夜雨聆风
夜雨聆风





AI也有斩s线,DeepSeek是抵在全球所有大模型后脑勺的枪
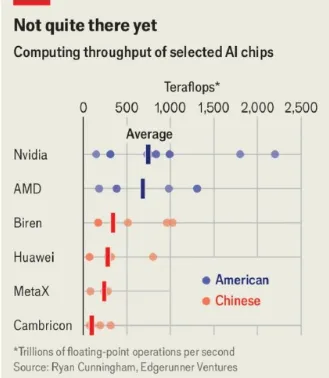
AI行业每天变动不已,看似矛盾的结论也不意外。
一方面,DeepSeek V4千呼万唤始出来以后,让国产开源模型再攀性能高峰,给美国AI大厂带来的威胁是Kill Line(商业生死线);
另一方面,自DeepSeek R1发布这一年多以来,中国最强大的模型和美国最强大的模型之间的差距实际上在慢慢扩大。
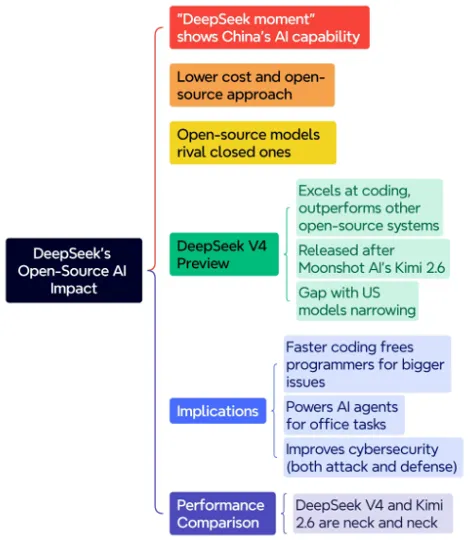
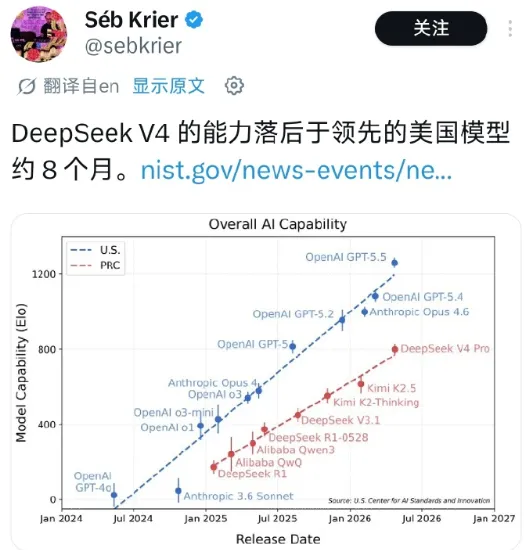
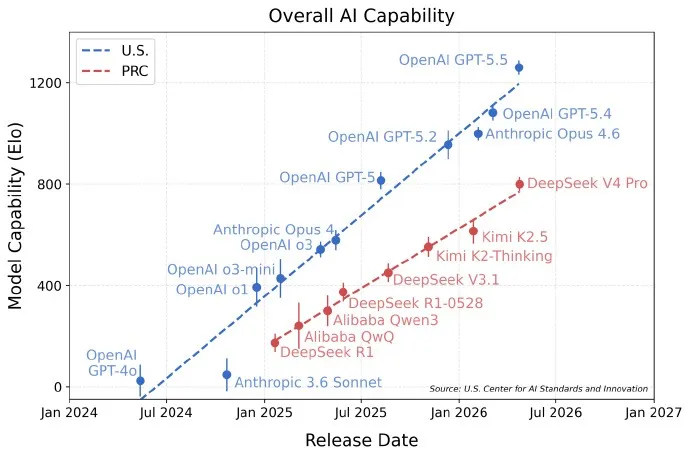
5月1日,美国国家标准与技术研究院(NIST)下属的人工智能标准与创新中心(CAISI)发布了对DeepSeek V4的测试,结论是:
1、DeepSeek V4是迄今为止CAISI评估过的最强大的中国AI模型。
2、CAISI认为DeepSeek V4的整体性能相当于8个月前发布的GPT-5,与美国顶尖模型存在约8个月技术代差。而DeepSeek自己的测试报告则认为与Opus 4.6和GPT-5.4类似,落后5-6个月。
3、DeepSeek V4在网络安全、复杂工程和抽象推理领域显著落后,但在数学推理、编程能力、自然科学上与国际前沿水平相当。
4、和同类模型相比,DeepSeek V4最大的优势是成本低廉,成本控制(API价格仅为竞品1/700)表现突出,美方担忧中国“国模+国芯”战略削弱芯片封锁效果。
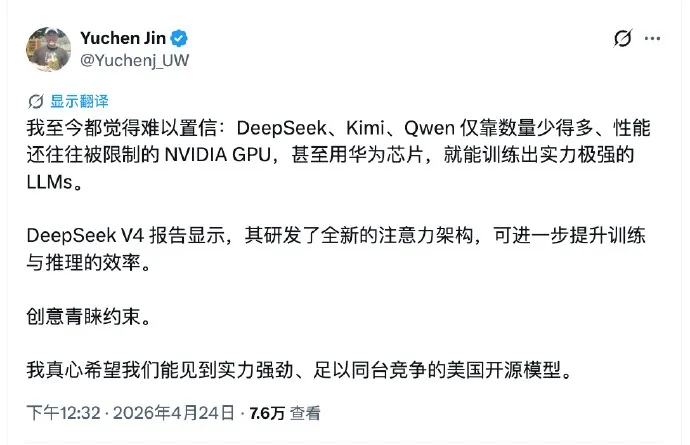
前OpenAI研究员Jenny Xiao提出了一个很多人意识到但是不敢说或者不愿意说的观点:
DeepSeek是抵在全球所有大模型公司脑门背后的枪,如果这些基础AI跑得不够快,更激进点说如果不是最强,那么它们的价值会瞬间“归零”。OpenAI也不例外。
在AI热潮中,赢者不一定能保证通吃,但输者一定会归零。
重点不是DeepSeek V4落后于硅谷几个月,而是全球AI公司都要感谢DeepSeek的后进鞭策、创新威慑。如果这些美国公司不拼命往前跑,一旦被中国更便宜高性能的开源模型追上,他们苦心经营、制造AI末日恐慌营销的商业帝国就会崩溃。
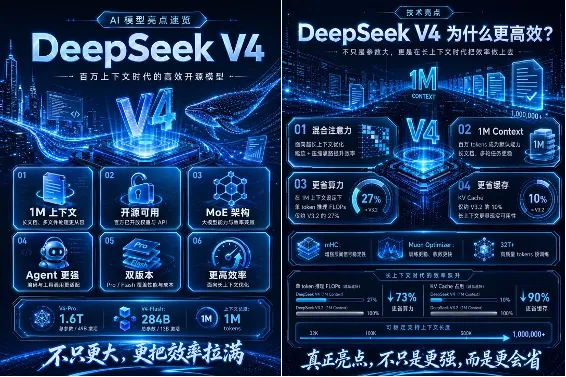
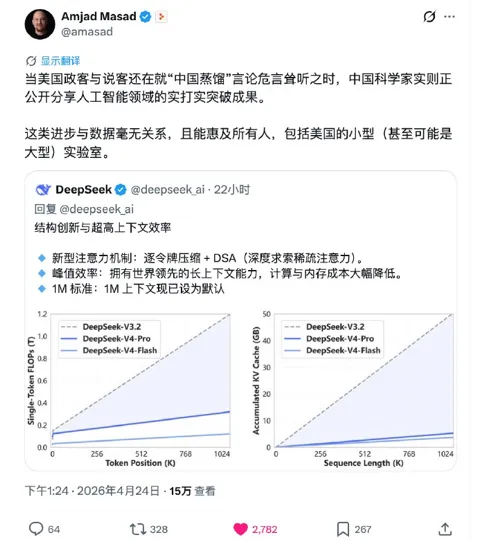
4月24日,国产AI之光DeepSeek正式发布V4系列模型,瞬间引爆全球AI圈。🎯 核心突破:• 标配100万Token超长上下文,全免费• 完全适配华为昇腾芯片,国产算力自主可控• Pro版本总参数1.6T,性能对标全球顶尖闭源模型• Flash版本效率大幅提升,KV缓存占用压缩至前代7%💡 性能数据炸裂:• 百万级上下文场景,单token推理计算量降至前代27%• 开源社区评测登顶,编程能力超越GPT-5.4• 与华为昇腾950深度适配,下半年API定价有望大幅下调DeepSeek V4让”用开源模型实现闭源性能”成为现实。更关键的是,深度适配国产算力意味着——中国企业用芯片,以后不用再看英伟达的脸色了。
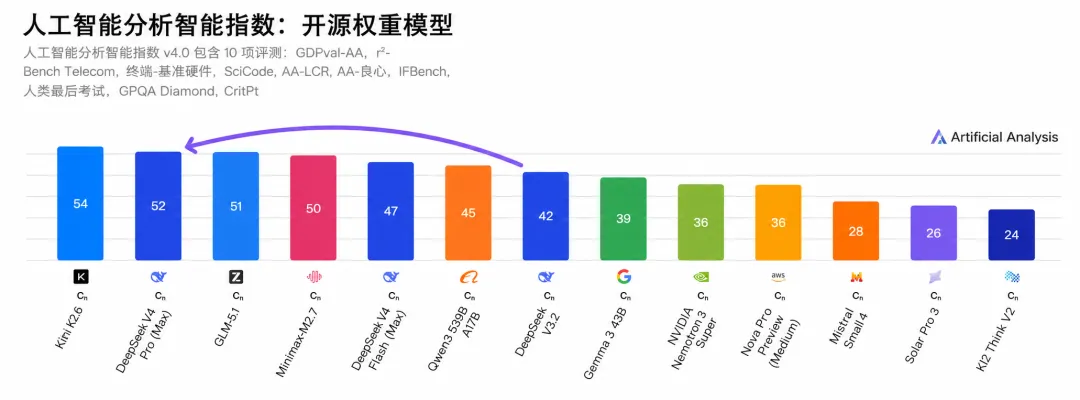
在全球权威Artificial Analysis智能指数开源模型榜单上,DeepSeek V4 Pro(Max)相比上一代模型V3.2提升了10分,以52分进入全球开源模型的前两位。第一是万亿参数开源模型Kimi K2.6。
全球开源前五大AI,都是中国模型了。
导演侯孝贤说过,有限制才有自由。
中国的AI和芯片公司,面临算力资源约束和商业化的多重高压,被倒逼着不能盲目追求指数规模,必须在硬件设计和模型效率上搞砸到底。
经济学人称,DeepSeek、华w等公司在极限中创新,巧妙避开国外限制,对准模型效率(Token Efficiency),依靠“模糊数学”把制造工具做到极限,通过芯片集群弥补单个芯片性能不足,并融合软硬件来榨取每一分性能。