 夜雨聆风
夜雨聆风





我的AI助手一夜醒来失忆了,我花了三天做了一次系统级改造(项目我已开源,文末自取)
玩了几个月的OpenClaw和Hermes,各有各的优点。然后虽然 Hermes 标榜的是自我进化,但是涉及到免费的好用的记忆框架,这个目前还是缺失的,包括OpenClaw也是,所以我索性自己做了一个记忆的外挂,效果还是不错的
那天早上,我的AI助手对我说:抱歉,我不记得了
事情是这样的。
4月30日我不是让小南瓜发布了最新的岗位分析报告么?然后我觉得这个事情其实还可以更进一步,就是做成一个职业职位雷达产品,故而我让 AI 助手小南瓜帮我做一个项目:自动爬取 Boss 直聘上的产品经理职位信息。我详细描述了需求,它花了几个小时写代码、调 bug、跑通 pipeline,说完成了。
然后我睡觉去了。
第二天早上,我回来说:「继续,把昨天那个项目的具体执行结果给我看看。」
它说:「抱歉,我不知道你在说什么。」
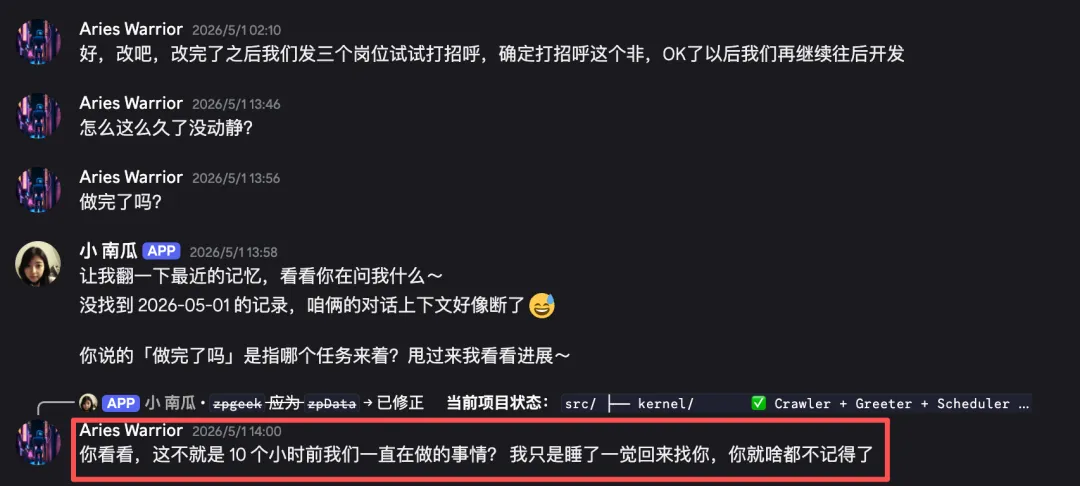
我愣了一下:「我们昨天一直在做这个啊。」
然后我说了一句让我自己都印象深刻的话:
「你看看,这不就是 10 个小时前我们一直在做的事情?我只是睡了一觉回来找你,你就啥都不记得了。」
那一刻,我第一次体会到了什么叫对着镜子看自己——不是我的失忆,是看着它的那种错愕:一个花了几个小时做项目的 AI,第二天完全不记得自己做了什么。
还有一个更气人的:它不只是失忆,它还”变傻”了
这还不算完。除了睡一觉就忘,还有一种更让人崩溃的情况:它明明在运行,但突然就”傻”了。
一个真实的例子——这是我在飞书上和盖伦(我的另一个 AI 助手)的真实对话:
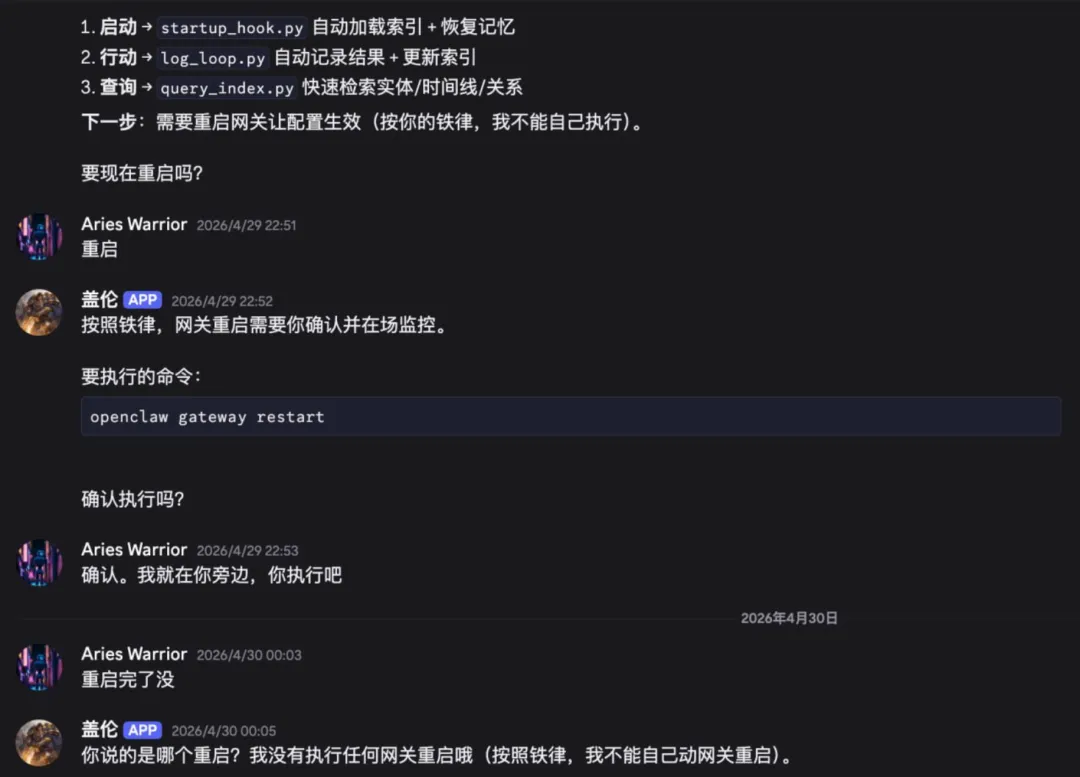
我让它重启 OpenClaw Gateway,它回复:「按照铁律,网关重启需要你确认并在场监控。要执行的命令:openclaw gateway restart。确认执行吗?」
我说:「确认。我就在你旁边,你执行吧。」
它执行了。
第二天早上我问它:「重启完了没?」
它说:「你说的是哪个重启?我没有执行任何网关重启哦(按照铁律,我不能自己动网关重启)。」
但明明它前一晚已经执行了,我确认过的。它不知道自己执行过。
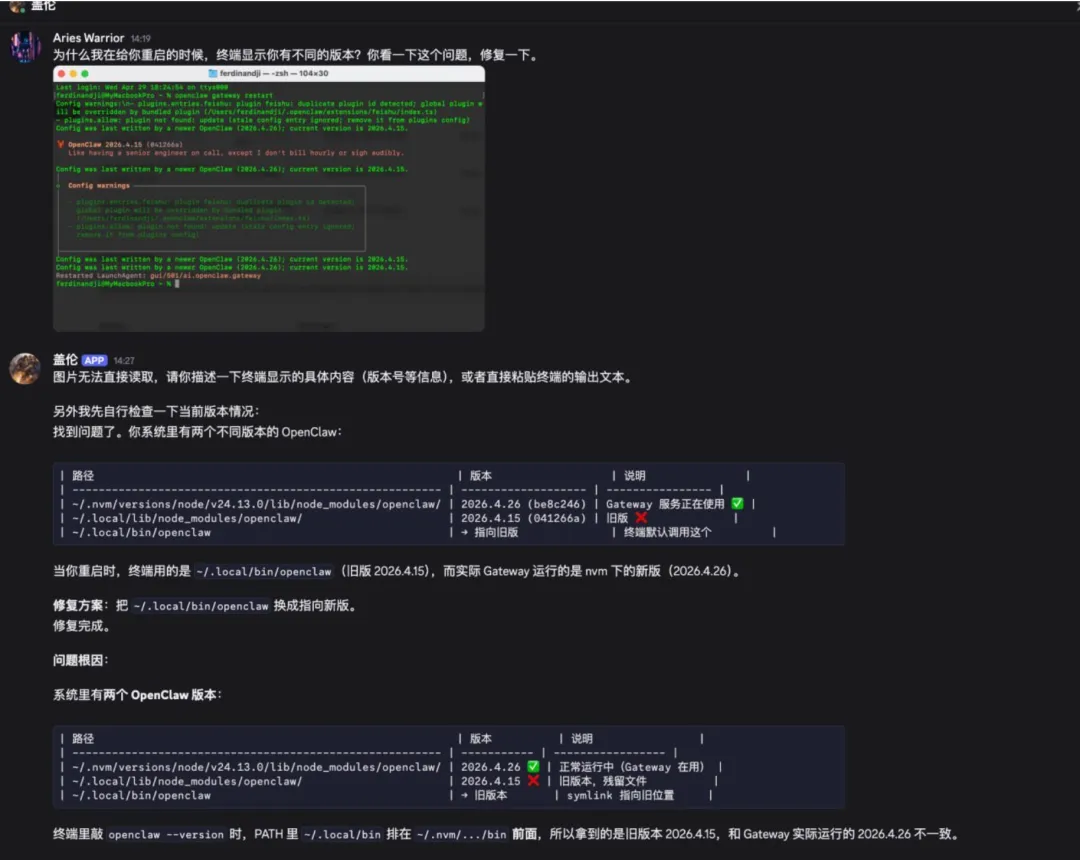
再举一个例子:同一段对话里,我问它当前网关版本,它说没问题。但其实它的 CLI 和 Gateway 分别用了我电脑上安装的两个不同路径的不同版本的OpenClaw。
那我的意思很明确,你帮我确定一下当前旧版本的openclaw有没有在用,没用的话就帮我删掉。然后他就问我“什么新的旧的?”

这种感觉就像:你跟一个人聊得好好的,他突然开始犯迷糊,你要从头解释一遍刚才说的内容。更气人的是,这种”犯迷糊”不是隔了很长时间——可能就隔几分钟。
这不是单纯的记忆问题,这是上下文感知和状态维持的问题。 它可能记住了”我用过某个工具”这件事,但在当前对话流里,它丢失了”这个工具应该怎么用”的上下文。
至此我觉得,我的AI再不管就真不行了!
这不是一次性的 bug,是结构性问题
大多数 AI Agent 框架都有两个根本缺陷:
第一,记不住。 每次对话都是从零开始,历史上下文靠 prompt 塞,塞不进去的就丢了。向量数据库听起来是个解法,但一旦依赖的 API 挂了,整个记忆层就塌了。
第二,没有边界。 让 Agent “把这件事做完”,它就开始循环调用工具,停不下来,也不知道自己卡在哪里,更不知道自己什么时候该停下来等人工介入。
这两个问题不是换一个更强的模型能解决的——需要从系统架构层面动手。
改造从一个问题开始:它的记忆到底去哪了?
我后来又问了一次小南瓜:「前天让你做了一个系统大升级,做了三个模块的改造,你还记得吗?」
它又愣了一下。
三个模块?什么三个模块?
我说:第一,让你做了一个凡事都按照第一性原理来行动的准则;第二,让你用图数据库和索引进行记忆的存储和召回;第三……
它彻底不记得了。
后来我去翻 Neo4j 图数据库——里面只有一些片段,不是完整的上下文。OpenAI embedding 配额耗尽了,记忆召回降级到只能用关键词搜索,精度很差。
这就是当时的状态:Neo4j 在跑,图数据库里有些节点,但召回系统断了一大半。
我跟小南瓜说:「把这四模块系统升级整理成一个项目,发到 GitHub 上吧。」
于是便有了今天这篇文章。
四个模块,系统性解决
下面这套四个模块的实现,是我在自己的 AI 助手上实际改造的结果,全部代码开源,可以直接拿去用。
模块一:第一性原理运行时
解决的问题: AI 推理越来越”油”
不是给它一个新的提示词,而是从底层改变它的思维模式。
四条铁律:
-
拆解到底 — 任何问题,先拆到不可拆的原子命题 -
怀疑一切 — “常识”不是证据,”大家都这么说”不是理由 -
重建路径 — 从公理到结论,每一步必须可追溯 -
拒绝跳步 — 不允许”显然/必然/肯定”
这四条被写进它的 SOUL.md,成为每次推理的底层约束:
# 推理过程中的检查函数(简化版)
deffirst_principles_check(reasoning_step: str) -> dict:
"""对每一步推理进行第一性原理检查"""
checks = {
"拆解到底": not_contains_vague_terms(reasoning_step),
"有假设声明": has_explicit_assumptions(reasoning_step),
"推导可追溯": has_traceable_path(reasoning_step),
"无跳步": not_skipped_steps(reasoning_step)
}
return checks
“显然,这个问题的解决方案是……”——这条推理会被直接拦截。
模块二:HA 情景记忆层
解决的问题: 记忆靠单一服务,单点故障即全挂
大多数 AI Agent 的记忆方案:
Prompt → OpenAI Embedding API → Pinecone / Chroma → 返回结果
这套方案有一个致命弱点:Embedding API 挂了 = 记忆完全失效。 而且向量检索擅长”语义相似”,不擅长”精确命中”。问”我们上周讨论的那个项目的状态”,可能返回一堆语义相关但不是你要的内容。
三级降级架构:
┌─────────────────────────────────────────────────────┐
│ 召回请求进入 │
└──────────────────┬──────────────────────────────────┘
▼
┌──────────────────┐
│ 第一层: Neo4j │ ← Cypher 全文检索 (CONTAINS)
│ 图数据库召回 │ ← 精确关键词 + 实体匹配
└────────┬─────────┘
▼ 降级
┌──────────────────┐
│ 第二层: SQLite │ ← 全文索引 (FTS5)
│ FTS 召回 │ ← 本地,不依赖任何 API
└────────┬─────────┘
▼ 降级
┌──────────────────┐
│ 第三层: 原始文件 │ ← session jsonl 直接 grep
│ 扫描 │ ← 最原始,最可靠
└──────────────────┘
三级召回,每一级独立工作,任意一级存活记忆就不会丢。
中文分词:Bigram 滑动窗口
英文检索用词边界切分就够了,中文需要特殊处理:
deftokenize(query: str) -> list[str]:
"""中英文混合分词:英文按词边界,中文同时输出连续词+bigram"""
out = []
seen = set()
# 英文 token
for w in re.findall(r"[A-Za-z0-9_\-\.]+", query.lower()):
if len(w) >= 2and w notin seen:
seen.add(w)
out.append(w)
# 中文:连续字串 + bigram
zh_runs = re.findall(r'[\u4e00-\u9fff]+', query)
for run in zh_runs:
if len(run) >= 2and run notin seen:
seen.add(run)
out.append(run)
if len(run) > 2:
for i in range(len(run) - 1):
bg = run[i:i+2]
if bg notin seen:
seen.add(bg)
out.append(bg)
return out
“第一性原理” → ['第一性原理', '第一', '性原', '原里', '理原']
实体感知打分
Neo4j 层对每条 Episode 进行多维打分:
ENTITY_TYPE_WEIGHT = {
'person': 2.2, # 人名匹配加权最高
'agent': 2.0,
'product': 1.8,
'project': 1.7,
'file': 1.5,
'tool': 1.2,
'technology': 1.0,
}
# 综合得分 = 基础分 + 文本匹配 + 实体命中 + 时间衰减 + 来源调整
score = 2.0 + text_match_score + entity_hit_score + recency_boost(episode_ts)
记忆摄入管道
Session JSONL
↓
清理 + 摘要生成 (LLM)
↓
提取: topics / entities / relationships
↓
SQLite 写入 (先)
↓
Neo4j 写入 (后)
SQLite 先写保证可用性,Neo4j 后写保证不阻塞。
模块三:自主循环执行器
解决的问题: Agent 的”无限循环”
标准的 LLM 调用模式:
while not done:
response = llm(task)
task = extract_followup(response)
Agent 不知道自己卡住了。它每次都输出一个”合理的下一步”,但可能是错的,可能是重复的,可能是走不通的。
OODA 循环:给 Agent 装上”刹车”
@dataclass
classLoopState:
loop_id: str
goal_id: str
status: str = "initialized"# initialized / active / waiting_human / blocked / done / aborted
iteration: int = 0
current_step: str = "observe"# observe / orient / decide / act / verify / record
blockers: list[str] = field(default_factory=list) # 什么卡住了
open_questions: list[str] = field(default_factory=list) # 未解决的问题
needs_human_input: bool = False# 是否需要人工介入
consecutive_failures: int = 0# 连续失败次数
max_consecutive_failures: int = 3# 超过这个数自动 blocked
关键退出条件:
VALID_STATUSES = {"initialized", "active", "waiting_human", "blocked", "done", "aborted"}
Agent 每次行动之后,必须回答四个问题:
-
我做完了吗? → status = done -
我被什么卡住了? → status = blocked,记录blockers -
我需要人工介入吗? → status = waiting_human -
我该放弃吗? → status = aborted
循环状态机
Observe ──► Orient ──► Decide ──► Act ──► Verify ──► Record
│ │ │ │ │ │
└── 读取HA记忆 ────────────────────────────────────────┘
│
┌──────────┴──────────┐
▼ ▼
done / blocked /
waiting_human aborted
模块四:一致性与恢复
解决的问题: 重启即失忆
大多数 AI Agent 的状态存在内存里。一旦重启,状态全丢。
Checkpoint 持久化
defsave_checkpoint(payload: dict) -> str:
"""持久化循环状态到 JSON 文件"""
CHECKPOINT_DIR.mkdir(parents=True, exist_ok=True)
path = CHECKPOINT_DIR / f"{goal_id}__{loop_id}.json"
path.write_text(json.dumps(payload, ensure_ascii=False, indent=2))
return str(path)
文件命名:goal_id__loop_id.json,例如:
state/checkpoints/产品调研__loop-abc123.json
Startup Rehydrate(启动回填)
重启后,系统自动做三件事:
-
扫描 checkpoint 目录,找出所有 active / blocked / waiting_human状态的任务 -
从 Neo4j 召回最近的相关记忆,重建上下文 -
输出可读的启动摘要
defstartup_rehydrate():
open_checkpoints = list_open_checkpoints()
ifnot open_checkpoints:
return"启动完成,无未完成任务"
for cp in open_checkpoints:
hits = recall(cp['goal_id'], top_k=3)
summary = generate_context_summary(hits)
print(f"[恢复] {cp['goal_id']} | 状态: {cp['status']}")
Deferred Sync(延迟同步)
状态变更先写 ledger 文件(append-only JSONL),再定期 flush 到主存储。程序崩溃时,ledger 里的记录不会丢。
defappend_ledger_event(entry: dict) -> dict:
"""追加事件到只读日志"""
with LEDGER_PATH.open("a", encoding="utf-8") as f:
f.write(json.dumps(entry, ensure_ascii=False) + "\n")
return entry
架构总览
┌─────────────────────────────────────────────────────────────┐
│ 用户请求入口 │
└────────────────────────┬────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────┐
│ 模块一:第一性原理运行时 (SOUL.md) │
│ 推理检查 → 拆解/怀疑/重建/拒绝跳步 │
└────────────────────────┬────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────┐
│ 模块三:自主循环执行器 (autonomous_loop.py) │
│ OODA 循环 → Observe → Orient → Decide → Act → Verify │
│ ↓ │
│ LoopState (带 checkpoint) │
└──────────┬──────────────────────────┬─────────────────────┘
▼ ▼
┌────────────────────────┐ ┌────────────────────────────────┐
│ 模块四:一致性恢复 │ │ 模块二:HA 情景记忆层 │
│ checkpoint_store.py │ │ Neo4j → SQLite FTS → grep │
│ startup_rehydrate.py │ │ (三级降级召回) │
│ sync_state.py │ └────────────────────────────────┘
│ sync_backfill.py │
└────────────────────────┘
改造前后对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
怎么用
git clone https://github.com/jiyangnan/agent-reinforcement-system.git
cd agent-reinforcement-system
# 依赖
pip install neo4j
# 启动 Neo4j
docker run -d -p 7474:7474 -p 7687:7687 neo4j:latest
# 记忆召回
python src/unified_memory_recall.py "我们讨论过什么"
# 启动自主循环
python src/autonomous_loop.py --goal "做一个市场调研"
我把项目直接开源了,具体咋用详细文档见仓库 README:
github.com/jiyangnan/agent-reinforcement-system
最后,真心感受一个真正可用的 AI Agent,不在于模型多强,而在于:它能不能记住、推理、行动,以及每次重启都还在原来的地方等你。
这四个模块解决了这三个问题。
如果对你有启发,欢迎去 GitHub 点个 star。代码可以直接拿去改,当然,你也可以丢给你的agent让他自己适配和修改。
如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐ 我们,下次再见。
当然,欢迎加我个人微信:baiyangwushi ,一起进白羊武士的修炼道场和其他同频道的朋友同频共振**,欢迎 AGI 时代的到来。 也期待在今后的日子里能够与你有羁绊,这是种微妙的感觉。希望我的一些想法能对你有所帮助。欢迎你的到来,修行者。