 夜雨聆风
夜雨聆风





AI Agent时代的Stata工作流:拥抱变化,守住判断
AI Agent时代的Stata工作流:拥抱变化,守住判断
当编码不再是瓶颈,研究的质量就完全取决于研究者的思维深度。AI Agent解放的是我们的双手,而不是我们的头脑。
一、效率革命已经到来
2025年,Stata-MCP在GitHub开源。这个基于Anthropic MCP协议的项目,第一次让大语言模型可以直接生成并执行Stata命令——数据清洗、回归建模、可视化输出,全流程不需要人工写一行代码。随后事情发展得很快:hanlulong做的Stata MCP Extension把这套能力嵌进了VS Code和Cursor,Trae通过MCP协议市场接入了Stata。
这不是画饼。TAN Song, Feng Mu-yao系统评估显示,Claude系列在Stata编程和计量理解任务上均分85.74,能独立走完从清洗到建模到输出的全流程,ReAct框架下的任务调度和流程管理能力也相当扎实。工具已经就位,问题变成了:怎么用。
二、AI真正擅长的,是什么?
AI Agent + StataMCP不是万能药,但提效是实打实的。关键在于搞清楚它到底在哪些环节有优势。
对于初学者,传统的Stata学习路径很折磨人——记语法、写代码、查帮助文档、调错误,动辄卡半天。
AI Agent把这个过程压缩成了”说需求、看代码、跑结果”,学习曲线被拉平了,但理解深度反而可能更好,因为你不再被语法细节绊住,注意力可以放在”为什么要这么做”上。对于有经验的用户,遇到不熟悉的命令时,AI同样好用。比如要做断点回归,rdrobust的带宽选择方法好几种,协变量平衡检验的选项一大堆,平时不常用,每次都要翻半天文档;用自然语言描述需求,让AI直接生成带正确选项的完整代码,效率高得多。
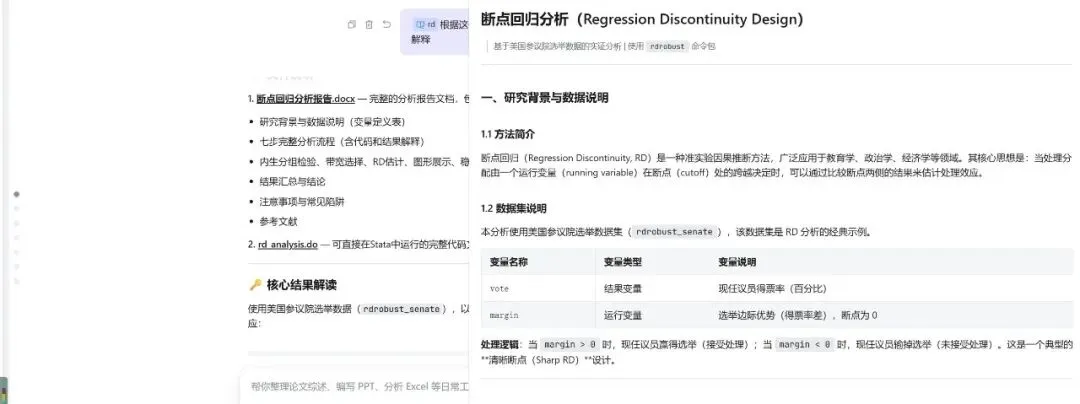
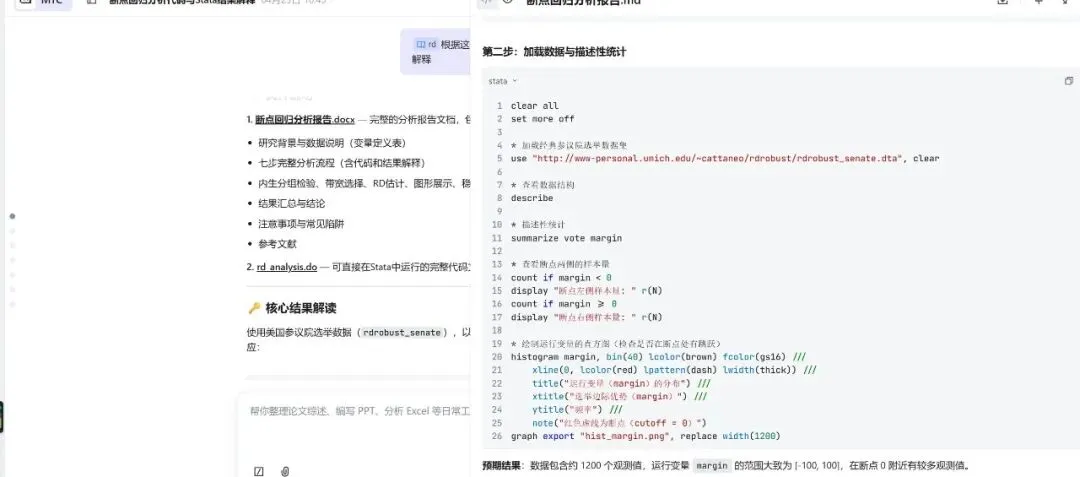
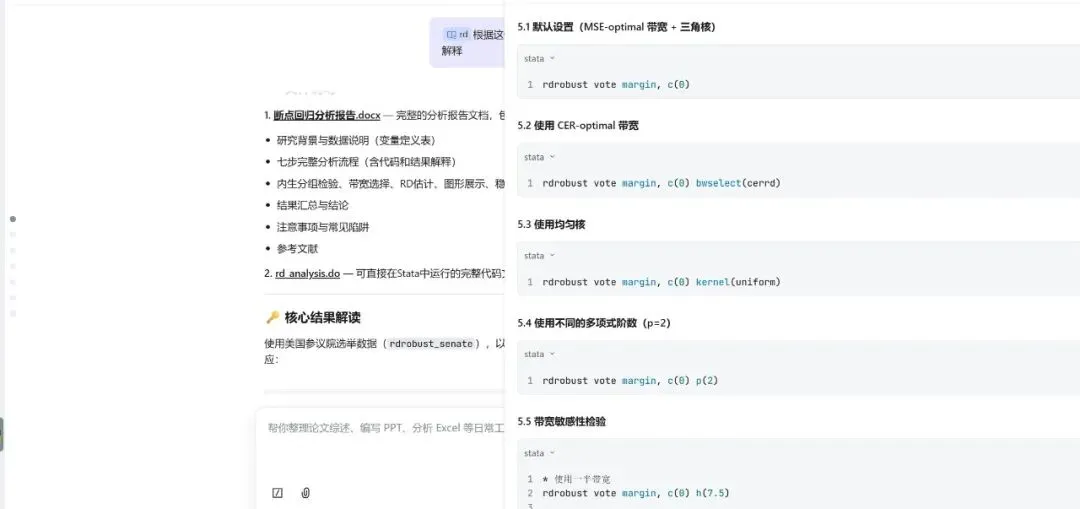
更广泛地说,凡是规则明确、可以流程化的操作,AI都有明显优势。数据清洗、变量重编码、多模型批量回归、结果格式化导出,这类结构化任务恰恰是AI最对口的领域。报错排查也是一例——少个逗号、变量类型不匹配、选项拼错,人工排查很烦,AI读一下报错信息就能定位。在探索性分析阶段,”边分析边对话”的模式让迭代速度快了很多:让AI解读回归结果的经济含义,建议可视化方案,直接生成图形代码,比传统方式高效得多。
这些场景有一个共同特征:规则明确、结构清晰、可流程化。 凡是符合这个特征的操作,交给AI基本不会出错,省下来的时间也很可观。
10年计量专家倾囊相授:AI (Deepseek) 赋能下的 Stata学术应用进阶攻略
三、AI做不了的,才是研究者的护城河
Stata-MCP研究报告里有一个发现值得反复咀嚼:所谓”思考模型”和”非思考模型”之间,没有统计上显著的性能差异。当前LLM本质上仍然是预测模型,在研究设计等开放式任务中表现不佳。
翻译成大白话就是:AI能执行,但不能决策。它可以帮你写出漂亮的DID回归代码,但判断不了你的研究设计到底满不满足平行趋势假设;研究设计、因果识别策略的选择、经济机制的提炼、结果的政策含义——这些才是实证研究的灵魂,也是AI在可见的未来都做不好的事。
那么,编码不再是瓶颈之后,什么变重要了?
学科直觉是第一位的。什么问题值得研究?什么现象背后藏着有意思的因果故事?这种嗅觉来自长期泡在文献里的积累,来自对现实世界的持续观察,来自跨领域知识的碰撞。AI帮你跑回归,但没法告诉你这个选题能不能发。研究判断力同样关键。DID的平行趋势不满足,是换事件研究法、换合成控制,还是干脆换识别策略?这些判断靠的是计量功底和实战经验,没有捷径。还有批判性思维——AI生成的代码一定对吗?结果解读一定合理吗?稳健性检验是不是真的检验了该检验的东西?研究者得做AI输出的最终把关人,不能照单全收。
归根到底,人机分工的边界很清晰:能流程化的交给AI,需要判断力的留给研究者。
四、三种工作流
当前Stata用户运行Stata命令可以通过如下方式:
Jupyter/VSCode与Stata交互方法3-StataMCP
Stata原生工作流稳定可靠、结果展示成熟、可复现性强,但编码效率低、学习曲线陡。
Jupyter + Stata实现了代码-结果-文档一体化,支持多语言混用,但配置稍复杂,不适合大型项目。Jupyter Notebook 与 Stata 交互方法1:nbstata方法2:stata_kernelStata18及csdid估计-12月23日AI赋能DID回顾
该文图2,就回顾了VS-Code中应用Stata的截图
AI Agent + StataMCP效率高、门槛低、能智能辅助,但结果展示不完善,且依赖网络和API服务。
下面为大家介绍一些VS-Code中应用Stata MCP的高级技巧。
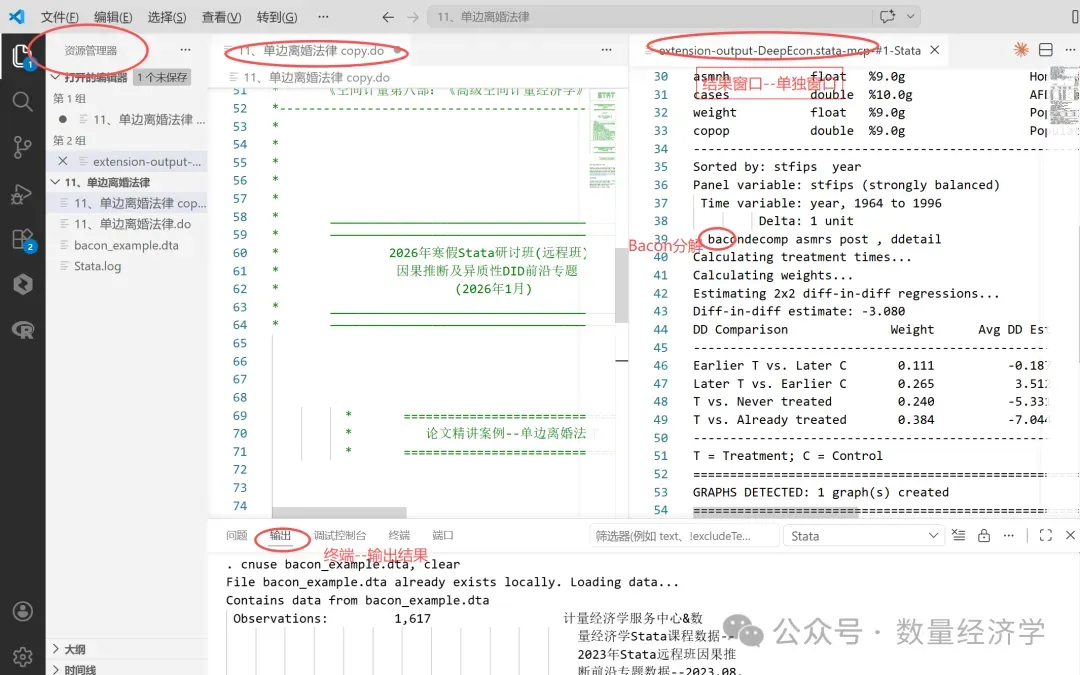
1、Stata MCP插件
下面展示的是第3种方法在VS-Code中执行Stata代码,即采用插件Stata MCP
2、AI助手结合应用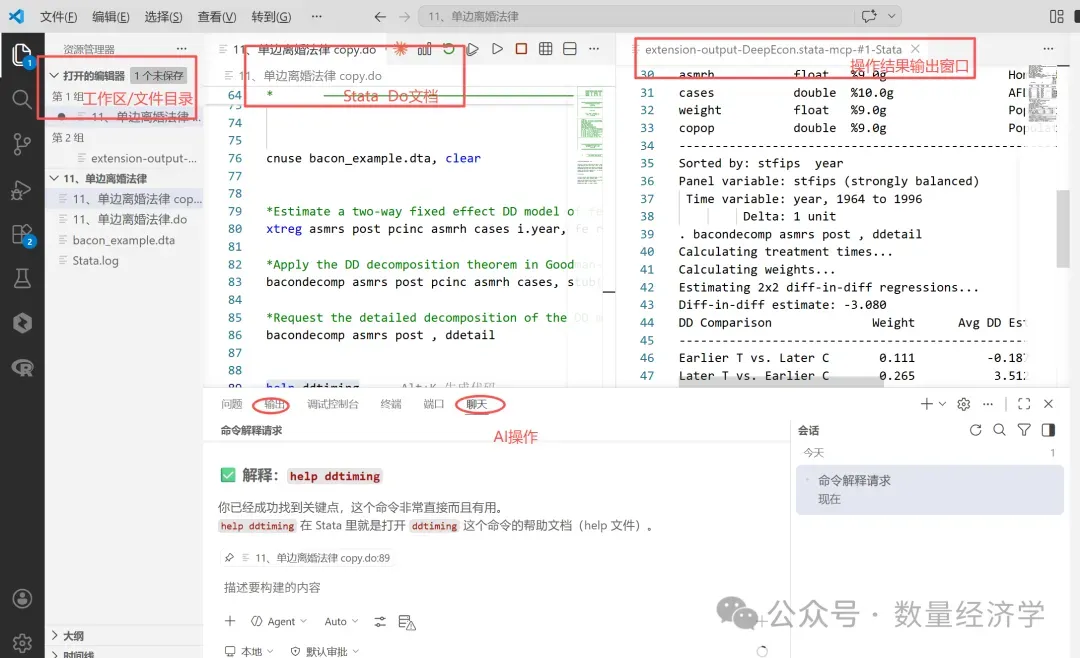
也可以结合AI 助手等(VS Code 里运行 GitHub Copilot Chat)
3、Stata MCP高级操作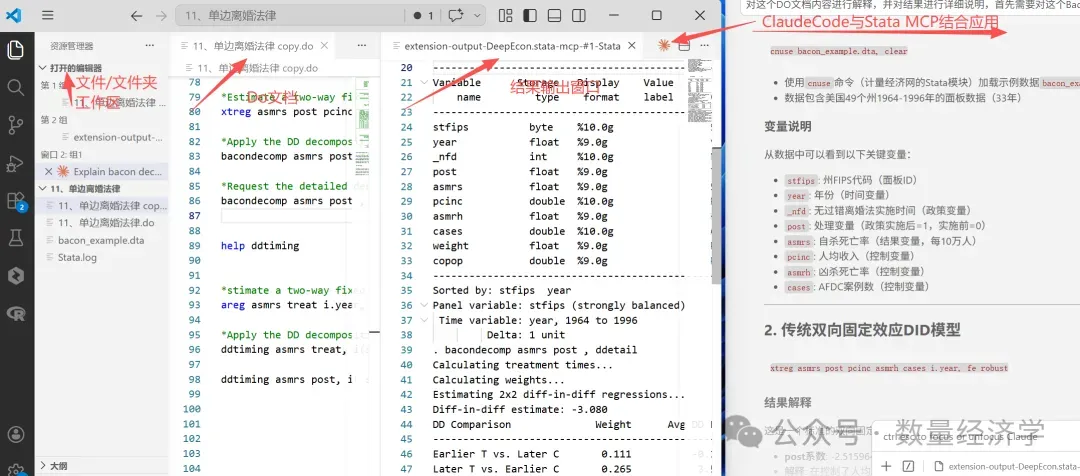
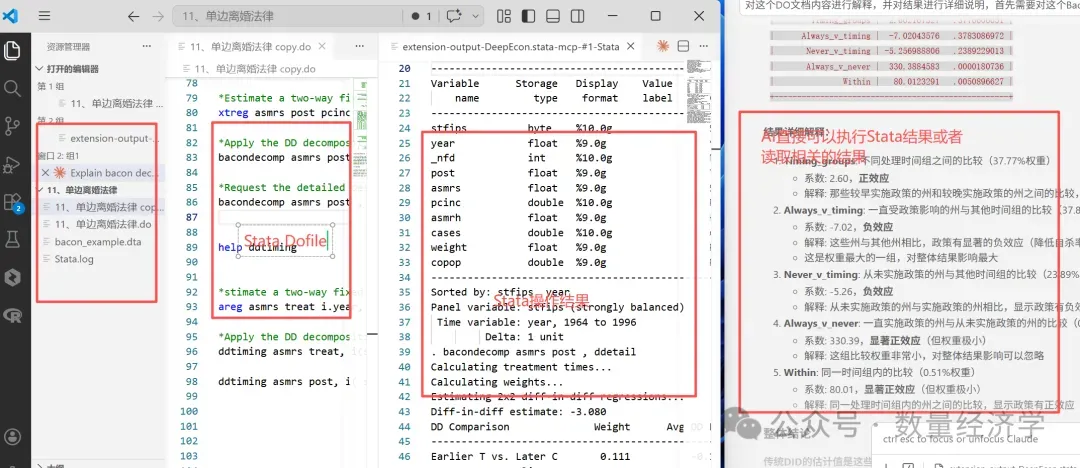
一个成熟的实证研究者,完全可以在不同阶段用不同工具:前期探索用AI Agent加速学习,中期验证用Stata原生确保可复现,后期展示用Jupyter生成一体化报告。工具之间不是谁替代谁的关系,是搭配使用的关系。
那么,高级用户为什么没有全部切到StataMCP?这个问题背后没有”保守”二字,全是务实的考量。已经内化的技能,AI反而慢——reg y x, robust这种肌肉记忆级别的操作,手写比”描述需求、等AI生成、检查、执行”快得多。Stata原生的结果展示体系三十多年打磨出来,esttab一键出出版级表格,Log文件构成完整的分析审计链,换到AI Agent工作流里反而要多花精力配置。代码和结果不能并排看,也是个实际痛点:StataMCP在VS Code或Trae里跑完代码,结果出现在交互窗口或输出面板,跟代码不在同一个视图里。此外,AI Agent工作流需要IDE、MCP服务器、API服务、网络,缺一不可,迁移成本不小。而如果只是想要代码和结果一体化展示,Jupyter + PyStata本身就是成熟方案,不需要AI介入。
不过,这些短板大多是工程层面的,不是原则性的。StataMCP迭代很快,交互窗口嵌进了VS Code面板,上下文工程的研究也在推进。务实的选择是:现在就用,但清楚它的边界在哪。
五、计量经济学科研范式正在被重塑
当下的计量经济学,恰好站在科研范式转变的交叉路口。
因果推断革命以Angrist、Imbens、Card等诺贝尔奖得主为代表,DID、RDD、IV、合成控制这些方法论在过去二十年彻底改写了实证研究的游戏规则,研究者的核心竞争力从”会估计参数”变成了”会识别因果”。机器学习革命则将Double Machine Learning、Causal Forest、异质性处理效应等方法推向主流,Stata 19正式集成的H2O机器学习模块就是明证。而AI编程革命——以StataMCP为代表——正在把研究者从编码的琐碎中解放出来。上述发展叠加的效果不是线性的:因果推断提供了方法论框架,机器学习扩展了工具箱,AI编程降低了执行成本。研究者终于可以把主要精力放在”想清楚”上,而不是”写出来”上。
面对这样的变局,教材改革已经势在必行。一些走在前面的计量经济学家提出了明确的方向:以因果推断为主线组织内容,让学生从第一天就建立”相关不等于因果”的思维;把机器学习、非参数方法、异质性处理效应融进正文,而不是塞在”扩展阅读”里;按”研究问题→识别策略→估计方法→稳健性检验”这条研究者的真实工作链来编排,而不是按”OLS→GLS→IV→面板→时间序列”的传统线性结构。软件上以Stata为主、R或Python为辅,着力降低入门门槛。
数量经济学–AI-Stata-Python-R前沿系列公开课–本周免费直播里面介绍到近年来国外因果推断前沿专家在专题研讨会上介绍面板数据/因果推断等前沿,都还采用的有R软件或Python软件,例如
-
Difference-in-Differences workshop at LSU -
Difference-in-Differences Talk at Camp -
NEXT-D Workshop -
Workshop on Research Design for Causal Inference
Stata、R、Python这些软件工具,与Markdown、Beamer、Overleaf、Latex等软件工具的交互,正在被 AI Agent打破。
AI+Stata3.0 节选!从”喂代码”到”一句话”:我用AI爬了4300多条SSC命令,全程没碰网页源代码
六、拥抱变化,守住判断
回到最初的问题:AI Agent时代的Stata工作流,到底该怎么看?
态度很简单:能用就用,该守就守。
在初学入门、探索分析、批量操作、语法查询这些场景里,AI Agent的效率优势是实实在在的,没必要因为”还不够完美”就拒绝。技术工具的成熟从来不是等出来的,是用出来的。但研究设计、因果识别、机制分析、结果审视,这些需要深度思考和专业判断的环节,AI做不了,也不应该让AI做。Stata原生的稳定性和可复现性,在正式研究中仍然不可替代。
更根本的一点是:当编码不再是瓶颈,研究者之间的差距就完全取决于思维深度。AI时代给实证研究者带来的最大机会,不是让你更轻松,而是让你有机会把精力全部投入到真正重要的事情上——学科直觉、研究判断力、批判性思维。这三样东西,没有捷径,只能靠长期的文献积累、实战打磨和持续思考来获得。AI可以帮你省下写代码的时间,但没法帮你省下想问题的时间。
而这,恰恰是好消息。
参考资源:
-
Stata-MCP (hanlulong): github.com/hanlulong/stata-mcp -
Stata-MCP (SepineTam): github.com/SepineTam/stata-mcp -
Stata-MCP研究报告: statamcp.com -
PyStata官方文档: stata.com/features/overview/pystata -
Trae IDE: trae.com.cn
