 夜雨聆风
夜雨聆风





零成本搞定语音转文字:OpenClaw 中文音频处理实战
FunASR + FFmpeg 的组合,可能是目前最好的中文免费方案。
写在前面
一、我们面临的真实需求
1.1 五大典型场景
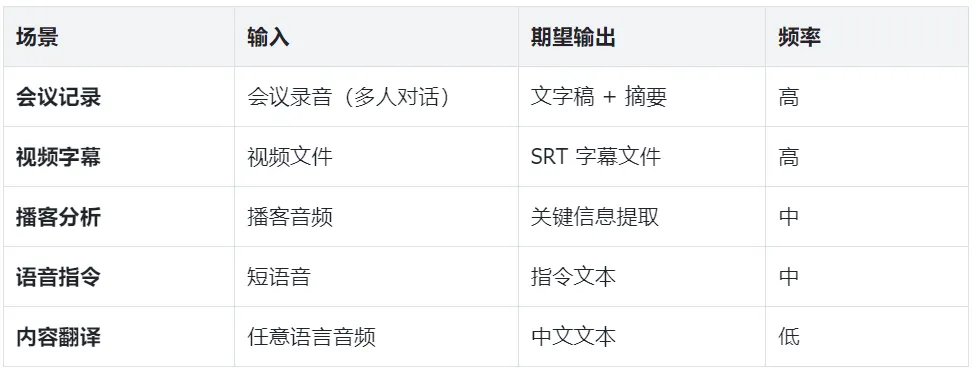
1.2 四条选型原则
-
中文优先—— 主要面向中文场景,识别精度是第一指标 -
免费优先—— 优先开源方案,能省就省 -
本地部署—— 会议录音涉及隐私,数据不出本机是底线 -
Skill 集成—— 与 OpenClaw 自然语言交互无缝衔接
二、全景扫描:语音转文字方案怎么选
2.1 OpenClaw 内置 Skill 三件套
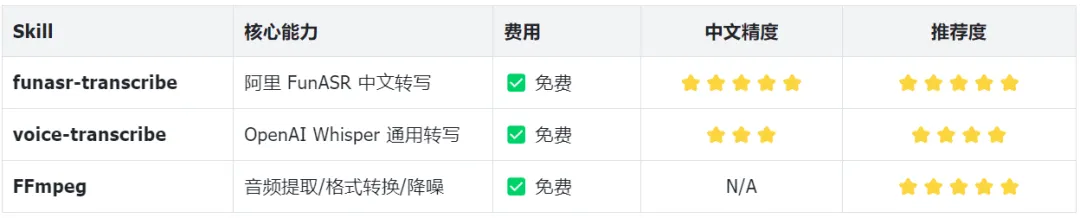
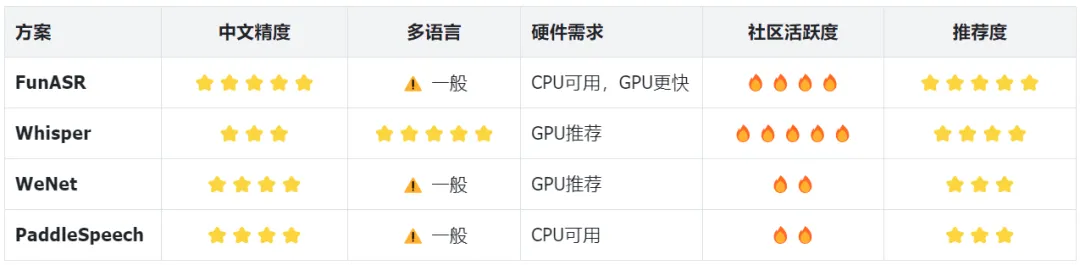
2.2 开源自建方案对比
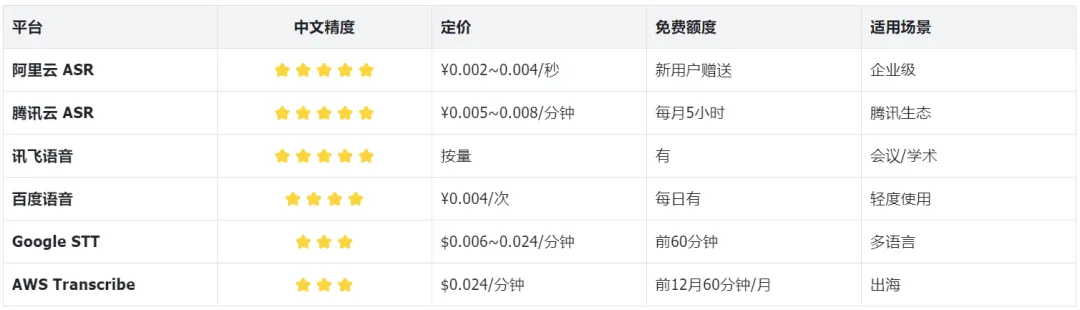
2.3 云服务商方案(作为参照系)
2.4 一图看懂选型
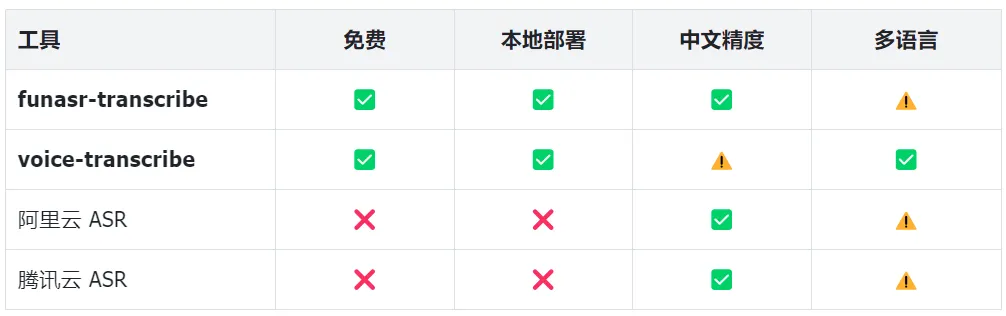
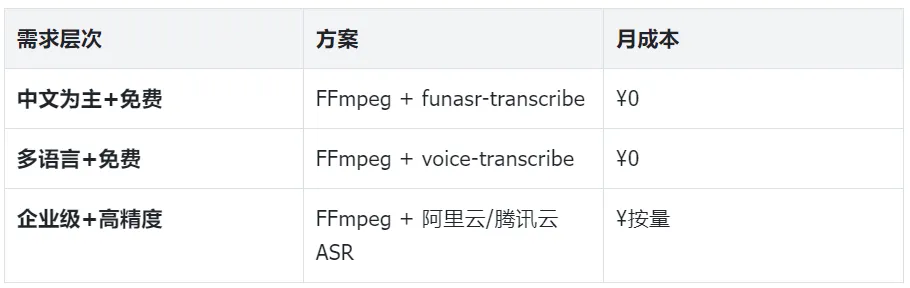
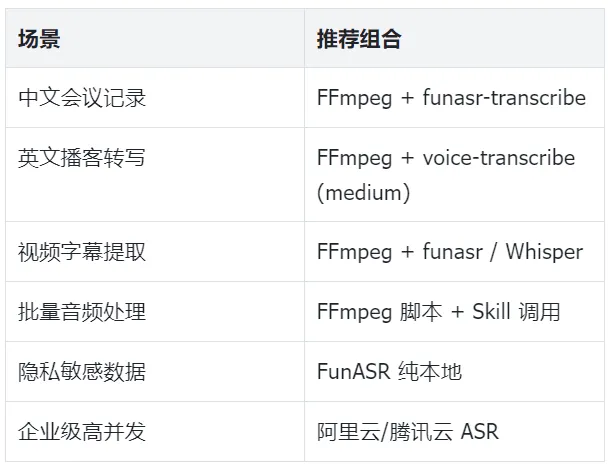
2.5 三套推荐组合
三、FFmpeg 音频处理:管道工的基础活
3.1 从视频提取音频
#提取为 MP3(有损压缩,文件小)ffmpeg -i video.mp4 -vn -acodec libmp3lame -q:a 2 output.mp3# 提取为 WAV(无损,推荐给转写模型用)ffmpeg -i video.mp4 -vn -acodec pcm_s16le output.wav# 指定采样率16kHz + 单声道(大多数ASR模型的标准输入)ffmpeg -i video.mp4 -vn -ar 16000 -ac 1 output.wav
提示:16kHz 单声道 WAV 是 FunASR 和 Whisper 的标准输入格式,建议提取时一步到位。
3.2 格式转换
#MP3 转 WAVffmpeg -i input.mp3 -acodec pcm_s16le output.wav# WAV 转 MP3ffmpeg -i input.wav -acodec libmp3lame -q:a 2 output.mp3# 改变采样率(适配不同模型)ffmpeg -i input.mp3 -ar 16000 -ac 1 output_16k.wav
3.3 音频剪辑
#取前30秒(适合快速测试)ffmpeg -i input.mp3 -t 30 -c copy output.mp3# 从第10秒开始,取20秒ffmpeg -i input.mp3 -ss 10 -t 20 -c copy output.mp3# 指定时间段ffmpeg -i input.mp3 -ss 00:05:00 -to 00:15:00 output.mp3
3.4 基础降噪
#简单的高低通滤波(去除低频噪音和高频电流声)ffmpeg -i input.mp3 -af "highpass=f=200,lowpass=f=3000" output.mp3# 移除开头和结尾的静音ffmpeg -i input.mp3 -af "silenceremove=start_periods=1:start_threshold=-50dB:start_silence=0.5" output.mp3# 更高级的降噪(需要 afftdn 滤镜)ffmpeg -i input.mp3 -af "afftdn=nf=-25" output.mp3
四、funasr-transcribe:中文转写利器
4.1 为什么是 FunASR
-
中文精度业界领先,接近商业API水平 -
完全本地运行,数据不出机器 -
支持标点恢复、说话人分离等高级功能 -
模型选择灵活(从轻量到专业)
4.2 安装准备
#macOS / Linuxcurl -LsSf https://astral.sh/uv/install.sh | sh# Windows (PowerShell)powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
clawhub install funasr-transcribe#确认安装成功ls ~/.openclaw/skills/funasr-transcribe/
#可以手动预下载,避免首次使用等待python -c "from funasr import AutoModel; model = AutoModel(model='iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8405-pytorch')"
4.3 使用方法
|
你说的话 |
实际效果 |
|
“用 funasr 转写这段音频” |
自动调模型,返回文字稿 |
|
“用 funasr 转写这段音频,返回 SRT 字幕” |
带时间戳的字幕格式 |
|
“用 funasr 转写,语言选中文” |
明确指定语言,减少误判 |
4.4 支持的格式
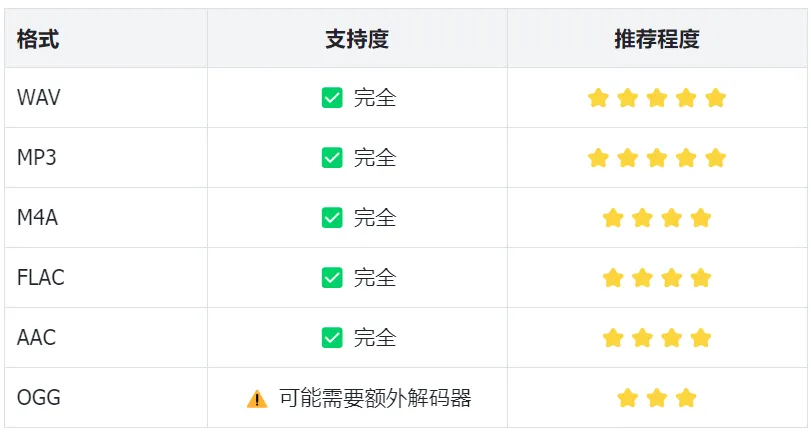
4.5 常见故障排查
#设置 HuggingFace 镜像export HF_ENDPOINT=https://hf-mirror.com
#使用轻量模型(精度略低,但内存占用小很多)python -c "from funasr import AutoModel; model = AutoModel(model='iic/speech_paraformer-small_asr_nat-zh-cn-16k-common-vocab8405-pytorch')"
#检查 CUDA 是否可用python -c "import torch; print(torch.cuda.is_available())"# 如果返回 False,安装 CUDA 版 PyTorchpip install torch --index-url https://download.pytorch.org/whl/cu118
五、voice-transcribe:多语言场景的补充
5.1 定位
5.2 安装与配置
clawhub install voice-transcribe#安装依赖pip install openai-whisper# 或uv pip install openai-whisper
5.3 模型选择指南
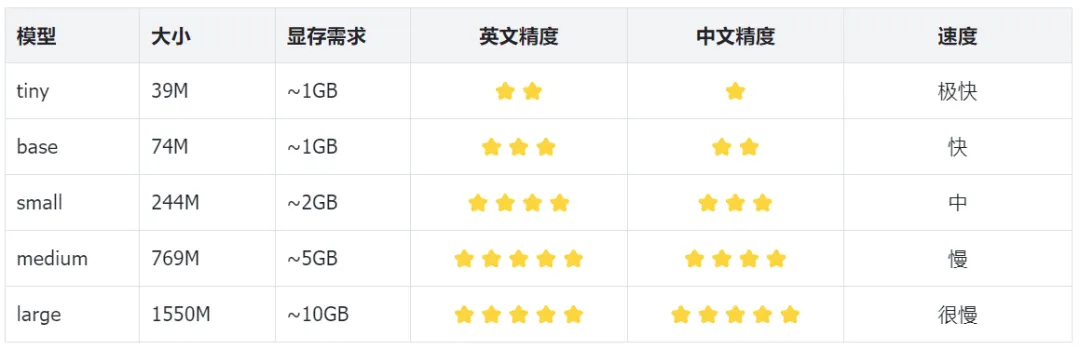
5.4 FunASR vs Whisper 决策表
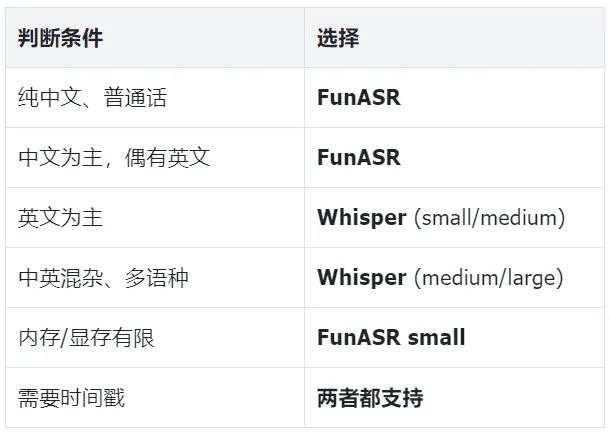
六、完整工作流实战
6.1 视频 → 文字稿(最常用的流程)
ffmpeg -i video.mp4 -vn -ar 16000 -ac 1 audio.wav用 funasr-transcribe 转写 audio.wav#!/bin/bash# video_to_text.shINPUT_VIDEO="$1"OUTPUT_DIR="${2:-./output}"mkdir -p "$OUTPUT_DIR"echo "🔊 正在提取音频..."ffmpeg -i "$INPUT_VIDEO" -vn -ar 16000 -ac 1 "$OUTPUT_DIR/audio.wav" -yecho "📝 正在转写..."# 通过 OpenClaw Skill 执行openclaw skill run funasr-transcribe --input "$OUTPUT_DIR/audio.wav" --output "$OUTPUT_DIR/transcript.txt"echo "✅ 完成!文字稿:$OUTPUT_DIR/transcript.txt"
6.2 生成 SRT 字幕
whisper audio.wav --model medium --language zh --output_format srt --output_dir ./outputfrom funasr import AutoModelmodel = AutoModel(model="iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8405-pytorch")result = model.generate(input="audio.wav")def text_to_srt(result, output_file):with open(output_file, 'w', encoding='utf-8') as f:for i, item in enumerate(result, 1):text = item['text']start = item['start']end = item['end']# SRT 时间格式:HH:MM:SS,mmmstart_srt = f"{int(start//3600):02d}:{int((start%3600)//60):02d}:{int(start%60):02d},{int((start%1)*1000):03d}"end_srt = f"{int(end//3600):02d}:{int((end%3600)//60):02d}:{int(end%60):02d},{int((end%1)*1000):03d}"f.write(f"{i}\n{start_srt} --> {end_srt}\n{text}\n\n")text_to_srt(result, "output.srt")
6.3 批量处理
#!/bin/bash# 批量转写文件夹下所有 mp3INPUT_DIR="$1"OUTPUT_DIR="${2:-./transcripts}"mkdir -p "$OUTPUT_DIR"for audio_file in "$INPUT_DIR"/*.mp3; dofilename=$(basename "$audio_file" .mp3)echo "📝 正在处理: $filename"# 统一转16kHz WAVffmpeg -i "$audio_file" -ar 16000 -ac 1 "$OUTPUT_DIR/${filename}.wav" -y -loglevel error# 调用 Skill 转写echo " 转写完成"doneecho "✅ 批量处理结束!"
七、踩坑记录
7.1 FFmpeg 音频问题
# 基础降噪ffmpeg -i input.mp3 -af "highpass=f=80,lowpass=f=11000" output.mp3# 高级降噪ffmpeg -i input.mp3 -af "afftdn=nf=-25" output.mp3
# 压缩到 1MB 以内ffmpeg -i input.wav -fs 1M output.mp3# 降低比特率ffmpeg -i input.wav -acodec libmp3lame -q:a 4 output.mp3
7.2 转写质量问题
python -c "from funasr import AutoModel; model = AutoModel(model='iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8405-pytorch')"whisper audio.wav --language Chinese --model medium八、最佳实践总结
8.1 完整工具链
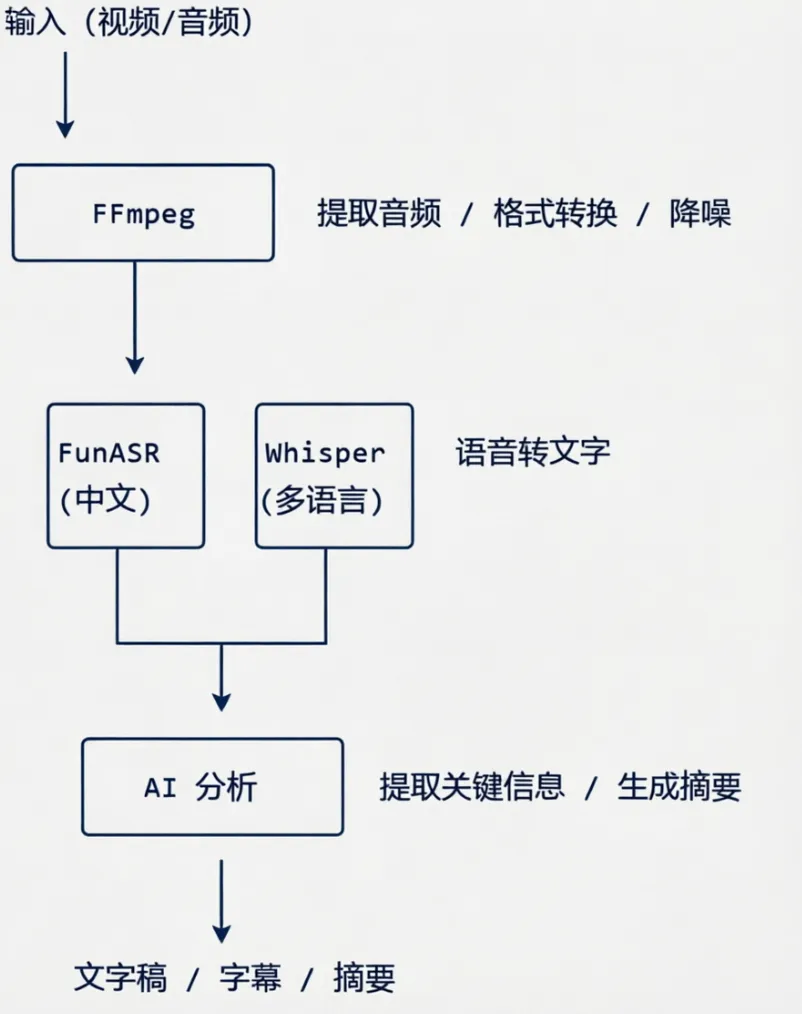
8.2 场景化推荐速查
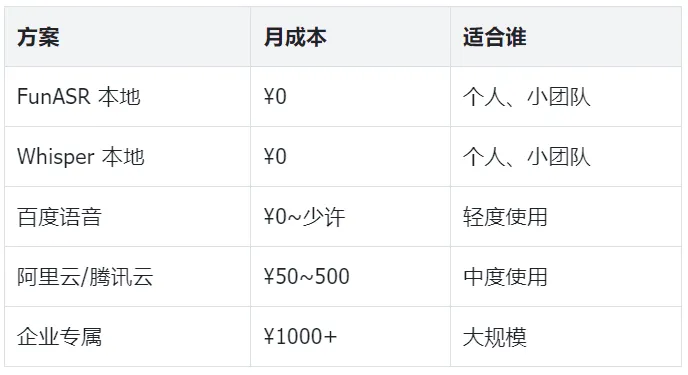
8.3 成本一览
写在最后
——
感谢阅读
真实经历,真诚分享
关注我,一个只分享 AI 实战记录的人类