夜雨聆风
夜雨聆风





国家数据局出手:高质量数据正在成为AI竞争的关键资源

4月15日,国家数据局发布《关于推进行业高质量数据集建设行动的实施方案(征求意见稿)》,明确提出形成“场景牵引数据、数据驱动模型、模型赋能应用、应用创造价值”的“数据飞轮”。
这份文件释放了两个关键信号:
第一,高质量数据的战略地位正在提升。 专业、可用的数据,将在AI产业链中发挥关键作用。
第二,企业内部沉睡的行业数据,将被重新整理、标注、变现。 数据正在从“成本”走向“资产”。
而且,文件发出仅一周后,地方已经行动起来。

ONE
政策出台一周,地方已经“动”了
4月23日,江苏无锡召开全省高质量数据集建设推进会。
会上公布了实打实的成果:全省已形成高质量数据集521个,数据总规模超95PB;25个重点项目集中签约,总金额达5.26亿元。
同时,全国首个省级高质量数据集普惠认证评测工作正式启动。这意味着,“好数据”开始有了“合格证”——可以衡量、可以认证、可以流通。
此外,无锡市首批“数据券”正式兑现,企业可以用数据券购买数据服务,政府补贴、市场运作,降低企业用数门槛。
从中央文件到地方签约,只用了8天。 这不是口号,这是正在发生的产业变革。

TWO
为什么数据正在成为AI的新焦点?
过去两年,行业的聚光灯一直打在大模型身上:谁参数大、谁跑得快、谁融资多。
但现在,瓶颈正在转移。

行业专家指出,无标签语料对模型性能提升的贡献正在减弱。更大规模数据带来的性能提升,与训练开销相比,性价比显著降低。
好模型不缺,缺的是“好数据”。
而“好数据”从哪里来?从专业的数据服务商来。
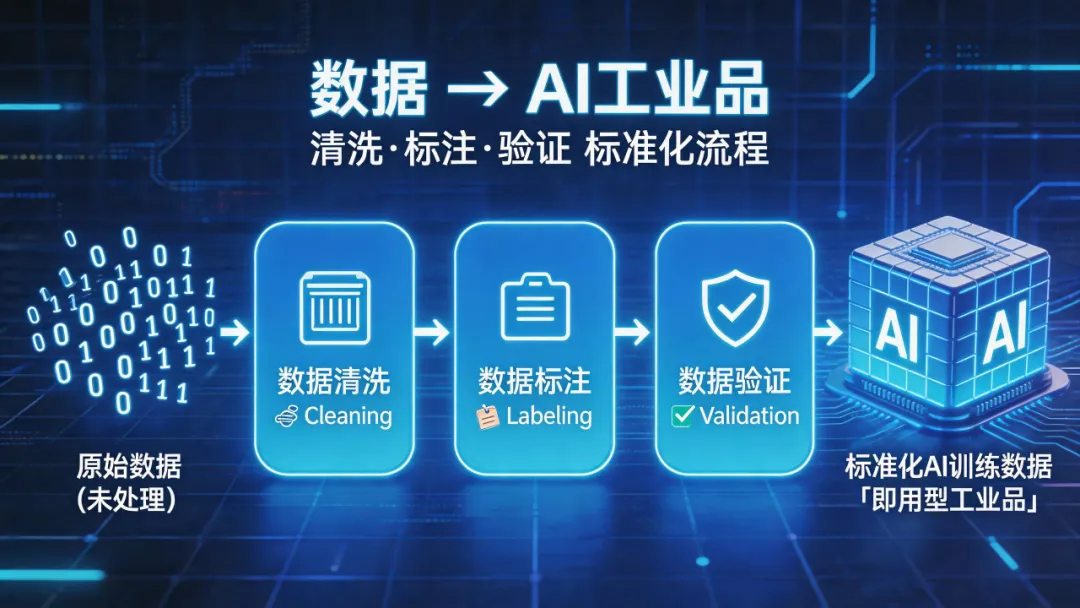
根据征求意见稿,行业高质量数据集是“经过采集、加工等数据处理,可直接用于开发和训练人工智能模型,并能有效提升模型、智能体、智能终端等应用效能的行业数据集合”。
这不是简单地把数据存起来,而是要把数据变成标准化的“工业品”——清洗过、标注过、验证过,拿过来就能训练模型。
能够提供这类高质量数据的企业,正在成为AI产业链中不可或缺的一环。
THREE
行业数据将被重新“洗一遍”
文件释放的另一个重要信号是:企业内部那些沉睡的数据,很快会被重新整理、标注、变现。
这实际上将推动数据从“成本中心”向“价值中心”转变。
过去,很多企业拥有大量行业数据——金融交易记录、医疗影像、工业生产日志、零售消费行为——但这些数据要么“脏乱差”,要么“锁在柜子里”,根本没有发挥价值。
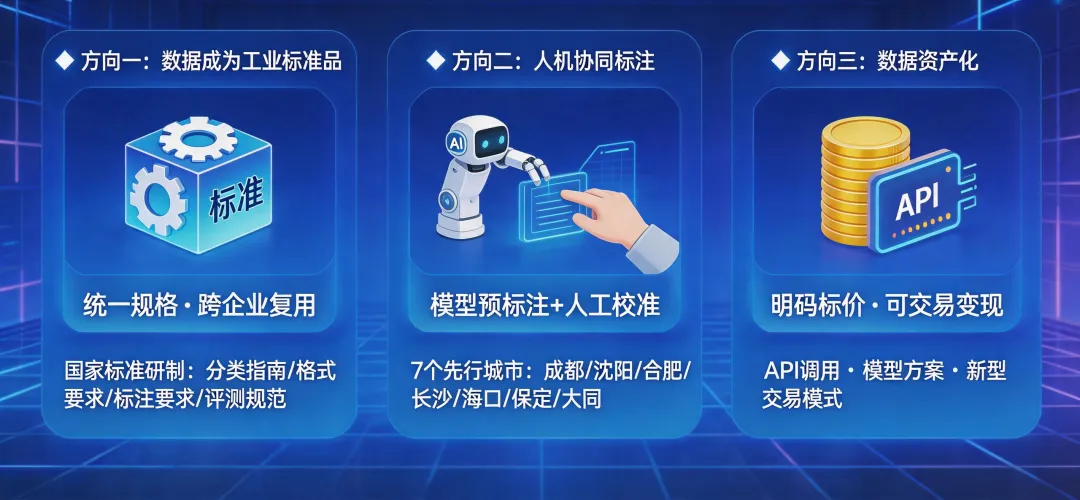
政策正在推动三件事:
-
第一,数据要变成“工业标准品”。 文件提出加快高质量数据集格式、类型、标注、质量测评等相关国家标准研制。目前,《高质量数据集分类指南》《格式要求》《数据标注要求》《质量评测规范》等已形成征求意见稿。
这意味着,未来数据要有统一“规格”。不同企业的数据可以像零件一样互相匹配、复用。
-
第二,数据标注要从“人海战术”升级为“人机协同”。 文件明确发展“模型预标注+人工校准”“人工标注+模型检验”等智能化标注服务。行业专家参与标注,让数据质量上一个台阶。
国家数据局已在成都、沈阳、合肥、长沙、海口、保定、大同布局七个标注先行先试城市。数据标注,正在从“劳动密集型”向“技术密集型”转型。
-
第三,数据要“明码标价”,可以交易、可以资产化。 文件专设“价值释放行动”,明确提出培育“为优质数据付费”的市场共识,探索数据集资产化路径,推动商业模式从基础数据包销售向API调用、模型化解决方案跃升,探索词元交易等新型交易模式。
FOUR
“数据飞轮”:一个越用越强的循环
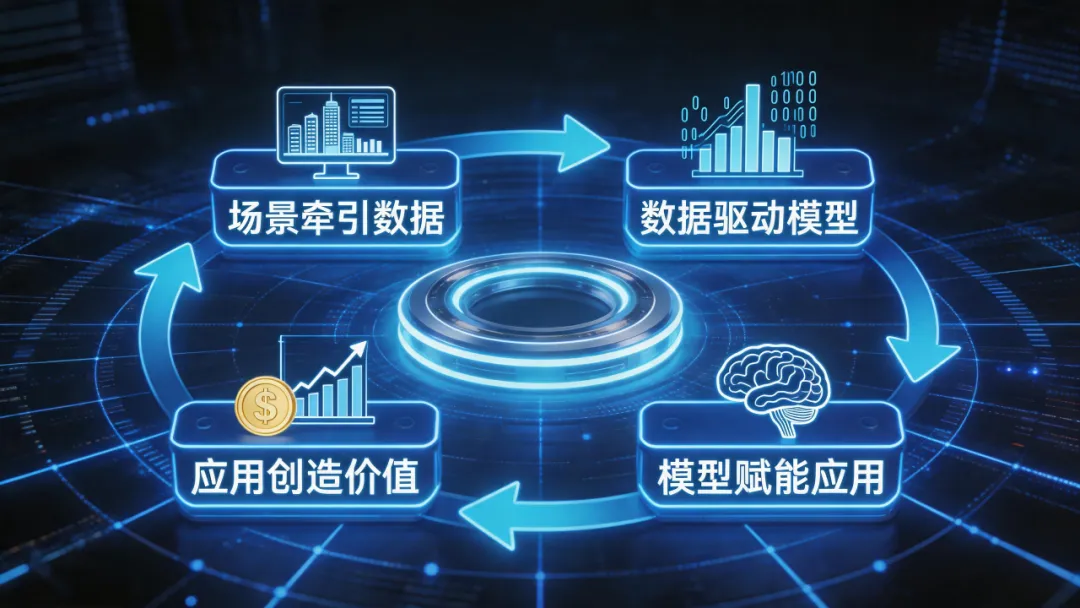
文件明确提出,要形成 “场景牵引数据、数据驱动模型、模型赋能应用、应用创造价值” 的“数据飞轮”。
简单理解:这是一个越用越强的循环——场景产生数据,数据训练模型,模型赋能应用,应用创造价值,新场景又产生新数据。
过去,AI项目往往是“做完一个模型就结束了”。未来的AI,将是 “用起来→产生新数据→再优化模型→再用” 的循环系统。
这意味着,数据不是一次性卖掉的“原材料”,而是可以持续产生价值的“资产”。
一个行业数据集,用的人越多,产生的反馈越多,数据集的质量就越高,价值就越大。
这份文件并非从零开始。截至2025年底:
-
全国已建成高质量数据集超过 10万个;
-
总数据量超过 890PB——相当于中国国家图书馆数字资源总量的 310倍;
-
高质量数据集累计交易额达 40亿元。
-
另一个印证产业爆发的数据是:全国日均词元调用量已超过 140万亿,相比2024年初的1000亿增长了1000多倍。
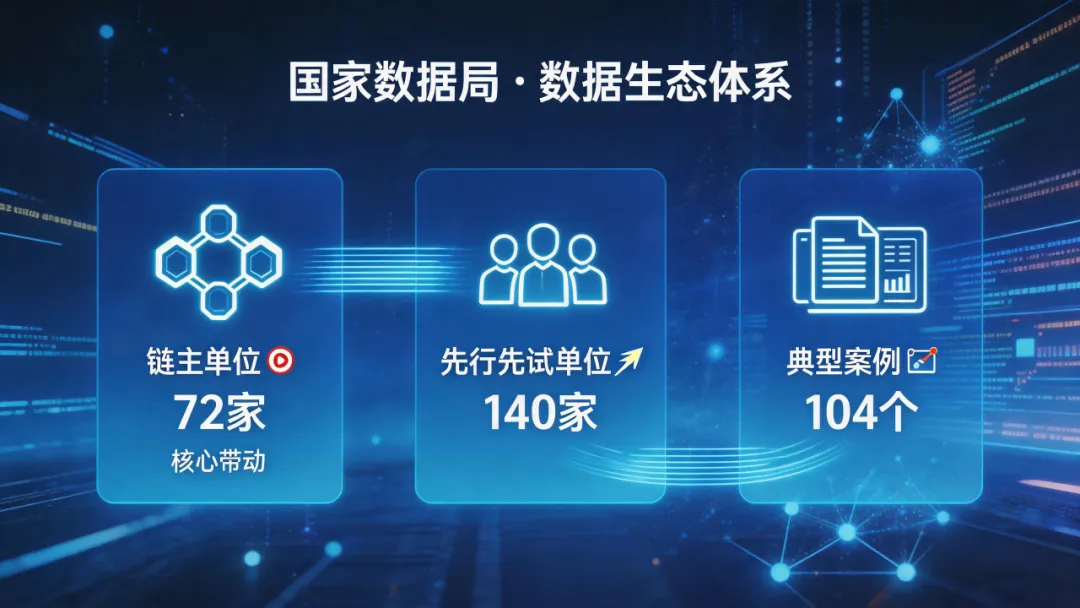
国家数据局已会同26个部门,遴选了 72家链主单位、140个先行先试单位和 104个典型案例。一个“链主带动、多方参与”的数据生态正在形成。
下一步:2028年底的目标
征求意见稿设定了明确的时间表:
到2028年底,建成一批覆盖重点领域、经过应用验证的行业高质量数据集,打造一批数据驱动AI创新的典型应用场景,培育一批具备领先优势的创新型数据企业和专业人才。
TalkingData洞察:
这份文件释放的真正信号,不是“要多建数据集”,而是:AI竞争的重心,正在从模型参数的比拼,转向数据体系的构建。
谁的数据更干净、更专业、更新得更快,谁的AI就更有用。
这带来了两个值得关注的变化:
第一,能够提供高质量、专业化、可复用数据集的“数据供应商”,将在AI产业链中占据重要位置。 资本市场和产业界对这一角色的关注度正在上升。
第二,每一家拥有行业数据的企业,都需要重新审视自己的数据资产。 那些沉睡在服务器里的日志、记录、影像,可能比想象中更有价值。整理、标注、变现——这不仅是技术问题,更是战略选择。
这一轮,比拼的不只是算法的先进性,更是数据与真实世界的贴合度。
关注TalkingData,获取更多数据洞察与行业分析。

END





高质量数据集是未来AI 发展的支撐。

为人工智能提供所需的一切数据
Delivering Comprehensive AI Data for All Industries.
#Data AI# #万亿数据要素市场#
推荐阅读:

国家首次提出“词元交易”:AI的“结算单位”,有了交易市场

国家安全部发声:140万亿次Token调用背后,你的“数字身份证”正在裸奔?

“Token”定名“词元”:AI圈的地震背后,藏着什么?


TalkingData
用数据优化决策、加速转型
欢迎关注分享