 夜雨聆风
夜雨聆风





2026年中美AI芯片技术差距缩小路径与系统级追赶策略深度研究


摘要
本研究基于2026年最新数据,系统分析中美AI芯片在三维度(制程工艺、单芯片性能、系统级能力)的差距现状,量化评估系统级创新对差距缩小的贡献度,研判国产替代路径与时间节点。核心发现:中国AI芯片自给率有望从2026年的33%提升至2030年的76%;在”每瓦及每美元性能”框架下,本土产品的商业价值显著凸显;全球AI算力格局正从”单芯片性能竞赛”转向”系统级效率竞赛”,为中国提供了弯道超车的结构性机遇[2]。
核心发现: – 制程差距约1.5-2个世代,但系统级创新可缩小实际应用差距至1倍左右 – 先进封装(2.5D/3D)和光互连技术成为追赶的关键突破口 – 推理经济学正在重构竞争规则,中国在成本和规模化部署方面具备优势 – 2026-2027年是技术路线选择的关键窗口期

引言
英伟达CEO黄仁勋在2025年11月闭门会上直言:“如果问未来5-10年生成式AI竞赛谁会赢,中国会赢。”高盛最新研报指出,中美核心AI技术差距已缩小至约3-6个月[4]。这一判断的背后,是中国AI芯片产业正在走出一条不同于美国的技术路线——不执着于单芯片性能的绝对领先,而是通过系统级架构创新实现”整体大于部分之和”的效果。
本报告聚焦一个核心问题:在制程工艺暂时落后的客观现实下,中国如何通过系统级创新路径缩小AI芯片差距?我们将从差距识别、原因分析、追赶策略、产业应用四个维度展开深度研究,为技术投资与产业决策提供参考。

技术差距概述
差距背景
这种外部约束倒逼中国加速构建本土半导体供应链。以政府和国企为主导的”主权AI”买家,以及三大电信运营商,将基础设施本土化视为核心战略。政策层面的强力支持为本土AI芯片度过早期产能与良率爬坡期提供了关键支撑。
差距范围
制程工艺维度:美国已进入台积电1.6nm(GAAFET)时代,中国SMIC N+2工艺约等效7nm,存在约2个世代的差距[6]。但值得关注的是,SMIC正通过DUV多重图案化技术向N+3(约5nm)演进。
单芯片性能维度:英伟达Blackwell架构GPU在训练场景仍保持显著领先,但华为昇腾910C(120 TFLOPS)预计2026年下半年量产后,将在推理场景接近H100水平。
系统级能力维度:差距正在快速缩小。华为CloudMatrix 384、阿里PPU架构、字节256加速器机架设计,通过规模化架构弥补单芯片性能差距[7]。
差距影响
产业安全层面:中国AI算力需求正在快速本土化,2026年本土芯片不再只是出口管制下的替代方案,而逐渐成为AI算力体系的结构性组成部分。
经济成本层面:摩根士丹利测算,中国云计算行业2030年整体资本开支将达1300亿美元,其中51%用于AI GPU相关设备。国产化替代将显著降低长期TCO。
战略竞争层面:全球AI算力格局正在重塑。美国占69%,中国15%,但中国集群数量达230个,在规模化部署能力上具备独特优势[8]。

技术差距分析
差距识别
差距1:先进制程工艺 – 美国:台积电1.6nm量产中,Intel 18A/14A推进中 – 中国:SMIC N+2(约7nm)量产,N+3(约5nm)研发中 – 差距评估:约1.5-2个世代,但可通过DUV多重图案化缩小至1-1.5个世代[9]
差距2:EDA工具与设计能力 – 美国:Synopsys、Cadence、Mentor垄断全流程EDA – 中国:华为联合国内企业完成14nm全流程EDA替代,7nm以下自主设计能力2025年实现 – 差距评估:设计工具链仍有差距,但基础能力已建立
差距3:先进封装与Chiplet – 美国:台积电CoWoS、Intel EMIB/Foveros领先 – 中国:长电科技XDFOI稳定量产,通富微电承接AMD 70-80%封测订单 – 差距评估:差距正在快速缩小,部分领域已达国际先进水平[10]
差距4:光互连技术 – 美国:英伟达Feynman首次大规模引入硅光子互连(2026年GTC发布) – 中国:中际旭创800G先发优势,硅光产品研发加速 – 差距评估:在光模块领域差距较小,但CPO芯片侧集成仍有距离
差距度量
量化指标二:系统级算力 – 英伟达NVL72:约1.44 exaflops FP4(72颗B200) – 华为CloudMatrix 384:约300 PFlops(384颗昇腾+192颗鲲鹏) – 系统级差距缩小至约1.5-2倍
量化指标三:推理经济性(关键指标) – 摩根士丹利引入”每瓦及每美元性能”评估框架 – 在该框架下,中国本土AI GPU的商业价值显著凸显 – 中国大模型日均Token消耗量已突破10万亿,推理经济性成为核心竞争指标[11]
差距分类
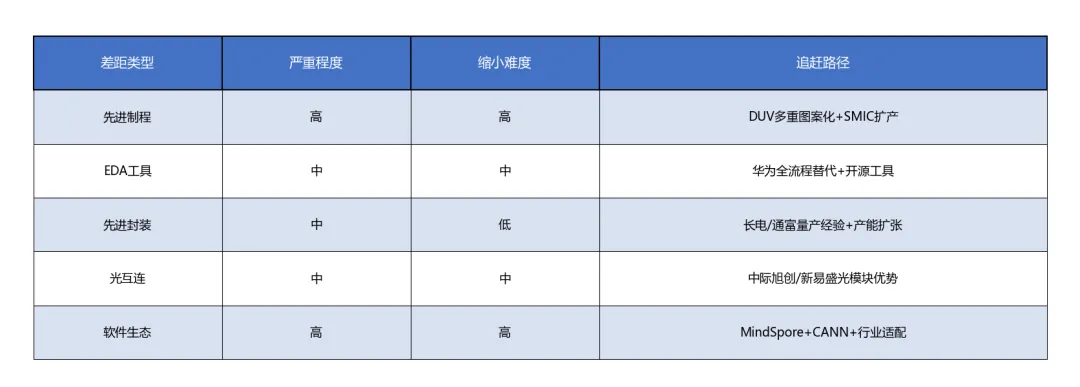
表格2
差距演化

原因分析
技术因素
国内AI产业长期存在”重应用、轻基础”倾向。在物理、化学、材料学等底层科学积累不足,导致原创性技术突破乏力[13]。这一短板在EDA工具、光刻机、先进制程材料等领域尤为突出。
关键技术受制于人: – EUV光刻机:ASML High-NA EUV无法对华出口,制约3nm以下制程 – 高端EDA:全流程工具链仍由美企垄断,7nm以下设计验证能力不足 – HBM存储:SK海力士、三星主导,国产替代进展缓慢
但存在积极变化: – 首台商用电子束光刻机”羲之”量产,支撑量子芯片研发 – 国产设备已支撑起国产产线70%的需求,北方华创刻蚀机、上海微电子光刻机实现突破 – 中国计划未来五年新建21座芯片制造厂,到2030年产能占全球28%
产业因素
产能瓶颈: SMIC N+2产能2026年约4万片/月,2027年约5.1万片/月。但这些产能需同时满足智能手机、汽车SoC、AI GPU等多领域需求,AI GPU可分配产能有限[14]。
成本优势显现: 中芯国际28nm晶圆厂单位成本比台积电同类产线低40%,成熟制程领域已具备全球竞争力。在”成熟制程+先进封装”组合策略下,成本优势将进一步放大。
政策因素
美国政策演进: 从全面封锁转向”精准管制+技术租赁”模式。放行H200但附加25%销售分成,既赚取中国市场收益,又维持技术代差控制。这种策略短期内缓解了中国算力缺口,但长期倒逼自主可控加速。
资源因素
人才储备:高端复合型人才仍不足,缺乏具备理论和规模应用经验的顶尖领军人才。但华为、寒武纪等企业通过”工程硕士+产业实践”模式加速人才培养。
电力基础设施:中国电网适合大干快上,数据中心建设速度显著快于美国,在AI基础设施规模化部署方面具备结构性优势[15]。

国际对比
全球技术格局
Epoch AI数据显示,美国占全球GPU集群性能75%,中国15%。但中国在集群数量和规模化部署能力上具有独特优势——230个集群意味着更丰富的工程实践经验和迭代速度。
领先国家分析
对中国启示: 单纯复制美国路线难以成功,必须走出差异化路径。正如华为昇腾选择”异构计算+系统级优化”路线,在自然语言处理场景中性能达到传统GPU的3倍,功耗降低50%[16]。
追赶国家分析
中国的差异化优势在于:庞大的本土市场、完整的工业体系、以及”政策+市场”双轮驱动的产业模式。
对比启示

追赶策略分析
技术追赶路径
路径一:制程工艺渐进追赶 – SMIC通过DUV多重图案化推进N+2/N+3节点 – 目标:2027年实现等效5nm量产,缩小至1个世代以内 – 风险:EUV禁运限制3nm以下突破,需依赖技术创新绕过物理极限
路径二:先进封装弯道超车 – 长电科技XDFOI Chiplet工艺已进入稳定量产 – 通富微电承接AMD 70-80%封测订单,验证技术能力 – 2026年全球先进封装占比已突破55%,中国企业在PLP面板级封装等领域形成差异化竞争力[17]
路径三:系统架构降维打击 – 华为CloudMatrix 384:384颗昇腾NPU+192颗鲲鹏CPU全对等互联,300 PFlops算力 – 阿里PPU架构、字节256加速器机架设计 – 通过规模化架构弥补单芯片性能差距,在推理场景实现”整体大于部分之和”
追赶策略选择
训练场景(高算力需求): – 短期依赖进口+国产混合部署 – 中期通过集群架构提升有效算力 – 长期目标:昇腾910C级芯片规模化替代
推理场景(经济性优先): – 国产芯片已具备竞争力 – 重点优化”每瓦及每美元性能” – 寒武纪思元590推理性能提升300%,支持FP8格式[18]
边缘场景(低功耗需求): – 端侧AI芯片(瑞芯微、全志科技)快速迭代 – 存算一体芯片商用加速,能效比提升10倍
追赶案例分析
追赶中案例:寒武纪 – 思元590在推理场景性能显著提升 – 但软件栈优化仍在进行中,生态建设是长期挑战
追赶风险评估

产业应用分析
技术转化
云计算中心: – 华为昇腾910B已在华为云、电信运营商数据中心规模化部署 – 阿里云、腾讯云开始测试国产芯片推理集群
工业质检: – 搭载寒武纪MLU370-S4芯片的智能相机,能同步处理8路4K视频流 – 某3C电子工厂电路板焊点检测准确率飙到99.97%
医疗影像: – 推想科技专用诊断芯片已覆盖90%三甲医院 – 肺部CT阅片从30分钟压缩到1分钟[20]
产业升级
PCB产业: – 中国高端多层板份额快速提升,2026年3月海关数据显示集成电路及相关组件出口额同比暴涨72.6% – 沪电股份、景旺电子在28层以上高层板良率上已追平台系巨头
新兴产业培育
人形机器人:高端场景对64TOPS以上算力芯片需求激增,端侧AI芯片形成低功耗入门级(<1TOPS)、中算力主流级(1-16TOPS)、高算力高端级(≥16TOPS)金字塔结构。
传统产业改造
能源行业:AI芯片赋能电网智能化调度,中国电网优势与AI算力需求形成正向循环。

政策支持分析
政策体系
国家战略层: – 《电子信息制造业2025-2026年稳增长行动方案》:面向光子领域重点环节开展技术攻关 – 国务院”2027年国产AI芯片自给率超70%“目标 -”特殊情况才批准采购”底线政策,既保障短期算力又倒逼长期自主
产业基金层: – 国家集成电路产业基金三期3440亿元 – 上海500亿元、北京300亿元、深圳200亿元地方产业基金 – 社会资本参与,形成”国家队+民间队”协同格局
财税支持层: – 14纳米以下制程企业税收返还 – 研发费用加计扣除比例提升至120% – 进口设备免税政策延续
政策工具
间接支持工具: – 应用场景开放:政府项目、国企项目优先使用国产AI解决方案 – 标准制定:推动国产AI计算标准成为行业标准 – 国际合作:通过”一带一路”输出中国AI芯片解决方案
政策协同
政企协同:华为、阿里等头部企业成为政策执行主体,通过”揭榜挂帅”承担关键核心技术攻关任务。
产学研协同:高校基础研究+企业工程化+资本产业化,形成完整创新链。
政策建议

未来展望
技术趋势
趋势二:Chiplet与先进封装成性能提升关键 先进制程逼近物理极限,2.5D/3D封装、CoWoS、TSV等技术加速普及。通过芯粒异构集成实现算力、存储、I/O协同优化,降低对先进制程依赖。预计2026年后,高端算力芯片的标准方案将是”Chiplet+先进封装”组合。
趋势三:光互连进入规模部署阶段 英伟达Feynman架构首次大规模引入硅光子互连,CPO技术从技术验证期向早期商业化过渡。中国光模块厂商(中际旭创、新易盛)在800G/1.6T领域具备全球竞争力,但在CPO芯片侧集成方面仍需追赶[21]。
差距演化
但需清醒认识:7纳米以下芯片制程、高端光刻机等领域仍有根本性差距。短期追不上先进制程,就先补生态、抓应用;拿不到高端芯片,就先做好本土替代。
追赶前景
基准情景(概率45%): 差距持续缩小但无法完全消除,形成”有限领先+部分并跑”格局。
悲观情景(概率15%): 美国加强管制+AI范式突变,追赶窗口关闭。
战略机遇

结论与建议
核心观点
战略建议
中期(2028-2029): 1. 构建自主软件生态,降低CUDA转换成本 2. 推动Chiplet标准制定,形成产业联盟 3. 在CPO/光互连领域加大投入,缩小与Feynman架构差距
长期(2030+): 1. 实现7nm以下全流程自主可控 2. 在部分细分场景(边缘推理、特定行业应用)实现领先
政策建议
实施路径

数据来源

附录
技术差距清单表
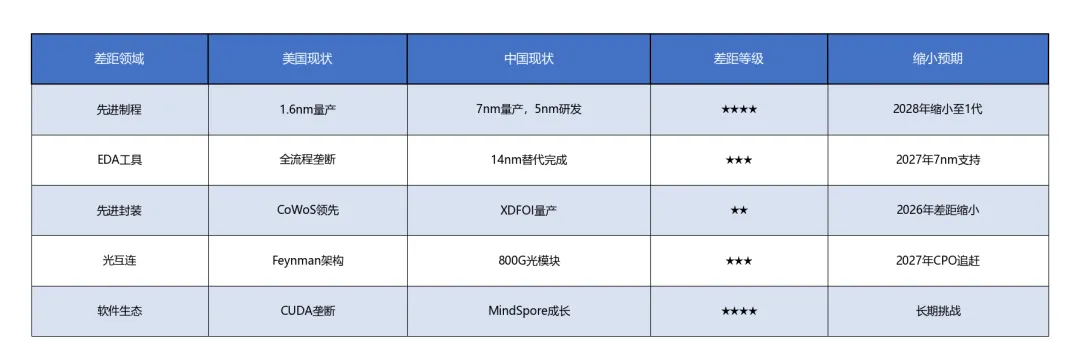
表格3
国际对比数据表
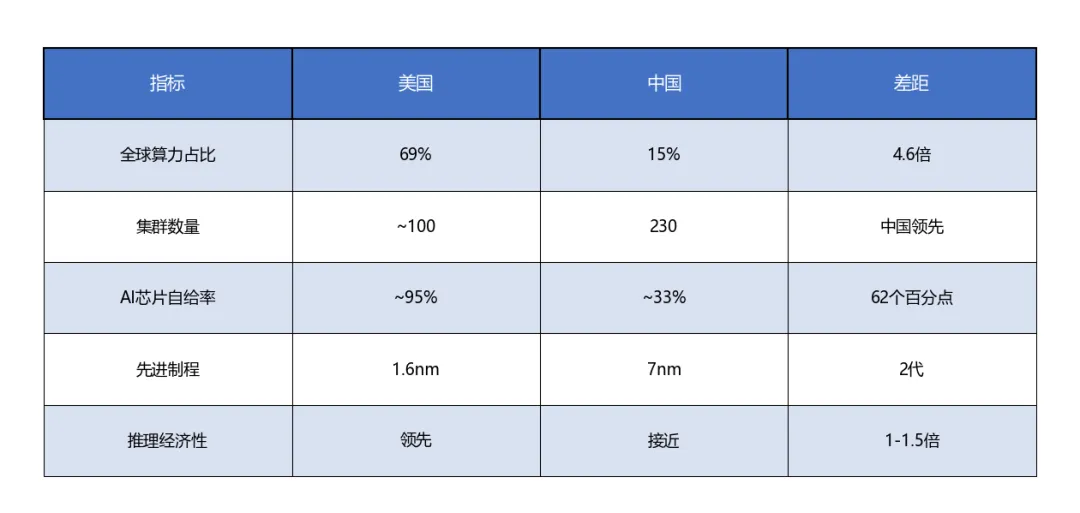
表格4
追赶路径图

代码1

研究者观察
独立观点
当前舆论对中美AI芯片差距的讨论存在两个误区:一是过度关注制程数字,忽视了系统级性能的乘数效应;二是将”自主可控”简化为”完全替代”,忽略了渐进式替代的可行性。
我认为,真正的差距在于”持续迭代能力”。美国的技术领先不仅体现在当前产品,更体现在从设计到制造的完整迭代闭环——每一代新产品都能在18-24个月内推出。中国当前面临的最大挑战不是某一代产品的性能差距,而是如何建立可持续的迭代机制。SMIC N+2的量产经验、长电XDFOI的量产验证、华为昇腾从910B到910C的快速迭代,都在证明这一能力正在形成。
观点二:推理经济学正在重写竞争规则,中国有结构性优势
英伟达GTC 2026的核心信号是”推理取代训练”,这一范式转移对中国的意义被严重低估。推理场景的核心指标不是峰值算力,而是”每Token成本”——这正是中国厂商的结构性优势所在。
中国在推理经济学的优势来自三个维度: 1. 电力成本:中国工业电价约为美国的60%,在7×24小时运行的推理中心,电力成本差异会直接转化为TCO优势 2. 工程效率:230个集群的规模化部署经验,意味着更成熟的散热方案、更优化的网络拓扑、更高效的运维体系 3. 市场密度:中国大模型日均Token消耗突破10万亿,庞大的本土需求为国产芯片提供了”试错-迭代”的闭环
我判断,到2027年,中国在推理场景可能出现”性能接近+成本更低”的组合优势,这是改变竞争格局的关键变量。
跨维度分析
自主×引进:当前”有限开放+自主可控”策略是理性的。完全封闭会导致技术脱钩加速,完全开放会削弱自主研发动力。美国放行H200但附加25%分成的做法,客观上为中国提供了”低成本学习窗口”——既能获得必要算力维持产业运转,又能看清技术差距的具体位置,为自主研发提供精准目标。
