 夜雨聆风
夜雨聆风





当 AI 替你参加集体决策:它真的懂你吗?

图 1:人类成员通过各自的GenAI数字代表参与团队决策
导语
想象一个很日常的场景:周末去哪玩?Alice 想安静一点,Bob 想热闹一点。两个人都不想反复讨论,于是各自派出一个 AI “数字代表”替自己表达偏好、参与协商,最后由 AI 们一起给出团队决策。
听起来很高效。但问题来了:AI 代表你之前,你要告诉它多少关于自己的信息?告诉得越多,它越懂你;告诉得越少,你省时省力,也少暴露隐私;但如果别人告诉得比你多,最后的集体决策可能就会被“拉向”对方。
这篇论文《Generative AI as Digital Representatives in Collective Decision-Making: A Game-Theoretical Approach》正是从博弈论角度,研究了这个问题:当 GenAI 成为集体决策中的数字代表,人类会如何策略性地向 AI 透露自己的偏好?
为什么这个问题重要?
过去,我们通常把 AI 看作一个“助手”:帮你总结会议、润色文档、生成方案、辅助投票。
但现在,AI 正在从被动工具变成主动参与者。它不仅能提供建议,还可能直接代表人类参与协商、投票、资源分配、团队决策。
比如:代表用户参与推荐系统选择;代表公民参与公共议题讨论;代表病人或医生参与医疗决策;代表团队成员参与项目方案协商。
这就带来一个核心问题:AI 想准确代表你,必须了解你;但你不可能、也不一定愿意,把所有信息都告诉它。
论文指出,仅仅让大模型根据年龄、职业、性别等人口统计信息进行角色扮演,往往会产生偏差,无法准确模拟真实个体偏好。更丰富的个人信息,例如历史行为、社交媒体内容、人格测评结果,确实有助于提升 AI 代表的准确性。
但现实中,完整披露偏好几乎不可能。因为这需要时间、精力、沟通成本,也涉及隐私风险。
于是,问题变成了:在集体决策中,每个人会选择向自己的 AI 代表透露多少信息?
论文如何建模
论文构建了一个两人集体决策模型。为了便于理解,我们可以继续用 Alice 和 Bob 的例子。
两个人各自有一个真实偏好。例如 Alice 更喜欢安静活动,Bob 更喜欢社交活动。每个人都有一个 AI 数字代表。这个 AI 代表一开始并不了解具体用户,只拥有一个关于普通人偏好的“先验认知”。
用户可以选择向 AI 透露一定程度的信息。论文用一个变量来表示这个披露程度:α ∈ [0, 1]。
当 α = 0 时,用户什么都不说,AI 只能依赖自己的默认先验;当 α = 1 时,用户完全披露信息,AI 可以准确表达用户真实偏好。但论文假设,完全披露的沟通成本趋近无穷大,因此现实中几乎不会发生。
于是,AI 学到的偏好其实是一个折中:AI 的输出 = 用户真实偏好与 AI 先验认知的加权平均。
用户透露越多,AI 越接近真实用户;用户透露越少,AI 越接近默认大众偏好。
最后,Alice 和 Bob 的 AI 代表分别表达推断出的偏好,系统再将两者平均,形成团队最终决策。
每个用户的损失由两部分组成:偏好损失,即最终团队决策离自己真实偏好有多远;沟通成本,即为了让 AI 理解自己,需要付出多少信息披露成本。
这就构成了一个“数字代表博弈”。
核心发现一:偏好冲突时,人们反而透露更多信息
论文最有意思的发现是:当成员之间偏好冲突时,他们会更积极地向 AI 披露信息。
这听起来有点反直觉。我们可能会以为:如果两个人意见一致,大家会更愿意沟通;如果意见冲突,反而会更保守。但在这个模型里,结果恰好相反。
原因在于:当 Alice 和 Bob 偏好相反时,Bob 向 AI 披露更多信息,会把最终团队决策往 Bob 的方向拉。Alice 为了不让决策偏离自己太远,也会被迫透露更多信息来“反制”。
这是一种竞争性信息披露。换句话说:意见越不一致,越不能沉默。因为你不说,别人说了,AI 就可能更像别人。
这也解释了为什么在 AI 代理参与的群体决策中,偏好冲突不一定让系统失效,反而可能激发更多信息披露,使 AI 更充分地了解各方立场。
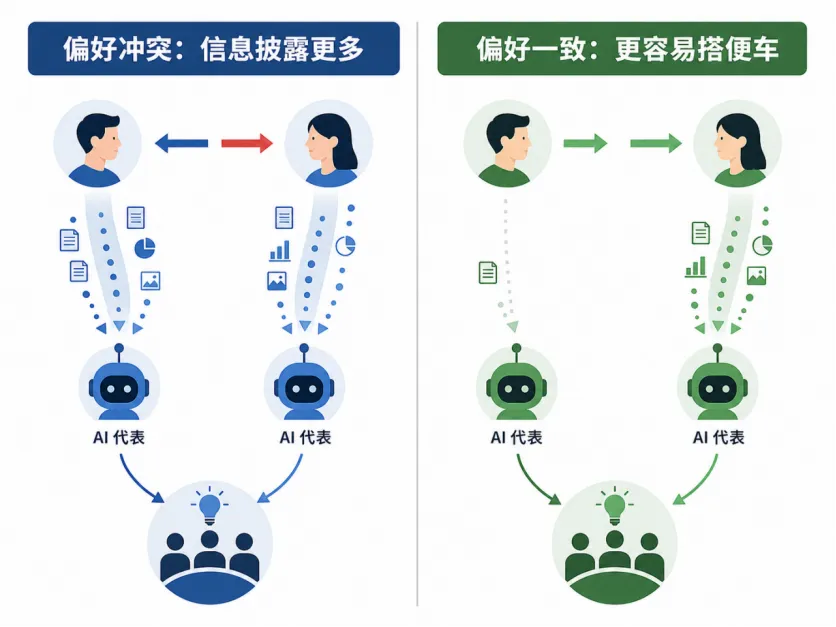
图 2:偏好冲突会激发竞争性信息披露;偏好一致时更容易出现“搭便车”。
核心发现二:偏好一致时,反而容易“搭便车”
如果 Alice 和 Bob 的偏好方向一致,情况就不一样了。假设两个人都偏向安静活动,只是程度不同。Bob 已经告诉 AI 很多信息,Alice 可能会想:反正他的偏好和我差不多,他说得越多,最终结果也不会太偏离我。那我少说一点,也能省成本。
这就是论文所说的 free-riding,也就是“搭便车”。
当成员偏好一致时,一个人的信息披露会帮到另一个人。因此,部分成员会策略性地少透露信息,把沟通成本留给别人。
这带来了一个重要启示:群体意见一致,并不意味着 AI 代表能更准确地理解每个人。相反,意见一致时,大家可能都觉得“别人说了就够了”,结果导致 AI 获得的信息不足,最终代表质量下降。
核心发现三:越“不像大众”的人,越需要多说一点
论文还定义了一个概念:diversity,可以理解为“用户偏好与 GenAI 默认先验之间的距离”。
如果一个人的偏好很接近 AI 对普通人的默认认知,那么即使他不透露太多信息,AI 也不会偏得太离谱。
但如果一个人的偏好很独特,和大众偏好差异很大,那么默认 AI 很难准确代表他。
因此,论文证明:偏好越偏离 AI 先验的成员,在均衡中会透露更多信息。
这对实际系统设计很有启发。如果未来我们真的让 AI 代表用户参与公共讨论、医疗协商、推荐决策或团队协作,那么系统不能只关注“平均用户”。那些偏好更少见、更边缘、更个性化的用户,反而更需要额外的表达通道。否则,AI 代表很可能默认向主流偏好靠拢。
AI 代表比真人直接参与更好吗?
论文进一步比较了两种模式:一种是每个人直接表达完整偏好,也就是传统人工参与;另一种是让 AI 数字代表参与决策。
结论很微妙。
从“偏好损失”看,AI 代表通常不如真人直接参与。因为真人可以完整表达偏好,而 AI 只能根据部分披露的信息进行推断。
所以论文证明:在整体偏好匹配程度上,数字代表的团队偏好损失不会低于直接参与。
但如果考虑“总损失”,结果就可能反转。所谓总损失,不只是最终结果是否满意,还包括讨论、表达、沟通、协商所消耗的时间和精力。
当人工参与成本很高时,例如复杂谈判、战略规划、大规模公共协商,使用 AI 代表反而可能降低整体损失。
也就是说:AI 代表未必让结果更完美,但可能让决策过程更省成本。
论文的数值实验也显示,当手动参与成本较高,或者 GenAI 系统能力更强、交互门槛更低时,数字代表更有可能带来整体收益。
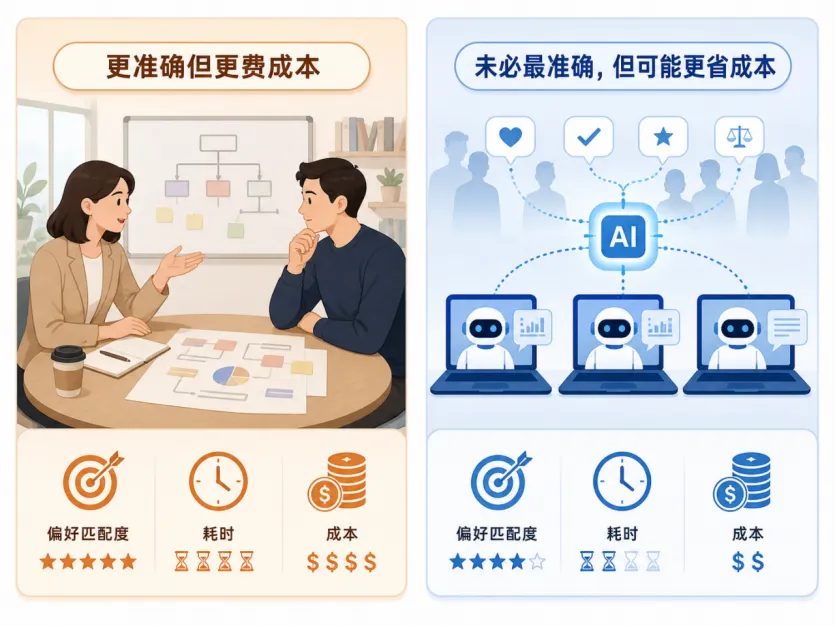
图 3:直接参与更准确但成本更高;数字代表未必最准确,但可能降低总成本。
一个反直觉结果:个体可能比直接参与更满意
AI 代表比真人直接参与更好吗?
结语:AI 替你发言之前,你要先决定告诉它多少“你”
它可以替我们总结、协商、投票、推荐,甚至在未来参与更复杂的集体决策。
但这篇论文提醒我们:AI 代表不是天然懂你。它懂多少,取决于你说多少;你说多少,又取决于别人怎么说。
当偏好冲突时,人们会更积极地披露信息,形成竞争性表达;当偏好一致时,人们可能选择搭便车,反而让 AI 学得不够充分;当人工参与成本很高时,AI 代表可能不是最准确的方案,却可能是更经济的方案。
所以,未来真正关键的问题或许不是:“AI 能不能替我们做决定?”
而是:“在一个由 AI 代表参与的集体决策系统里,我们该如何设计规则,让每个人都被更好地代表?”
这才是数字代表时代真正值得讨论的问题。
参考文献
[1] Chen, K., Huang, J., & Luo, Y. (2025). Generative AI as Digital Representatives in Collective Decision-Making: A Game-Theoretical Approach. In I. Lynce et al. (Eds.), ECAI 2025 (pp. 1334–1341). IOS Press. https://doi.org/10.3233/FAIA250950.

写在最后

我们的文章可以转载了呢~欢迎转载与转发呦

想了解更多前沿科技与资讯?
点击上方入口关注我们!
欢迎点击右上方分享到朋友圈

香港中文大学(深圳)
网络通信与经济实验室
微信号 : ncel_cuhk