 夜雨聆风
夜雨聆风





AI 编程小白用codex,从 0-1 搭建图生服装电商视频网站

前段时间 AI 编程上瘾,寻思还能做点什么网站出来。
于是想到,现在团队日常视频产出不足,从生图到生视频到剪辑要跳好几个网站,能不能直接一键完成?
想着就来干个最基础版本。
基于我们团队的短视频打法,想了个框架,核心工作流程就是: 上传衣服白底图–>输入图片提示词–>生成模特+场景图–>输入视频提示词–>升成视频。
流程比较简单,因为团队的打法简单。
告诉codex 我的需求,并且让他做个网站,但是初版质量太差,做的太复杂了,于是我问了下 Claude 这个网站的全流程可以怎么做


同时我还让 Claude 直接给我出个提示词,我复制给 codex 让他帮我生网站。
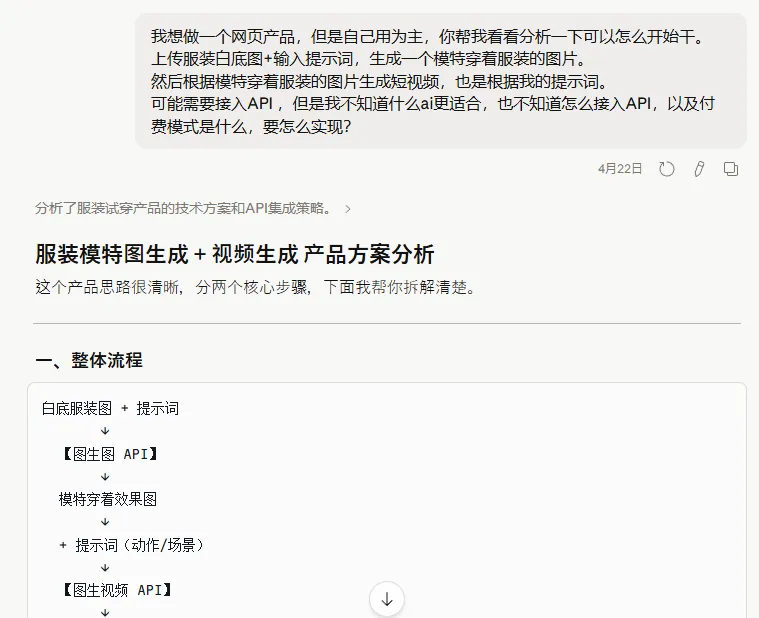

这是第一版
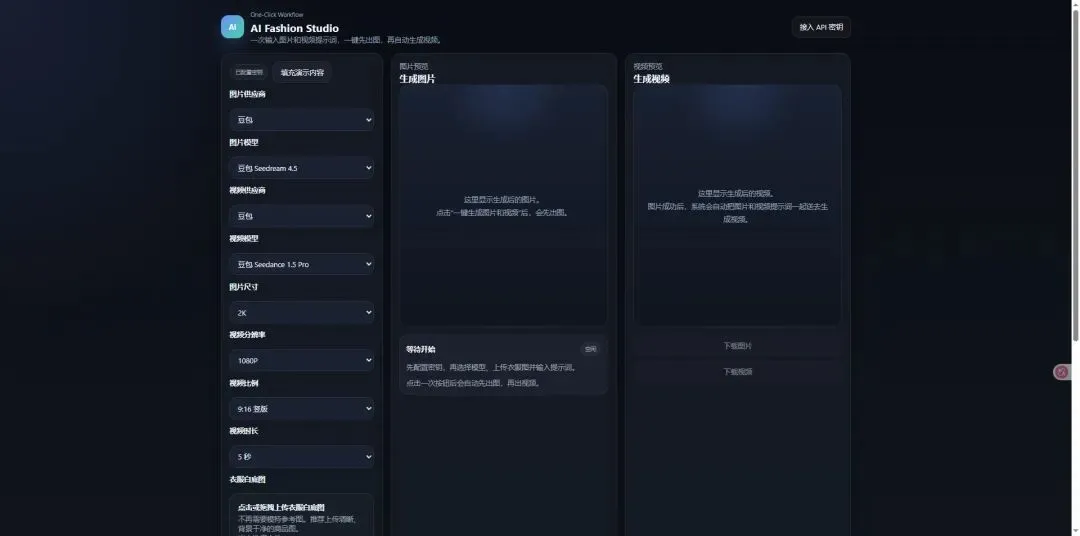
当时打算接入的可灵的 API,但是我没有付费啊,于是找了个豆包的免费模型来试试。
新注册可以领 50 万 token,足够测试把这个网站搭起来了。
(不是广哈,纯小白,分享给其他还没接入过 api 的小白,做测试,学习,能免费就免费)
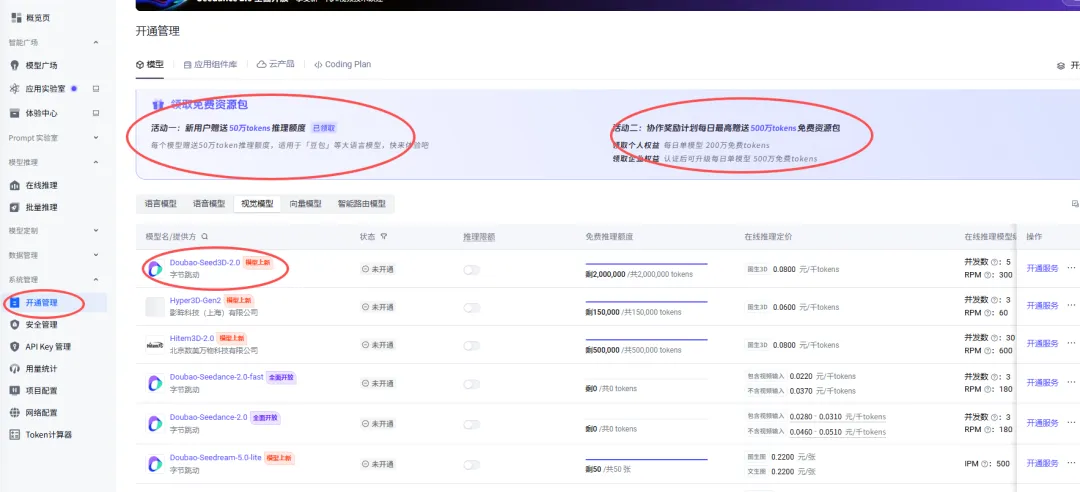
再对 codex 和他说,增加豆包 API 接口。
我的对话方式都是能讲话就讲话,讲话的时候表达欲会散发出来。
可以更好的把自己想的内容传达出来,AI 也能更有上下文,对你更了解。
用的是 typeless 的语音输入(电脑版),要付费,我现在用的试用版,他还会自己帮我排版。


做出来之后,也加了豆包密匙,生成失败。
这个步骤来来回回卡了半天,就是生不出来,他自己也找不到原因,最后的解决方法,我复盘了下大概是可以这样:
1.增加一个前端的错误原因,而不是单纯的乱码。
2.增加一个后端的日志,记录返回和发送的内容,让 AI 看错误的原因,自己修复。
当然了,也是和 AI 对话出来的结果。
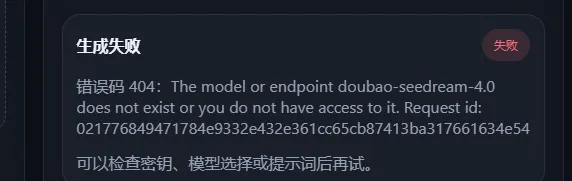

知道了错误原因,可能是 key 的错误,于是我根据 codex 提供的解决方法,上传了新的 key 和开通了权限(刚刚那个火山方舟的图片)
还有个生成不出来的原因可能是,官方不让 key 暴露在前端网页,很容易被攻击,于是我让 codex 做了个本地后端,把 key 通过后端去响应官方API


解决完后,可以生成视频了,就想优化下皮肤。
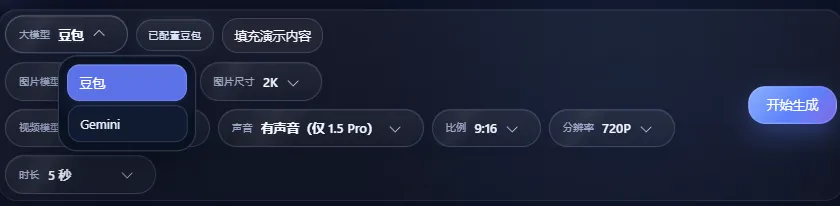
把最开始的可灵接口删了,想到应该可以改尺寸、比例、分辨率吧?
然后让codex 根据我所说的增加,分辨率,图片比例的选择项。


继续优化

到这一步比较关键。
我觉得和 AI 对话比较重要的是复盘成一个可以复用的工作流,或者提示词。
也能够通过AI 基于聊天上下文,帮你复盘你对 AI 是否有可以优化的部分。
这才是越使用AI越厉害的迭代方法。
于是我说:


codex 把我夸了一通,我承认很受用,听的很满意。
也提供了和他对话的模板,或者可以优化的方向,这个就挺有价值。




我没记得太多,想着每次都发一串指令,跟着他的模板讲话太反人类,但有个印象。
于是我把‘一次只改一类问题’记牢了,并且执行加深印象。
现在的情况就是,图片生视频中间没有停顿,如果生出来的图片有问题,就直接影响视频质量。
如果不能停下,直接浪费了一次 token。
于是我增加一个暂停功能,停止不达标的图片;
还有继续生成功能,通过审核的图片继续生成视频。


继续优化皮肤。
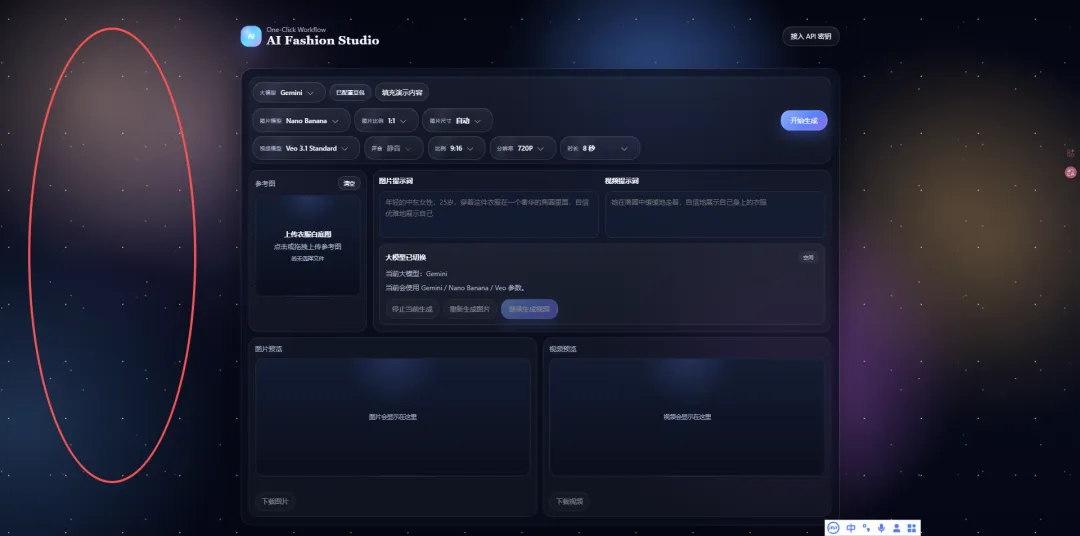
这两天看到一个网站,星空风格,挺喜欢的,于是让 ChatGPT 帮我做了张图。

做了美化之后就出现 bug 了。
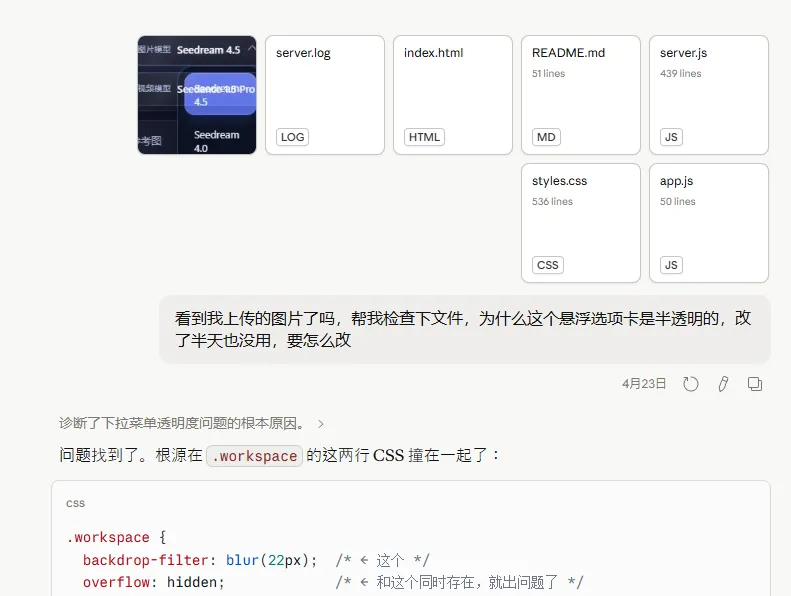
这个下拉选项卡背景是半透明的,用了各种提示词,各种不同方式的表达,还是解决不了。

于是我直接把所有文件发给 Claude 让他帮我检查。
虽然我用的还是免费版,但是不得不说真好用。
但我也很好奇,是表达不对,还是 codex 本身有局限。
为什么 Claude sonnet4.6 都能检查出来,5.4 查不出来呢,于是我继续问。
以下是回答,不感兴趣可以直接略过。
核心大意是,他一直在‘皮肤层’找问题,但问题出在了网页架构上。




现在也是彻底跑通了整个流程,但我突然想起来,我的 gemini 还有 300 美金的 API 赠金没用。
这不正好拿来提升嘛。
于是我基于刚刚的经验,1 是接入 API,2 是网页端直接可以通过选项调用不同的模型,3 是官方的模型太多,输出形式不同,我口述肯定不完整,让他自己做我也不放心。
于是我新开了个窗口了解下 gemini 的图片和视频模型收费和输出形式。
整理成一个可以复制的模板还有网站,直接发给执行 codex 来做。

效果很好,一次通过,不需要调试。
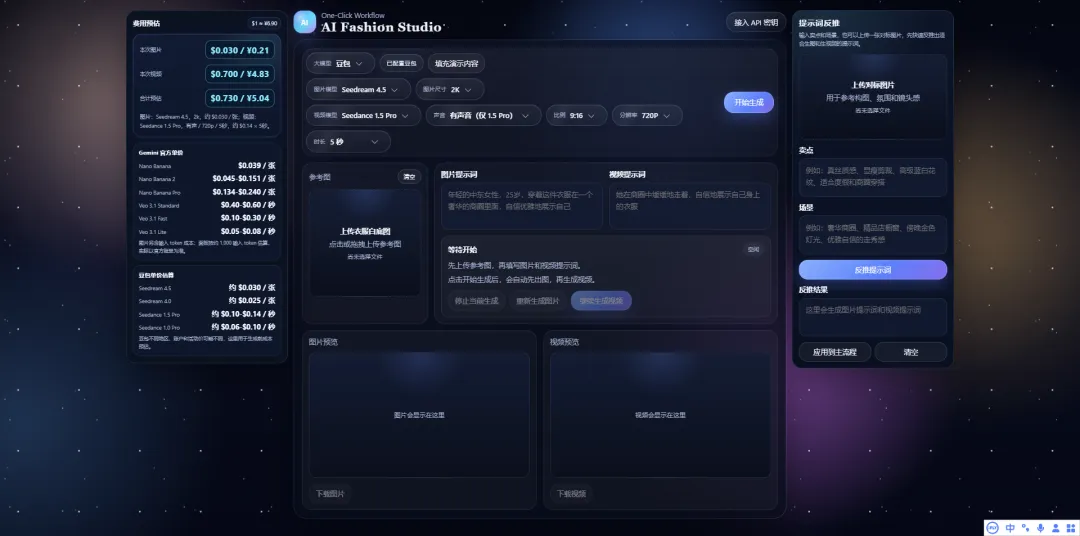
然后我本人真不知道那么多模型,之间有什么差别,到底要调用哪个,对我来说,最直观的体现就是价格。
于是我就想做个每一次调用大模型,可以自动帮我根据我的模型和输出做一个计费预估。
起码心里有个概念,一条视频生成出来多少钱。
我让 codex 帮我做一个。
提示词

最后我想了想,有时候并不是脑子凭空就有提示词,基本上都是基于对标视频来的。
于是我又增加了个提示词反推的窗口,这部分还没完善。
工作流程是,放入图片,内置一个视觉识别的模型,把场景,模特样貌风格,动作,都生成提示词。
并且还可以输入我自己的产品卖点信息,自动改成适合我的提示词,一键转入到工作区。

最后是网站整体效果
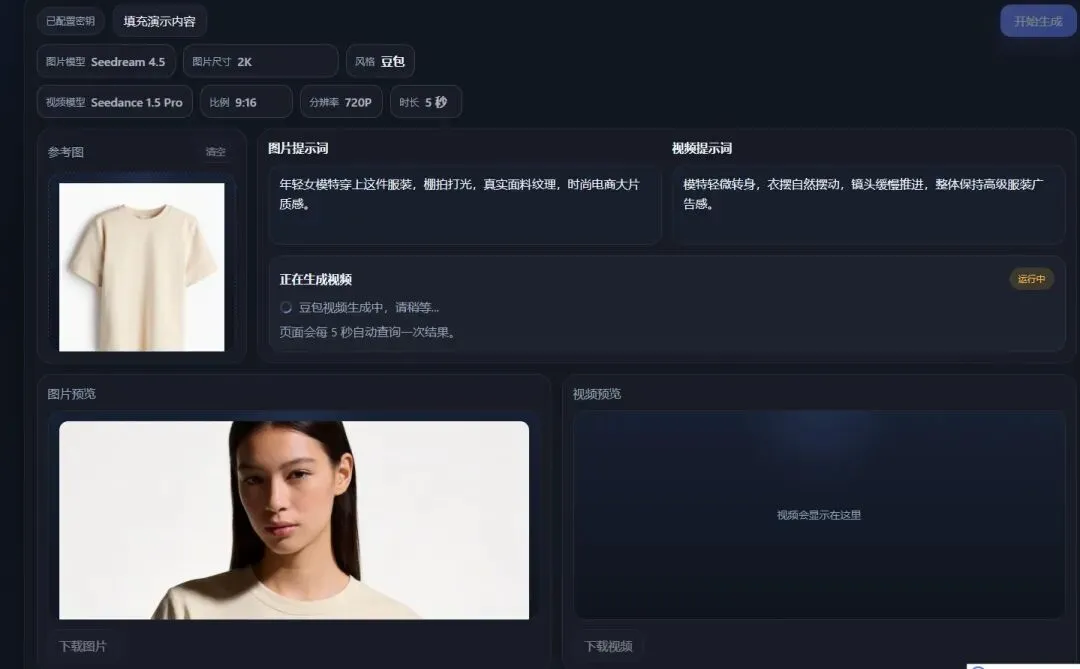
感谢观看,复盘文章比较枯燥,希望能够对你有启发。
也请有经验的大佬帮我看看,和 AI 交互的过程中有什么可以优化的。
感谢支持!