下文压缩均来自该文档。