 夜雨聆风
夜雨聆风





AI大乱斗!DeepSeek V4 vs GPT-5.5 vs Claude 4.7
2026 年 4 月底,“价格屠夫”DeepSeek 带着 V4 预览版直接掀了桌子。
这次 DeepSeek 的出场方式极其“抽象”:它就像一个不按常理出牌的穷小子,平时闷声不响躲在实验室吃泡面,突然有一天掏出了神兵利器,对着英伟达的“垄断大坝”就是一记重锤。
V4 不仅把“百万上下文”变成了全系标配,还顺带把底层架构给重构了。
这感觉就像是人家在卖 8 万一平的精装房,它突然在隔壁开了个盘,精装修还送百万平米花园,单价只要八百块。
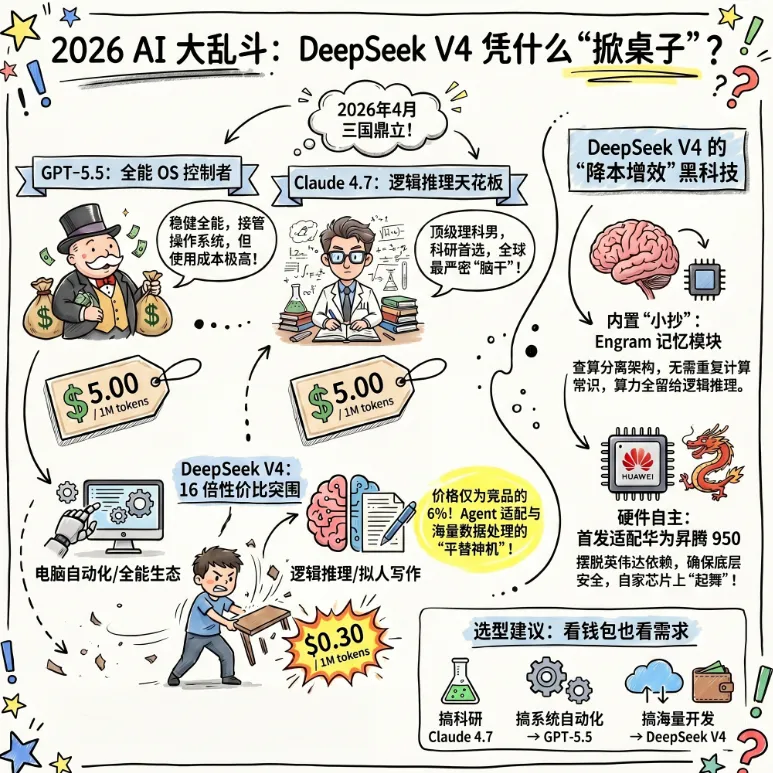
三国演义:DeepSeek V4 vs GPT-5.5 vs Claude 4.7
模型名称 / 输入价格(每 1M tokens) / 输出价格(每 1M tokens) / 上下文长度 / 核心强项
GPT-5.5: 输入价格 (每 1M tokens) $5.00;输出价格 (每 1M tokens) $30.00;上下文长度 1M;核心强项是电脑自动化、OS 控制、全能生态
Claude 4.7: 输入价格 (每 1M tokens) $5.00;输出价格 (每 1M tokens) $25.00;上下文长度 1M;核心强项是顶级逻辑推理、拟人写作、科研战神
DeepSeek V4: 输入价格 (每 1M tokens) $0.30;输出价格 (每 1M tokens) $0.50;上下文长度 1M;核心强项是 16 倍性价比、Agent 适配、国产算力
GPT-5.5:全能地主老财。 它是那种各方面都稳得可怕的选手。在 OSWorld-Verified(78.7%)和 Terminal-Bench 2.0(82.7%)上,它依然是能直接替你操作电脑、像个真人一样用命令行干活的“顶级牛马”。但价格是真的黑,甚至有英伟达工程师吐槽:“失去 GPT-5.5 的访问权限就像是被截肢”。它就是个让你用上瘾后疯狂抽血的重税机器。
Claude 4.7:文艺理科男。 逻辑推理的天花板,读 PhD 论文的首选。它的“脑干”确实贵,虽然在 API 价格上比 GPT 厚道一丁点,但在极高难度的“Think Max”模式下,它的推理严密性依然是全球第一。DeepSeek V4 虽然在追,但遇到那种变态的逻辑题,还得是 Claude 才能“脑补”出来。
DeepSeek V4:国产卷王。 核心优势就是一个字:省。输入价格只要 $0.30,跟 GPT-5.5 差了整整 16 倍多!而且它不仅仅是便宜,在 Claude Code 和 OpenClaw 等 Agent 工具的适配上极其丝滑,简直就是为了给 Agent 当“发动机”而生的。
DeepSeek V4 的“三板斧”与“软肋”
DeepSeek 凭什么能把“推理效率(Inference Efficiency)”压到这个地步?
优势分析:
内置“小抄”:Engram 记忆模块。别听那些术语,大白话解释:V4 引入了 Engram(条件记忆),就像给模型配了个内置字典。以前模型回答“1+1”都要动脑子算一遍,现在这种常识性的东西直接去“字典”里查。这种“查算分离”的架构让它不用浪费脑力去复读常识,把算力全留给逻辑推理。这才是它敢把价格打到骨折的底层底气。
百万上下文标配:吃书不吐骨头。现在 1M 上下文成了标配,你可以把《三体》全集塞进去,它不仅能瞬间定位“大海捞针”,单 token 的计算成本还比 V3.2 降了快 4 倍。
硬件自主:不看老黄脸色。首发适配华为昇腾 950。这意味着即便英伟达的卡不卖了,咱们自家的模型照样能在自家芯片上“起舞”。这就是所谓的底层安全性,也是国产模型的“护城河”。
劣势分析:
智力梯队仍有级差: 说实话,在“硬碰硬”的 PhD 级逻辑挑战下,DeepSeek V4-Pro 虽然接近了 Claude Opus 4.6 的非思考模式,但跟开启了全力模式的 Claude 4.7 相比,逻辑链的韧性还是略逊一筹。
高端算力还得等: 虽然适配了华为,但昇腾 950 的大规模批量供货要等 2026 年下半年。所以现在的预览版有时候会排队,吞吐量(Throughput)受限,这属于典型的“有神兵但还没全装配上”。
2026 年我们到底到哪了?
现在的国产模型圈,已经不再是只会复读的小卡拉米了:
Qwen 3.6:数学和多模态能力依然硬核,阿里系的底子还是厚。
Kimi K2.6:长文本的老祖宗,虽然被 DeepSeek 逼得很紧,但在搜索 Agent 领域依旧有独特的粘性。
GLM-5.1:在代码竞赛上跟 GPT-5 掰手腕的常客。
现状总结: 国产模型走的是一条“先卷价格,再卷性能,最后卷硬件绑定”的硬核突围路。在全球范围内,最便宜且能干重活的高级 API,现在就在中国。
你到底该选哪一个?
别纠结了,选模型其实就是选钱包和需求之间的平衡:
搞顶尖科研、写需要灵魂的文案、处理变态复杂的 Ph.D 级逻辑: 咬牙上 Claude 4.7。它的“脑子”确实值那个价。
追求极致全能、预算拉满、想让 AI 帮你接管整个操作系统: 选 GPT-5.5。虽然贵得想“截肢”,但在电脑自动化操作上,它依然是你唯一的真神。
搞本地化开发、批量处理海量数据、钱包比较紧: DeepSeek V4 闭眼入。同样的预算,GPT 刚开个头,DeepSeek 能帮你把活儿干完顺便把报表都生成了。
你还有看法?一起来聊聊吧~
