 夜雨聆风
夜雨聆风





AI 语音的寒武纪爆发:从"听清你说话"到"比你更懂你的声音"
四件事,同一周发生

AI 语音三大突破:听、说、跑
最近一周,AI 语音领域密集发生了四件事:
微软把一个 2.47GB 的语音识别模型压缩到了 670MB——体积砍掉 73%,准确率只掉了 0.17 个百分点。端侧语音识别,真的能用了。
阿里通义发布 FunASR 1.5,方言识别准确率相比上一版下降了 56.2%(字错误率)。5 种方言突破 90%,15 种方言超过 80%。七大方言体系全覆盖,连温州话都能听懂了。
面壁智能+清华开源 VoxCPM 2,一个 2B 参数的语音大模型:30 种语言、9 种中国方言、48kHz 高保真音质。最炸的功能——你可以用文字描述来”凭空创造”一个从未存在过的声音。
sherpa-onnx 框架让 SenseVoice 模型跑在了普通安卓手机上。10 秒音频只需 70ms 识别,比 Whisper 快 15 倍。12 种编程语言、几乎所有平台都能部署。
四件事指向同一个结论:AI 语音正在经历寒武纪大爆发。
第一波:听——从”听清普通话”到”听懂每一个中国人”
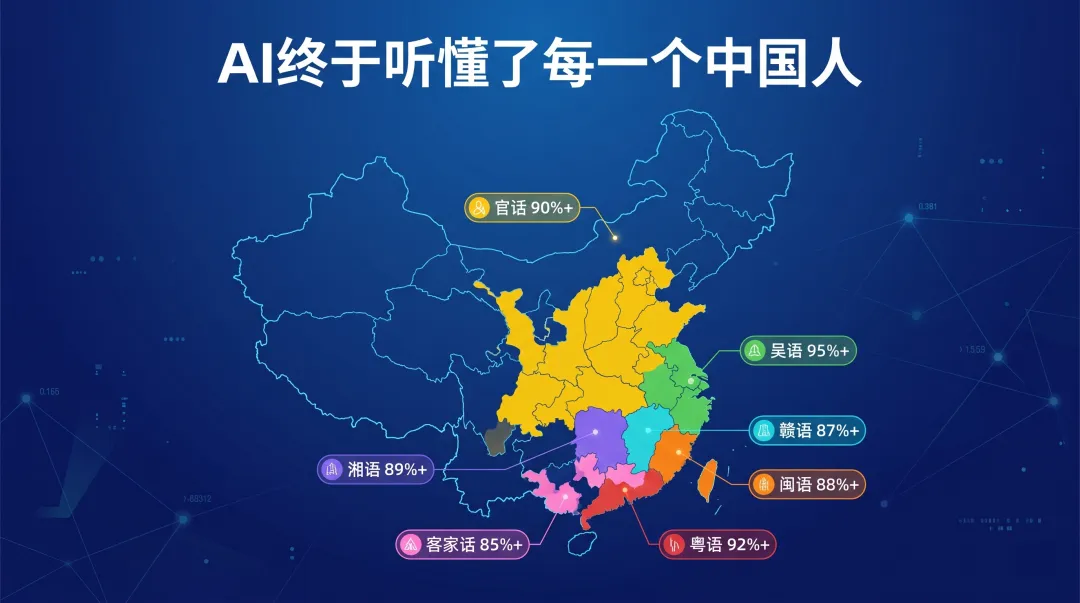
AI 终于听懂了每一个中国人:七大方言全覆盖
语音识别(ASR,自动语音识别)做了这么多年,普通话识别率早就卷到了 97%、98%。
但一换方言,准确率直接腰斩。
这不是小问题。中国有七大方言体系、几百种地方口音。你在上海的客服中心接到一个温州客户的电话,AI 听不懂;你在四川的养老院给老人做语音助手,AI 听不懂;你在广东的法院做庭审记录,AI 听不懂。
阿里 FunASR 1.5 把这个瓶颈打开了。
它覆盖了汉语七大方言体系——官话、吴语、湘语、赣语、客家话、闽语、粤语,还对 20 多种地方口音做了适配:河南、陕西、四川、重庆、云南、广东、广西、天津、山东、安徽、南京、杭州……
连温州话都能识别了。温州话在坊间被叫做”鬼话”,连浙江其他地方的人都听不太懂。
更厉害的是混合语种识别。你在一段话里先说中文,突然蹦一句英文,又切回中文夹个日语词——AI 不需要你提前告诉它”接下来是英文”,它自己就能识别并正确切换。这个能力叫 Code-Switching(语码转换),以前需要多个模型配合才能做到,现在一个模型搞定。
还有一个让人意外的功能:古诗词识别,准确率 97%。 给 AI 念一首《春江花月夜》,从”春江潮水连海平”到”不知乘月几人归”,几乎一个字不差。
千年的韵律被现代技术听懂了。这件事本身就挺浪漫的。
第二波:说——从”机器朗读”到”凭空造声”
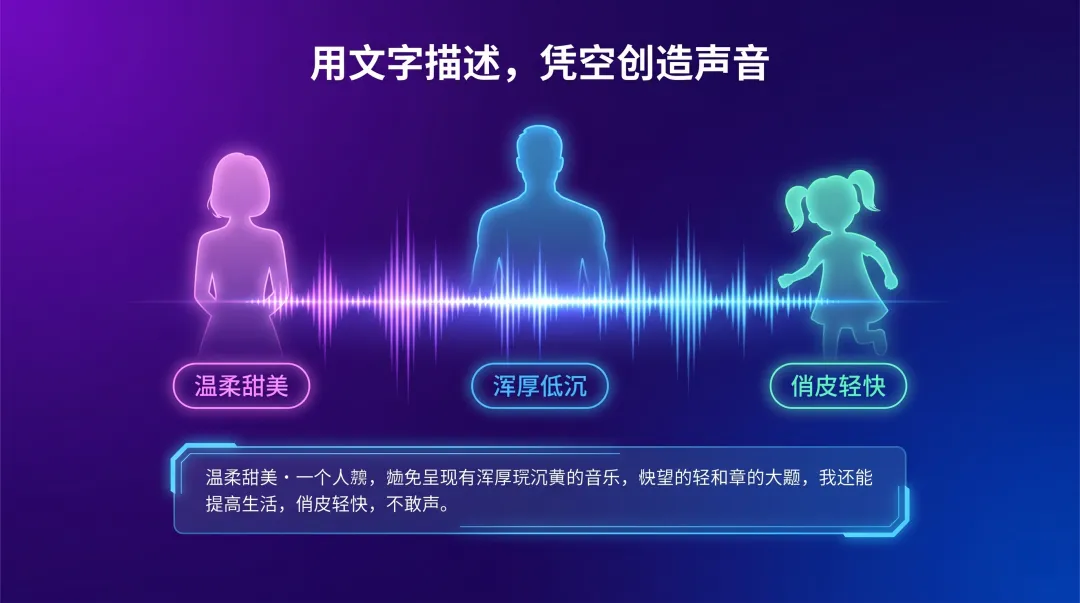
用文字描述,凭空创造声音
如果说语音识别是”AI 学会了听”,那语音合成(TTS,文本转语音)就是”AI 学会了说”。
面壁智能的 VoxCPM 2 把”说”这件事推到了一个新高度。
以前的语音合成是什么样的?给你几个预设音色——”温柔女声””磁性男声””新闻播报”——你在里面挑一个。
VoxCPM 2 不一样。你可以用文字描述来创造一个全新的、从未存在过的声音。
比如你输入:”年轻女性,温柔甜美,语速偏快,带一点俏皮。”
AI 就会生成一个符合这个描述的声音。每次生成还会有微妙的随机变化——相当于每次都在给你匹配一个不同的 AI 声优。
这个能力叫音色设计(Voice Design)。它打开的想象空间非常大:
• 游戏里每个 NPC(非玩家角色)都有独一无二的声音
• 有声书里每个角色都有专属音色,不再是一个人分饰多角
• 客服系统可以根据品牌调性定制专属声音
• 教育产品可以为不同年龄段的学生匹配最合适的声音
从”选声音”到”造声音”,这是质的飞跃。
VoxCPM 2 还支持声音克隆——上传 5 秒以上的音频,AI 就能复制这个音色,用它念出任何文本。而且克隆不只是复制,你还可以改变情绪和语速。上传一段日常说话的录音,加一句”语速很快,清亮饱满”,AI 就会保留原音色,但以你想要的语气来播报。
30 种语言、9 种中国方言、48kHz 高保真——这是开源模型,免费的。
第三波:跑——从”云端专属”到”手机就能用”

从云端到端侧:语音 AI 的部署革命
以前跑语音识别,要么接云端 API(准但慢,还有隐私问题),要么本地跑大模型(Whisper Large 占 2G 显存,卡成 PPT)。
微软这篇论文和 sherpa-onnx 框架,把端侧语音识别变成了现实。
微软做了什么?他们发现一个反直觉的事实:排行榜上跑分最高的模型,到了真实的流式场景直接崩。
比如 Qwen3-ASR,批处理词错率只有 5.9%,听起来很猛。但切到 2.4 秒分块的流式识别后,直接飙到 10.45%——几乎翻倍。
为什么?因为大部分模型的训练数据都是完整句子。你给它喂 2.4 秒一段的碎片,前后文断了,模型就懵了。
真正的端侧之王是英伟达的 Nemotron-0.6B。它的”缓存感知”架构天生为流式设计——边听边记住前面的内容,偶尔偷看一眼后面的音频再下结论。从批处理切到流式,准确率几乎没掉(8.03% → 8.20%)。
微软把这个模型用 int4 量化从 2.47GB 压到 670MB,在普通笔记本上就能实时跑。
sherpa-onnx 更进一步——让阿里的 SenseVoice 模型跑在了普通安卓手机上。10 秒音频 70ms 识别完毕,比 Whisper 快 15 倍。支持 12 种编程语言、几乎所有平台。
这意味着什么?语音识别不再需要联网,不再需要高端设备,不再需要付 API 费用。你的手机、你的树莓派、你的智能音箱,都可以本地跑语音识别了。
三条赛道同时爆发,意味着什么?
把这三波放在一起看,先看一张全景排行榜:
语音识别(ASR)主流模型对比
| 模型 | 开发者 | 中文 WER | 方言支持 | 流式支持 | 端侧部署 | 开源 |
|---|---|---|---|---|---|---|
| FunASR 1.5 | 阿里通义 | ~3% | 七大方言+20种口音 | 是 | 是 | 是 |
| SenseVoice | 阿里 | ~3% | 粤语优秀 | 是 | 是(70ms) | 是 |
| Whisper Large V3 | OpenAI | ~5% | 有限 | 否 | 困难(2G+) | 是 |
| Nemotron-0.6B | 英伟达 | ~8% | 无 | 原生支持 | 是(670MB) | 是 |
| Qwen3-ASR | 阿里 | ~4% | 有限 | 差(翻倍退化) | 困难 | 是 |
| Paraformer | 阿里 | ~4% | 有限 | 是 | 是 | 是 |
语音合成(TTS)主流模型对比
| 模型 | 开发者 | 语言数 | 音色设计 | 声音克隆 | 采样率 | 开源 |
|---|---|---|---|---|---|---|
| VoxCPM 2 | 面壁+清华 | 30 | 文字描述造声 | 5秒克隆 | 48kHz | 是 |
| GPT-4o Voice | OpenAI | 50+ | 预设音色 | 否 | – | 否 |
| ElevenLabs | ElevenLabs | 30+ | 有限 | 是 | 44.1kHz | 否 |
| Fish Speech | 社区 | 中英日 | 否 | 是 | 44.1kHz | 是 |
| Kokoro-82M | 社区 | 英语为主 | 否 | 否 | 24kHz | 是 |
| CosyVoice | 阿里 | 中英日韩 | 有限 | 是 | 22kHz | 是 |
几个关键发现:
ASR 赛道:中国团队(阿里)在中文和方言识别上已经全面领先。FunASR 1.5 和 SenseVoice 的中文准确率远超 Whisper。但英伟达的 Nemotron 在端侧流式场景独占鳌头。
TTS 赛道:VoxCPM 2 是目前开源 TTS 的天花板——30 语言、音色设计、声音克隆、48kHz 全部拉满。闭源的 ElevenLabs 和 GPT-4o Voice 在自然度上仍有优势,但差距在快速缩小。
共同趋势:开源正在追平闭源,端侧正在追平云端,中文正在追平英文。
GitHub 热门语音 AI 项目(截至 2026 年 4 月)
| 项目 | Star 数 | 类型 | 一句话介绍 |
|---|---|---|---|
| OpenAI Whisper | 98,588 | ASR | 语音识别的”GPT 时刻”,开源标杆 |
| Real-Time-Voice-Cloning | 59,645 | 克隆 | 5 秒克隆声音,实时生成语音 |
| GPT-SoVITS | 57,027 | TTS+克隆 | 1 分钟音频训练语音模型,中文社区最火 |
| MockingBird | 36,900 | 克隆 | 中文语音克隆先驱 |
| OpenVoice | 36,342 | 克隆 | MIT 出品,即时声音克隆 |
| ebook2audiobook | 18,765 | TTS 应用 | 电子书转有声书,支持 1158 种语言 |
| VoxCPM 2 | 16,148 | TTS | 面壁+清华,30 语言+音色设计+声音克隆 |
| FunASR | 15,889 | ASR | 阿里通义,方言识别突破 90% |
| Qwen3-TTS | 11,032 | TTS | 通义千问语音合成,端到端架构 |
几个值得关注的趋势:
声音克隆是最火的方向。 前五名里有三个是声音克隆项目。GPT-SoVITS 只需 1 分钟音频就能训练出一个语音模型,在中文社区极其火爆。
中国团队占据半壁江山。 FunASR、VoxCPM 2、Qwen3-TTS、GPT-SoVITS、MockingBird——热门项目里中国团队的比例远超其他 AI 领域。语音 AI 是中国开源力量最强的赛道之一。
端到端模型是新方向。 Qwen3-TTS 和 GPT-4o Voice 代表了一个新趋势:不再走”语音→文字→理解→文字→语音”的老路,而是直接在音频层面做理解和生成。这会让语音交互的延迟和自然度再上一个台阶。
把这三波放在一起看,你会发现一个清晰的趋势:
| 能力 | 过去 | 现在 |
|---|---|---|
| 听(识别) | 只听得懂普通话 | 七大方言 + 30 种语言 + 混合语种 |
| 说(合成) | 几个预设音色选一个 | 用文字描述凭空创造声音 |
| 跑(部署) | 必须云端 API | 手机本地实时运行 |
| 成本 | 按调用次数收费 | 开源免费,本地部署零成本 |
AI 语音正在从”云端的、昂贵的、只听得懂普通话的工具”,变成”本地的、免费的、听得懂每一个人的基础设施”。
这个变化的速度快得惊人。半年前,方言识别还是实验室里的论文;现在,它已经是”工业级可用”了。半年前,语音克隆还需要几分钟的参考音频;现在,5 秒就够了。半年前,端侧语音识别还是”能跑但不能用”;现在,手机上 70ms 就能出结果。
这对我们意味着什么?五个判断
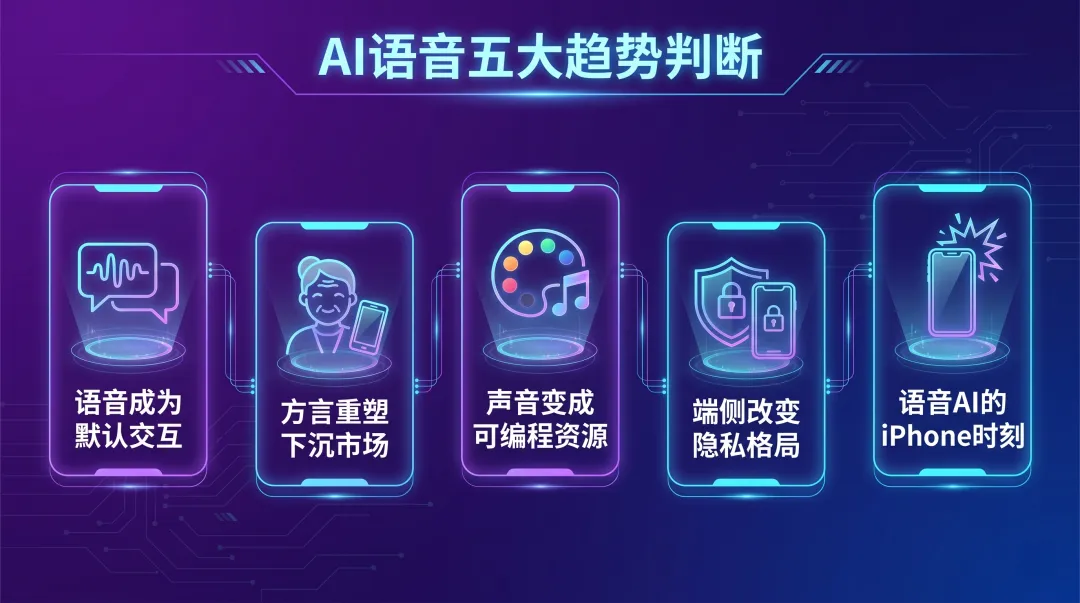
AI 语音五大趋势判断
判断一:语音将成为 AI 的默认交互方式
现在大部分人和 AI 交互还是靠打字。但打字是反人性的——人类天生就是用语音交流的物种。
当语音识别足够准、语音合成足够自然、延迟足够低的时候,打字会变成 AI 交互的”命令行”——高级用户用,但大部分人会直接说话。
这和我们之前讨论的 Flipbook 文章里的判断一致:聊天框会退居二线,更自然的交互方式会成为主流。语音就是最自然的交互方式之一。
判断二:方言识别会重塑下沉市场
中国有 10 亿人不以普通话为母语。他们中的很多人——尤其是老年人——说普通话不流利,甚至完全不会说。
当 AI 能听懂方言的时候,这 10 亿人第一次可以无障碍地使用 AI 服务。
• 县域的政务热线可以自动记录和转写方言来电
• 农村的老人可以用方言和智能音箱对话
• 地方医院的问诊系统可以听懂患者的方言描述
• 方言文化纪录片可以自动生成字幕
方言识别不只是技术进步,它是数字包容。
判断三:声音将变成可编程的资源
VoxCPM 2 的”音色设计”功能,本质上是把声音变成了一种可编程的资源。
以前,声音是稀缺的——你需要找真人配音演员,按小时付费。现在,你可以用一段文字描述来创造无限种声音。
这会催生一批新的应用场景:
• 个性化教育:每个学生的 AI 老师都有不同的声音和语气,内向的学生配温柔的声音,活泼的学生配有活力的声音
• 情感陪伴:AI 伴侣可以有独一无二的声音,而不是千篇一律的”AI 女友音”
• 品牌声音:每个品牌都可以拥有专属的 AI 声音,就像品牌有专属的 logo 和色彩一样
• 无障碍服务:为视障人士定制最舒适的阅读声音
判断四:端侧部署会改变隐私格局
语音数据是最敏感的个人数据之一。你的声音里包含了你的身份、情绪、健康状态、甚至你的位置(通过口音判断)。
当语音识别必须上传到云端时,隐私风险是不可避免的。但当语音识别可以完全在本地运行时,你的声音数据永远不需要离开你的设备。
微软的 670MB 模型和 sherpa-onnx 的手机部署,让这个愿景变成了现实。
对于医疗、法律、金融等对隐私要求极高的行业,端侧语音识别不是”可选项”,而是”必选项”。
判断五:语音 AI 的”iPhone 时刻”正在到来
回顾历史,每一次交互方式的变革都催生了巨大的产业机会:
• 键盘 → 鼠标(1984,Macintosh)→ 图形界面应用爆发
• 鼠标 → 触屏(2007,iPhone)→ 移动应用爆发
• 触屏 → 语音(2026,正在发生)→ ?
当语音识别准确率突破 97%、语音合成自然度接近真人、端侧部署成本趋近于零的时候,语音交互的”iPhone 时刻”就到了。
接下来会爆发的,不是”语音助手”这种已有品类的升级,而是全新的、我们现在想象不到的产品形态。
就像 2007 年没人能想到”15 秒短视频”会成为移动互联网最大的应用一样。
结语
AI 语音正在经历三个”从…到…”的转变:
从听清到听懂——不只是识别文字,而是理解方言、情感、语境。
从模仿到创造——不只是复制声音,而是凭空设计全新的声音。
从云端到本地——不只是能用,而是随时随地、零成本、零隐私风险地用。
这三个转变加在一起,意味着语音正在从”AI 的一个功能”变成”AI 的基础设施”。
未来的 AI 不会只是一个你打字交流的聊天框。它会听你说话、用你喜欢的声音回应你、记住你的口音和习惯、在你的手机上本地运行。
当 AI 学会了听、学会了说、学会了在你身边运行——人机交互的下一个时代,就真的开始了。
作者:张震 · 公众号「进化三部曲」
参考来源:
– 微软端侧 ASR 压缩论文:Nemotron-0.6B int4 量化(2026.4)
– 阿里通义 FunASR 1.5:方言识别突破 90%(2026.4)
– 面壁智能 VoxCPM 2:30 语言 + 音色设计 + 声音克隆(2026.4)
– sherpa-onnx + SenseVoice:手机端侧语音识别部署(2026.4)