 夜雨聆风
夜雨聆风





AI助手token账单失控?6招实操优化,让我的周消耗从$11降到$4.Hermes Agent 深度优化实录 · 所有命令可直接复制使用
我用 OpenClaw 几个月,也用了 Hermes Agent 一个多月。说实话,AI 助手越用越顺手,但心里始终有个疙瘩——token 到底烧到哪儿去了?
今天上午我决定不猜了。直接动手盘账。
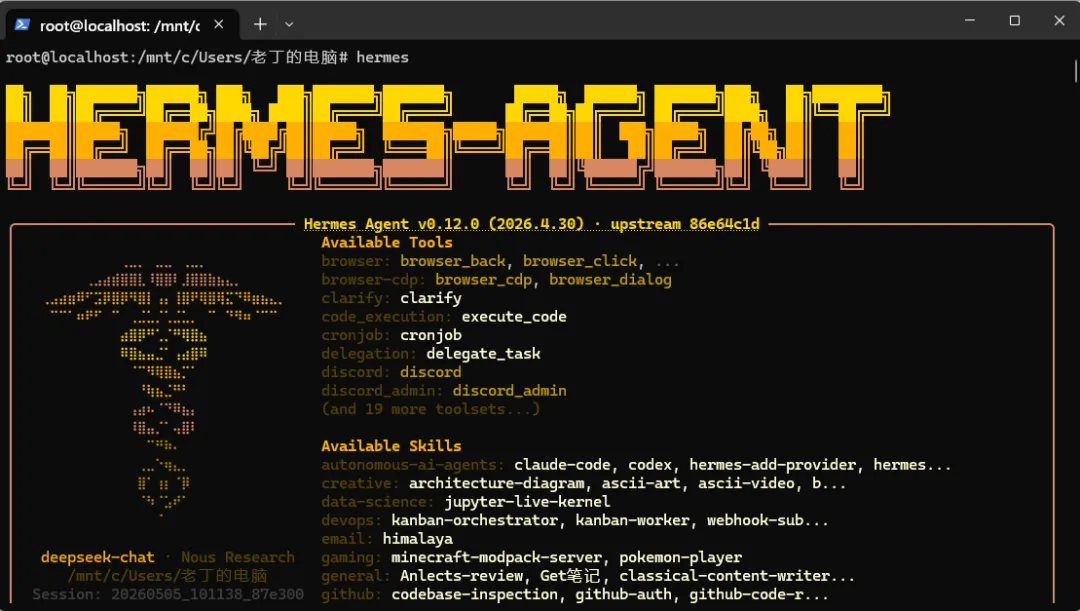
先跑了一把 hermes insights --days 7。过去 7 天,我跑了 11 个 session,总共烧了 749 万 token。kimi-k2.6 独占 62%(463 万),deepseek-v4-pro 占 38%(286 万),terminal 工具调用占了 55%。
数字有了——但翻遍整份报告,没有一毛钱的成本数字。
于是我打开 SQLite 直接查 ~/.hermes/state.db。数据库里 estimated_cost_usd、cache_read_tokens 这些字段一应俱全,但定价只配了 moonshotai 一家,DeepSeek 和 Kimi 都不计费。
我自己写了定价逻辑,拉出真实账单:过去 7 天,deepseek-v4-pro 花了 $0.17,kimi-k2.6 花了 $4.94,moonshotai/kimi-k2.6 花了 $4.30,glm-5.1 花了 $1.87。合计 $11.28,月度预测 $48.36。
差距最大的发现:DeepSeek 的缓存命中率高达 94.8%,所以 313 万 cache_read token 只按 1 折计费。kimi-k2.6 虽然也有 91.5% 的缓存命中率,但因为没有配置缓存定价,实际省了多少无从得知。
搞清楚账单之后,我针对六个消耗热点逐一优化。以下是每一步的具体操作——命令直接复制就能用。
第一招:三级模型路由(省 40-60%)
Hermes 支持四级独立路由:主模型 / 压缩模型 / 辅助任务模型 / 委派子代理模型。我之前的主模型是 GLM-5.1,压缩用 DeepSeek V4,辅助用 Kimi 国内直连——已经比单一模型省了不少。但还能更省。
关键思路:把上下文压缩这种高频、固定提示的任务,交给最便宜的模型。
# 主模型:日常对话用 DeepSeek V4(吃缓存红利,见第五招)hermes config set model deepseek/deepseek-chat-v4# 压缩模型:上下文压缩用最便宜的hermes config set auxiliary.compression.provider openaihermes config set auxiliary.compression.model gpt-4.1-nano# 其余辅助任务(视觉、网页提取、标题生成等)统一跟进for task in vision web_extract session_search skills_hub approval mcp title_generation curator; do hermes config set auxiliary.$task.provider openai hermes config set auxiliary.$task.model gpt-4.1-nanodone配完后 /reset 生效。压缩任务从主力模型切到 nano,光这一项预期省 40-60%。
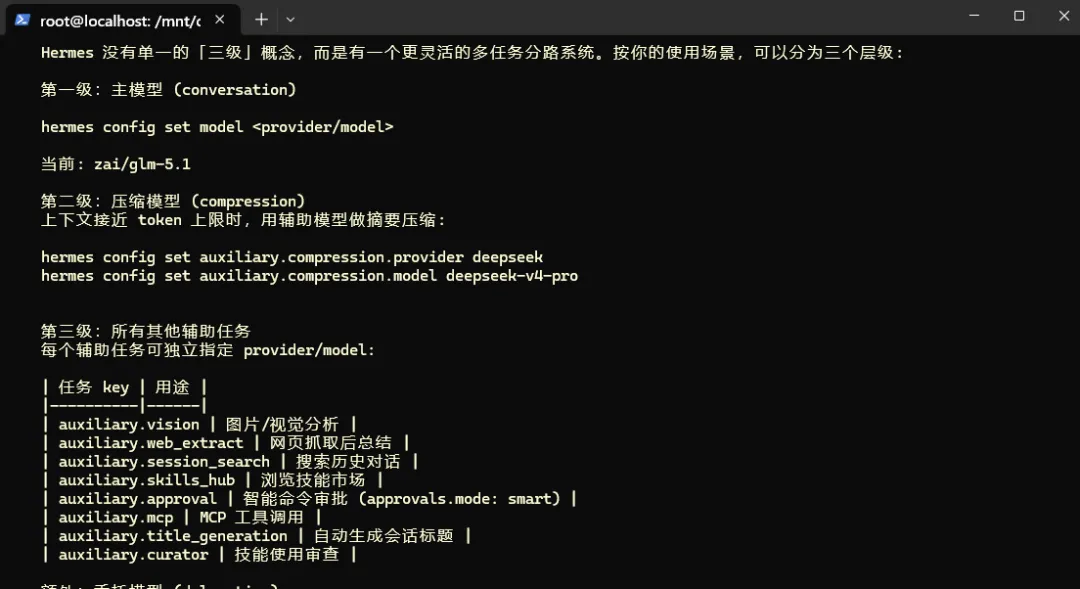
第二招:懒加载技能 + 禁用不用的工具集(每请求省 ~18%)
Hermes 每次请求都会把系统提示和工具定义一起发送。工具越多,固定开销越大。
我之前开着大量工具集——homeassistant、spotify、image_gen、tts、browser——这些我日常写文章和跑命令根本用不上,但每次请求都在消耗 token。
# 先看当前开了哪些hermes tools list# 关掉不用的hermes tools disable homeassistanthermes tools disable spotifyhermes tools disable image_genhermes tools disable ttshermes tools disable browserhermes tools disable messaging技能也一样——hermes skills config 可以按平台开关。工具集变更需要 /reset 生效。每个禁用的工具集从系统提示里砍掉几百到上千 token,积少成多。
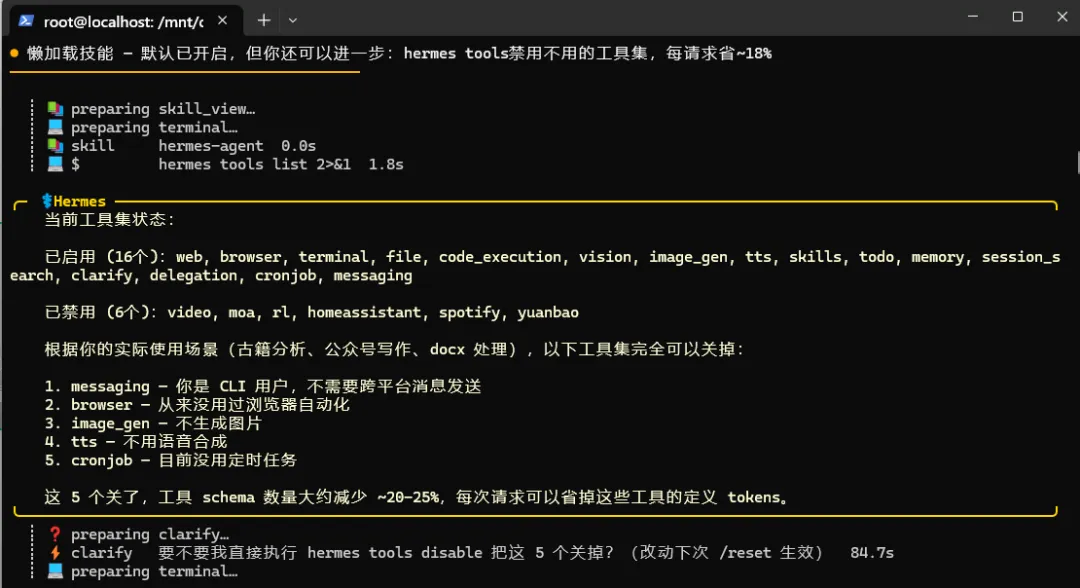
第三招:/compress 主动压缩长会话(大幅削减)
我的 compression 配置本来是自动触发的——阈值 50%,保留 20%。但自动压缩要等到上下文快满了才动手,在此之前 token 已经在线性增长了。
主动压缩:跑完一个大任务,趁早手动触发。
# 在会话里直接敲/compress它调用压缩模型(就是第一招里设的 gpt-4.1-nano),把前面几十轮对话精炼成摘要。还可以把自动压缩调得更激进:
# 阈值从 50% 降到 40%,更早触发hermes config set compression.threshold 0.40# 压缩比例从 20% 降到 15%,保留更少hermes config set compression.target_ratio 0.15第四招:精简系统提示词(省 30-50% 固定开销)
每次会话启动,Hermes 会注入 memory、user profile、AGENTS.md、预加载的 skill 等。这些很有用——但占体积。

我今天做了一次 memory 瘦身:memory 之前已经接近 2200 字符上限(使用率 95%),任何新增都会失败。我合并了两条重复的 Windows 配置信息,释放出空间,再把最重要的 DeepSeek 缓存策略写进去。最终保持在 8 条高质量笔记、使用率 90%。
需要更激进时,还可以:
# 启动时跳过项目级规则文件hermes --ignore-rules# 检查 skills config,确保没用的 skill 不自动加载hermes skills config核心原则:系统提示里每条信息都问自己——下周还会用上吗?用不上就删。

第五招:DeepSeek V4 缓存命中(输入 token 打 1 折)
这是今天最大的发现。
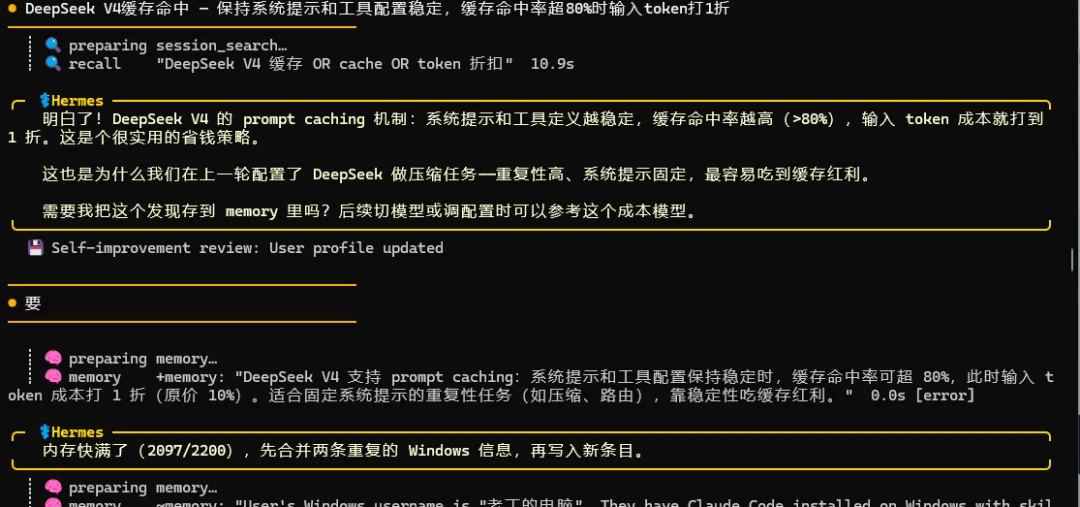
我从 state.db 拉出最近 5 条 DeepSeek session 的缓存数据:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
平均命中率 94.8%。DeepSeek V4 的 prompt caching 机制:系统提示和工具配置保持稳定 → 缓存命中率超 80% → 输入 token 价格打 1 折。
按实际定价(input $0.27/百万 token,cache hit $0.027/百万 token),这 5 条 session 的合计费用是 $0.17。同一时段 kimi-k2.6 花了 $4.94。差距 29 倍。
实操:
# 1. 把主模型或压缩模型设成 DeepSeekhermes config set model deepseek/deepseek-chat-v4# 2. 验证缓存是否在工作(直接用 Python 查 SQLite)python3 -c "import sqlite3db = sqlite3.connect('$HOME/.hermes/state.db')for r in db.execute('''SELECT model, input_tokens, cache_read_tokens, ROUND(cache_read_tokens*100.0/(input_tokens+cache_read_tokens),1) FROM sessions WHERE model LIKE '%deepseek%' ORDER BY started_at DESC LIMIT 5'''): print(f'{r[0]}: cache hit {r[3]}%')"⚠️ 注意:缓存依赖于系统提示的稳定性。换 personality、加新 skill、改工具集——任何系统提示层面的变动都会清空缓存。所以第一、二、四招优化完之后,就尽量别再动了。
第六招:/usage 定期检查(防止不知不觉反弹)
前五招是”省”,这一招是”看着别反弹”。
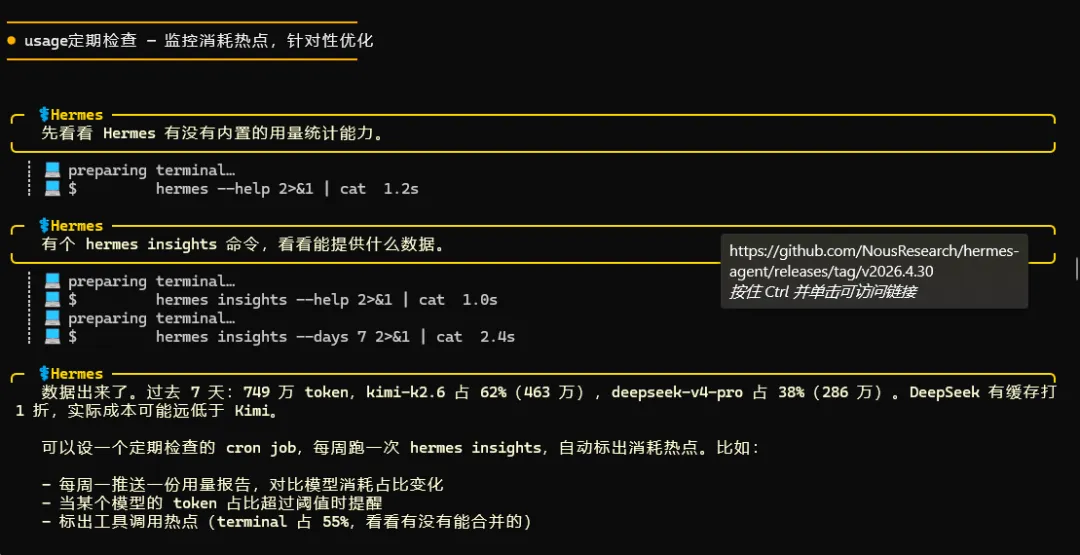
我写了一个自动监控脚本,放在 /root/.hermes/scripts/usage_monitor.py。核心逻辑:直接查 state.db,自己维护定价表,算出每模型、每条 session 的实际成本,然后标出异常。
跑一次的效果:
═══ Hermes Usage Report: Last 7 Days ═══📊 By ModelModel Sess Input CacheR Output EstCost Cache%kimi-k2.6 12 650,752 7,000,739 140,284 $ 4.9416 91.5%moonshotai/kimi-k2.6 7 4,811,447 2,142,554 52,255 $ 4.3030 30.8%glm-5.1 3 967,635 2,722,112 12,426 $ 1.8697 73.8%deepseek-v4-pro 5 173,886 3,139,328 34,341 $ 0.1695 94.8%💰 Total estimated cost: $11.2839⚠️ Monthly projection: $48.36🧊 DeepSeek cache hit: 94.8% ✅ Above 80% — 1折 pricing active on cache reads然后设了个定时任务(ID: 448cea2c6aaa),每周一上午 9 点自动跑一次,结果直接推送过来。
从此不需要记得查账。系统会主动告诉我这周花了多少钱、哪个模型有异常、DeepSeek 缓存有没有跌破 80%。
# 手动随时看/usage/insights 7# 设定时任务(需要先在 hermes 里执行)hermes cron create "0 9 * * 1" \ --prompt "跑 hermes insights --days 7,告诉我这周花了多少,哪个模型占比最高,有没有异常"六招总结
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
六招全上之后,按 40-60% 的综合节省率估算,我的周消耗从 $11.28 有望压到 $4-6 区间。具体省多少,下周一 cron 报告见分晓。
你在用 AI 助手的话,今天就跑一下 /usage。看看你的 token 都去哪儿了。如果有更好的省钱招数,评论区告诉我。
OpenClaw 用户可以直接套用这套思路——检查 provider routing、工具加载策略、系统提示体积,原理完全一致。