 夜雨聆风
夜雨聆风





app finetune
做过风控的同学都知道,用户手机里装了什么App,能暴露很多信息。
频繁安装借贷App的用户,风险大概率偏高;手机里全是办公、出行类App的用户,画像相对稳定。
所以AppList一直是风控中非常重要的特征维度。
但问题在于: AppList 是一个变长序列,不是结构化特征。
这就导致了没法直接把它输入树模型里训练。
那么问题就变成:
我们到底是要压缩信息,还是建模序列?
过去的做法是:
做统计聚合特征,简单有效,但本质上是在丢信息。
这篇文章换一种思路: 直接把 AppList 当作序列,用模型去学。
今天这篇文章,小编要讲一套端到端的App序列建模方案:
-
用预训练+微调的思路,让模型真正读懂App序列 -
对比3种Pooling策略,看哪种最适合风控场景
本文聚焦在下游分类微调这一环节。预训练在上篇文章已经介绍过,本篇不再介绍。
一、App序列
1.1 输入
每个用户有一串App列表,比如:
用户A: [微信, 支付宝, 抖音, 京东金融, 360借条, 微粒贷]用户B: [微信, 支付宝, 钉钉, 高德地图, 网易云音乐]经过编码后,变成一个整数序列:
用户A: [102, 5, 78, 234, 567, 891]用户B: [102, 5, 445, 312, 678]模型的原始输入是 APP ID。
1.2 输出
二分类标签:是否逾期。所以我们本质上是在做:给定一个App序列,预测该用户未来是否逾期。
1.3 为什么要用预训练
直接从零训练一个序列分类模型,数据量不够、表征能力弱,效果可能不会很好。
但如果先用海量无标签App序列做一次MLM预训练,让模型学到App之间的 共现关系 和 上下文语义,再在有标签数据上微调,效果会好很多。
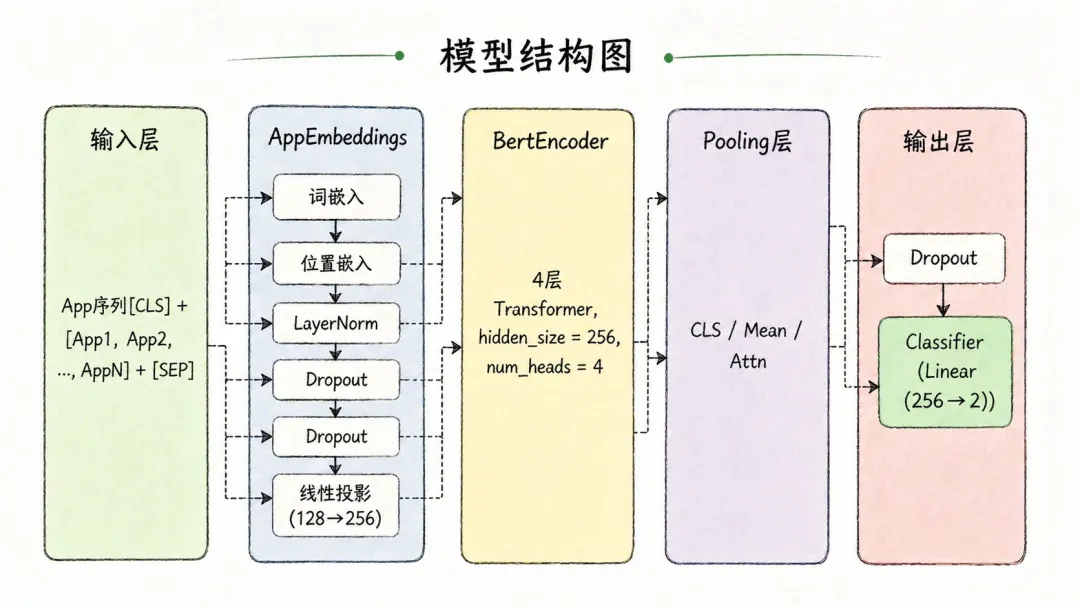
二、模型架构:Embedding + BertEncoder + Pooling + 分类头
这一套结构其实可以拆成四块:
Embedding -> Encoder -> Pooling -> 分类头
下面咱们逐一拆解。
2.1 Embedding层
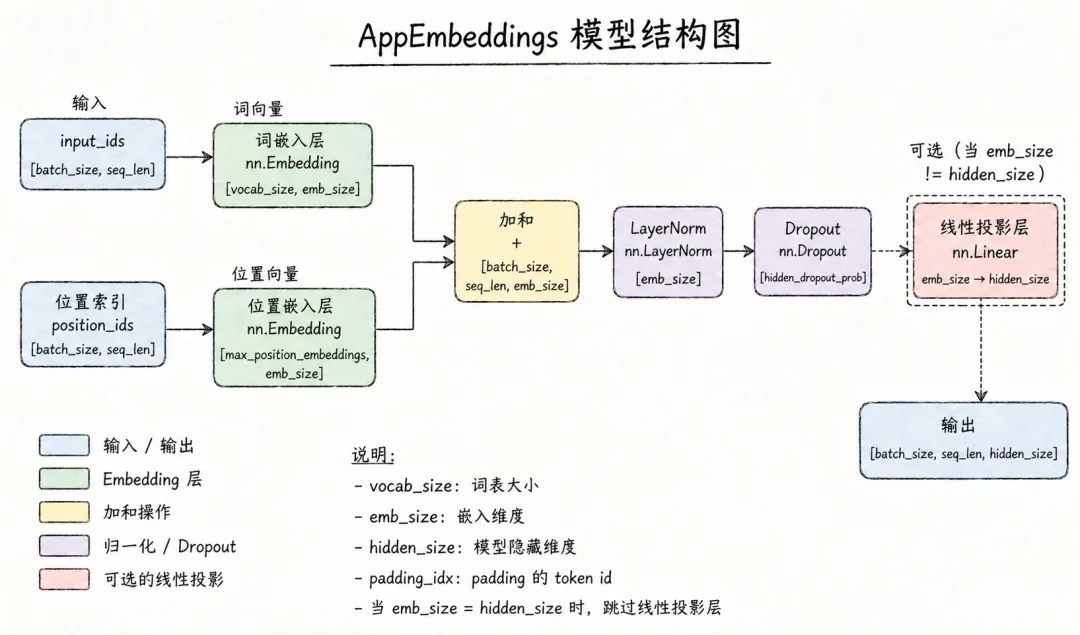
"""@file : finetune.py @author : yq1005 @date : 2026-04-25 @version : 2.1 @desc : AppList 序列二分类模型 —— DDP 分布式微调 note: - 数据达到亿级,本次按 user_id 维度建模,后续效果好的话再分首复贷吧,哎。。。TODO: 1. 将 applist 完成词表映射对齐,51后与 zb 对齐结果,看下子分及emb收益性,暂时收益1pp 2. 存储优化:当前为增量表(day 级覆盖),可能存在穿越风险,后续改为快照表或增加时间窗口约束吧 3. 看下是否可加入统计聚合特征拼接 效果? 4. 将建模流程 抽象为可复用 pipeline,适配其他序列特征场景"""import gc,polarsimport inspectimport shutilimport osimport jsonimport pickleimport datetimefrom importlib import import_moduleimport config as cfgimport numpy as npimport pandas as pdimport torchfrom torch import nnfrom torch.utils.data import Dataset, DataLoaderimport torch.distributed as distfrom sklearn.metrics import ( roc_auc_score, accuracy_score, f1_score, classification_report, confusion_matrix,)from transformers import ( Trainer, TrainingArguments, set_seed, BertConfig, EarlyStoppingCallback,)from transformers.configuration_utils import PretrainedConfigfrom transformers.modeling_utils import PreTrainedModelfrom transformers.models.bert.modeling_bert import BertEncoderclassAppEmbeddings(nn.Module):def__init__(self, config): super().__init__() self.word_embeddings = nn.Embedding( config.vocab_size, config.emb_size, padding_idx=config.pad_token_id) self.position_embeddings = nn.Embedding( config.max_position_embeddings, config.emb_size) self.LayerNorm = nn.LayerNorm(config.emb_size, eps=config.layer_norm_eps) self.dropout = nn.Dropout(config.hidden_dropout_prob)# 当 emb_size != hidden_size 时, 需要线性投影 self.proj = (nn.Linear(config.emb_size, config.hidden_size)if config.emb_size != config.hidden_size elseNone)几个关键设计点:
-
词嵌入 + 位置嵌入。 -
emb_size 和 hidden_size 分离 -
padding_idx=0:PAD位置的Embedding始终为零向量,不参与梯度更新。
2.2 BertEncoder
直接复用HF的 BertEncoder,4层Transformer,hidden_size=256,4个注意力头。
self.bert = BertEncoder(c) 参数配置:
HIDDEN = 256# 隐层维度LAYERS = 4# Transformer层数HEADS = 4# 注意力头数FFN = 1024# Feed-Forward 中间层维度2.3 分类头
self.dropout = nn.Dropout(config.dropout) self.classifier = nn.Linear(c.hidden_size, config.num_labels) 三、Pooling策略对比:CLS vs Mean vs Attention
这是本文最重要的部分。
BERT输出的 seq_out 是一个 [B, L, H] 的张量,每个位置(包括PAD)都有一个256维的向量。但分类头只需要一个 [B, H] 的向量作为输入。
怎么从序列变成单个向量?这就是Pooling要解决的问题。
小编对比了3种策略,下面咱们逐一讲清楚。
3.1 CLS Pooling(基线)
最经典的做法:直接取第一个位置的隐状态。
pooled = seq_out[:, 0, :] # [B, H]原理:在BERT预训练中,[CLS] token通过Self-Attention聚合了整个序列的信息,天然适合做分类任务的表征。
优点:零额外参数,计算最快,BERT原生设计。
缺点:所有信息压缩到一个token上,如果序列很长(我们的max_len=200),中间位置的信息可能被稀释。
3.2 Mean Pooling(均值池化)
对所有非PAD位置的隐状态取平均。
classMeanPooling(nn.Module):def__init__(self): super().__init__()defforward(self, seq_out, attention_mask): mask = attention_mask.unsqueeze(-1).float() # [B, L, 1] summed = (seq_out * mask).sum(dim=1) # [B, H] count = mask.sum(dim=1).clamp(min=1e-8) # [B, 1]return summed / count # [B, H]原理:把每个有效位置的向量加起来,除以有效位置数。等价于对序列做一个”平均投票”。
关键细节——一定要mask掉PAD位置!
很多同学第一次写Mean Pooling会直接 seq_out.mean(dim=1),这会导致PAD位置的零向量也被平均进去,人为拉低表征质量。正确的做法是用 attention_mask 过滤:
# [B, L, 1]mask = attention_mask.unsqueeze(-1).float() pooled = (seq_out * mask).sum(dim=1) / mask.sum(dim=1).clamp(min=1e-8)优点:零额外参数,对每个位置一视同仁,不会遗漏序列中间的信息。
缺点:不区分重要位置。对于风控场景,”用户装了360借条”和”用户装了计算器”,权重应该不同,但Mean Pooling一视同仁。
3.3 Attention Pooling
学习一组注意力权重,让模型自己决定每个位置的重要性。本质上,这是在让模型回答一个问题:这个序列里,哪些 App 更重要?
classAttentionPooling(nn.Module):def__init__(self, hidden_size): super().__init__()# 256 -〉1 self.attn = nn.Linear(hidden_size, 1) defforward(self, seq_out, attention_mask):# 每个位置算一个分数 [B,L] scores = self.attn(seq_out).squeeze(-1) # pad -inf, softmax 后权重为 0 scores = scores.masked_fill(attention_mask == 0, float('-inf'))# [B, L] weights = torch.softmax(scores, dim=-1) # 加权求和 pooled = torch.bmm(weights.unsqueeze(1), seq_out).squeeze(1) return pooled逐步拆解:
-
打分:每个位置的隐状态(256维)通过一个Linear层映射成一个标量分数 -
Mask:PAD位置的分数设为负无穷,确保softmax后权重趋近于0 -
归一化:softmax把分数变成概率分布(所有位置权重之和=1) -
加权求和:用权重对隐状态加权求和,得到最终的序列表征
优点:
-
只多了一个 Linear(256, 1)的参数(257个参数,几乎可以忽略) -
**能自动学习”哪些App更重要”**。比如模型可能学到”借贷类App的权重更高” -
对变长序列更友好
缺点:
-
多了softmax计算,速度略慢 -
注意力权重可解释性有限(不像树模型那样直观)
四、样本加权:风控场景下的必修课
做过风控的同学都知道,对重要样本加权是常态。
除了常规的正负样本加权,小编设计了多层样本加权方式,这里只介绍如何使用样本权重:
4.1 在训练时,通过 weight 参数传入loss计算:
# 加权交叉熵ce = nn.functional.cross_entropy(logits, labels, reduction='none')loss = (ce * weight).sum() / weight.sum().clamp(min=1e-8)注意:这里用的是 .sum() / weight.sum() 而不是 .mean()。因为 .mean() 除以的是batch size,而不是权重之和,会导致loss值失真,影响学习率的等效值。这是一个容易被忽略的坑。
五、实验结果怎么看?
跑完后会输出一个OOT样本对比表:
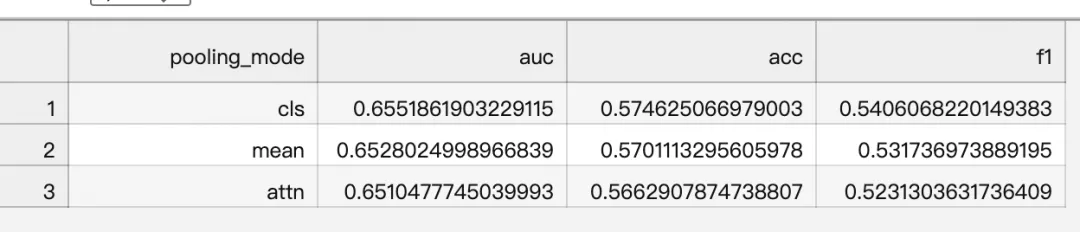
可看到CLS效果最好,而且单独序列建模AUC竟然可达到0.655!小编也尝试了applist 聚合变量单独lgb建模,对齐oot后,AUC也只有0.65,效果和finetune模型相差0.5pp!!!
六、总结
这套方案本质上解决了一个问题:如何把行为序列转成可学习的表示。
核心抓三点:
1)结构设计
-
Embedding + Encoder 是基础 -
Pooling 决定上限
2)训练细节
-
加权 loss 要规范 -
PAD 一定要处理干净
3)工程落地
-
embedding 可复用 -
pipeline 要可扩展
七、下一步可以做什么?
-
引入更多特征:除了App ID序列,还可以加入App使用时长、打开频次等连续特征,拼接到Pooling后的向量上 -
多任务学习:同时预测逾期+多头借贷+首逾,共享backbone -
对比学习:用正负样本对做对比学习,进一步提升Embedding质量 -
模型压缩:量化或蒸馏,把4层Transformer压缩成更轻量的模型,线上推理更快
觉得有收获?
👉 点赞 + 在看 是对作者最大的鼓励
👉 关注 公众号,第一时间收到后续文章
👉 留言区 欢迎提问:
-
你在序列建模中遇到过什么坑? -
你们团队用的什么Pooling策略?
评论区见!