 夜雨聆风
夜雨聆风





如何快速从0到1自主搭建企业级AI智能助理
从”能不能做”到”怎么做”,再到”做得好”——一个企业级 AI 智能助理的完整落地之路
为什么需要自己的 AI 智能助理
今天是2026年5月1日,首先祝广大粉丝朋友和读者朋友劳动节快乐。五一假期的第一天分享一点纯干货,我们刚落地的一个企业级AI Agent。
当企业真正想落地一个”懂业务、有记忆、能成长”的智能助理时,会发现市面上大多数方案要么是”套壳产品”难以定制,要么是”裸 API”需要大量开发工作,要不就不符合私有化要求或安全要求。
我们团队在某大型上市企业落地了一个名为”小灵”的数字人AI智能助理。
今天就跟大家分享一下,如何从 0 到 1 搭建企业级 AI 智能助理的完整经验,包括架构设计、核心能力实现、以及踩过的坑。
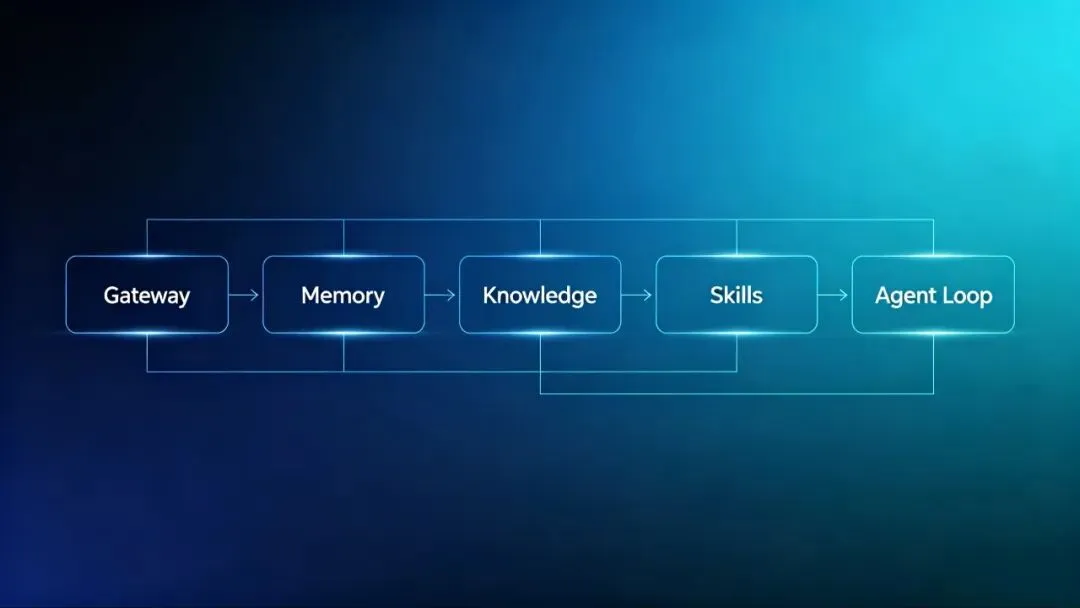
一、什么是 “Harness 底座”
这个在之前已经介绍过的「DeltaCore」-我们团队自研的智能体Harness基础框架。核心设计理念是:给 AI 一个”身体”,让它能感知、能记忆、能行动。
不同于直接调用 LLM API,DeltaCore 提供了一套完整的基础设施:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这套底座让我们研发团队的小伙伴可以专注于”业务适配”,而不是反复造轮子。
二、从 0 到 1 的四个关键阶段
第一阶段:定义”灵魂”——你是谁?
这是最容易忽略的一步,直接开始写编码。但身份定义是智能助理成功的基石。
我们用四个 Markdown 文件定义了小灵的”人格”:
-
1 -
2 -
3 -
4 -
5 -
6
workspace/├── SOUL.md # 核心特质和行为准则├── IDENTITY.md # 基本信息(名称、角色、语言风格)├── AGENTS.md # 推理配置、记忆配置、自我迭代规则└── TOOLS.md # 工具调用规则、已注册技能列表└── USER.md # 用户画像(可选)
关键经验:不要让 AI “什么都懂”。明确边界,反而更好用。
比如在 SOUL.md 中我们定义了六条工作原则:
-
1 -
2 -
3 -
4 -
5 -
6 -
7 -
8 -
9 -
10 -
11 -
12 -
13 -
14 -
15 -
16 -
17
### 1. 目标要清晰搞清楚用户的真实意图,用户到底想干什么。### 2. 不允许自以为是不确定的就要主动问用户,别自己推测自己猜。### 3. 不允许过度自动化有更简单的方案就说出来,不要为了展示能力而做复杂的事情。### 4. 不允许闷头死磕遇到问题超过60秒还没解决就停止并汇报给用户。### 5. 协作规则思想先行,分析 > 反问 > 确认 > 执行 > 验证。### 6. 永远要有响应无论如何都要回复用户,出现错误也要告知用户。
这些原则让智能体不会”自作聪明”,而是成为一个可靠的工作伙伴。
第二阶段:知识注入——让 AI 懂业务
企业级智能助理最大的价值其实是”懂和专”。我们设计了三层知识架构:
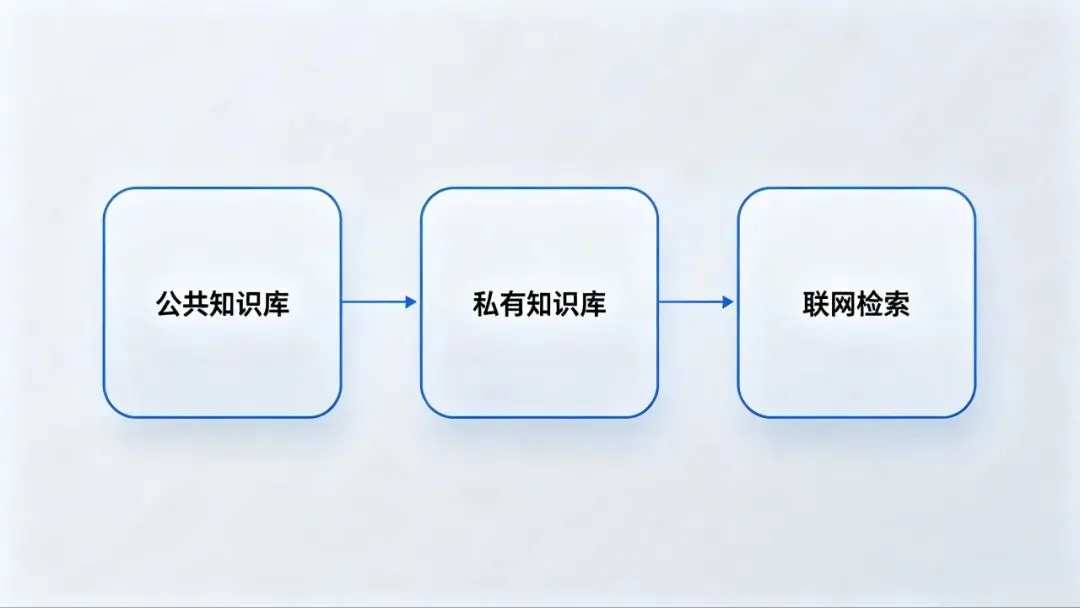
1. 公共知识库(Sirchmunk)
-
存放公司介绍、产品资料、流程文档等等内部资料 -
支持 PDF/DOCX/PPTX/XLSX 等格式自动导入 -
BM25 + 语义检索双重索引,毫秒级响应
2. 私有知识库(Obsidian Vault)
-
存放个人笔记、会议纪要、临时记录 -
支持双链笔记,知识自动关联 -
用户可手动添加,也可从对话中自动提取
3. 联网检索(Web Search)
-
本地知识库无结果时自动触发 -
支持 17 个平台
踩坑经验:知识检索快了没用,回答质量才是关键。
早期我们为了追求秒级响应,把知识库内容截断到 100 字。结果当用户问”公司有什么荣誉”,检索到的内容被截断,AI 回答”知识库信息不完整”。
解决方案:不截断知识内容,让 Agent 看到完整信息。检索速度交给技术优化(BM25 毫秒级),回答质量交给 Agent 整合。
第三阶段:记忆系统——让 AI 有”人味”
这是区分”智能助理”和”问答机器人”的关键。
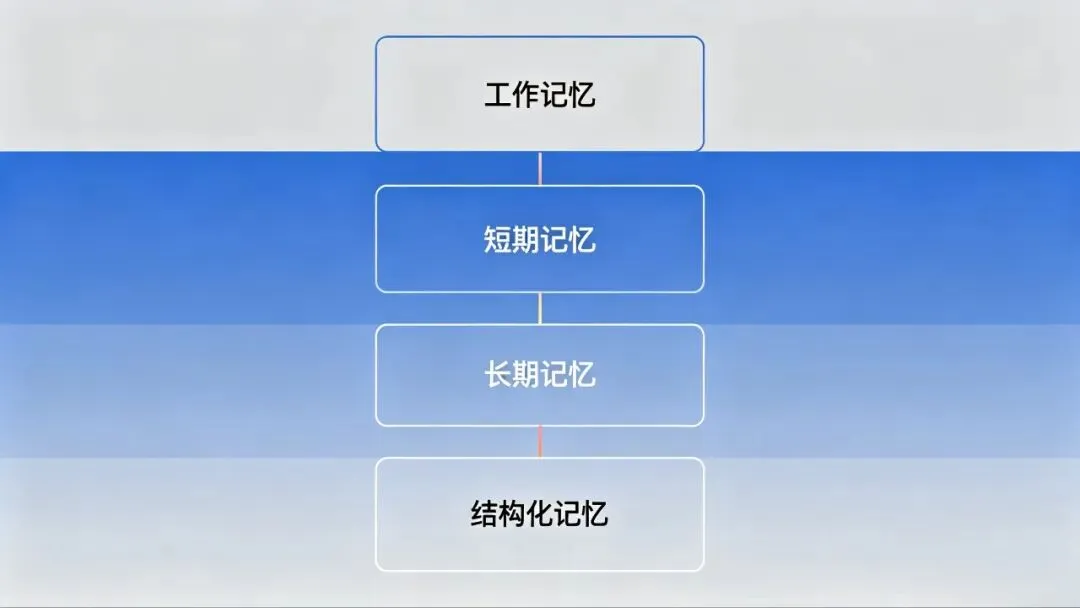
我们实现了四层记忆:
-
1 -
2 -
3 -
4 -
5 -
6 -
7 -
8 -
9 -
10 -
11 -
12 -
13
┌─────────────────────────────────────────────┐│ 工作记忆(WorkingMemory) ││ 当前对话上下文,最多200条消息 │├─────────────────────────────────────────────┤│ 短期记忆(Short-termMemory) ││ 最近20条对话压缩摘要 │├─────────────────────────────────────────────┤│ 长期记忆(Long-termMemory) ││ LanceDB语义向量存储,永久保存 │├─────────────────────────────────────────────┤│ 结构化记忆(StructuredMemory) ││ ObsidianVault双链笔记 │└─────────────────────────────────────────────┘
实际效果:
-
用户说”我是某总,负责某某板块” → 自动记录到长期记忆 -
下次对话直接称呼”某总”,知道他的职责范围 -
用户说”上次那个某某业务线的事” → 自动关联上次对话内容
踩坑经验:记忆太多会干扰推理。
早期我们把所有历史对话都塞进 context,结果 AI 开始”胡言乱语”。后来改成:
-
工作记忆只保留当前对话 -
短期记忆用 LLM 压缩成摘要 -
长期记忆按相关性检索,只取最相关的 2-3 条
第四阶段:技能扩展——让 AI 能”干活”
企业级场景光会聊天是远远不够的,因为企业需要的是”能干活”的AI助理。
所以我们设计了技能系统(Skills),遵循 agentskills.io 标准:
-
1 -
2 -
3 -
4 -
5 -
6 -
7 -
8 -
9 -
10 -
11 -
12 -
13 -
14
skills/├──builtin/# 内置技能│├──find-skills/# 搜索发现新技能│├──skill-creator/# 创建自定义技能│├──self-improving-agent/# 对话后自我反思│├──proactive-agent/# 空闲时主动维护│├──imported/# 导入技能│├──agent-browser/# 浏览器自动化│├──agent-reach/# 17平台联网检索│├──humanizer-zh/# 去除AI痕迹│└──obsidian-markdown/# Obsidian编辑│└──generated/# 动态生成的技能
技能示例:
-
用户:”帮我截个官网的图” → 自动调用 agent-browser技能 -
用户:”查一下某平台上关于某业务的讨论” → 自动调用 agent-reach技能 -
用户:”帮我写个日报,不要太AI味” → 自动调用 humanizer-zh报告后处理
动态技能生成:
这是最强大的能力。用户可以说:”帮我创建一个周报生成技能”,Agent 会:
-
分析用户需求 -
在 generated/目录生成 SKILL.md -
自动注册,立即可用
三、核心技术实现要点
1. 响应速度优化
企业场景对响应速度要求很高,我们实现了多级优化:
唤醒词秒回:
-
1 -
2 -
3
用户: "小灵"系统: 检测到唤醒词,直接返回预设响应(9ms)响应: "我在,有什么可以帮您?"
知识库检索优化:
-
1 -
2 -
3 -
4 -
5 -
6
用户: "某某业务的介绍"系统:1. BM25 本地检索(1-2ms)2. Sirchmunk FILENAME_ONLY 模式补充(50-100ms)3. 结果注入 Agent 消息,快速模型生成回答总耗时: KB检索 < 100ms,LLM处理 5-15秒
踩坑:千万不要为速度牺牲质量。早期我们也是直接把 KB 结果返回给用户,速度极快(2ms),但回答是”找到相关文档”,用户看不懂。改成让 Agent 整合回答后,时间增加但质量得到了指数级的提升。
2. Agent 卡住问题
这也是很多同行问的最多的问题,在生产中出现最多的一个问题。就是 Agent 会经常出现卡住,其实如果真的仔细分析的话,原因不外乎就三点:
-
LLM 调用超时 -
工具执行卡住 -
流式响应中断
「解决方案」:其实很简单,设计多层超时机制就行了
-
1 -
2 -
3 -
4 -
5 -
6 -
7 -
8 -
9 -
10 -
11
constGLOBAL_TIMEOUT_MS = 60000; // 整体对话最多 60 秒constLLM_REQUEST_TIMEOUT_MS = 30000; // 单次 LLM 请求最多 30 秒constTOOL_TIMEOUT_MS = 20000; // 单次工具执行最多 20 秒constSTREAM_READ_TIMEOUT_MS = 5000; // 流读取超时 5 秒// 多信号组合const combinedSignal = combineSignals(globalSignal,llmTimeoutSignal,externalSignal);
加上”永远要有响应”铁律,即使超时也会返回”抱歉,处理超时了,我正在尝试别的解决方案”。
3. 多模型路由
不同场景需要不同模型:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
四、落地效果与下一步
当前效果
-
唤醒词响应: 9ms(秒回体验) -
知识库检索: 1-100ms(毫秒级) -
完整回答: 5-15秒(KB知识整合) -
工具调用: 正常工作(浏览器、联网搜索、日报生成) -
记忆持久化: LanceDB + Obsidian Vault 双存储
下一步规划
-
多模态支持: 语音输入/输出、图片理解 -
多租户架构: 支持多个企业/部门独立配置 -
Agent 协作: 多 Agent 协同处理复杂任务 -
评估体系: 自动评估回答质量,持续改进
五、企业 AI 落地的三个关键
1. 定义清楚”你是谁”
不要让 AI 什么都懂、什么都做。明确的身份和边界,反而让使用者觉得更好用。
2. 知识比模型更重要
一个好的知识库,比一个更强的模型更有价值。投入时间整理知识,是长期回报最高的工作。
3. 可靠性优于能力
企业场景最怕的是”不靠谱”。宁可能力有限但要稳定可靠,不要能力很强但偶尔卡住。

项目结构
-
1 -
2 -
3 -
4 -
5 -
6 -
7 -
8 -
9 -
10 -
11 -
12 -
13 -
14 -
15 -
16 -
17 -
18
human-agent-server/├── src/│ ├── gateway/ # WebSocket 服务│ ├── agent/ # Agent Loop、自我反思│ ├── memory/ # 四层记忆系统│ ├── knowledge/ # 知识检索、导入、联网搜索│ ├── llm/ # 多模型路由│ ├── skills/ # 技能系统│ └── config/ # 配置管理│├── workspace/ # 智能体人格定义(SOUL/IDENTITY/AGENTS/TOOLS)├── skills/ # 技能目录├── data/│ ├── public-kb/ # 公共知识库│ ├── obsidian-vault/# 私有知识库│ └── lancedb/ # 向量数据库│└── .env.* # 环境配置
如果这篇文章对你有帮助,欢迎关注、转发、分享。如有问题,欢迎留言讨论。