 夜雨聆风
夜雨聆风





AI Agent的记忆难题:为何智能体总忘记上下文?
当你连续问Agent三个问题,它往往只记得最后一个。这不是技术缺陷,而是架构设计的深层矛盾。本文拆解Agent记忆系统的核心挑战,探讨企业落地场景中的解决方案。
一、问题场景:Agent的「健忘症」
说实话,用AI Agent的时候,最让人崩溃的不是它答错,而是它忘事。
我之前测试一个客服Agent,问它:”帮我查一下订单12345的物流状态”,它回复得很准确。接着我又问:”那这个订单能不能退货?”它直接给我甩出退货政策链接,完全没意识到我在问同一个订单。
嗯,这种健忘症在日常使用中太常见了。你可能觉得是模型问题,但实际上,这涉及到Agent架构中最核心的设计矛盾:短期记忆vs长期记忆。
当前主流Agent框架(LangChain、AutoGPT、CrewAI等)都面临这个挑战。用户连续提问时,Agent往往只能保留最近几轮对话的有效上下文,导致”失忆”现象频发。
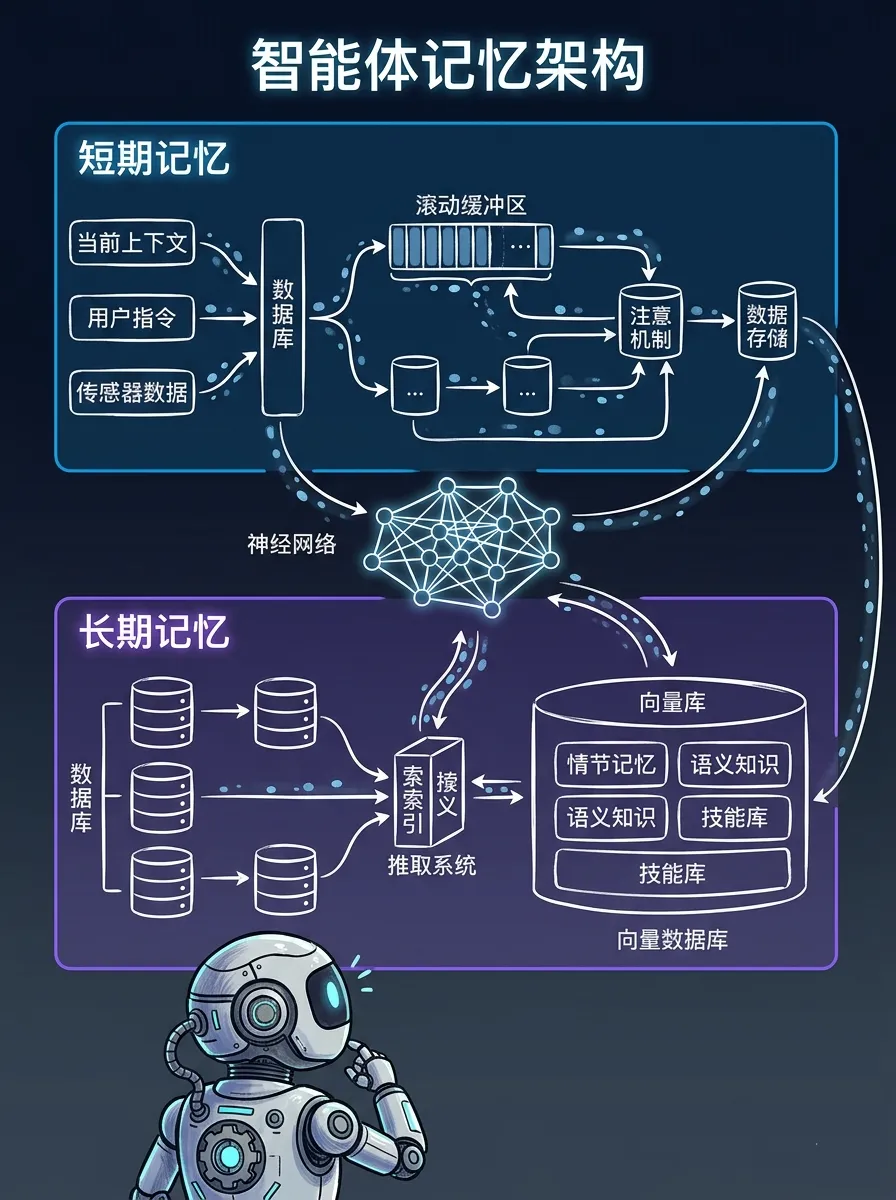
记忆系统架构
二、记忆系统的技术架构
要理解Agent为什么健忘,得先搞清楚它的记忆系统怎么设计。
短期记忆(Working Memory)
Agent的短期记忆本质上是大模型的上下文窗口。比如GPT-4 Turbo有128K token窗口,Claude 3有200K,看起来很宽敞。
不过话说回来,这个窗口不是无限可用的。每次对话,系统会把历史消息塞进窗口,但有几个问题:
1. Token限制:当对话超过窗口容量,早期对话会被截断或压缩
2. 注意力稀释:模型对所有历史内容的”注意力”不均匀,越早的内容权重越低
3. 成本累积:每次调用都要重新发送全部历史,成本按token计费
长期记忆(Long-term Memory)
长期记忆通常用向量数据库实现(如Pinecone、Weaviate、Chroma)。Agent会把关键信息存进去,需要时再检索。
听起来很美好?实际落地有几个坑:
● 写入时机问题:什么时候把对话内容存入长期记忆?存什么?存多少?
● 检索精度问题:向量检索不是万能的,关键词匹配和语义检索各有盲区
● 更新同步问题:用户信息变了,长期记忆怎么更新?

企业场景痛点
三、企业落地场景中的记忆痛点
理论讲完了,来看看实际场景。企业部署Agent时,记忆问题比想象中更复杂。
场景一:客服Agent的订单追踪
用户说:”查订单12345状态”,Agent回复后,用户接着问”能不能改地址?”。
理想状态:Agent应该知道用户在讨论订单12345,直接给出改地址流程。
现实状态:Agent可能问”请问您的订单号是多少?”,用户被迫重复信息,体验很差。
场景二:财务Agent的多轮报表生成
财务人员让Agent”生成上季度销售报表”,然后问”按区域拆分”,再问”对比去年同期”。
如果Agent记忆断裂,每轮都要重新理解”上季度销售报表”这个上下文,效率大打折扣。
场景三:研发Agent的代码修改
开发者让Agent”修改auth.py文件的登录逻辑”,然后问”顺便改下密码验证部分”,再问”加上日志记录”。
三轮对话后,Agent可能完全忘了最初说的是auth.py文件,把改动写到错误的地方。

解决方案对比
四、当前解决方案的局限
市面上的解决方案不少,但各有短板。
方案一:增大上下文窗口
GPT-4 Turbo、Claude 3等模型确实提供了超大窗口。但:
● 成本随窗口大小线性增长
● 大窗口≠好记忆,注意力稀释问题依然存在
● 不适合高频调用场景(客服、运维等)
方案二:对话摘要压缩
把历史对话压缩成摘要,减少token消耗。但:
● 摘要会丢失细节信息(订单号、时间戳等)
● 摘要质量依赖模型能力,可能引入歧义
● 实时摘要增加延迟
方案三:向量检索增强
用向量数据库存储关键实体,检索时补充上下文。但:
● 需要精细的信息提取策略(存什么、何时存)
● 检索召回率不稳定,关键信息可能漏检索
● 系统复杂度显著增加
方案四:显式状态管理
在Agent架构中引入状态层,显式存储对话关键信息。但:
● 需要人工设计状态字段(订单号、用户ID等)
● 状态更新逻辑复杂,容易遗漏边界情况
● 增加开发和维护成本
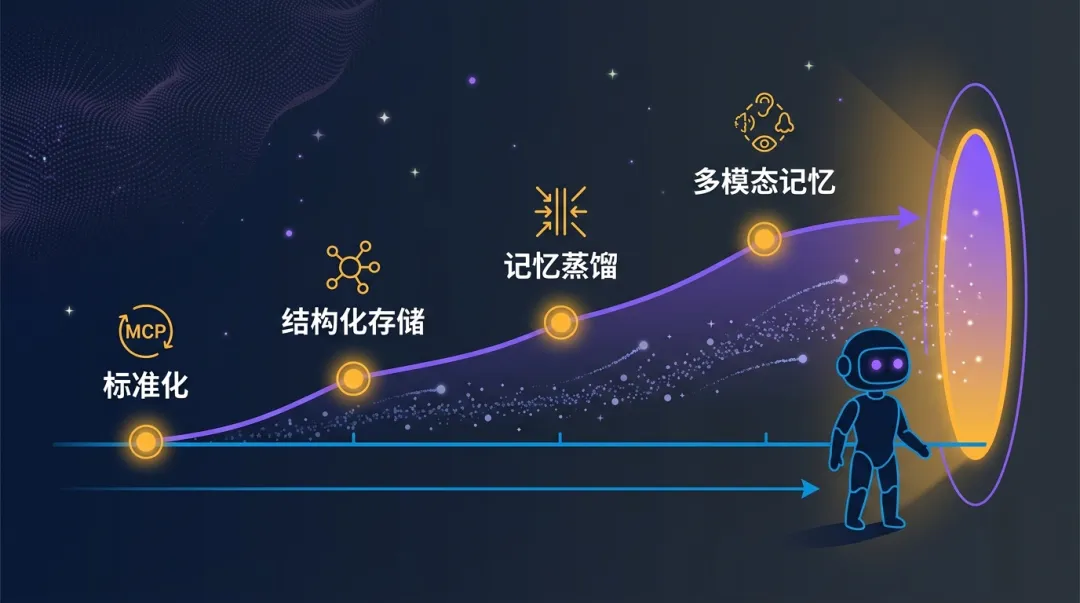
未来演进趋势
五、未来方向:记忆系统的架构重构
不管了,现有方案都不完美。但趋势正在变化,几个方向值得关注。
1. 记忆层标准化
MCP(Model Context Protocol)协议正在推动Agent记忆层的标准化。未来,记忆系统可能像数据库一样,有统一的接口和操作规范。
2. 结构化记忆存储
不再把记忆当纯文本,而是存储结构化实体(订单、用户、项目等)。类似”知识图谱”思路,让Agent能精准查询和更新记忆。
3. 记忆蒸馏技术
把高频使用的记忆”蒸馏”成更紧凑的表示,既保留关键信息,又减少检索开销。这可能是解决成本问题的突破口。
4. 多模态记忆
Agent记忆不只是文本,还包括图片、语音、行为序列。多模态记忆能更完整还原对话场景。
六、企业部署建议
面对记忆难题,企业该怎么应对?先试试这几个策略。
策略一:场景化记忆设计
不要追求通用记忆方案,而是针对具体场景设计。比如:
● 客服场景:显式存储订单号、用户ID,强制检索
● 财务场景:对话摘要+结构化报表元数据
● 研发场景:代码上下文+文件路径状态
策略二:记忆分层管理
区分不同层级的信息,采用不同存储策略:
● 临时信息(当前任务)→ 短期上下文
● 任务关键信息(订单号、参数)→ 状态层
● 领域知识(产品规则、流程)→ 向量库
管理三:记忆检索验证
Agent检索记忆后,不要直接使用,先验证。比如:
● 用户问”改订单地址”,Agent检索后回问”是订单12345吗?”
● 这种确认机制能减少记忆错误的影响
策略四:记忆边界透明化
告诉用户Agent的记忆边界在哪。比如:
● 客服Agent明确说”我能记住最近5轮对话中的订单信息”
● 用户知道边界,就不会提出超出能力的请求
结语:记忆是Agent的「灵魂」
说到底,记忆系统决定了Agent是”工具”还是”伙伴”。
工具型的Agent,单次调用解决问题,不需要记忆。但伙伴型的Agent,需要理解你的上下文,记住你的偏好,积累你们的对话历史。
目前的Agent大多还停留在工具阶段。但随着记忆架构的演进,真正的”智能伙伴”正在逼近。
企业落地Agent时,别只关注生成能力,记忆系统同样是成败关键。
关于作者:另一个AI世界,专注Agent智能体落地、大模型重塑行业、企业AI转型。带你探索AI的下一个世界。