 夜雨聆风
夜雨聆风





给 AI 喂文档太麻烦?微软开源神器,几行代码统一转成标准 Markdown
-
PyPI 官方页面(https://pypi.org/project/markitdown/)无法正常访问,提示“Oops, something went wrong. Please check your connection, disable any ad blockers, or try using a different browser.”,建议优先通过 GitHub 源代码安装;
-
hatch 安装链接(https://hatch.pypa.io/dev/install/)可正常访问,以下将补充该链接内的详细安装方法,替代原“通过 Python 官方渠道获取”的表述。
-
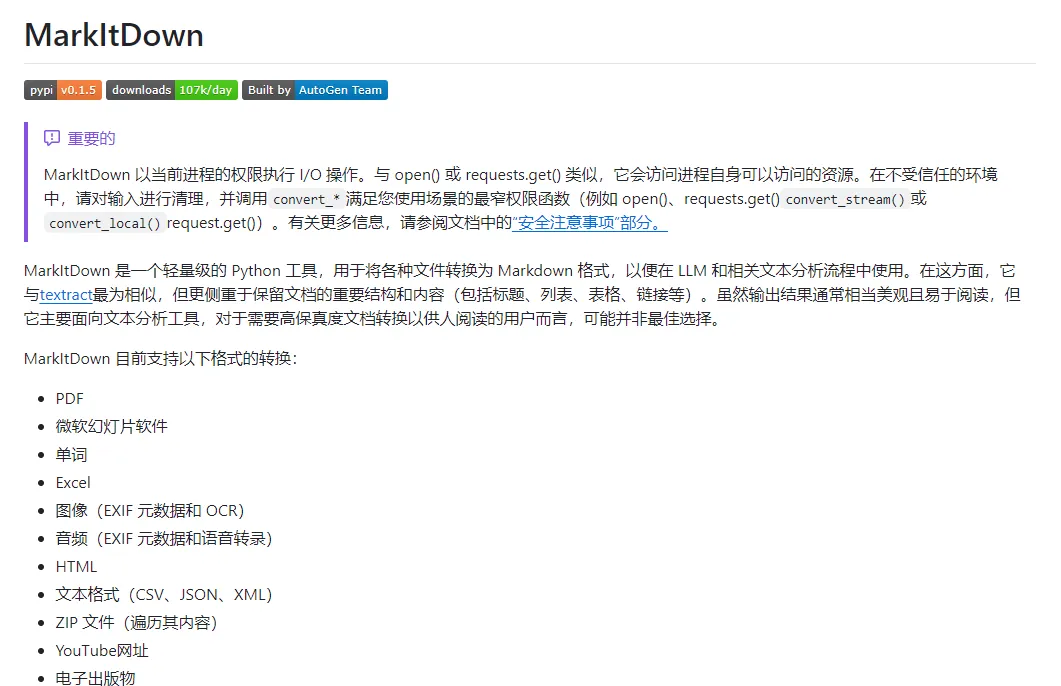
文档类: Word(DOC/DOCX,可保留标题格式、列表、表格,支持提取批注)、Excel(XLS/XLSX,支持表格结构保留,可解决格式化单元格的货币提取问题)、PPT(PPTX,可提取文本、图片,支持通过 LLM 生成图片描述)、HTML(可提取网页文本及链接结构)、PDF(支持文本提取、表格提取,可通过插件实现 OCR 识别嵌入式图片文本)、ZIP(可遍历压缩包内所有文件并逐一转换)。
-
多媒体类: 图像(支持 EXIF 元数据提取和 OCR 文本识别,需搭配 LLM 客户端)、音频(支持 EXIF 元数据提取和语音转写,需安装对应可选依赖)。
-
结构化数据: CSV、JSON、XML 等文本格式,转换后保留原始数据结构。
-
其他格式: Youtube 链接(可提取视频字幕转写内容)、EPub 电子书(提取文本内容及章节结构),社区正持续贡献旧版 PPT、EML 邮件、ODT 文件等新格式支持。
-
集成大型语言模型(如 GPT-4o),可自动生成图像描述或优化文本内容,搭配 markitdown-ocr 插件可实现嵌入式图片的 OCR 文本提取,无需额外安装机器学习库或二进制依赖。
-
支持 Docker 容器化部署,简化环境依赖,可避免 Python 依赖冲突,目前社区正推进 Docker 多阶段构建优化,区分开发环境和生产环境,后续可获取更轻量的生产级镜像。
-
可集成 Azure 文档智能服务(原 Form Recognizer),实现更高精度的文档转换,尤其适合复杂格式、多语言的文档提取,有效解决原生转换器精度不足的问题。
-
支持插件扩展,可通过第三方插件实现功能增强,如 OCR 优化、新格式支持等,插件默认禁用,可通过命令行启用。
-
Python 3.10 及以上版本(注:原架构提及的 Python 3.8 及以上版本,结合工具实际要求,建议使用 3.10+ 以避免兼容性问题);
-
pip(Python 包管理器);
-
建议使用虚拟环境(如 venv、uv、Anaconda)安装,避免依赖冲突;若需使用 hatch 工具进行测试,可参考以下详细安装方法。
-
标准 Python 命令:python -m venv .venv
-
激活命令根据系统不同有所差异 -
Linux/macOS:source .venv/bin/activate; -
Windows 命令提示符: .venvScriptsactivate; Windows PowerShell:.venvScriptsActivate.ps1);
-
uv 工具: uv venv –python=3.12 .venv,激活后建议使用 uv pip install 安装包;
-
Anaconda:conda create -n markitdown python=3.12,conda activate markitdown。
-
pip 安装(简单便捷,注意可能存在依赖冲突):
`pip install hatch``pipx install hatch`-
Homebrew 安装(macOS 系统):
`brew install hatch`-
Conda 安装:
`conda install -c conda-forge hatch`mamba:`mamba install hatch`-
系统专属安装(macOS/Windows):
-
macOS:通过 curl 下载安装包并安装
curl -Lo hatch-universal.pkg https://github.com/pypa/hatch/releases/latest/download/hatch-universal.pkgsudo installer -pkg ./hatch-universal.pkg -target /
-
Windows:通过 msiexec 命令静默安装(64位系统)
`msiexec /passive /i https://github.com/pypa/hatch/releases/latest/download/hatch-x64.msi`pip install 'markitdown[all]'pip install markitdowngit clone git@github.com:microsoft/markitdown.git
cd markitdown
pip install -e 'packages/markitdown[all]'# 方式1:输出到指定 Markdown 文件
markitdown test.xlsx > test.md
# 方式2:使用 -o 参数指定输出文件(更规范,推荐)
markitdown test.xlsx -o test.md# 先安装插件及 LLM 客户端
pip install markitdown-ocr
pip install openai
python
# 使用 Python API 转换(支持 OCR 识别)
from markitdown import MarkItDown
from openai import OpenAI
md = MarkItDown(
enable_plugins=True,
llm_client=OpenAI(),
llm_model="gpt-4o", # 需使用支持视觉能力的 LLM 模型
)
result = md.convert("包含图片的文档.pdf")
# 保存转换结果
with open("输出文档.md", "w", encoding="utf-8") as f:
f.write(result.text_content)cat 目标文件.pdf | markitdownmarkitdown 目标文件.pdf -o 输出文件.md -d -e "<document_intelligence_endpoint>"-
批量转换: 通过命令行实现 CI/CD 集成,批量处理文件夹内所有 PDF 文件,可直接复制使用的实操命令:
# 批量转换 ./docs 目录下所有 PDF 文件,输出为 原文件名.pdf.mdfind ./docs -name '*.pdf'; | xargs -I{} markitdown {} -o {}.md# 批量转换 ./docs 目录下所有 Word 文件,输出到指定文件夹find ./docs -name '*.docx'; -exec markitdown {} -o ./output/{}.md ;
-
数据湖预处理: 将散落的 Excel 报表、会议录音、邮件附件等统一转换为 Markdown 格式,实操命令:
# 批量转换 Excel 报表(支持 xls/xlsx 格式)find ./reports -name '*.xlsx' -o -name '*.xls' | xargs -I{} markitdown {} -o {}.md# 转换音频文件(需先安装音频依赖:pip install 'markitdown[audio-transcription]')markitdown 会议录音.mp3 -o 会议录音文字稿.md
-
文档管理优化: 将企业内部的 Word 手册、PPT 汇报材料转换为 Markdown,便于跨平台查看,实操命令:
# 转换 Word 手册并保留批注markitdown 企业手册.docx -o 企业手册.md# 转换 PPT 汇报材料,生成图片描述(需配置 LLM 客户端)markitdown 项目汇报.pptx -o 项目汇报.md --llm-model gpt-4o
-
论文解析: PDF 转换后可直接提取方法论、实验数据、参考文献等核心内容,实操命令:
# 转换普通 PDF 论文markitdown 学术论文.pdf -o 论文解析.md# 转换扫描版 PDF 论文(启用 OCR 识别,需先安装插件)markitdown 扫描版论文.pdf -o 扫描论文解析.md --use-plugins --llm-model gpt-4o
-
教材数字化: 保留原始公式与图表引用,转换后适配 Anki 等记忆工具,实操命令:
# 转换 EPub 教材markitdown 专业教材.epub -o 教材笔记.md# 转换 PDF 教材,保留公式格式markitdown 数学教材.pdf -o 数学教材笔记.md
-
跨平台发布: Word 文档转换为 Markdown 后,无缝发布至 GitHub、Notion 等平台,实操命令:
# 转换 Word 文章,保留标题和列表格式markitdown 公众号文章.docx -o 公众号文章.md# 转换 HTML 网页内容,提取核心文本markitdown https://xxx.com/article.html -o 网页文章.md
-
多媒体处理: 播客、会议录音自动生成带时间戳的文字稿,图片生成描述,实操命令:
# 转换播客音频,生成带时间戳的文字稿markitdown 播客节目.mp3 -o 播客文字稿.md --audio-timestamp true# 转换图片,生成详细描述(需配置 LLM 客户端)markitdown 图文素材.jpg -o 图片描述.md --llm-model gpt-4o
-
知识库构建: 将企业手册、产品文档等多格式文件转换为 Markdown,供 RAG 模型训练,实操命令:
find ./company-docs -name '.pdf' -o -name '*.docx' -o -name '*.xlsx' | xargs -I{} markitdown {} -o ./rag-data/{}.md# 转换 ZIP 压缩包内所有文档markitdown 企业文档包.zip -o 文档包转换结果.md
-
多模态输入: 图片描述 + 音频转录 + 文档内容,形成复合上下文,实操命令:
# 转换图片生成描述markitdown 产品图片.jpg -o 图片描述.md --llm-model gpt-4o# 转换音频生成文字稿markitdown 产品介绍音频.mp3 -o 音频文字稿.md# 合并多模态内容(可结合 shell 命令)cat 图片描述.md 音频文字稿.md 产品手册.md > 多模态上下文.md
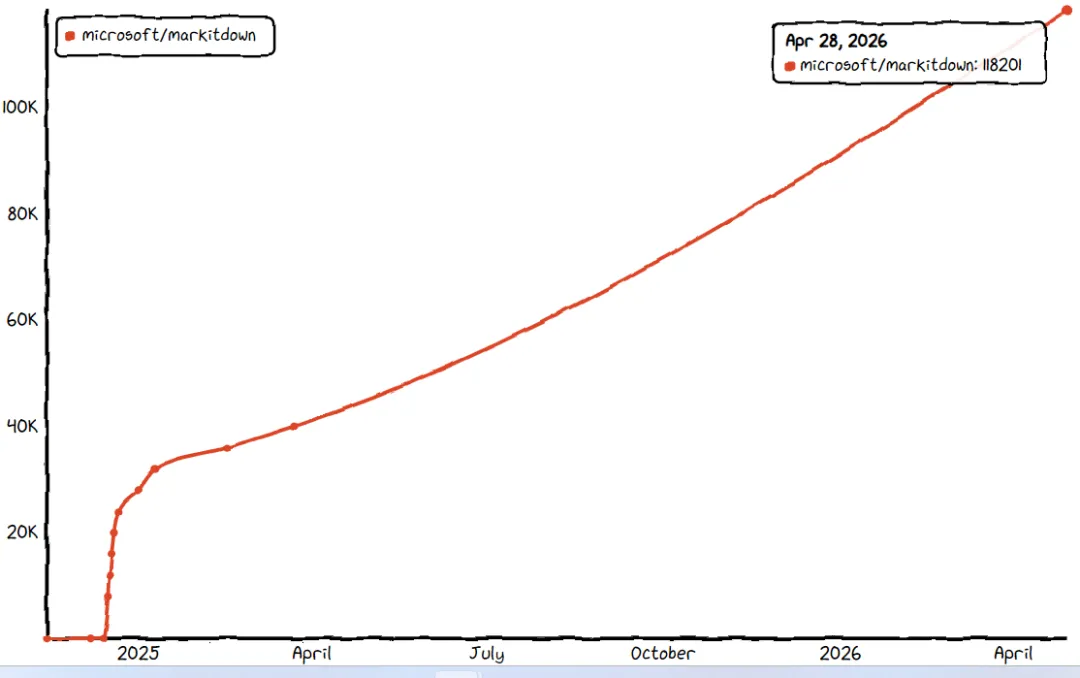
https://www.star-history.com/microsoft/markitdown-
Claude Code 团队落地指南:一套可复制的 配置方案 -
Remotion 最强竞品!用 HTML 写视频,AI 自动成片 -
51K+ Star 谁用谁爽!ClaudeCode 最强辅助工具终于被我找到了 -
告别手动拖拽!AI 一键生成架构图!官方开源项目彻底解放双手 -
生化危机女主跨界开源,用记忆宫殿重构AI记忆 -
暴击设计行业!Claude Design系统提示词在 GitHub 上全泄露了 -
GitHub上爆火的AI投研神器!免费解锁彭博终端所有核心功能 -
别再盯 AI 写代码了!让 AI 当你真正队友 -
单人靠 AI 也能做出专业级游戏,零成本拥有 49 人游戏研发团队 -
GitHub 上一路飙到 4.5 万 Star 的 Claude Code 最佳实践,开源了! -
最值得装的8个AI Skill,覆盖联网、自动化、安全场景 -
GitHub 周榜持续封神!凭什么碾压 OpenClaw 成开发者新宠 -
Google大神开源谷歌工程最佳实践,让AI编程智能体写出生产级优质代码
-
这个开源工具太猛了!让 Claude Code 成本爆降 89% -
省71.5倍Token!AI编码时代,让你的代码变成多模态的知识图谱 -
Claude Code 不写代码!直接帮你找工作,打造 AI 求职全流程指挥中心 -
Claude Code 为开发者提供即插即用的垂直领域专家级 AI 助手
-
从决策、执行到记忆复利:gstack + Superpowers + CE 完整实战 -
遵循 Google 官方格式,一键复用大厂设计! -
炼化同事、反蒸馏、老板、自己……全都被封装成AI插件 -
史上最快突破 100K+ 星标!Claw Code 开源解析!
终身学习,深耕AI领域
持续分享,优质AI开源