 夜雨聆风
夜雨聆风





全球最火的OpenClaw龙虾,为何把中国AI作为首选
两天前DeepSeek V4发布的时候,我就猜到会有一波大动静。
但真没想到,动静来得这么快,而且这么大。
OpenClaw,就是那个GitHub上攒了25万星标、全球最火的开源Agent框架——龙虾,在最新的2026.4.24版本里,直接把DeepSeek V4 Flash设成了默认模型。
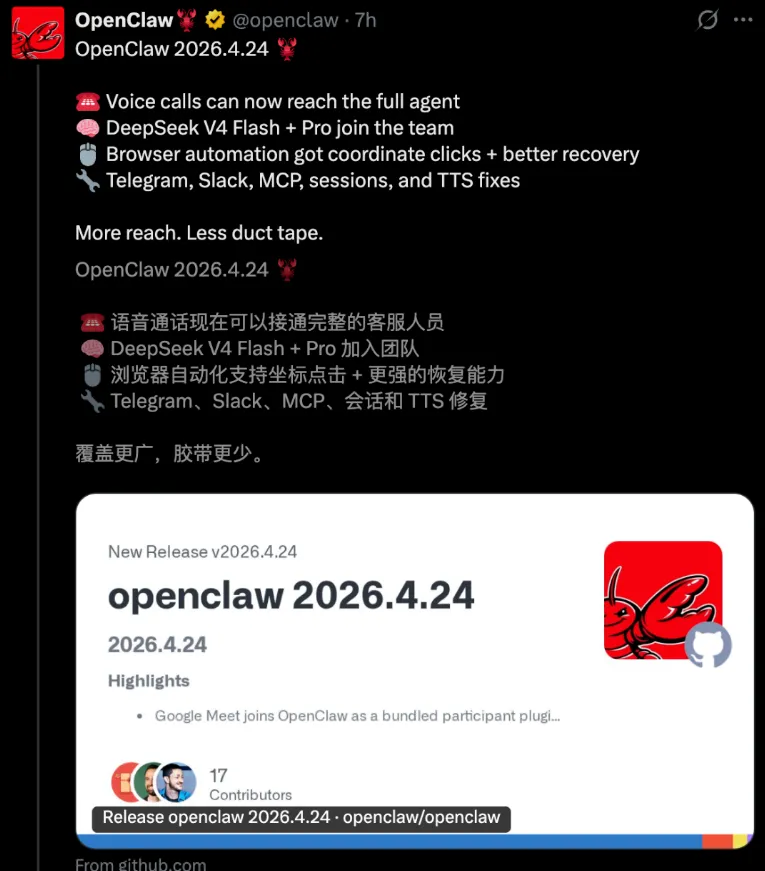
你打开OpenClaw,默认对话的模型,就是DeepSeek V4 Flash。
说实话,我看到这条更新日志的时候,愣了一下。
不是说DeepSeek不够好。恰恰相反,V4刚出来就被全球AI圈盯着,1.6万亿总参数的Pro版本被称为开源新王,MIT协议完全开源,100万token的上下文窗口,这些数据随便拎一个出来都很能打。
但问题是,OpenClaw不是小角色。25万星标意味着什么,做开源的朋友都懂。这是一个全球开发者用脚投票投出来的位置。
这样一个项目,把默认模型的C位给了一个中国模型。
这就不只是技术选型了。
我跟你说说我为什么觉得这件事有意思。
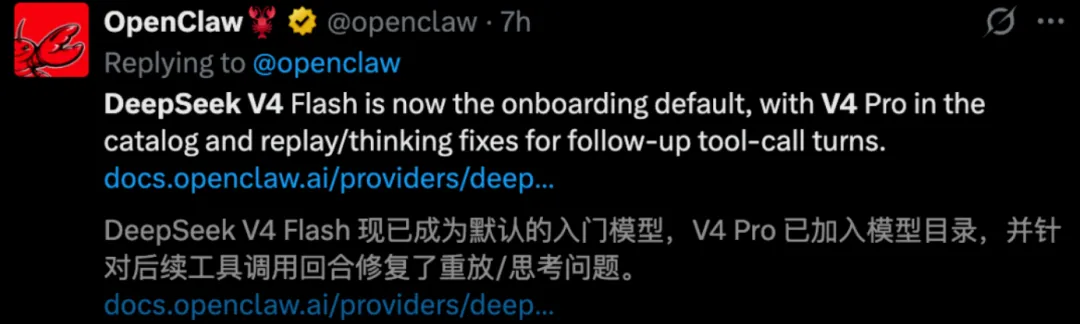
首先,OpenClaw选的不是Pro,是Flash。
V4 Flash总参数284B,激活参数只有13B,比Pro小得多。但官方说在Max模式下,Flash的推理能力几乎追平Pro。同时它更小、更快、更便宜。
看懂了吗。
OpenClaw作为一个面向全球用户的开源框架,默认模型必须考虑一个现实问题,成本。
全球每一个打开OpenClaw的用户,第一下交互就是跟默认模型对话。如果默认模型太贵、太慢,用户体验就直接崩了。
Flash在这个位置,就像球队里的首发控卫,不一定是全场最耀眼的明星,但一定是最稳、最能托底的那个。

而且OpenClaw早就不只是一个聊天工具了。
他们现在做的事情,是往工作流系统进化。浏览器自动化、会议接入、语音通话、文件处理、插件调度,这些都不是简单的你问我答,而是需要模型在多轮工具调用里保持稳定。
这次更新里有个细节特别值得注意。他们专门给DeepSeek V4修了一个工程bug,就是多轮工具调用时reasoning_content缺失会导致provider replay检查错误的问题。
听起来很技术对吧。
但这恰恰是Agent产品和普通聊天产品最大的区别。聊天产品模型回错了,顶多就是答案不对。Agent产品模型在工具链路上抖一下,整个任务就断了。
OpenClaw选DeepSeek V4,不只是看它在基准测试上跑多少分,而是看它在真实的复杂链路里能不能撑住。
从这个角度来说,这次合作对双方都是一次验证。
对DeepSeek来说,能被OpenClaw这种量级的项目选为默认,意味着它的工程稳定性经过了全球最严苛的开源社区之一的压力测试。
对OpenClaw来说,接入一个MIT协议完全开源、性价比极高的中国模型,也让它在全球开发者面前多了一个强有力的选择。
更有意思的是,这件事发生在一个微妙的时间点。
OpenClaw正在从聊天产品走向工作流系统,电话和会议正在成为Agent的运行环境。真正决定体验的不是文本回复有多漂亮,而是模型能不能撑住那些复杂的长链路任务。
在这个转折点上,OpenClaw选择了DeepSeek V4 Flash作为默认大脑。
你想想看,这像什么。
像是一个正在扩建的城市,在选择它的第一条地铁线路。
不是选最贵的,而是选最能跑、最稳、最能跟城市一起长大的。

以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~ 谢谢你看我的文章,我们,下次再见。