 夜雨聆风
夜雨聆风





AI模型专题报告:DeepSeek V4和Kimi K2.6,性能跃升,国产算力适配加快

“计算机行业AI模型系列(三):DeepSeek V4和Kimi K2.6,性能跃升,国产算力适配加快”由广发证券发布。
本报告共计:32页。完整版PDF电子版报告下载方式见文末。
Kimi K2.6 和DeepSeek V4 陆续发布,性能跃升。
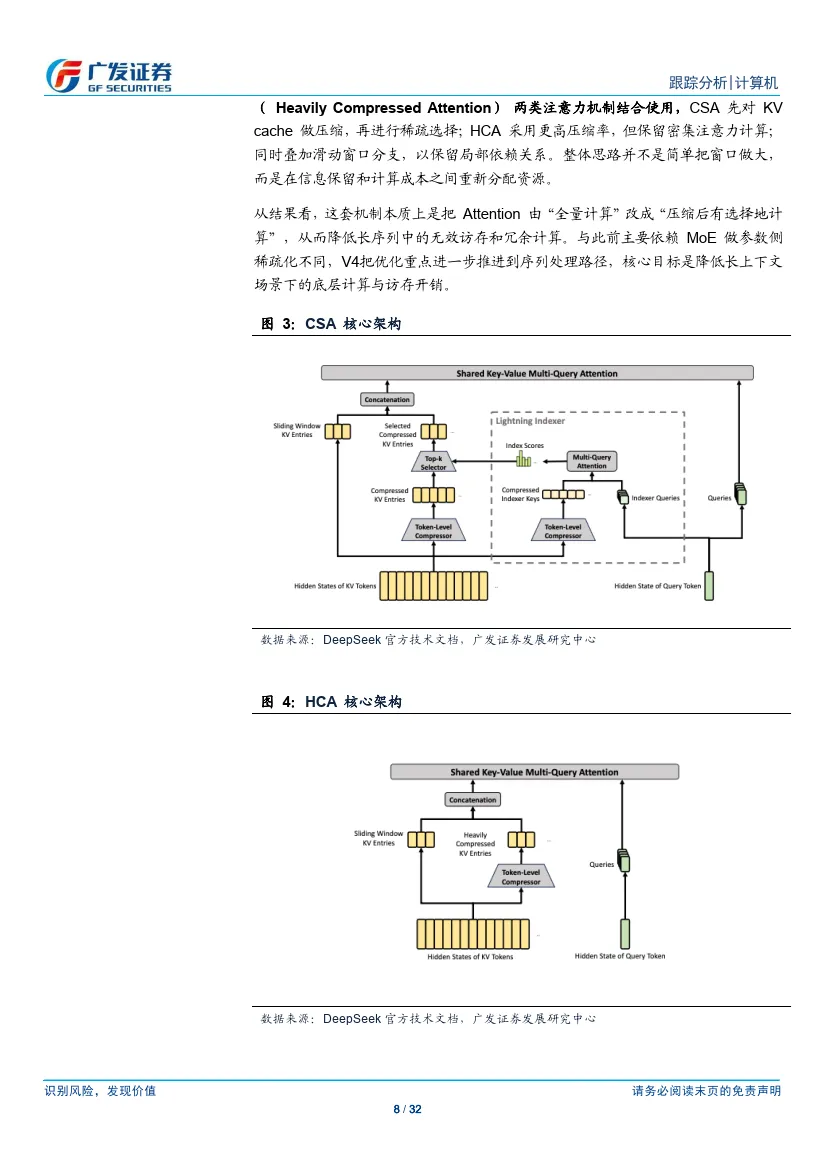
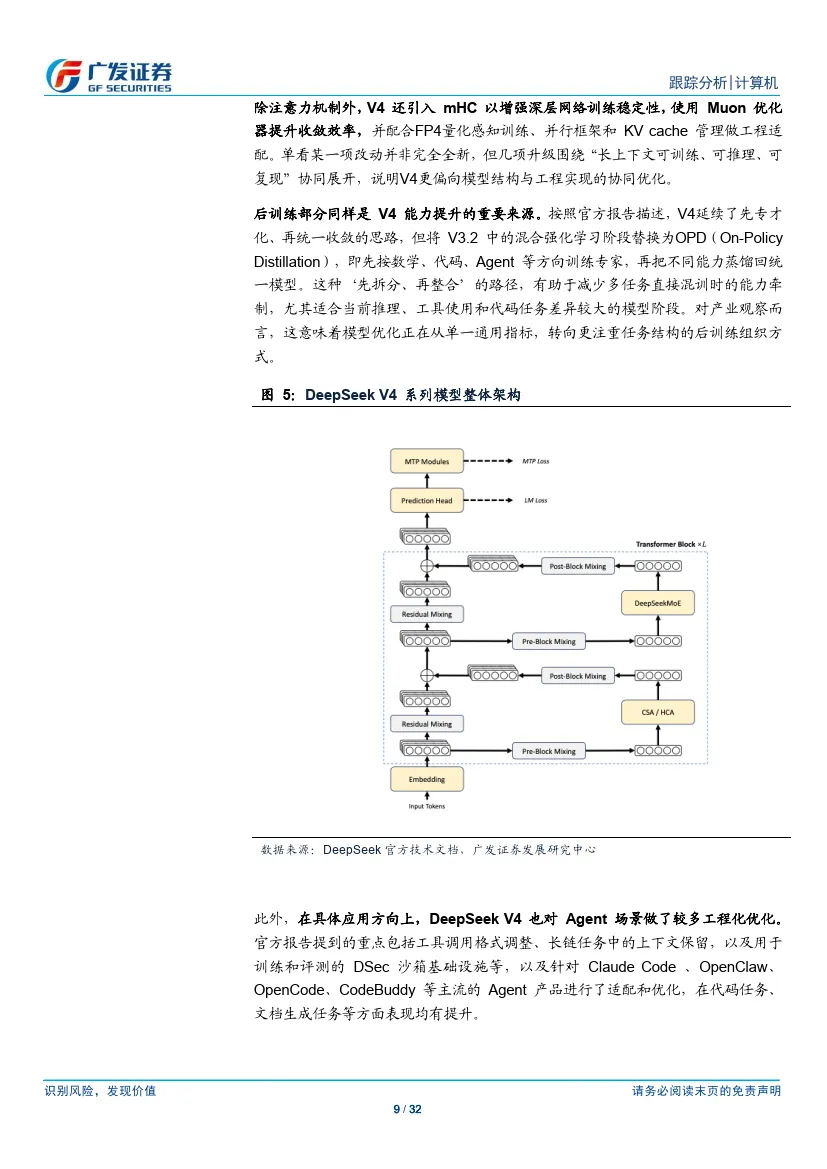
①26年4月24日,DeepSeek发布V4 模型,拥有百万字超长上下文,在Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。根据官方技术文档,在百万token 场景下,V4-Pro 单token 推理算力降至V3.2 的27%,KV cache 占用降至10%;V4-Flash 则进一步压缩至10%和7%。
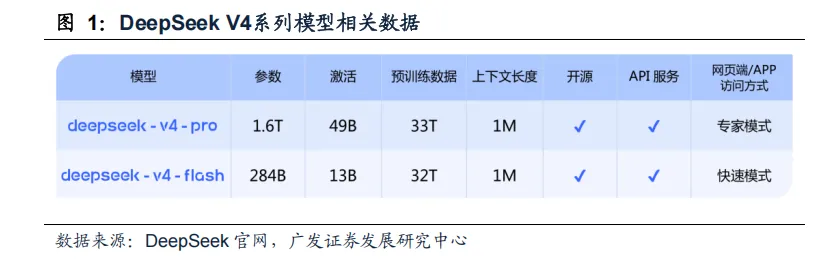
模型性能:开源第一梯队,与闭源前沿仍有差距
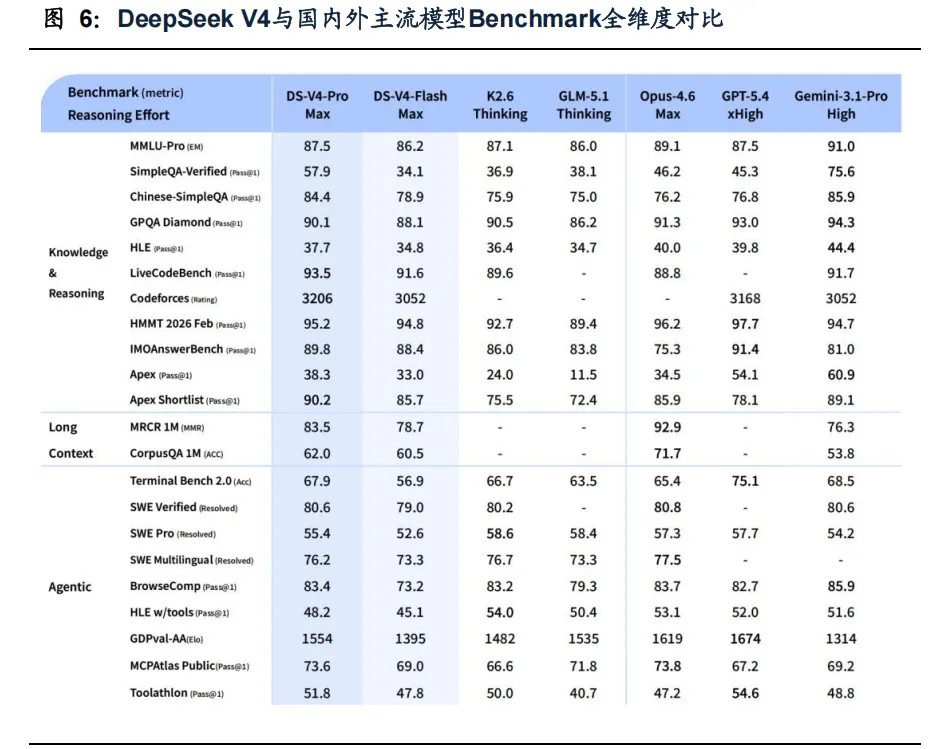
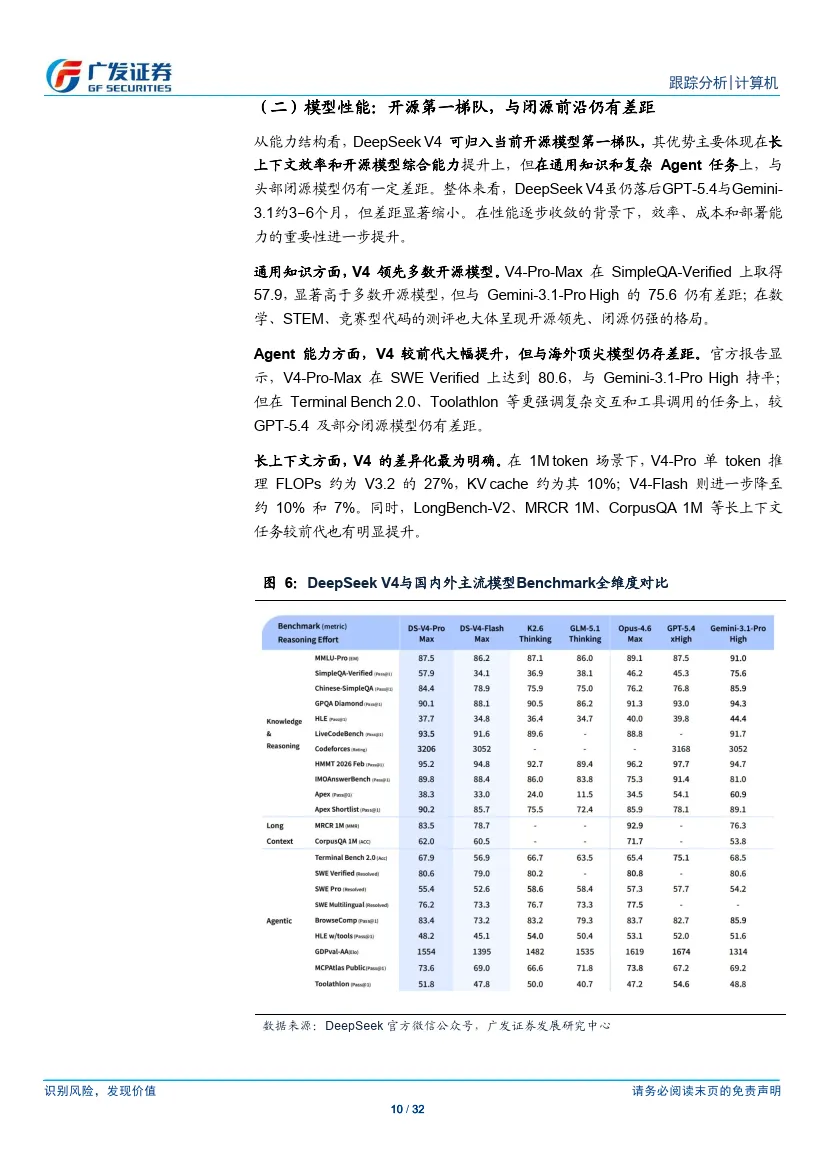
从能力结构看,DeepSeek V4 可归入当前开源模型第一梯队,其优势主要体现在长上下文效率和开源模型综合能力提升上,但在通用知识和复杂Agent 任务上,与头部闭源模型仍有一定差距。整体来看,DeepSeek V4虽仍落后GPT-5.4与Gemini- 3.1约3–6个月,但差距显著缩小。在性能逐步收敛的背景下,效率、成本和部署能力的重要性进一步提升。

-
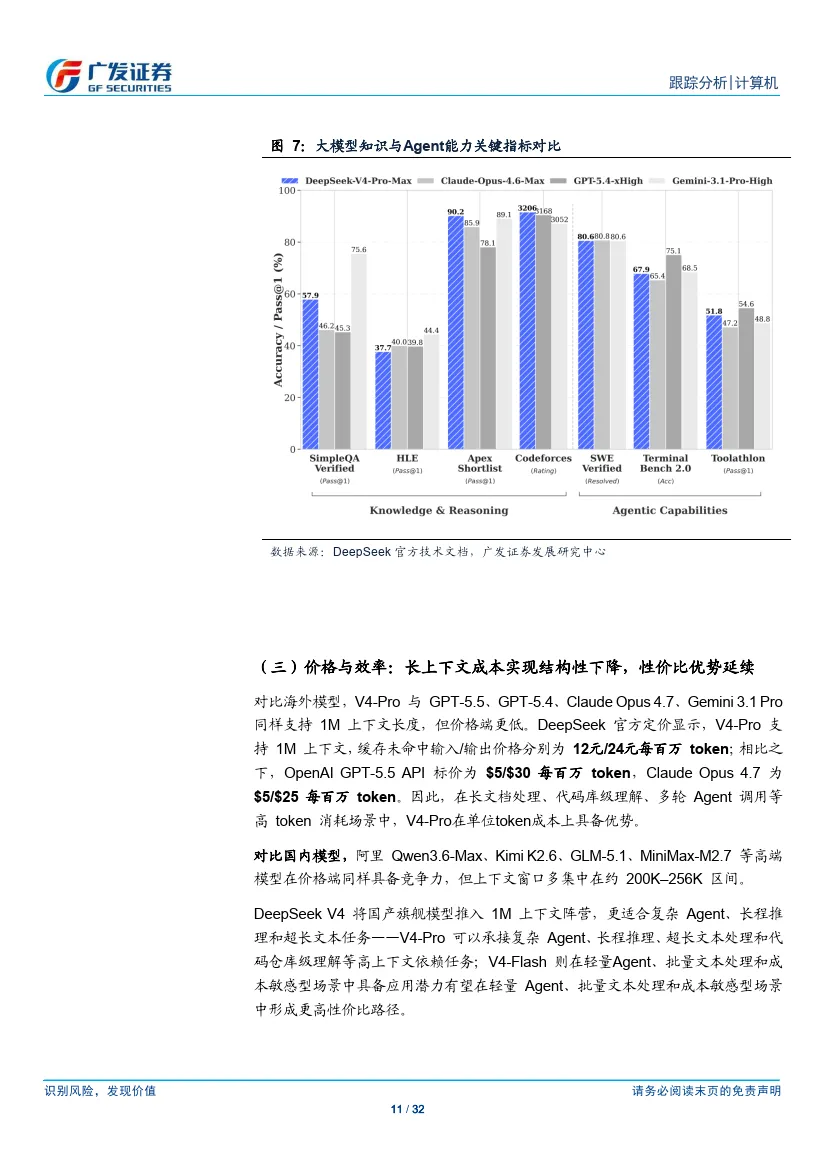
通用知识方面,V4 领先多数开源模型。V4-Pro-Max 在SimpleQA-Verified 上取得57.9,显著高于多数开源模型,但与Gemini-3.1-Pro High 的75.6 仍有差距;在数学、STEM、竞赛型代码的测评也大体呈现开源领先、闭源仍强的格局。
-
Agent 能力方面,V4 较前代大幅提升,但与海外顶尖模型仍存差距。官方报告显示,V4-Pro-Max 在SWE Verified 上达到80.6,与Gemini-3.1-Pro High 持平;但在Terminal Bench 2.0、Toolathlon 等更强调复杂交互和工具调用的任务上,较GPT-5.4 及部分闭源模型仍有差距。
-
长上下文方面,V4 的差异化最为明确。在1M token 场景下,V4-Pro 单token 推理FLOPs 约为V3.2 的27%,KV cache 约为其10%;V4-Flash 则进一步降至约10% 和7%。同时,LongBench-V2、MRCR 1M、CorpusQA 1M 等长上下文任务较前代也有明显提升。
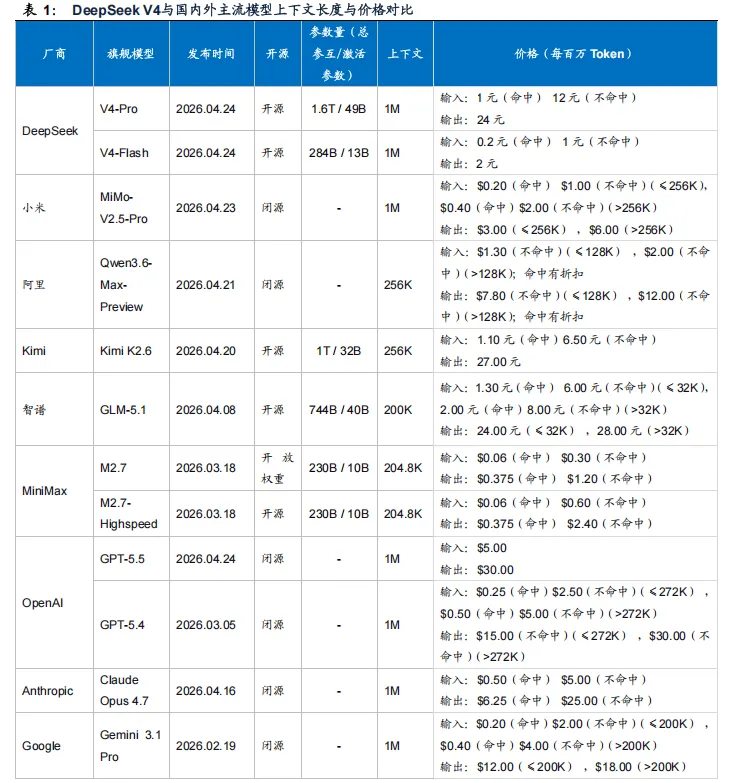
价格与效率:长上下文成本实现结构性下降,性价比优势延续
对比海外模型,V4-Pro 与GPT-5.5、GPT-5.4、Claude Opus 4.7、Gemini 3.1 Pro 同样支持1M 上下文长度,但价格端更低。DeepSeek 官方定价显示,V4-Pro 支持1M 上下文,缓存未命中输入/输出价格分别为12元/24元每百万token;相比之下,OpenAI GPT-5.5 API 标价为$5/$30 每百万token,Claude Opus 4.7 为$5/$25 每百万token。因此,在长文档处理、代码库级理解、多轮Agent 调用等高token 消耗场景中,V4-Pro在单位token成本上具备优势。
对比国内模型,阿里Qwen3.6-Max、Kimi K2.6、GLM-5.1、MiniMax-M2.7 等高端模型在价格端同样具备竞争力,但上下文窗口多集中在约200K–256K 区间。DeepSeek V4 将国产旗舰模型推入1M 上下文阵营,更适合复杂Agent、长程推理和超长文本任务——V4-Pro 可以承接复杂Agent、长程推理、超长文本处理和代码仓库级理解等高上下文依赖任务;V4-Flash 则在轻量Agent、批量文本处理和成本敏感型场景中具备应用潜力有望在轻量Agent、批量文本处理和成本敏感型场景中形成更高性价比路径。
②26年4月20日,月之暗面发布Kimi K2.6。K2.6 强调长程代码任务和Agent Swarm 编排能力。在官方博客示例中,K2.6 曾在12 小时以上连续执行、4000 多次工具调用和14 轮迭代中完成模型推理任务。

DeepSeek V4 和Kimi K2.6 的推出不仅有望拉动国产AI 芯片的需求,CPU 和超节点等产品也有望放量。
在国产AI 算力和模型厂商紧密合作下,我们预计下游客户有望采购较大比例的国产AI 芯片来满足其对DeepSeek 和Kimi 的新增算力需求。此外,在Agent 能力增强的情况下,DeepSeek V4 和Kimi K2.6 在辅助编程、工具调用、业务协同等场景的使用也有望拉动CPU 的需求。
经测算,为支持DeepSeek V4 和Kimi K2.6 大模型相关Tokens 的推理需求,预计市场新增采购的AI 加速卡在11 万至47 万张之间;新增的CPU 数量为5 万至24 万颗;新增的超节点在283 至1236 台之间。
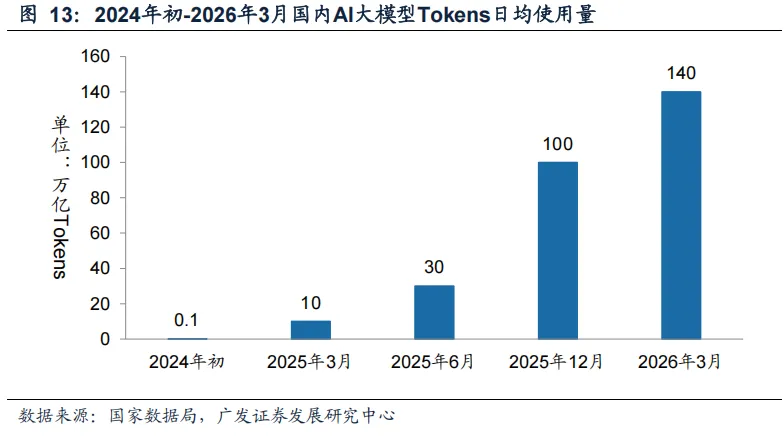
截止2026年3月底,国内AI大模型日均Tokens调用量已达140万亿。据国家数据局数据,截至2026年3月底,中国AI大模型日均Tokens消耗量已达140万亿,2025年底该数值约为100万亿,这反映了AI大模型在国内各行各业逐步应用与商业化落地。Token调用量是衡量AI模型使用强度与商业价值的核心指标,国内AI大模型Tokens 的快速增长,既源于DeepSeek、GLM、MiniMax、Qwen等国产模型能力的持续迭代,也反映了其在编码、智能体及视频生成等多个场景落地钟的高频使用。
幻影视界整理分享报告原文节选如下:






 戳“阅读原文”下载报告。
戳“阅读原文”下载报告。