 夜雨聆风
夜雨聆风





AI 辅助开发范式 ⑤:OpenSpec,把规范驱动做成 npm install 的轻量框架
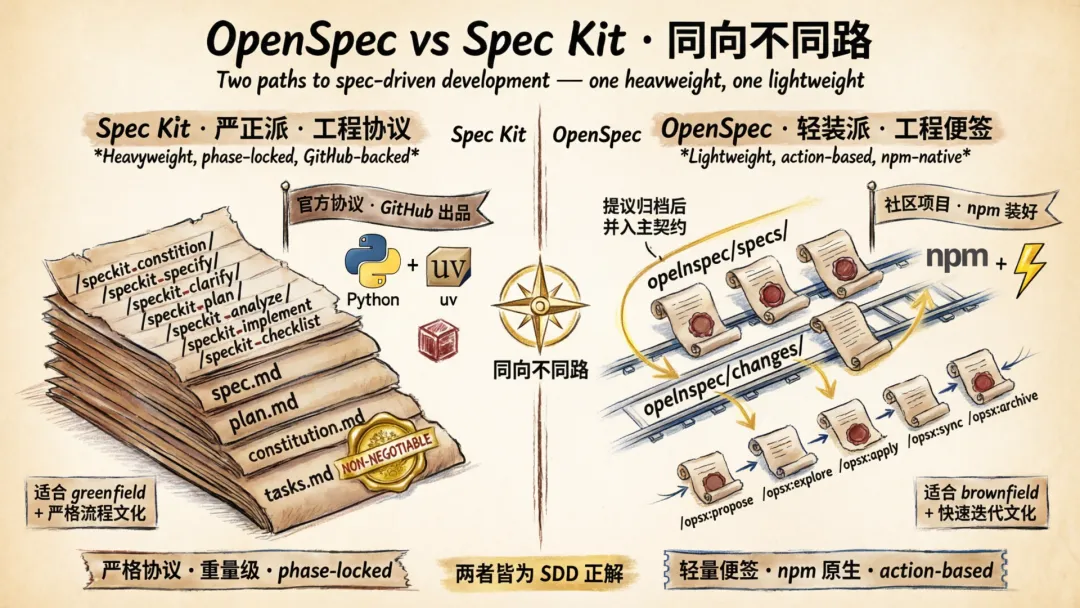
当 Spec Kit 把规范驱动写成行业标准,OpenSpec 把它压成一行
npm install。
一、轻量规范答卷:OpenSpec 凭什么挤进规范驱动赛道
在第四篇里我们刚讲过 GitHub 官方的 Spec Kit,它确实很有效,但有一个被反复吐槽的尾巴:前端团队装一个 Python 工具链,光是搞定 uv 和虚拟环境就够磨半天。
就在这个空隙里,OpenSpec 长了出来。
它来自 Fission-AI 团队,GitHub 仓库 Fission-AI/OpenSpec,主仓库 v1.0.0 在 2026 年初发布,被作者命名为 “The OPSX Release“(OPSX 即 OpenSpec 工作流命令的前缀)。从那时起,Star 数从 2.6 万一路涨到 4.45 万、Fork 3100——增速接近 Spec Kit 同期表现。最新版本已经迭代到 v1.3.x,主线维护者依然活跃。
它的安装命令短得令人意外:
npm install -g @fission-ai/openspec@latest仅此一行。没有 Python、没有 uv、没有虚拟环境。Node.js ≥ 20.19.0 就够。官方支持 25+ 种 AI 编码工具——Claude Code、Cursor、Windsurf、Continue、Gemini CLI、Copilot、Amazon Q、Cline、RooCode、Auggie、Codex、OpenCode、Antigravity、iFlow、Pi.dev、AWS Kiro……一份 OpenSpec 工件,所有工具共用。
OpenSpec 在自己的官网首页直接写下了对手:
“vs. Spec Kit (GitHub) — Thorough but heavyweight. Rigid phase gates, lots of Markdown, Python setup. OpenSpec is lighter and lets you iterate freely.“
“更轻、能自由迭代”——这就是它给规范驱动赛道交的答卷。
二、看不见的脚手架:specs / changes / delta 三件套,加 OPSX七命令
OpenSpec 的全部魔法藏在两个目录和七个命令里。
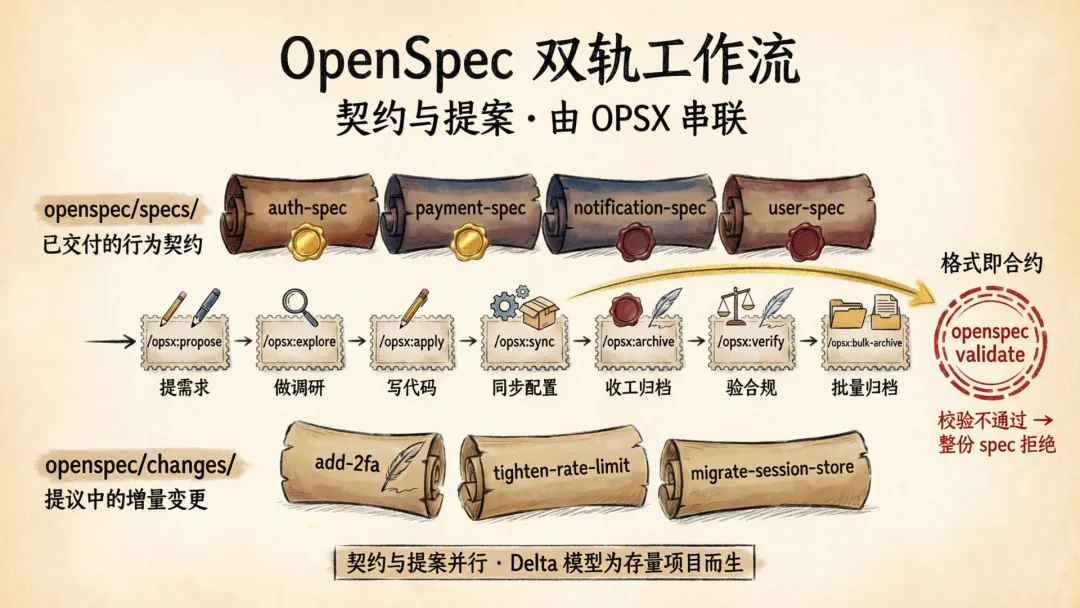
specs 与 changes:把”现状”和”提案”分开
OpenSpec 把项目知识切成两半:
openspec/specs/——描述系统当前的行为契约(冻结的真相源)openspec/changes/——描述正在被提议的修改(活的提案)你可以把 specs/ 理解为 Git 里的主分支——只有通过审查、已上线的代码才能进去;把 changes/ 理解为功能分支——每个改动先在这里开一条分支,改完再合并回主分支。这个设计让多个改动可以并行推进,互不干扰。
这里需要澄清一个常见误会:OpenSpec 并不是”只管变化、不管规范”。恰恰相反,specs/ 里存的就是完整的规范——系统当前有哪些能力、每个能力有什么行为约束,全部写在里面。changes/ 里也不只有”变化清单”,每份 change 都是一个完整的提案文件夹,包含:
proposal.md——为什么要变specs/——变什么(Delta Spec)design.md——打算怎么实现tasks.md——拆成哪几步做所以 OpenSpec 既管规范,也管计划,也管任务拆分。看到这儿你可能会问:”这不也有一堆文件吗?跟 Spec Kit 有什么区别?”
区别确实不在”文件数量”,而在两份核心文档的写法:

举个例子:你要给登录功能加双因素认证。
openspec/specs/ 里已经有”登录功能”的现状描述了。你只需要在 openspec/changes/ 下写一份 Delta Spec,标出一句”ADDED:登录流程增加 TOTP 双因素认证步骤”,再配上 Given/When/Then 场景。其他没变的需求不用提。这就是”轻”的真正含义:不是文件少,而是每次改动时,你笔下要写的东西少。
Delta Specs:只写”变什么”,不用重写整本书
每个 change 里的 specs/ 只放一份 Delta Spec——它不是重写整套规范,而是像”修订批注”一样,只标出四个类型的变更:
## ADDED Requirements——新增能力## MODIFIED Requirements——修改既有能力(必须粘贴完整修订后的内容)## REMOVED Requirements——废弃能力## RENAMED——只改名不改语义Delta 的意思是”差量”或”增量”。你不需要让 AI 把 50 万行老项目的所有功能重新描述一遍,你只需要说:”在现有登录流程里,加一个双因素认证步骤。”这就是 Delta Spec 的核心理念——只描述变化,不重复现状。
这个设计对brownfield(存量/遗留)项目特别友好,但不是说新项目不能用。新项目完全可以从空的 specs/ 开始,第一个 change 就把基础规范写进去。Delta 模型是一种”组织规范的方式”,不是一种”只能修修补补”的限制。
Requirement + Scenario:用 BDD 给 AI 写”测试用例”
OpenSpec 的需求格式相当严苛——这也是它跟 Spec Kit 最大的差别。
每个 Requirement 必须用 RFC 2119(互联网标准关键词规范,即 MUST/SHALL/SHOULD/MAY 等强制性分级词汇)关键词表达强度,必须至少包含一个 Given/When/Then 格式的 Scenario(场景/用例)。
Scenario 是什么? 翻译成中文就是”场景”,也常译为”用例”。你可以把它理解成”一个具体的使用例子”。比如”假设用户没登录,当他输入正确密码点击登录,那么他就应该进入首页”——这就是一条 scenario。AI 改完代码后,你拿着这些 scenario 一条条验证,对得上就是改对了,对不上就是改错了。
一份合规的 Delta Spec 核心结构如下——你可以把它理解为一份”机器能读懂的变更说明书”:
# Delta for Auth(本次变更的主题)## ADDED Requirements(新增需求)### Requirement: Two-Factor Authentication(需求标题)The system MUST support TOTP-based two-factor authentication.(系统必须支持基于 TOTP 的双因素认证。TOTP 即"基于时间的一次性密码",就是你手机上常见的 6 位动态验证码。)>#### Scenario: 2FA enrollment(场景:开通双因素认证)- GIVEN a user without 2FA enabled(假设用户未开启 2FA)- WHEN the user enables 2FA in settings(当用户在设置中开启时)- THEN a QR code is displayed(则显示二维码供Authenticator App扫描)- AND the user must verify with a code(且用户必须输入验证码确认)## MODIFIED Requirements(修改既有需求)### Requirement: Session ExpirationThe system MUST expire sessions after 15 minutes of inactivity.(Previously: 30 minutes —— 以前是 30 分钟)请注意这份 spec 的本质:它就是一份机器可验证的测试用例。Given/When/Then 是 BDD(Behavior-Driven Development,行为驱动开发)的标准结构,AI 可以直接把每一条 Scenario 翻译成集成测试。规范不再是 PRD(Product Requirement Document,产品需求文档)那种”软描述”,它是可执行的合约。
Spec Kit 用 [NEEDS CLARIFICATION] 标记模糊点,OpenSpec 则通过 RFC 2119 + BDD 尽量避免模糊。
OPSX 工作流:七个 action 串联整条 spec→code 链路
OpenSpec使用一套 action-based(按动作触发) 的 /opsx:* 命令。这是它跟 Spec Kit 另一条核心路线分歧。
核心 7 个命令:
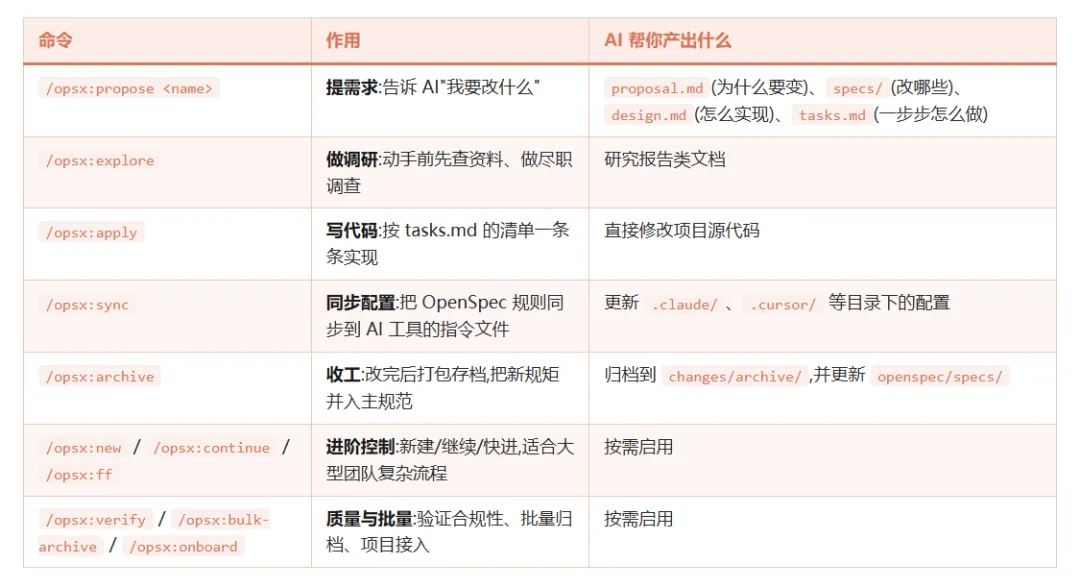
跟 Spec Kit 的 8 个严格串联命令不同,OPSX 不强制顺序。AI 知道当前工件状态——什么存在、什么尚未创建、下一步可以做什么。你可以只跑 /opsx:propose,几天后回来直接 /opsx:apply,中间没有任何 phase gate 卡死。
openspec validate(校验规范格式):格式即合约
CLI(Command Line Interface,命令行工具)里最关键的命令不是 init(初始化项目配置),是 validate(校验规范格式)。它会扫描每一份 spec / delta,检查:
如果你把”Scenario”写错了层级(比如少打了一个#号),或者没用规定的段落格式而是随手写了个列表,validate 直接拒绝,不会让 AI 拿着错误格式的 spec 去执行。这是两者的风格差异:Spec Kit 偏向自然语言,允许一定弹性;OpenSpec 把 spec 当源代码一样做格式校验。
三、它解决的是”规范驱动太重,AI 又听不懂”
如果说 Spec Kit 解决了”AI 上来就写代码、忘了三天前的需求”,OpenSpec 在它之上又解决了一层——怎么让规范驱动本身不变成另一种重型流程和开发障碍。
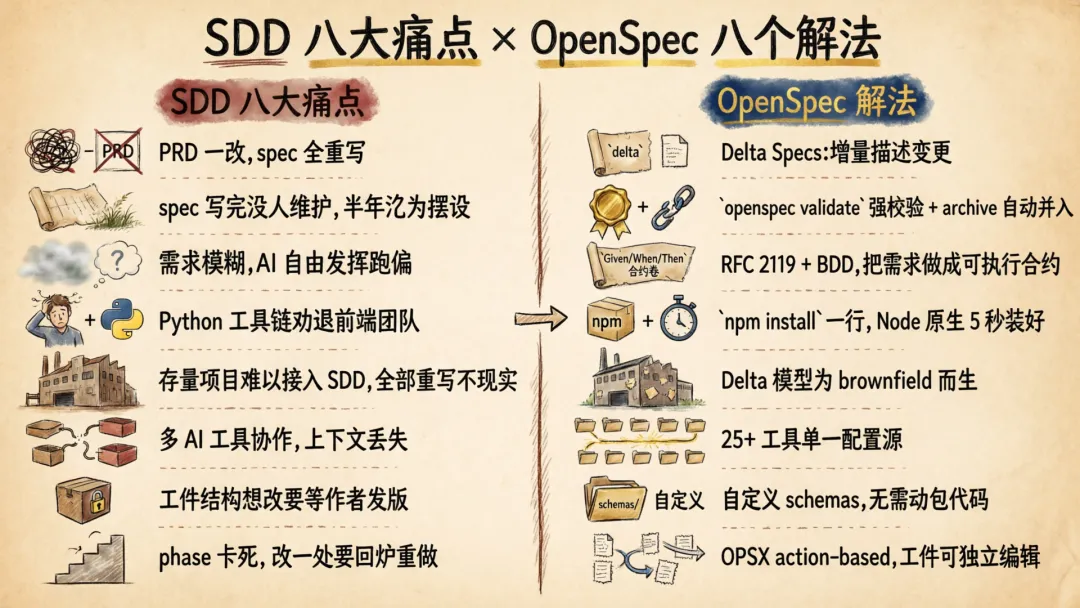
我们对照一下 SDD(Spec-Driven Development,规范驱动开发)实践里最常见的 8 个痛点:
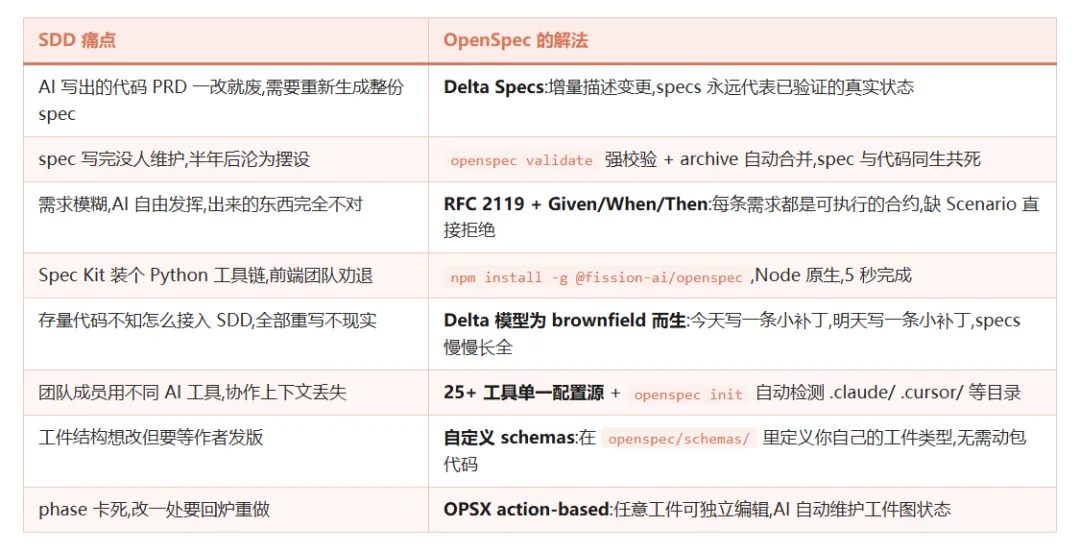
这八条问题中,前三条关于”需求怎么写清楚”,Spec Kit 和 OpenSpec 都提供了解法;后五条关于”工具链适配、存量项目接入、多团队协作”,OpenSpec 走了另一条路。两者代表了 SDD 的两种不同风格:一种像写正式协议,强调阶段和流程;一种像写代码注释,强调即插即用。
四、为什么”轻量”也能站住:三个底层设计判断
OpenSpec 的价值源于三个反直觉的判断。
判断一:契约 vs 提案,必须分离
Spec Kit 的世界里只有 spec,你写完一个 feature,spec 就更新一次。OpenSpec 把这件事拆成两份:
specs/ 是契约——只有通过 archive 流程的内容才能进来,代表”已交付、已验证、不可随意修改”changes/ 是提案——完全自由,可以同时存在多个、可以争论、可以放弃这个分离的价值,只有在 brownfield 项目里才显出来。你不想让一个未经验证的草稿污染主 spec;你也不想等所有提案都吵完才更新主 spec。契约和提案必须并行,这是 Git 给我们带来的”分支模型”在 spec 层的复刻。
OpenSpec 写在文档里的一句话很尖锐:
“Specs are behavior contracts, not implementation details.“
spec 是行为合约,不是实现细节。这句话决定了它和 Spec Kit 的根本不同——Spec Kit 把 plan.md 和 tasks.md 也纳入 spec 流程,OpenSpec 则选择让 spec 只表达”系统行为应该是什么样”,实现细节交给 design.md。
判断二:动态指令三层装配——AI 指令必须可改
v1.0 OPSX 引入了一个被低估的设计:AI 指令不是写死的,是动态装配的。
每次 AI 工具读 OpenSpec 的指令文件时,文件由三层组合而成:
你可以改 templates 而不需要 rebuild npm 包。这意味着:
openspec/schemas/ 里定义,不动核心代码Spec Kit 的 8 个命令 prompt 固定在 .specify/ 模板中,修改需要自行 fork(复制一份独立维护)。OpenSpec 则允许直接改 templates,无需重建 npm 包——这是它”轻量”的另一层含义:轻的不只是安装包大小,还包括后续调整的成本。
判断三:Scenario 即测试,把”规范”做成机器合约
OpenSpec 最关键的设计,是它把 BDD 当强制项。
Spec Kit 鼓励你写 spec,但 spec 是自然语言;OpenSpec 强制你写 Scenario,Scenario 是 Given/When/Then。openspec validate 校验每条 Requirement 都至少有一个 Scenario,缺一个就拒绝整份 spec。
为什么这件事重要?因为 AI 编码最大的失败模式,是 AI 觉得自己听懂了,但其实没听懂。自然语言可以模糊,Given/When/Then 不能模糊——它就是一条测试用例的输入和预期输出。AI 实现完一个功能,你拿着 Scenario 一条条对,不需要相信 AI,只需要验证 AI。
OpenSpec 自己的描述很直接:
“Scenarios are the most critical part for AI assistants because they provide unambiguous ‘tests’ for the code.“
Scenario 是 AI 编码的对账单。Spec Kit 的思路是”让需求尽量写清楚”,OpenSpec 的思路是”给 AI 可验证的验收标准”。两种路径,适合不同风格的团队。
五、OpenSpec vs Spec Kit:同向不同路
既然两个工具都站在规范驱动赛道,我们必须把它们摆到一起对一对。
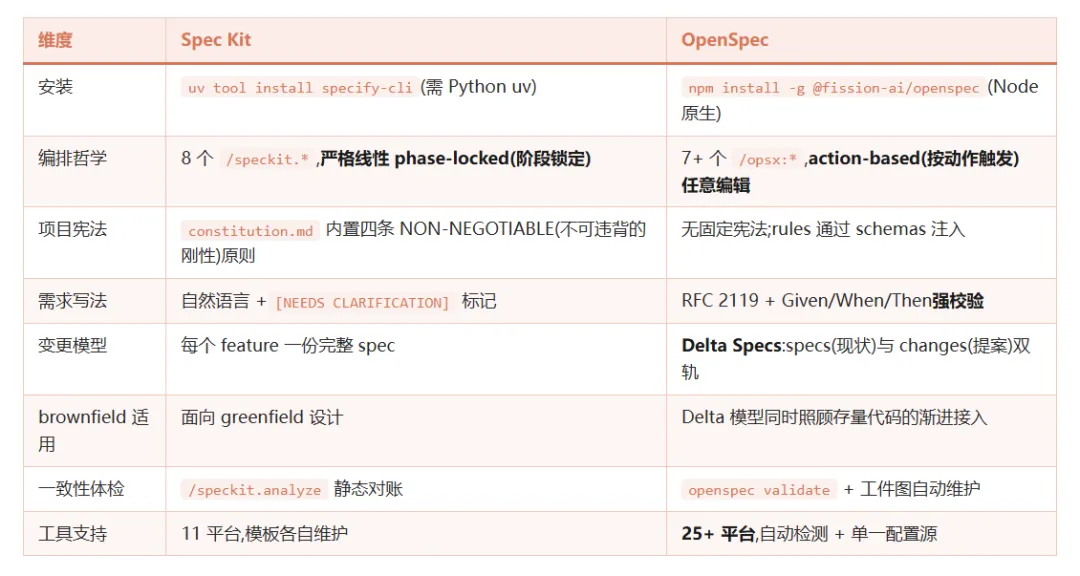
差异虽多,真正决定选型的只有三件事:
第一件事:入门门槛。uv tool install 对纯前端团队是隐形劝退——你团队没人愿意为一个开发流程工具学 Python 包管理。npm install -g 对 Node/前端团队是零摩擦。这一项决定了 OpenSpec 在前端社区扩散更快,也是为什么它能在没有 GitHub 加持的情况下跑出 4.45 万星。
第二件事:变更模型。Spec Kit 适合 greenfield(从零新建)——你新开一个项目,从零写 constitution → spec → plan → tasks。OpenSpec 适合 brownfield(存量遗留)——你在一个 50 万行的项目里,这周改个登录限流,下周加个 2FA,specs 慢慢长成。这一项决定了你团队的真实场景属于哪种。
第三件事:流程刚性。Spec Kit 的 phase-locked(阶段锁定)适合”想清楚再写”的严肃团队——它强迫你不能跳步。OPSX 的 action-based(按动作触发)适合”边迭代边对齐”的快节奏团队——AI 自己知道下一步该做什么,不需要 phase gate(阶段关卡)卡死。这一项是文化偏好的问题,没有对错。
如果一定要给一个选型建议:
两个工具不冲突。事实上你完全可以在一个项目里两个都装:Spec Kit 用来写整体宪法和初始 spec,OpenSpec 用来跑日常 brownfield 增量。
六、局限与边界
OpenSpec 同样有其边界。
高推理模型刚需
官方明确推荐 Opus 4.5 + GPT 5.2。便宜模型上 BDD 场景生成质量打折——它会写出语法正确但语义浅薄的 Scenario(比如全是”GIVEN 系统正常 / WHEN 用户操作 / THEN 返回成功”)。这种 Scenario 通过了 validate,但起不到测试用例的作用。OpenSpec 对 AI 推理质量的依赖更高;Spec Kit 则更依赖模板化提示词,受模型能力波动的影响相对较小。
v1.0 OPSX 重构带来的迁移成本
老用户的 /openspec:proposal、/openspec:apply、/openspec:archive 在 v1.0 全部废弃。如果你 2025 年下半年装过 OpenSpec 0.x,升到 1.0 时所有旧命令报错,需要跑 openspec init 重新生成工具配置。这是单作者项目的代价——重构带来的破坏性变更对老用户不够友好,后续的 v1.1 / v1.2 / v1.3 几乎都在补这次重构遗留的问题。
自定义 schemas 强大但学习曲线陡峭
openspec/schemas/ 让你自定义工件,这是 OpenSpec 最高级的能力。但它也意味着:没有定制经验的团队,八成不会用这个功能。多数用户停留在默认的 propose / apply / archive 三件套,自定义 schemas 的潜力闲置。Spec Kit 选择把逻辑集中在 8 个固定命令中,开箱即用;OpenSpec 选择开放 schemas,天花板更高但需要学习成本。两者取向不同。
它不是项目管理平台
跟 Spec Kit 一样,OpenSpec 没有看板、没有任务分配、没有审计日志。3-5 人团队靠 git PR + openspec list 还能跑顺,5 人以上必须配合 Linear / Jira / GitHub Projects 才能管住任务流。SDD(Spec-Driven Development,规范驱动开发)工具不是项目管理工具替代品,它只覆盖”代码与规范”这一层。
七、总结:OpenSpec 做了什么,没做什么
OpenSpec 不是项目管理工具,没有看板、没有任务分配、没有审计日志。它只做一件事:让”规范”成为 AI 写代码时可验证的边界。
这件事藏在三个设计选择里。
第一,specs 与 changes 分离。 已交付的行为契约放在 openspec/specs/,未经证实的提案放在 openspec/changes/。这种分离让多个改动可以并行推进,也让 AI 始终清楚哪些是”已经确认的规矩”,哪些是”还在讨论的草稿”。
第二,Delta Spec 只描述”变什么”。 你不需要为一个跑了三年的老项目重写整套规范。今天写一份”只改注册流程”的补丁,明天写一份”只调登录限流”的补丁,specs 在 archive 时被局部更新,项目规范是慢慢长出来的,不是一次性设计出来的。
第三,Scenario 是强制项,不是可选项。 每条 Requirement 必须配至少一个 Given/When/Then 场景。openspec validate 会拒绝没有 Scenario 的 spec。这不是为了增加写文档的负担,而是为了消除 AI 编码最大的失败模式——它觉得自己听懂了,其实没有。Scenario 就是对账单:AI 改完后,你逐条验证,对得上就是改对了,对不上就是改错了。
如果你已经有一个存量项目,不想推倒重来,但又想让 AI 的改动有边界、可验证——npm install -g @fission-ai/openspec@latest 试一行。写一份 Delta Spec,给 AI 一份 Given/When/Then 的合约,然后让它在合约内一行行写代码。
OpenSpec 想表达的轻量:安装很轻,一份 Delta Spec 很轻,但对”到底要什么”的思考,一点儿也不轻。