🧠🛠✋🏻最好的算法,是在最少的时间内做最合理的事情。同样,一直以来,AI Coding 要解决的核心问题都是:如何在最大化 AI 价值,最小化时间、精力和花费的前提下,做出质量最高的产品?对此,业界做了很多探究,各种概念和框架层出不穷。Anthropic 是 AI Coding 领域的翘楚,目标用户就是开发者,从他们的视角可以看到 AI Coding 的全局。来看全局。
理想态
AI Coding 的理想态是让 AI 自己用最快的速度、花最少的钱鼓捣出来好东西。拆解成三个点:“AI 价值最大化”、“成本最小化”、“高质量”。其中最重要的是第三点。前两点锚定方法,第三点定义标准。标准决定方法。1. 产品质量① 可用完整实现所有功能,并确保功能经过充分测试,放到流程中可用。② 美观在保证可用性基础上,让人潜意识里产生美感的产品,我们认为是高质量的。如何定义美?每个人对美的标准都不一样,如果让 AI 凭空去评估美,结果一定是不稳定的。但如果问“这符合好的设计原则吗?”,它就可以给出相对合理的评估依据。Anthropic 定义的设计原则:1)设计品质:是否是连贯的整体,而不是组件堆叠。颜色、排版、布局、意象和所有细节结合起来,是否能营造独特的氛围?2)原创性:设计是源于创意?还是基于模版布局、Library 的预设 or AI 生成的样式?3)精巧度:排版层次、间距一致、色彩和谐、对比度。4)可用性:用户能否理解界面功能,不用猜就能完成操作?3、4都是能力层面的要求,AI 擅长。而品质和原创性方面,AI 表现糟糕。所以模型训练时,就会对诸如“白色卡片上覆盖紫色渐层”这种 AI 垃圾模式予以惩罚,并加大设计和创新权重,逼模型采取更具审美的策略。2. AI 价值AI 比人类高明的地方在于,在限定条件下高效做出最优决策的能力。要最大化 AI 价值,就要充分发挥这项优势。3. 成本控制成本即做出高质量产品所花费的时间、人的精力和 AI 的算力。
保质保量
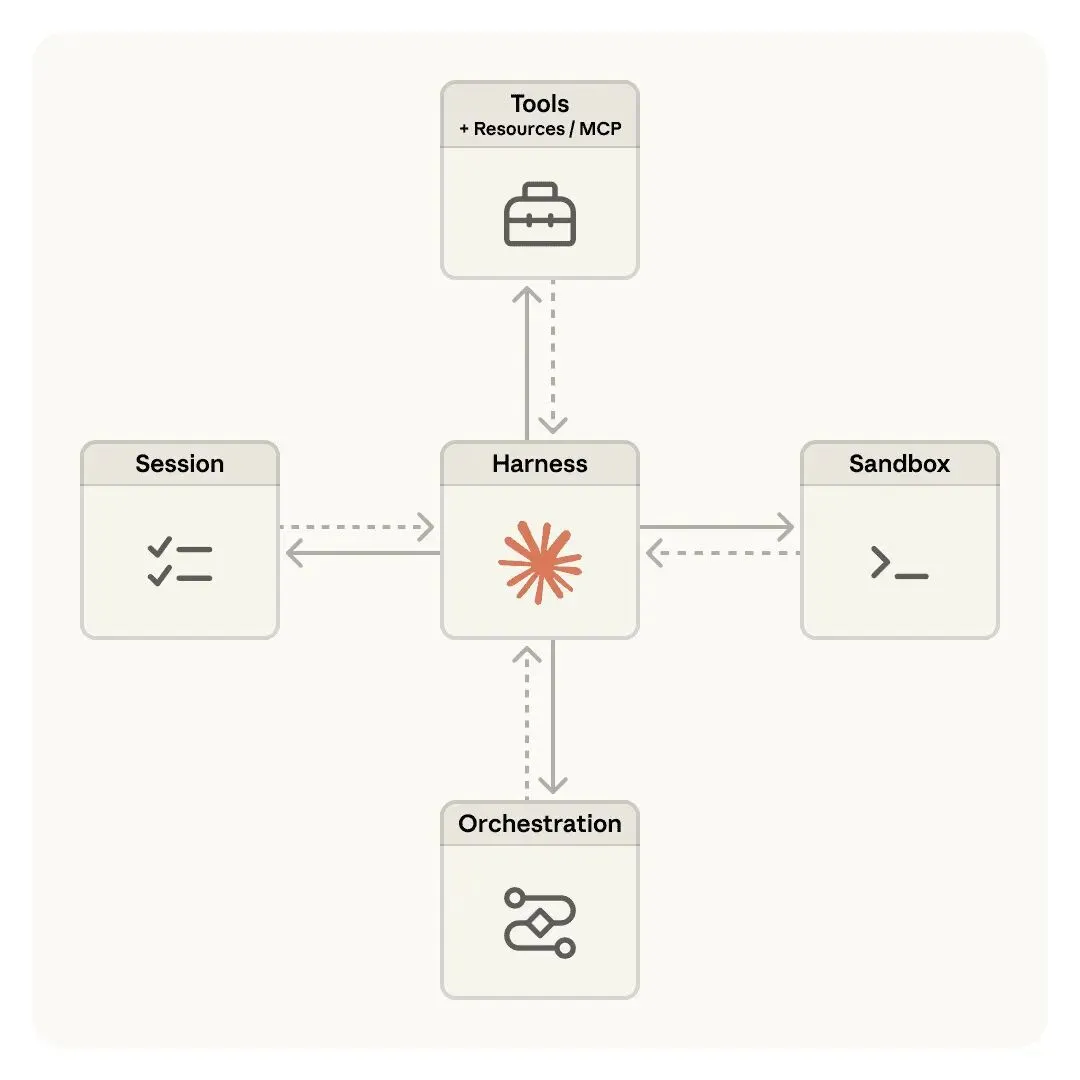
试想一下,我们在做新需求时是什么流程?产品针对特定场景下的用户动机提出需求,交给设计和技术落地。无论是设计,还是技术,都会对需求进一步拆解:具体有哪些功能,哪些可以复用/更改已有逻辑?哪些要新加?可以看到,面对复杂需求时,我们人类不会直接开始做,而是拆解成小点逐步推进。(😒那又凭什么要求 Agent 拿到需求文档就 100% 完美实现呢?)一、目标限制:和人类一样,AI 的上下文窗口有限,复杂项目的任务们没法在一个窗口中完成,需要多个 Sessions。 问题:但是分散在多个 Sessions 里的任务没有上下文记忆。目标:弥合 Sessions 之间的 Gap。二、解法理论上,具备上下文管理和Coding 能力的 Agent 应该能持续有效地工作才对。但实际,即使是 Opus 4.5,在跨多个上下文窗口完成复杂任务时,也还是不能构建出满足质量标准的产品。它们一般会掉入以下两种失败模式中,导致无法完成任务。模式 1 – 贪多嚼不烂Agent 倾向于一口吃成个胖子,总想着一次性完成整个产品的构建。导致模型执行过程中,因为上下文溢出而中断。下一轮会话面对的就会是一个实现了一半、且缺乏记录的烂摊子。然后 Agent 就会去推测前面怎么了,还会耗费大量时间去让产品 Work。像瀑布一样,止不住地一错再错。模式 2 – 提前结束工作部分功能构建完成后,Agent 审视项目时,发现有实质性进展,就会误以为任务全都完成了,然后宣告工作结束啦!👍🏻了解了这两种模式特征,拆分两块解决:首先建初始环境,引导 Agent 采取循序渐进、逐个击破的工作模式;其次,引导 Agent 在 Session 结束时,将环境恢复整洁(即:代码已达到合并主分支的质量标准,无重大 bug、代码井井有条、文档完备,人类工程师可以直接接手)。基于上述方案,Anthropic 创造了两个 Agents:1. 初始化 Agent:负责在首次运行时完成环境配置。包含用于初始化设置的 `init.sh`脚本 + 用于记录日志的 `claude-progress.txt` 文件 + 用于展示本次会话新增文件的一次初始 Git Commit。2. Coding Agent:优秀工程师通常会通过查阅进展记录和 Git 提交历史来把握当前工作状态。将这个洞察迁移到 Coding Agent,它需要让每个 Session 开始时都能获取当前进展,并在编程结束时为后续 Sessions 记录清晰的阶段成果。三、实施这两个 Agents 的具体协作可以分成 4 个模块:1. Feature List初始化 Agent 负责细化用户提示词,编写出一份详尽的需求文档,让 Coding Agent 明白完整产品的最终形态。Coding Agent 负责更新每个 Feature 的 `passes` 字段状态,其他都不许动(这个任务用 JSON 格式。相较于 Markdown,模型处理 JSON 文件时不太会发生不当更改和覆盖操作)。2. 渐进式开发要求 Coding Agent:① 每次只专注开发一个功能。② 写完代码后,必须把环境恢复整洁。具体:要求它提交到 Git,并附详细提交信息;要求它将进度摘要写入进度文件。这样,模型就能够通过回滚,快速撤销错误改动。3. 测试AI 往往在没有经过充分测试的情况下,就将功能标记为已完成,它无法识别功能在整体流程里并不 Work。通过提示词,可以要求它使用自动化工具,并像人类一样执行全流程测试,这样,它才会去认真验证功能完整性。但仍存在问题:受限于视觉能力,以及浏览器自动化工具的局限性,Agent 无法识别所有类型的错误(比如浏览器原生 Alert,这类功能更容易出 Bug)。4. 基础但有用的步骤除了上述三个模块外,每个 Coding Agent 还需要完成一些步骤,以确保每次启动时能核实产品是否状态异常,并立即修复:① Run `pwd` to see the directory you’re working in. You’ll only be able to edit files in this directory.② Read the git logs and progress files to get up to speed on what was recently worked on.③ Read the features list file and choose the highest-priority feature that’s not yet done to work on.
Claude 的博文写得都很踏实,基本逻辑都是针对某个问题或现象,提出一套解决方案,且可以看到解法和解法之间渐进发展的脉络。OpenAI 4/15 也发布了博文,类似的底层架构。但文章只介绍了功能,“支持了xxx”、“现在可以xxx”,没有具体场景的来龙去脉,感觉像凭空冒出来的,就不看了。参考:[1] Anthropic Blog: Effective harnesses for long-running agents[2] Anthropic Blog: Scaling Managed Agents: decoupling the brain from the hands
 夜雨聆风
夜雨聆风