 夜雨聆风
夜雨聆风





AI Agent这两年很火?说实话,刚开始它连天气都查不准
今天想说下agent的发家史以及这一路的llm一线工程师的经历,还有agent的未来在哪儿呢?
2022年ChatGPT出来后,就有种声音“NLP不存在了”。chatgpt在nlp所有任务上横扫soto模型。我们搞nlp的,以前是什么任务都得标注数据、训练、上线、翻车再回来改。然后chatGPT来了–一个模型,什么都能聊。
兴奋劲过后,其实也没有多兴奋,都是自媒体带的各种节奏,于是作为一个资深的NLPer,一个致命的问题:它能聊,但是不能干啊。
简单的任务,你albert微调成本可比gpt成本低多了,复杂的任务gpt也不太行。再说应用,让它查天气,给你一个随机的天气。整理邮箱,它说“只能提供文本建议”。让他处理excel,它生成一段跑不起来的python代码让你自己跑,没啥意义。
一个只会动嘴的AI,跟只会做PPT的程序员有啥区别?
这就是Agent故事的起点了— 不是 “这个技术好酷”,而是“它能干点啥实事才行”。
后来三年发生的事,就像是跟LLM不断装手脚的过程。从AutoGPT的疯狂是错,到langchain的工程化尝试,到MCP/ACP协议的统一,再到Claude Code和OpenClaw的系统化。整个过程的核心点就是:
怎么让一个非确定性的,会胡编乱造的、没有常识的模型,稳定的干成一件具体的事?
这篇文章,就是一个NLPer在这些年看到、踩过、想明白又或是想不明白的东西。
第一章:AutoGPT的炸场–第一次看见LLM“动手”
那个让人上头且头疼的项目。
2024年3月,AutoGPT在github上几天拦了几万star,估计还不止,不记得了,就很火。
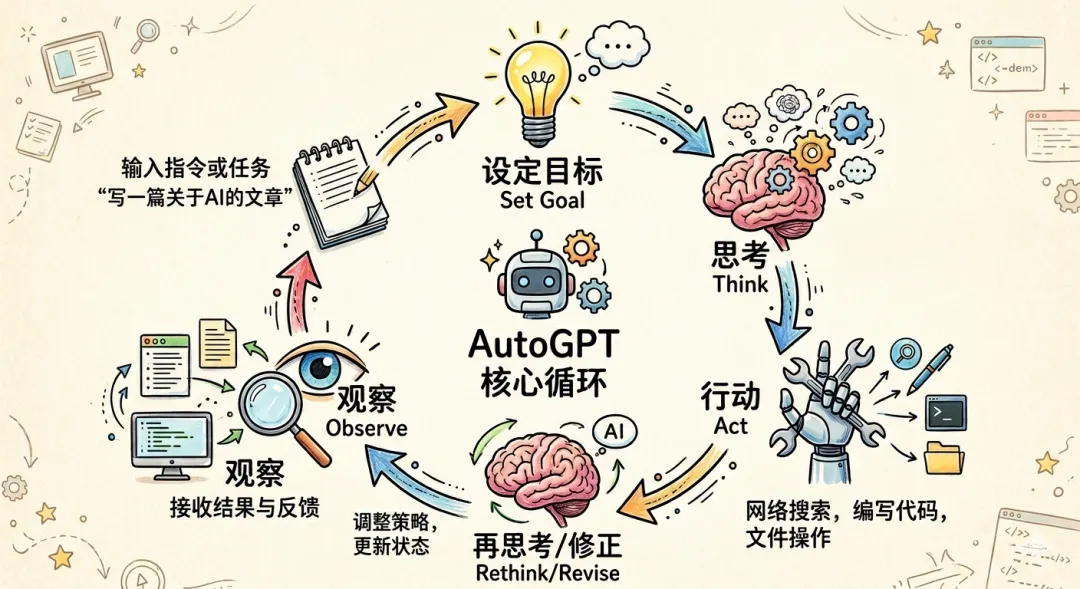
它的逻辑其实很简单,通俗点说就是:给AI一个目标,让它不断问自己“下一步该干嘛”,执行,观察,再问自己“现在该做什么”… 无限循环,不达目的不罢休。
我当时就拿它跑了一个很简单任务,帮我干嘛来着,反正就很简单,然后就看到它自己干了这些事:
打开浏览器、搜索、返回、继续搜索,然后不知道在循环个什么,虽然具体的印象很模糊了,但是可以在日志窗口看到它的“内心独白”,像是个人,在自言自语的干活–虽然很蠢,但确实在动,在做了。
然后开源社区就疯了–各种类agent层出不穷
AutoGPT一火,后面跟风的项目就灭听过。
比如,BabyAGI,更加细化流程,它搞了个任务管理系统。内部有三个agent:执行任务的、根据结果创建新任务的、给所有任务排优先级的。你给它一个目标,能拆成十几个任务,像项目经理一样。比autoGPT靠谱,但实际操作,能力也不太行,受限于LLM本身的能力,写不了代码,也就处理不了很多实际的事。
除了这两个,还有superAGI、huggingGPT等等一堆项目,github隔几天就会冒出一个。
热闹归热闹,实际跑下来基本也就那回事。
人人上头,人人头疼。
我们当时自己搭建了autoGPT,一个调研竞对的任务,跑了40分钟,调了30多次api,花掉了好几美元,产出是几页非常普通的总结。还有些任务,直接循环到上限也没出结果,纯粹再烧钱了。
最常见的几个问题:
-
死循环家常便饭 -
目标漂移 -
token消耗巨大
Langchain差不多也是这时候开始活跃的。我们当时还挺排斥它的—它本质上就是把LLM能力套了层封装,prompt模板、chain、内存管理,看着方便,但对于我们来说,用起来处处是坑,底层调试非常麻烦,报错排查也很麻烦。
当时力推的ReAct模式本质上就是“思考->行动->观察->再思考”的循环。思想很好,但当时LLM能力就那样,几步下来就出错–工具格式调不对、要调A却调了B、返回了结果不知道下一步怎么解读。10步以上的长任务,完成率只有28%。
从那个时候开始,Agent概念才开始火起来了,但生产环境里根本没法用的。我们公司利用llm的地方依然就是老老实实做文案编写/转写和角色扮演。agent那个方向,大家觉得“未来是这么回事”,但清楚现在用不了。
Function Call和Tool Call也是那时候出来的。说实话,当时实际测试没什么大用。虽然写了各种工具调用说明,但LLM能力有限,稍微复杂些的问题,工具根本调不起来。大家最常用的场景设计也就是“查个天气”了–大模型查天气,在当时已经算高级应用了。
第二章:架构分化–Agent开始长出不同的“脑子”
从“走一步看一步”到“先想清楚再干”
AutoGPT和ReAct暴露的问题本质上是同一个:走一步看一步,只看眼前,缺少全局。
那自然有人想:人类做复杂事情不是这样的。你先规划好步骤,然后一个螺丝一个螺丝地拧。于是Plan-and-excute模式出来了–把Agent拆成规划器和执行器,先整体规划,在逐步执行。
还是那个调研竞对的例子:
-
ReAct的做法:搜索->观察->在搜索->在观察->整理->发现不全->继续搜…… -
Plan-and-Execute的做法:先列出完整步骤清单(搜竞对、汇总分析、生成报告),然后一步一步地执行
测试数据对比非常直观:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Plan-and-Execute在长任务上碾压ReAct,但短板也比较明显:如果执行某一步发现数据源坏了,ReAct会换个源继续,Plan-and-Execute只会接受错误没有备选方案。
Reflection和多Agent协作
还有一个重要的路线是Reflection–让Agent生成输出后自己检查一遍,发现问题自己修正。这可以叠加在任何架构上,能提升1-2个点的准确率,降低幻觉率。
多agent协作也开始热起来。一个Agent做研究、一个写代码、一个做质检、一个当领导分任务,像个小团队。
想法都很好,但当时依旧没什么实际用途。底层LLM能力就那样,在上面搭建再复杂的架构,也没啥用,这时候基本也就等待着LLM能力进一步的提升了。
第三章:协议来了–MCP、ACP和skills怎么把散兵游勇拧在一起
一个当时被一些人看不起的东西
2024年底,Anthropic发布了MCP(Model Context Protocol)。
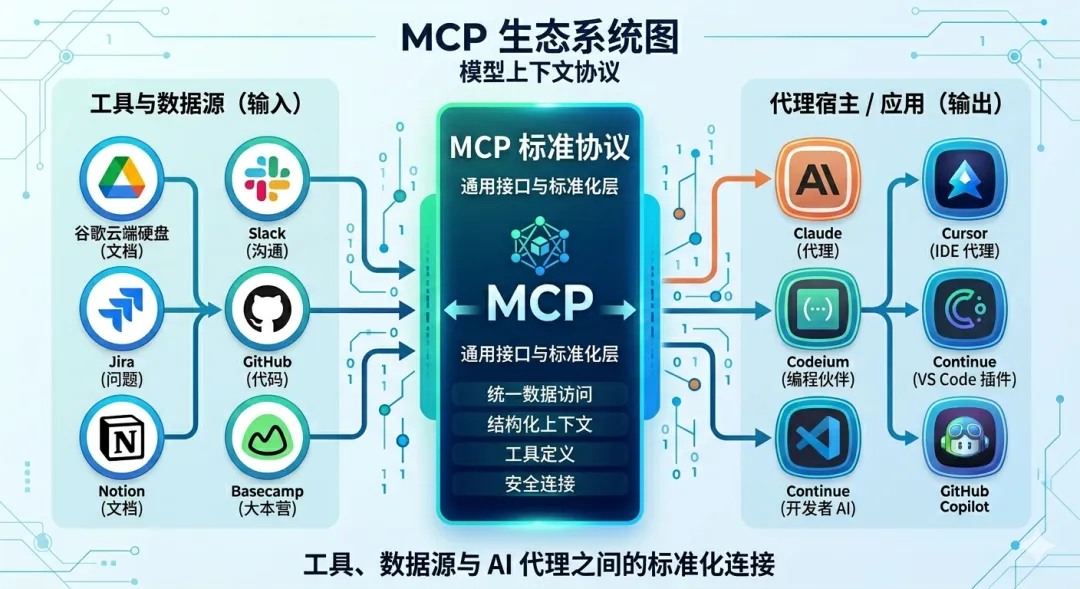
第一反应是:就这?就是个工具调用的协议?技术上真没什么高深的–定义了一套让LLM连接外部工具的通用接口。以前为每个工具单独写接入代码,现在大家按照同一套格式来。
我当时也感觉没什么东西,后来证明我错了。
为什么一个技术含量不高的东西改变了局面
MCP真正的力量不在技术,在标准化带来的网络效应。
在MCP之前,github上各类工具,接一个就得单独写一套适配。开发者把大量时间花在重复工作上。
MCP之后就不一样了。只需要按照MCP标准写一次工具,所有支持MCP的agent框架都能用。就跟当年的USB接口一样–标准本身不复杂,接口统一后,整个生态或了。
cursor、vs、coze、dify等等基本都加入了MCP接入;github上也出现了很多高质量MCP工具–文件管理、搜索引擎、股票API、天气api;甚至有人开始用MCP工具赚钱了–做一个高质量MCP工具包挂网上,按调用量收费。
这是Agent生态第一次有了真正的经济循环。不再是开发者自己的事呢。
ACP:Agent之间的互动也更加标准了
MCP解决了“agent怎么拿工具”,ACP解决“agent之间怎么说话”。
ACP规定了意图声明、本体定义、身份教研,Agent之间也能像“调API一样”交互了。
两个协议合体后,Agent生态发展速度也明显上了一个台阶。减轻了开发者之间的交流壁垒。
Skills:协议之上,长出了“专业技能包”
MCP解决了“怎么接工具”,但:工具太多,Agent怎么知道什么时候用哪个?
skills的思路很简单:把工具和使用工具的知识打包成一个技能包。一个skill不只是一个工具接口,里面还装着:
-
这个工具是干什么的(一句话描述) -
什么场景下该用它(触发条件) -
怎么正确使用它(详细指令和最佳实践) -
用完之后怎么判断对不对(校验规则)
更关键的是加载机制。它采用了渐进式披露的设计:
- 启动时只加载名字和一句话描述(大约100个词),让Agent”知道有这个技能”
- Agent决定要用这个技能时,才加载详细的SKILL.md指令文件
- 真正执行时,才加载运行时代码和工具配置
这种设计的好处就是Context不会爆。几百个skills挂在Agent身上,Agent只感知到他们的存在,只有在有用时才会真正占用空间。
到2025年底,skills生态才开始真正起飞了。github上出现了各种skills包:财报分析、法律文书、文案编写、SEO优化、角色扮演……社区不再只做工具,开始做技能了,各类领域知识的技能包。
从MCP到ACP到Skills:MCP统一了工具接口,ACP统一了Agent通信,Skills统一了怎么干成事的知识。三层叠在一起,Agent才真正从能调API变成了能干活的。
第四章:系统化觉醒–Agent开始像个真正的系统了
编程工具先炸了
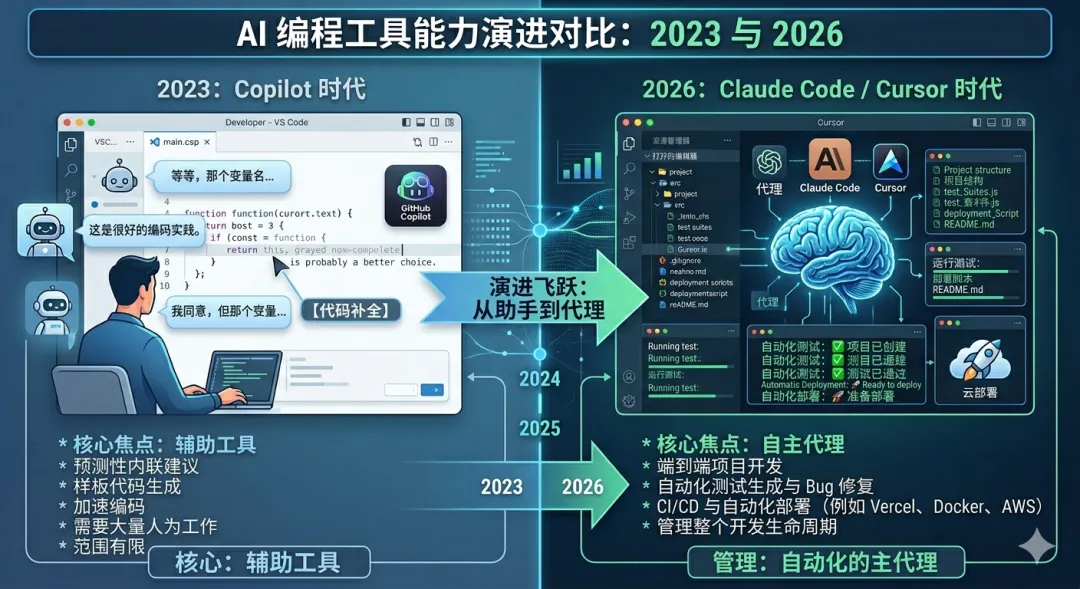
Cursor、Claude Code、GitHub Copilot、Codex、Trae——这些AI编程工具突然就强到“真能用”了。以前你写代码,AI提示补全;现在是AI自己写代码、自己测试、自己修Bug、自己部署,你是审查者。
比较写实的一件事就是,因为这些编程工具的能用,很多公司都在裁程序员了,包括我们也是。程序员从当年炙手可热的行业以及沦为和土木那一类的专业。
Claude Code源码泄露
然后发生了一件标志性事件:Claude Code的部分源码泄露。
从源码中可以看出,CC的创新并非底层算法的创新,全是工程技巧:怎么管理上下文不溢出、怎么缓存重复内容省计算、怎么在后台线程跑API让主线程随时能中断、怎么在沙箱里安全跑不受信任的代码……
整套设计。每个环节都在考虑“万一出错怎么办”。
具体的Claude Code的核心代码解读与复习可以参考我的另一篇文章:
这里就不做过多复述。
从Claude Code的源码暴露,让我也体会到一件事:原来把工程做到极致,比等下一个更强的模型靠谱得多。
Harness Engineering:不再教模型“别犯错”,而是让它根本逃不出去
这一波之后,一个新词被确立下来:Harness Engineering(驾驭工程)。
核心理念是一次重大转变:与其费尽心机教模型守规矩,不如设计一个让模型根本没机会犯错的运行环境。跟治水一样——不是研究水的性格,是修堤坝、建水库、挖泄洪道。
这时候的Agent跟早期完全不同了。早期Agent是个“聪明的个体”,现在Agent是个“被监控、被约束、被治理的系统化工程”。好比你不会让一个天才实习生管整个交易大厅——你得给他流程、权限边界、风控系统。
OpenClaw让普通人摸到了“贾维斯”
几乎同时,OpenClaw横空出世。
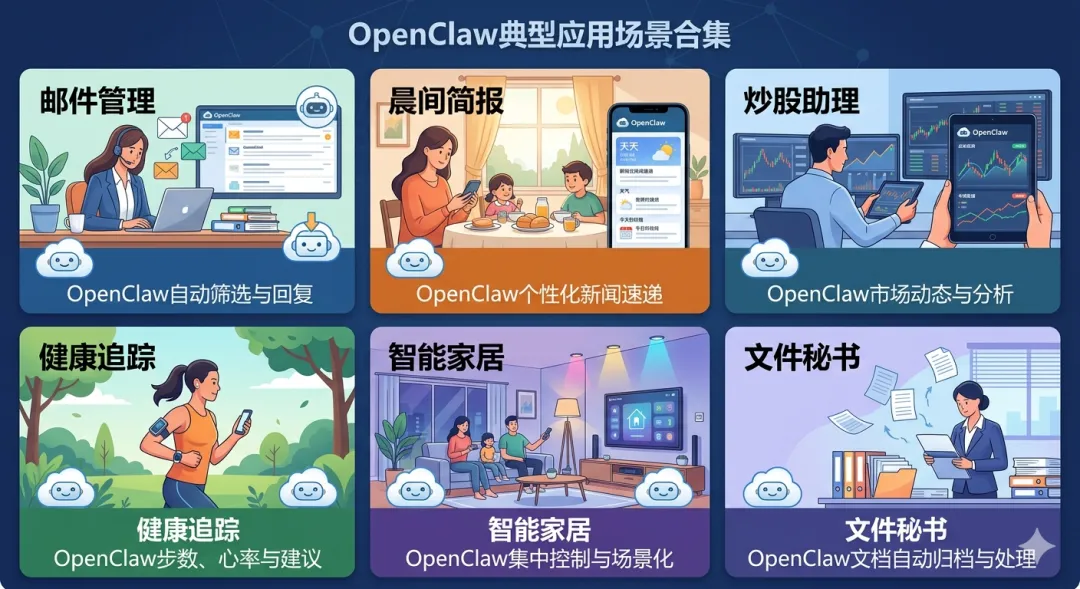
它跟ChatBot最大的不同:它是本地执行体,能直接操作你的电脑。不是跟你聊天,是替你干活。
大家给它起了个外号叫“小龙虾”。然后一大堆真实案例冒出来:
-
邮件管理:接Gmail,自动分类、归档、生成回复草稿。有人几天清了几千封未读 -
私人晨报:每天早6:30从日历、天气、RSS、GitHub拉数据,推送定制简报到手机 -
炒股助理:监控仓位、计算回报率、执行止损,触发阈值就推送告警 -
健康追踪:连WHOOP等设备API,拿睡眠和恢复数据跟日程交叉分析,提醒早点睡 -
文件秘书:配本地Ollama模型,读文件、做总结、回答问题,数据不出本地
那种感觉就像电影里的贾维斯突然接近现实了。不是概念视频,是GitHub上的真实代码,拉下来就能跑。
但OpenClaw也暴露了致命问题——安全。国家互联网应急中心后来监测到超3万个OpenClaw实例暴露在公网,CNNVD收录漏洞82个,其中超危漏洞12个。它给了AI一双“手”,但这双手能摸什么不该摸的东西?这就是Harness Engineering要解决的问题。
第五章:LLM和Agent的暗线战争——谁最后会吃掉谁?
你每进一步,我就退一截
到2026年回头看,LLM和Agent之间有一条持续的拉锯:
2023年Function Calling出现——消灭了一整代“伪装工具调用”方案。以前靠正则表达式匹配模型输出文本、手动调API的hacker方案,一夜报废。
2024-2025年超长上下文窗口出现(Gemini 100万Token、Claude 200K)——动摇了RAG的地位。Agent外挂RAG是因为模型记不住东西,现在模型能一次吞一本书,RAG的“检索”价值还剩多少?虽然后来RAG找到了新定位(从“帮模型看到看不到的东西”变成“帮模型在海量信息里精准定位”),但那波冲击很真实。
2025年Claude Skills直接从模型层面内置技能——过去需要Agent框架才能整合工具,现在模型自己就能管技能、决定何时调哪个。
规律很清楚:LLM每内化一个能力,Agent生态中就消失一层“补短板”的模块。 但奇妙的是,Agent总能在更高的地方重新找到存在感——模型能处理单Agent任务了,需求转向多Agent协同;能记100万上下文了,需求转向1亿上下文的跨组织知识整合。
就像蒸汽机效率越高,煤炭总消耗反而越大。模型越强,人们用Agent做的事越复杂,Agent生态反而不死。
如果LLM的底层架构变了呢?
到今天,LLM的底层还是Transformer + Causal LM。CoT、ICL、ReAct都是“用推理时的额外计算换能力”——本质还是序列生成,输入一堆Token,输出下一堆Token。Agent的规划、反思、工具调用,全是建在模型外的“外骨骼”。
但如果某一天,底层架构不再是这套东西?如果训练阶段就融合了“环境交互”和“自主规划”,推理时不是单纯预测下一个Token,而是内置了真正的Agent循环?
那今天整个Agent生态就真的危险了。外骨骼不需要了,模型自己长了骨骼和肌肉——它自己就是Agent。
这事会不会发生?不知道。Transformer统治了这么久,不是因为完美,而是下一代架构的诞生比想象中难得多。谁的判断都是赌。
但有一件事我比较确定:不管你赌哪条路——模型吃掉Agent,还是Agent继续繁荣——连接智能和真实世界的那层“中间件”永远有价值。 MCP、ACP、沙箱、监控、权限系统。不管智能发生在模型内还是模型外,它都必须在安全边界里做事。
结语
最初大家以为Agent的问题是“模型不够聪明”。ReAct、Plan-Execute、Reflection轮番上阵,想让模型思路更清、步骤更稳。后来发现,聪明的实习生照样捅娄子。控制Agent的方式,从“教聪明”变成了“教规矩”。
回头看几个节点:
-
AutoGPT证明了“AI能自主干事”——但也证明了纯自主是灾难 -
ReAct/Plan-Execute证明了“结构比聪明更重要” -
MCP/ACP证明了“标准是生态的加速器” -
Claude Code/OpenClaw证明了“工程压倒算法” -
Harness Engineering证明了“最好的控制不是改变大脑,而是设计牢笼”
而那条暗线——LLM和Agent互相蚕食又互相成就的战争,还在继续。
Agent式的LLM会不会出现?不是现在这种ICL、DeepThink模式——那些本质上还是Causal LM,只是推理时做了更多计算。我指的是训练阶段就内置了Agent循环的模型架构。如果那天真的来了,今天的Agent生态会迎来终极洗牌。
但这剧,远没到终局。
如果觉得有用,【赞同】+【评论】+【关注】就是对我最大的鼓励,感谢,下期见。