 夜雨聆风
夜雨聆风





AI 每日观察 · 2026.04.27
六条精选:DeepSeek打开融资大门、Altman重新定义AGI价值观、阿联酋宣布政府AI化50%、斯坦福指数揭示五大趋势、微软背景团队做出工业AI爆款、字节Kimi K2.6正面挑战OpenAI

01 DeepSeek首次打开融资大门:估值200亿美元,腾讯阿里联投18亿美元
4月27日,DeepSeek正式宣布完成成立以来首轮对外融资,腾讯与阿里联合注资,具体交易结构为:以约3%股权换取约3亿美元投资,整体估值达到约200亿美元。这意味着,这家以”开源+低成本”在2025年震动全球AI行业的中国公司,在成立不到两年后,正式站上了200亿估值的台阶。
这轮融资背后的驱动力相当直接。知情人士透露,DeepSeek正在加速推进V4大模型的研发,而训练一个参数规模达万亿级别的模型需要数万张高性能算力卡,单纯靠自有资金和云厂商的算力扶持已经不够用了。与此同时,公司在人才竞争上遭遇了来自字节跳动、小米、腾讯等大厂的直接冲击——至少5名核心研究员在过去几个月内相继离职,加入了上述公司。这次融资的部分资金,也将用于应对人才流失和留住核心团队。
另一个关键信息是DeepSeek正在推进技术栈的重大迁移:下一代模型将首发搭载华为昇腾AI芯片。这不仅意味着DeepSeek在算力采购上开始减少对英伟达的依赖,也是国产AI芯片真正进入顶尖大模型训练环节的重要节点。华为昇腾910系列此前主要面向推理场景,在训练环节的应用案例有限,DeepSeek的这次迁移将为昇腾芯片的能力边界提供一次真实的压力测试。
本轮融资完成后,有消息称DeepSeek最快将在2026年底递交港股或美股IPO申请。届时200亿美元的估值如果成立,它将成为全球仅次于OpenAI和Anthropic的第三大AI独角兽,而腾讯和阿里的入股也将为这笔IPO提供重要的市场背书。

02 Altman重写AGI的五个核心价值观:一场时机微妙的品牌重塑
4月27日,OpenAI CEO山姆·奥特曼发布了一篇文章,系统阐述了OpenAI眼中AGI(通用人工智能)的五个核心价值观:民主化、赋能个体、普惠繁荣、系统韧性和集体适应能力。这篇文章在社交平台上迅速引发广泛讨论,但很多评论的关注点并不在文章内容本身,而是它发布的时间节点——就在这篇文章发布的同时,OpenAI刚刚完成从非营利组织向营利性公司的法律转型,而外界注意到,公司在转型文件中悄悄删除了原有使命宣言中的”安全”(safety)一词。
先看这五个原则本身。民主化意味着AI能力不应被少数实体垄断,OpenAI承诺通过API和开源工具向全球开发者开放;赋能个体是指让每个个人和小型组织都能借助AI完成此前只有大型机构才能完成的任务;普惠繁荣指的是AI的经济收益应广泛分配而非集中于顶层;系统韧性强调AI基础设施的安全和可靠性;集体适应能力则是指AI应帮助人类社会更好地应对未来挑战。
从内容本身看,这五条原则并不空洞,每一条都有对应的OpenAI产品或政策动作作为支撑。但问题在于,它们的发布时间与OpenAI的公司结构转型高度重合,而转型过程中删除”安全”二字的细节被媒体挖掘出来之后,这五条原则的解读就变得复杂了。有评论指出:一份在商业化转型完成后才发布的”价值观宣言”,更像是一份IPO前的品牌定位文件,而非驱动公司决策的内部准则。
更尖锐的质疑来自竞争格局层面。奥特曼在文章中提到”民主化”和”普惠”——而OpenAI目前估值约3000亿美元,刚刚完成超过1100亿美元融资,正在筹备IPO。一个如此体量的商业公司谈”普惠”和”不被少数实体垄断”,说服力几何?这种矛盾不是新问题,但在这个时间节点上被放大了。

03 阿联酋宣布2028年50%政府服务交给AI:全球第一个AI政府的野望
阿联酋总统谢赫·哈利法·本·扎耶德·阿勒纳哈扬于4月27日宣布,到2028年,50%的阿联酋联邦政府服务、内部运营和行政流程将全部交由Agentic AI(自主智能体)来执行和决策。这不是一份政策白皮书里的远期愿景,而是一个带有明确时间表和考核机制的政府军令状:联邦各部部长和政府高官的绩效考核,将直接与本部门AI部署速度挂钩。
这是迄今为止全球范围内第一个在国家政府层面如此大规模、系统性地引入自主AI的案例。阿联酋不是AI产业大国,它没有OpenAI、没有Anthropic,但它有足够强的政治意志和充足的财政资源来完成这件事。为了支撑这个目标,阿联酋已经启动了一项覆盖全体政府雇员的强制AI培训计划,要求所有在职公务员必须掌握基础AI工具使用和AI协同工作方法。
Agentic AI与普通AI助手的本质区别在于”自主性”。传统AI助手是”你说我做”,而Agentic AI是”你定目标,我自己规划、自己执行、自己修正”。在政府场景下,这意味着AI不仅能回答”我的签证申请到哪一步了”这类查询问题,而是可以直接审批某些标准化申请、自动生成内部报告、协调跨部门数据流转——在某些环节上甚至可以跳过人工复核直接出结果。
阿联酋为什么在这个时间节点做出这个决定?一方面,迪拜和阿布扎比多年来一直在推进政府数字化,基础已经打好;另一方面,AI Agent技术的成熟度在2026年已经达到了可以在生产环境中承接复杂任务的水平。全球其他主要经济体都在讨论AI监管和AI安全,阿联酋选择了一条更激进的路径:用快速部署来换取先发优势。
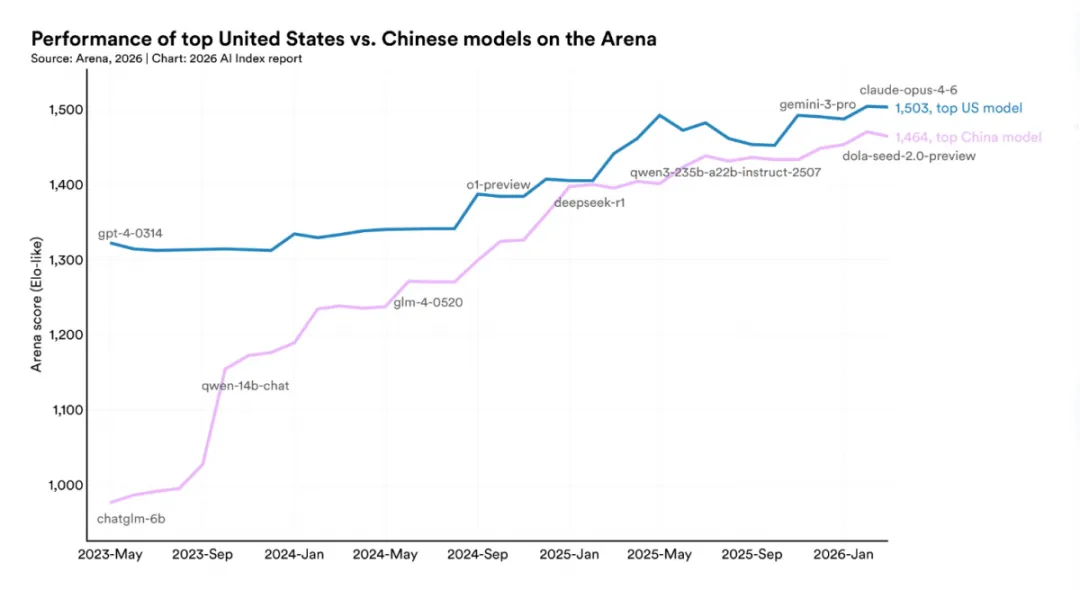
04 斯坦福AI指数报告2026版:五个值得深思的数据
斯坦福大学人类中心人工智能研究所(HAI)于4月中旬发布了2026年《人工智能指数报告》,这是目前全球最具权威性的AI年度数据汇编之一。今年的报告覆盖了基础研究进展、产业应用现状、人才流动趋势、AI对就业的影响以及模型透明度五大维度,以下是其中最值得关注的五个数据点。
第一组数据关于中美AI差距。报告显示,中美顶尖AI模型的性能差距已从2023年的显著差距,收窄至2026年的仅2.7%。换句话说,在模型能力的最前沿,中国模型已经几乎追平美国。这个数字背后,是DeepSeek V3、Kimi K2、字节豆包等多个国产模型在过去一年密集发布和迭代的结果。当然,2.7%的差距虽然很小,但它恰好横亘在”追赶者”和”领导者”之间,是真正突破前的最后一段距离。
第二组数据关于人才流失。报告显示,在美国顶尖AI研究机构任职的非美国籍顶尖学者数量较2017年峰值下降了89%,仅过去一年就锐减了80%。这个数字并不意味着AI人才消失了,而是说明全球AI人才正在经历一次大规模的重新分布——一部分流向了中国中东等新兴AI重镇,一部分选择了自主创业,还有一部分因为签证政策收紧而不得不离开美国。对于美国AI行业来说,这是比算力管制更深层的系统性挑战。
第三组数据关于AI的能力边界。报告指出,当前最强的大模型在数学奥赛级别的问题上已经能够稳定达到金牌水平——这是令整个AI行业振奋的里程碑。但同一个报告同时指出,同一批模型在基本的时间认知任务(如读取钟表或理解日历)上,准确率仅为50.1%。这个数字几乎是一个笑话:能做奥数题但分不清几点几分,揭示了当前AI系统在”真实世界物理直觉”上的根本缺陷。
第四组数据关于就业冲击。22至25岁软件开发者群体的就业率在过去一年下降了接近20%。这不是AI取代了所有程序员的故事,而是AI显著降低了个别程序员完成同样工作量所需的时间,而企业招聘新人的动力随之减弱。对于刚进入劳动市场的年轻技术从业者,这是一个冷峻的现实:他们的竞争对手不只是其他求职者,还有一个越来越能干的AI。
第五组数据关于模型透明度。最强AI模型的”透明度指数”——衡量模型训练数据来源、训练过程披露、安全测试结果等信息公开程度的综合指标——从去年的58分下降到了40分。模型越来越强,但外界对它的了解越来越少,透明度与能力之间的剪刀差正在扩大。这对于需要基于这些模型做合规决策的企业用户和监管机构来说,是一个越来越紧迫的问题。

05 智用开物:微软班底如何用工业AI做出一个近亿融资项目
4月27日,工业AI公司智用开物宣布完成新一轮融资,由立讯精密作为战略投资方参与,具体金额未披露,但据知情人士透露,本轮估值已达数亿美元,融资总额接近亿元人民币。这家成立仅一年的公司,核心团队几乎全部来自微软亚洲研究院,在工业AI这个已经被说了很多年但真正落地案例寥寥的领域里,拿出了少见的真实业务数据。
智用开物的核心产品是一套面向制造业的AI排产与SOP(标准作业程序)自动化系统。它目前的标杆客户是立讯精密——苹果供应链上的核心代工企业之一。在立讯的一条试点产线上,这套系统交出了这样一组成绩单:一个AI排产员的工作效率,相当于6名人类排产员;SOP文档的自动化生成率达到80%;新员工上岗培训时间从1.5天压缩到2小时;产线出现异常情况时,问题识别和响应速度提升了8倍。
这组数据的含金量在于它的可验证性。立讯精密是苹果的供应商,苹果对其供应商的生产数据管理有极高的合规要求,任何引入新系统都需要通过严格的安全和数据审计。智用开物能在这个级别的客户身上跑通完整的业务流程,本身就是对产品成熟度的一次高标准背书。
工业AI和消费AI的最大区别在于容错率。消费AI出错,顶多是生成一段不太通顺的文字;但工业AI出错,可能意味着整条产线停工或产品良率大幅下降。因此,工业AI产品的核心壁垒不在于模型有多强,而在于对特定行业业务流程的深度理解、与现有MES/ERP系统的无缝集成,以及在边缘计算环境下的稳定运行能力。这恰恰是那些有大厂背景、做过企业级产品的团队相比纯学术AI团队的核心优势所在。
制造业的AI渗透率目前仍然很低,大多数中小工厂的信息化基础薄弱,数据不规范,这是一个巨大的市场,但也是一个需要大量地面工作才能啃下来的市场。智用开物的案例给行业传递的信息是:这个市场不是不能做,而是需要真正沉下去做的耐心。

06 月之暗面Kimi K2.6发布:国产大模型正式进入”强人工智能对话”时代
4月27日,月之暗面正式发布Kimi新一代旗舰模型K2.6。这家成立于2023年的AI公司此前以”超长上下文”能力作为核心差异点,Kimi的200万字上下文窗口曾经是业内最长。但K2.6的意义远不止于参数或上下文长度的又一次刷新——它代表的是国产大模型在”复杂推理”和”多轮Agent执行”这两个能力维度上,第一次与GPT-5.5系列形成了真正意义上的正面竞争。
K2.6在基准测试上的最直接参照是OpenAI的GPT-5.5和Anthropic的Claude 3.7 Sonnet。在MATH数学推理、GPQA博士级科学问题和ARC-AGI通用推理这三个高难度测试集上,K2.6的表现与GPT-5.5的差距已经缩小到了单百分点之内。对于国内用户来说,这意味着如果一个任务此前必须调用GPT才能完成,现在Kimi K2.6可以作为等效的本地选项使用——在合规要求、数据隐私和响应延迟上反而更有优势。
更值得关注的是K2.6在Agent能力上的提升。月之暗面在发布时同步开放了Kimi Agent API,支持多步骤任务规划、工具调用和自我纠错。与OpenAI的Codex类似,K2.6的Agent模式不是给一个指令等一个答案,而是理解一个目标后自主规划路径、调用外部工具、迭代执行直至完成。这对于企业用户来说是一个关键能力,意味着AI可以从”回答问题的工具”进化为”完成任务的员工”。
月之暗面CEO杨植麟在发布会上说了一句话:K2.6不是对GPT的追赶,而是一次关于”AI应该以什么形态服务人类”的重新回答。这个说法有些宣传色彩,但K2.6背后确实有一个值得关注的产品思路:国产大模型厂商在2025年以前主要在做”能力补齐”——OpenAI有什么我们就做什么;进入2026年后,头部厂商开始出现分化,有些在做深度,有些在做广度,有些在做垂直场景。月之暗面选择继续押注” универсальный AI助手”这个赛道,K2.6是这个押注的最新注脚。
「AI 每日观察」