 夜雨聆风
夜雨聆风





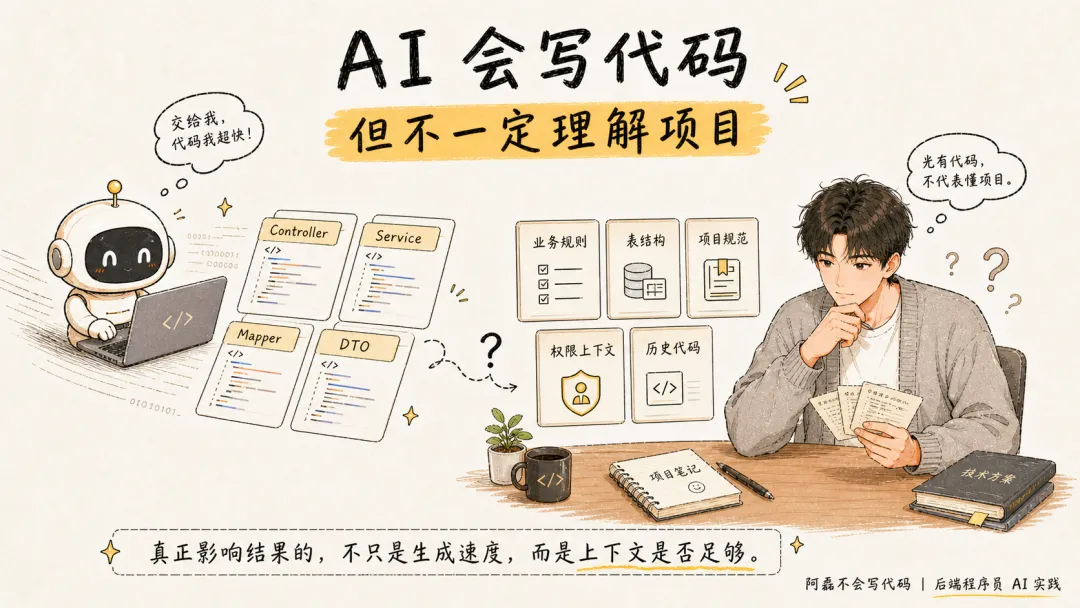
AI 编程下半场:程序员真正要补的是项目上下文能力
AI 编程下半场:程序员真正要补的是项目上下文能力
从“帮我写个接口”,到“让 AI 读懂项目”
写在前面
最近我用 AI 写后端代码越来越多,感受很明显:
现在的问题,已经不是 AI 会不会写代码。
它会写。
Controller、Service、Mapper、DTO、参数校验、异常处理,甚至事务、日志、幂等,它都能写得像模像样。
真正的问题变成了:
它写出来的代码,能不能放进你的项目里。
这两件事,中间差了一大截。
我一开始也经常对 AI 说:
帮我写个接口。
后来用多了才发现,这句话其实太粗糙了。
因为真实项目不是空白 Demo。真实项目里有业务规则、表结构、项目规范、历史代码、权限上下文,还有很多文档里没写、但老开发默认知道的约定。
AI 不知道这些。
你不给,它就只能猜。
这也是我现在越来越确定的一件事:
AI 编程已经进入下半场。
上半场,大家比的是谁会让 AI 生成代码。下半场,真正拉开差距的,是谁能让 AI 理解项目。
这才是我写这篇文章的原因。
一、很多人用 AI 写代码,返工不是因为模型弱
以前我们担心 AI 写不出代码。
现在的问题变了。
很多时候,它不是写不出来,而是写得太快、太完整,反而容易让人放松警惕。
比如你给它一个需求:
帮我写一个 Spring Boot 用户收藏文章接口,包括 Controller、Service、Mapper、DTO 和统一返回结果。它很快就能生成一套完整结构:
-
• FavoriteController -
• FavoriteService -
• FavoriteMapper -
• FavoriteDTO -
• addFavorite方法 -
• 参数校验 -
• 返回 success
第一眼看,很像那么回事。
如果只是 Demo,这可能已经够了。
但如果这是公司项目里的真实业务代码,问题就来了。
真实项目通常不是“能跑就行”。
它还要符合:
-
• 已有同类业务的写法 -
• 团队分层规范 -
• 统一返回结构 -
• 统一异常体系 -
• 权限上下文 -
• 表结构约定 -
• 状态枚举 -
• 逻辑删除规则 -
• 历史兼容逻辑 -
• 后续维护成本
这些东西,AI 不会天然知道。
你不告诉它,它只能按通用经验写。
通用经验不一定错,但很可能不适合你的项目。
所以很多人用 AI 写代码后的真实感受是:
生成很快,改起来也不少。
二、真正的问题,不是 Prompt 不够花
以前我也喜欢收集各种 Prompt。
比如:
你是一个资深 Java 架构师。请按照最佳实践生成代码。请注意异常处理、事务、日志和可维护性。这类 Prompt 有没有用?
有用。
但它解决不了最核心的问题。
因为真实项目里的“最佳实践”,不是抽象的。
你们项目的统一返回结构是什么?业务异常类叫什么?错误码怎么定义?当前用户从哪里取?逻辑删除字段叫什么?状态枚举有哪些值?类似业务之前是怎么写的?这个功能会不会影响旧逻辑?
这些不是一句“请按最佳实践”能解决的。
所以我现在越来越少迷信万能 Prompt。
我更关注的是:
我有没有把项目上下文给够。
Prompt 是入口。上下文,才是 AI 能不能写对的关键。
三、一个小实验:让 AI 写“用户收藏文章”接口
为了让这个问题更具体,我用一个后端常见需求举例:
用户收藏文章。
这个接口看起来很简单。
用户传一个文章 ID。后端拿到当前用户 ID。插入一条收藏记录。返回成功。
如果只看代码实现,它像是一个普通 CRUD。
但真实业务里,问题没有这么简单。
第一次:只给一句需求
我第一次给 AI 的需求很简单:
帮我写一个 Spring Boot 用户收藏文章接口,包括 Controller、Service、Mapper、DTO 和统一返回结果。AI 很快生成了代码。
结构完整。分层也有。正常流程也能跑。
但按真实项目标准再看,我会继续追问这些问题:
-
• 下架文章还能不能收藏? -
• 重复收藏怎么返回? -
• 作者能不能收藏自己的文章? -
• 收藏成功后要不要更新收藏数? -
• 文章删除后收藏关系怎么处理? -
• 是否要按幂等处理? -
• 查询是否要过滤逻辑删除? -
• 是否要考虑唯一索引冲突? -
• 是否要打日志? -
• 是否要补测试?
这些问题,AI 第一次不会自动知道。
它可能会写一个“看起来合理”的实现。
但这个合理,是通用意义上的合理,不一定是你项目里的合理。
这也是 AI 写业务代码最容易让人误判的地方:
它不是明显写错,而是写得像对的。

四、第二次:先喂上下文,再让它写
后来我换了一种方式。
我没有直接让 AI 写代码,而是先给它项目上下文。
大概是这样:
我要实现一个用户收藏文章功能。请先不要直接写代码。我会先给你项目上下文,你需要先理解,再给出实现方案。技术栈:Java + Spring Boot + MyBatis。项目分层:Controller 只负责接参和返回。业务逻辑放在 Service。数据访问放在 Mapper。项目规范:统一返回 Result。业务异常使用 BizException。当前用户从 LoginUserContext 获取。查询需要过滤 deleted = 0。写操作需要考虑事务。关键失败分支需要记录日志。业务规则:1. 下架文章不能收藏。2. 重复收藏直接返回成功,按幂等处理。3. 收藏成功后需要更新文章收藏数。4. 作者可以收藏自己的文章。5. 收藏列表只展示未删除、已发布文章。涉及表:article:id、status、deleted、favorite_count、author_iduser_favorite:id、user_id、article_id、deleted、create_timeuser_favorite 表有 user_id + article_id 唯一索引。请先输出:1. 你准备改哪些类?2. 每个类负责什么?3. 需要注意哪些边界?4. 可能有哪些风险?5. 有没有更小改动方案?确认后再生成代码。这次结果明显不一样。

AI 不再只是直接生成一套通用代码,而是会先开始分析:
-
• 要校验文章是否存在 -
• 要校验文章状态 -
• 要处理重复收藏 -
• 要考虑唯一索引冲突 -
• 要使用事务 -
• 要更新收藏数 -
• 要注意逻辑删除 -
• 要按项目返回结构处理异常 -
• 要补充日志 -
• 要提醒并发下收藏数一致性问题
它输出的代码不一定完美。
但它已经更接近真实项目里的初稿。
更关键的是,它开始主动暴露风险点。
这一步对我来说很重要。
因为我并不指望 AI 一次性写出最终代码。
我更希望它先参与分析,把可能遗漏的地方提前暴露出来。
这时候,AI 就不只是一个“生成代码的工具”。
它更像一个开发搭子。
五、第一次问法 vs 第二次问法
下面这张表,是我觉得最值得收藏的部分。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这也是我现在最想强调的一点:
不是让 AI 写得更多,而是让它少猜一点。
六、AI 编程下半场,补的是 5 类上下文
如果要把这件事总结成方法,我现在会把“项目上下文能力”拆成 5 类。
这 5 类信息,是我现在让 AI 写后端代码前,尽量会先补给它的。
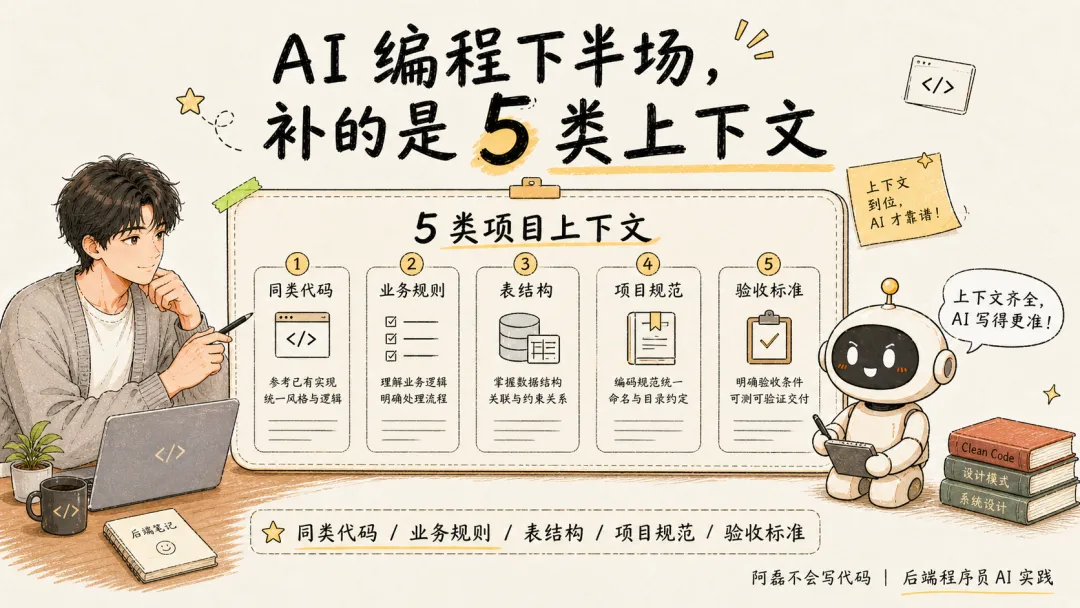
1. 同类代码:让 AI 学项目写法,而不是写通用答案
真实项目不是从零开始。
你要写一个“收藏”接口,项目里可能已经有:
-
• 点赞接口 -
• 关注接口 -
• 评论接口 -
• 提交审核接口 -
• 创建订单接口
这些代码里藏着很多项目习惯:
-
• Controller 怎么写 -
• Service 怎么拆 -
• Mapper 怎么命名 -
• 异常怎么抛 -
• 返回结构怎么封装 -
• 日志怎么打 -
• 权限上下文怎么取 -
• 包路径怎么组织
这些东西如果不提供给 AI,它只能写通用答案。
所以我现在会先给它一两个同类模块,让它总结:
这个项目的接口实现风格是什么?
然后再让它按这个风格写新功能。
这一步能减少很多“不像项目代码”的问题。
2. 业务规则:不要让 AI 猜
AI 最容易写错的,往往不是语法,而是业务理解。
比如“收藏文章”,你至少要告诉它:
-
• 下架文章能不能收藏 -
• 重复收藏怎么返回 -
• 作者能不能收藏自己的文章 -
• 收藏数是否同步更新 -
• 删除文章后怎么处理收藏关系 -
• 收藏列表展示哪些状态的数据
这些规则不说,AI 就会自己猜。
而它猜出来的结果,通常也不会显得很离谱。
这才危险。
因为它会写出一段看起来非常合理的代码,只是这段代码不符合你的业务。
所以我现在会把业务规则写成一组明确条件,让 AI 不要自行脑补。
3. 表结构和状态字段:让 AI 先理解数据
后端很多问题,最终都落在数据上。
表结构不给清楚,AI 很容易假设字段。
比如它可能不知道:
-
• deleted = 0才是有效数据 -
• status = PUBLISHED才能展示 -
• user_id + article_id有唯一索引 -
• favorite_count需要同步更新 -
• 项目里还有租户字段 -
• 某些状态不能被更新 -
• 某些关联表需要一起处理
这些问题前期不说,后面很容易返工。
所以我会尽量给它:
-
• 表名 -
• 关键字段 -
• 状态枚举 -
• 唯一索引 -
• 逻辑删除字段 -
• 关联关系
让 AI 先理解数据,再生成代码。
4. 项目规范:不要默认 AI 知道你们怎么写
每个项目都有自己的规范。
有些写在文档里。有些写在代码里。还有一些是团队默认的约定。
比如:
-
• 统一返回用 Result -
• 业务异常用 BizException -
• 错误码统一定义 -
• 当前用户从上下文获取 -
• 查询必须过滤逻辑删除 -
• 写操作需要事务 -
• 关键失败分支需要日志 -
• Controller 不写业务逻辑 -
• Service 不直接返回数据库 Entity
这些你不说,AI 就会按通用习惯写。
通用习惯不一定差,但项目适配性不够。
所以我现在会提前告诉它项目规范。
这一步看起来啰嗦,但能显著减少后续修改。
5. 验收标准:不要只让 AI 写,也要让它自查
最后一步很多人会忽略。
我不会只让 AI 生成代码。
我会让它先自查一遍:
-
• 这个实现复用了哪些已有逻辑? -
• 哪些边界还没覆盖? -
• 可能影响哪些旧功能? -
• 有哪些并发或幂等风险? -
• 需要补哪些测试? -
• 有没有更小改动方案? -
• 哪些地方需要人工确认业务规则?
这一步的价值在于,它会逼 AI 从“写代码模式”切到“Review 模式”。
当然,最后判断还是在人。
但 AI 的自查可以帮助我提前发现一些遗漏点。
七、我的后端 AI 编程路线图
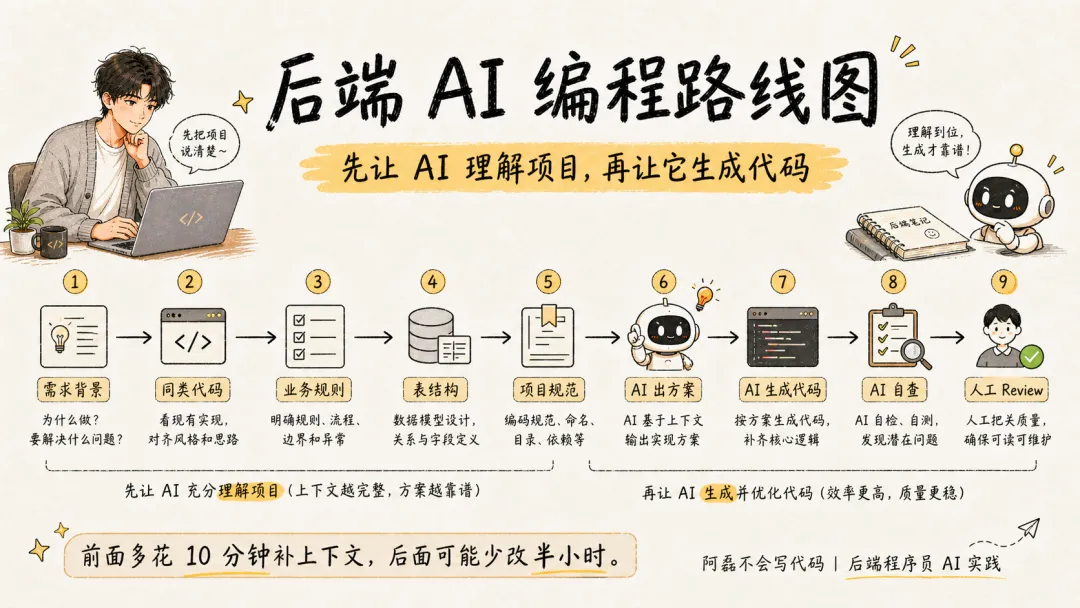
如果把上面内容整理成一条路线,大概是这样:
文字版可以这样理解:
-
1. 先讲需求背景告诉 AI 这个功能属于哪个业务模块,解决什么问题。 -
2. 给同类代码让它学习项目已有实现,而不是写通用代码。 -
3. 补业务规则把正常流程、异常流程、边界条件说清楚。 -
4. 给表结构让它理解数据模型、状态字段和索引约束。 -
5. 说明项目规范统一返回、异常、日志、权限、分层、错误码都提前说。 -
6. 先让它出方案不要一上来写代码。先让它说明准备改哪些文件、每个文件负责什么、可能影响哪些逻辑、有没有风险点。 -
7. 确认方案后,再生成代码这时候生成出来的代码通常会更贴近项目。 -
8. 生成后让它自查,再人工 ReviewAI 自查一遍,人再做最终判断。
这套流程看起来比一句“帮我写个接口”麻烦。
但我自己的感受是:
前面多花 10 分钟补上下文,后面可能少改半小时甚至更久。
八、什么时候不用这么复杂?
我不想把这套方法说成万能。
不是所有场景都需要这么重。
如果你只是写:
-
• 临时脚本 -
• Demo -
• 小工具 -
• 简单 SQL 辅助 -
• 一次性数据处理 -
• 简单转换函数
那完全可以直接让 AI 开写。
这类任务的目标就是快。
没必要上来就准备一堆上下文。
但如果你写的是公司项目里的业务代码,尤其涉及:
-
• 用户 -
• 订单 -
• 支付 -
• 库存 -
• 审核 -
• 权限 -
• 状态流转 -
• 数据一致性
那就不能只看 AI 写得快不快。
因为这类代码的问题,往往不是“能不能跑”。
而是:
跑得是不是符合业务,合进去是不是符合项目,后面是不是好维护。
九、一份可以直接复制的项目上下文模板
如果你也在用 AI 写后端代码,可以从这个模板开始。
下次不要直接说:
帮我写个接口。
可以先这样组织信息:
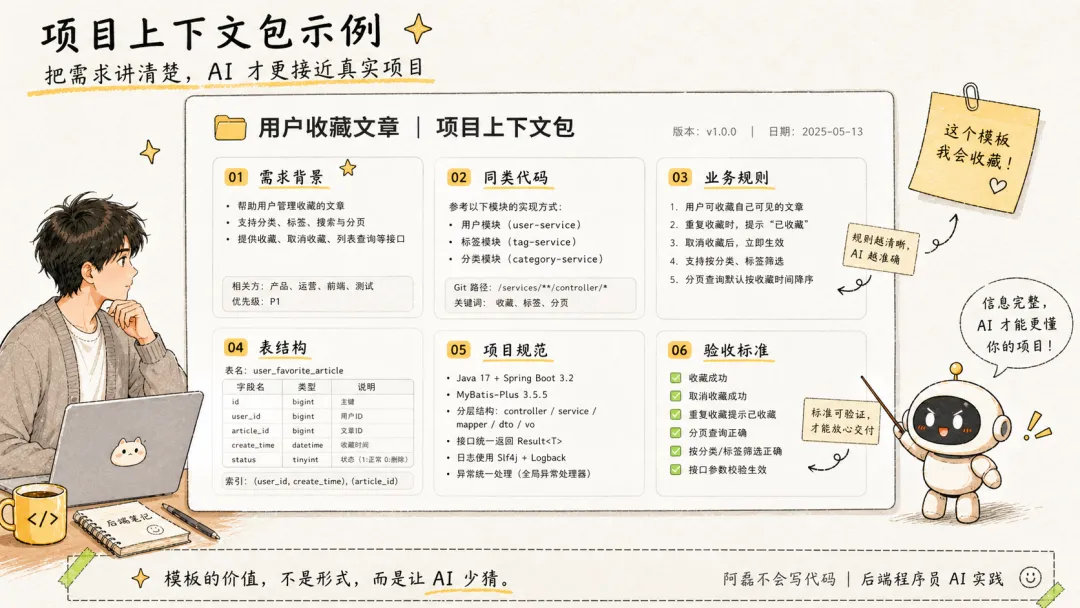
【需求背景】我要实现什么功能?属于哪个业务模块?目标是什么?【同类代码】项目里有哪些类似功能?它们的 Controller / Service / Mapper 是怎么写的?有哪些可以复用的逻辑?【业务规则】正常流程是什么?异常流程是什么?哪些边界条件必须处理?哪些规则不能让 AI 自己猜?【表结构】涉及哪些表?关键字段是什么?状态枚举有哪些?是否有唯一索引?是否有逻辑删除字段?表之间是什么关系?【项目规范】统一返回结构是什么?业务异常怎么抛?当前用户怎么获取?日志怎么打?事务怎么处理?分层规范是什么?【验收标准】哪些场景必须通过?哪些风险需要提醒?会影响哪些旧功能?需要补哪些测试?有没有更小改动方案?这份模板不复杂,但很实用。
它的核心不是让 AI 多写代码。
而是让 AI 少猜。
十、AI 编程下半场,程序员的价值会变
我现在越来越觉得,AI 编程对程序员的影响,不只是“少写几行代码”。
它会改变我们工作的重心。
以前很多人的价值体现在:
-
• 熟悉语法 -
• 熟悉框架 -
• 能快速写代码 -
• 能独立完成模块
这些能力当然还重要。
但 AI 出现以后,另一类能力会越来越重要:
-
• 能不能把需求拆清楚 -
• 能不能发现业务边界 -
• 能不能整理项目上下文 -
• 能不能判断 AI 方案对不对 -
• 能不能做工程取舍 -
• 能不能控制长期维护成本
说白了,AI 可以帮你更快生成代码。
但它不能替你承担工程判断。
所以我不认为 AI 会立刻让后端程序员失去价值。
但我认为,后端程序员的价值会从“我能写”逐渐转向:
我知道什么代码该写,怎么写才适合这个项目,以及写完后怎么判断它能不能进项目。
这才是更长期的能力。
十一、这篇文章可以怎么用?
如果你是后端开发,可以把这篇当成一个起点。
以后每次让 AI 写业务代码前,先问自己 5 个问题:
-
1. 我有没有给它同类代码? -
2. 我有没有讲清业务规则? -
3. 我有没有给出表结构和状态字段? -
4. 我有没有说明项目规范? -
5. 我有没有定义验收标准?
这 5 个问题,就是我现在理解的“项目上下文能力”。
它不是某个工具的功能。
它更像一种新的开发习惯。
十二、后续我准备继续写什么
这篇文章算是我整理“后端程序员 AI 实践”的第一篇总纲。
我的判断很简单:
AI 已经越来越会写代码了,但真正能不能在真实项目里用起来,关键不只是模型能力,而是我们能不能把项目上下文讲清楚。
后面我会继续把这套方法拆开写,比如:
-
1. 我给 AI 准备的后端项目上下文包长什么样 -
2. AI 写接口时,我常用的 Prompt 模板 -
3. AI 生成代码后,我会怎么做 Review -
4. 用 Cursor / Claude / Codex 改老项目的真实流程 -
5. AI 写代码最容易返工的 10 类问题 -
6. 后端程序员如何把 AI 接入日常开发工作流
我不想把 AI 讲成神话。
也不想制造程序员焦虑。
我更想记录一个普通后端程序员,在真实工作里怎么把 AI 用起来,怎么踩坑,怎么改进,怎么慢慢形成自己的方法。
我是阿磊不会写代码,一个后端程序员,记录 AI 写代码、做图、提效和副业实践。
如果你也在用 AI 写代码,欢迎留言告诉我:
你现在返工最多的是需求没讲清,还是项目上下文没给够?