 夜雨聆风
夜雨聆风





AI 时代的药物靶点发现:从"加速工具"到"闭环 co-scientist"
一个被忽略的数字
人类基因组里大约有 20000 个蛋白编码基因,其中估计 4500个是”可成药”的。而到今天为止,所有获批药物加起来只命中了 716 个不同的靶点。
换句话说,85% 的可成药空间还没被开发。挡在前面的不是化学,而是”挑哪一个”。最近 Nature Reviews Drug Discovery 上 Insilico Medicine 牵头的这篇综述(Pun et al.,2026),系统梳理了 AI 在靶点鉴定与评估中的角色变化。它真正想讲的不是”AI让某一步更快了”,而是一个更激进的转向:AI 正在重新定义”找靶点”这件事的工作流形态。
传统方式卡在哪
传统靶点发现的逻辑很线性——从一个疾病假说出发,靠人类遗传学、动物模型和文献阅读,圈出几个候选蛋白,再交给实验室一个个去验证。这套流程的隐含约束有三条:第一,专家能消化的证据是有限的,候选数量天然窄;第二,”新颖性”和”可信度”几乎对立——证据越扎实的靶点越可能已被开发,新靶点则证据稀薄;第三,实验只能串行排队,rate-limited by lab throughput。
Nelson 等人 2015 年那篇著名的统计显示,有人类遗传学支持的靶点,临床成功率比无支持的翻倍以上。这个发现把”用更多数据来支撑靶点假说”推到了行业共识,但人脑还是那个人脑——读不完每年增长的文献、组学和专利。AI 由此入场。
AI 在做什么:四层能力
文章用一张图(Fig 1)勾勒出 AI 在靶点发现全链路的位置:
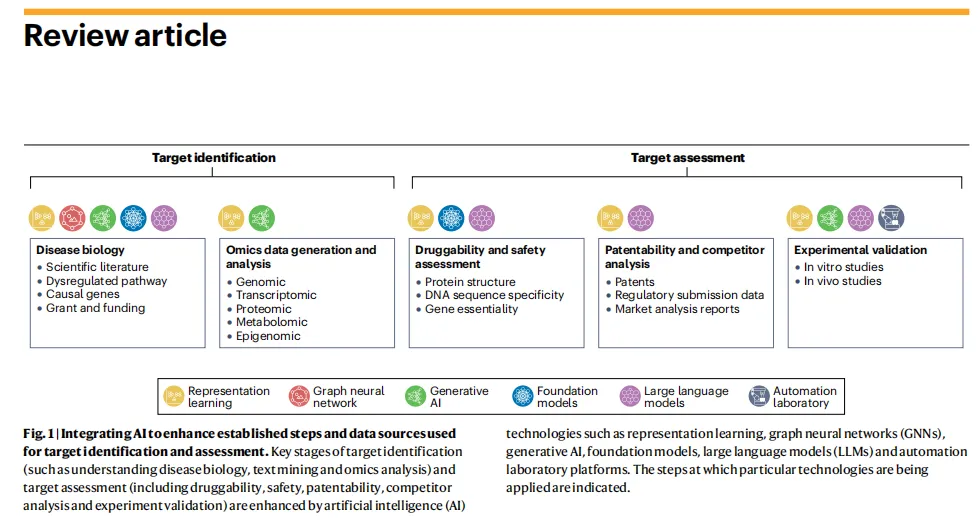
数据层几乎覆盖了所有可拿到的证据类型——基因组、转录组、蛋白组、代谢组、表观基因组、影像、文献、专利、临床试验记录。这一层堆数据本身不新鲜,但量级今非昔比:UK Biobank、All of Us、JUMP-Cell Painting、ChEMBL、Open Targets 等公共资源加起来,已经够支撑预训练大模型。
模型层是真正发生范式跃迁的地方:
– 图神经网络(GNN) 把蛋白互作网络、知识图谱直接嵌入模型,KG4SL用合成致死预测抗癌靶点,PDGrapher 找能逆转疾病表型的”扰动组合”
– 基础模型 比如 Geneformer(3000 万单细胞预训练)、scGPT、Recursion 的 Phenom-Beta(9300万细胞影像预训练)开始承担”通用细胞表征器”的角色,下游接靶点鉴定、扰动响应预测、细胞类型注释都能用
– 生成式 AI 走得更远——Insilico 的 Precious2GPT 把多组学和组织数据 token 化,让transformer 直接生成合成多组学样本,用来填补稀缺数据
– 大语言模型(LLM) 进入靶点发现是过去两年最快的变化:BioGPT、TxGemma、Google 的 AI co-scientist、Insilico 的 OriGene 都把”读文献 + 提假设 + 调用工具”做成了 multi-agent工作流
验证层作者画了三种模式:回顾性”时光机”测试(用 2015 年前的数据训练,看模型能否预测 2015年后真正进入临床的靶点)、体外/体内实验、以及前瞻性临床预测。inClinico 平台对 III期临床试验结果的前瞻性预测准确率达到 79%——这是一个比大多数 benchmark都更接近真实回报的数字。
真实的临床落地
综述里最有说服力的部分是几个已经走完或接近走完临床试验的案例:TNIK 与特发性肺纤维化(IPF)——Insilico 用 PandaOmics 平台从多组学+网络分析中把 TNIK排到第一,整个 in silico 到 IND 用了约 18 个月。其抑制剂 INS018_055 在中国一项 IIa期试验(NCT05938920)中入组 71 名 IPF 患者,60 mg QD 组观察到剂量依赖的用力肺活量改善。
DRD2 与脑胶质瘤——抗癌化合物 ONC201 当年靠表型筛选发现,但靶点不明。BANDIT(贝叶斯 ML模型)通过化学相似性、转录响应和报告基因数据反向解卷积,预测靶点是多巴胺受体D2(DRD2),后续实验确认。基于此推进的 dordaviprone 在 2025 年获 FDA 批准用于 H3 K27M弥漫中线胶质瘤——这是首个以”AI 解卷积出的靶点”作为关键证据获批的药物。
PIKfyve 与 ALS、APLNR 与衰老相关肌少症:作者也忠实记录了失败——Verge 的 PIKfyve 抑制剂VRG50635 在 ALS 中因疗效不足终止,BioAge 的 azelaprag/tirzepatide联用因肝酶升高停摆。这恰好提醒了一件事:AI 把靶点送上临床很快,但临床本身仍然是过滤器。
真正的范式转换:闭环
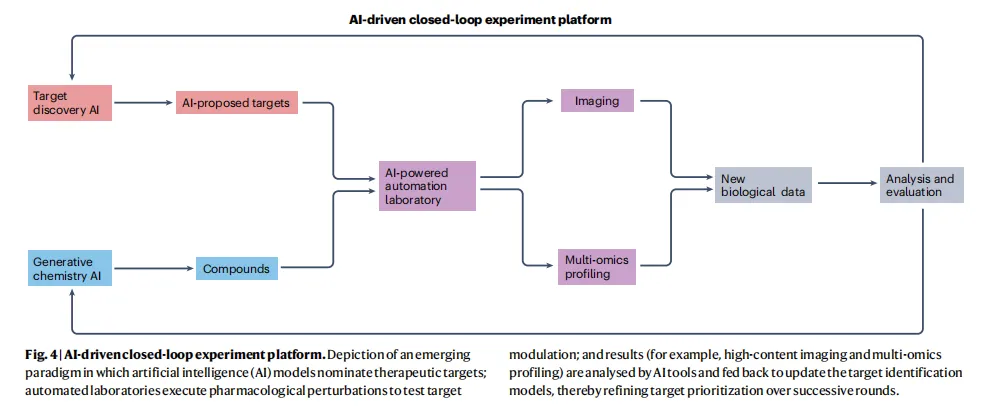
读到 Fig 4 才能看出作者真正想讲什么。传统逻辑是”模型预测 → 实验验证”的单向链条;AI co-scientist 加上自动化实验室(AstraZeneca 的 iLab、Tempus 的 Loop、Insilico 的ILab),让数据可以实时回流到模型——靶点 AI 提候选 → 化学 AI 设计探针 →自动化平台跑细胞画像/多组学 → 数据反哺训练。
这是从”AI 是工具”到”AI是工作流主体”的边界重定义。它的成本结构、迭代速率、决策对象都和传统药物发现不同。